Adding an auto scaling policy to an Amazon Aurora DB cluster
You can add a scaling policy using the AWS Management Console, the AWS CLI, or the Application Auto Scaling API.
Note
For an example that adds a scaling policy using CloudFormation, see Declaring a scaling policy for an Aurora DB cluster in the AWS CloudFormation User Guide.
You can add a scaling policy to an Aurora DB cluster by using the AWS Management Console.
To add an auto scaling policy to an Aurora DB cluster
Sign in to the AWS Management Console and open the Amazon RDS console at https://console.aws.amazon.com/rds/
. -
In the navigation pane, choose Databases.
-
Choose the Aurora DB cluster that you want to add a policy for.
-
Choose the Logs & events tab.
-
In the Auto scaling policies section, choose Add.
The Add Auto Scaling policy dialog box appears.
-
For Policy Name, type the policy name.
-
For the target metric, choose one of the following:
-
Average CPU utilization of Aurora Replicas to create a policy based on the average CPU utilization.
-
Average connections of Aurora Replicas to create a policy based on the average number of connections to Aurora Replicas.
-
-
For the target value, type one of the following:
-
If you chose Average CPU utilization of Aurora Replicas in the previous step, type the percentage of CPU utilization that you want to maintain on Aurora Replicas.
-
If you chose Average connections of Aurora Replicas in the previous step, type the number of connections that you want to maintain.
Aurora Replicas are added or removed to keep the metric close to the specified value.
-
-
(Optional) Expand Additional Configuration to create a scale-in or scale-out cooldown period.
-
For Minimum capacity, type the minimum number of Aurora Replicas that the Aurora Auto Scaling policy is required to maintain.
-
For Maximum capacity, type the maximum number of Aurora Replicas the Aurora Auto Scaling policy is required to maintain.
-
Choose Add policy.
The following dialog box creates an Auto Scaling policy based an average CPU utilization of 40 percent. The policy specifies a minimum of 5 Aurora Replicas and a maximum of 15 Aurora Replicas.

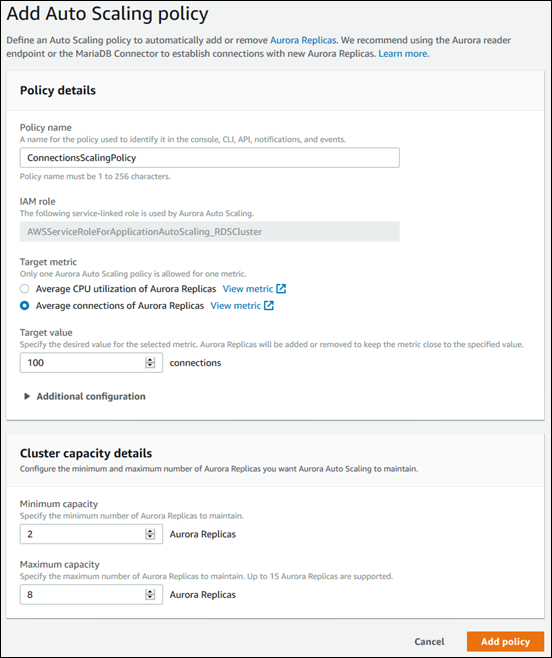
The following dialog box creates an auto scaling policy based an average number of connections of 100. The policy specifies a minimum of two Aurora Replicas and a maximum of eight Aurora Replicas.
You can apply a scaling policy based on either a predefined or custom metric. To do so, you can use the AWS CLI or the Application Auto Scaling API. The first step is to register your Aurora DB cluster with Application Auto Scaling.
Registering an Aurora DB cluster
Before you can use Aurora Auto Scaling with an Aurora DB cluster, you register your Aurora DB cluster with Application Auto Scaling.
You do so to define the scaling dimension and limits to be applied to that cluster. Application Auto Scaling dynamically scales the
Aurora DB cluster along the rds:cluster:ReadReplicaCount scalable dimension, which represents the number
of Aurora Replicas.
To register your Aurora DB cluster, you can use either the AWS CLI or the Application Auto Scaling API.
AWS CLI
To register your Aurora DB cluster, use the register-scalable-target AWS CLI command with the following parameters:
-
--service-namespace– Set this value tords. -
--resource-id– The resource identifier for the Aurora DB cluster. For this parameter, the resource type isclusterand the unique identifier is the name of the Aurora DB cluster, for examplecluster:myscalablecluster. -
--scalable-dimension– Set this value tords:cluster:ReadReplicaCount. -
--min-capacity– The minimum number of reader DB instances to be managed by Application Auto Scaling. For information about the relationship between--min-capacity,--max-capacity, and the number of DB instances in your cluster, see Minimum and maximum capacity. -
--max-capacity– The maximum number of reader DB instances to be managed by Application Auto Scaling. For information about the relationship between--min-capacity,--max-capacity, and the number of DB instances in your cluster, see Minimum and maximum capacity.
Example
In the following example, you register an Aurora DB cluster named myscalablecluster. The
registration indicates that the DB cluster should be dynamically scaled to have from one to eight Aurora
Replicas.
For Linux, macOS, or Unix:
aws application-autoscaling register-scalable-target \ --service-namespace rds \ --resource-id cluster:myscalablecluster\ --scalable-dimension rds:cluster:ReadReplicaCount \ --min-capacity1\ --max-capacity8\
For Windows:
aws application-autoscaling register-scalable-target ^ --service-namespace rds ^ --resource-id cluster:myscalablecluster^ --scalable-dimension rds:cluster:ReadReplicaCount ^ --min-capacity1^ --max-capacity8^
Application Auto Scaling API
To register your Aurora DB cluster with Application Auto Scaling, use the RegisterScalableTarget Application Auto Scaling API operation with the following
parameters:
-
ServiceNamespace– Set this value tords. -
ResourceID– The resource identifier for the Aurora DB cluster. For this parameter, the resource type isclusterand the unique identifier is the name of the Aurora DB cluster, for examplecluster:myscalablecluster. -
ScalableDimension– Set this value tords:cluster:ReadReplicaCount. -
MinCapacity– The minimum number of reader DB instances to be managed by Application Auto Scaling. For information about the relationship betweenMinCapacity,MaxCapacity, and the number of DB instances in your cluster, see Minimum and maximum capacity. -
MaxCapacity– The maximum number of reader DB instances to be managed by Application Auto Scaling. For information about the relationship betweenMinCapacity,MaxCapacity, and the number of DB instances in your cluster, see Minimum and maximum capacity.
Example
In the following example, you register an Aurora DB cluster named myscalablecluster with the
Application Auto Scaling API. This registration indicates that the DB cluster should be dynamically scaled to have from one
to eight Aurora Replicas.
POST / HTTP/1.1 Host: autoscaling.us-east-2.amazonaws.com Accept-Encoding: identity Content-Length: 219 X-Amz-Target: AnyScaleFrontendService.RegisterScalableTarget X-Amz-Date: 20160506T182145Z User-Agent: aws-cli/1.10.23 Python/2.7.11 Darwin/15.4.0 botocore/1.4.8 Content-Type: application/x-amz-json-1.1 Authorization: AUTHPARAMS { "ServiceNamespace": "rds", "ResourceId": "cluster:myscalablecluster", "ScalableDimension": "rds:cluster:ReadReplicaCount", "MinCapacity":1, "MaxCapacity":8}
Defining a scaling policy for an Aurora DB cluster
A target-tracking scaling policy configuration is represented by a JSON block that the metrics and target values
are defined in. You can save a scaling policy configuration as a JSON block in a text file. You use that text file
when invoking the AWS CLI or the Application Auto Scaling API. For more information about policy configuration syntax, see TargetTrackingScalingPolicyConfiguration in the Application Auto Scaling API
Reference.
The following options are available for defining a target-tracking scaling policy configuration.
Topics
Using a predefined metric
By using predefined metrics, you can quickly define a target-tracking scaling policy for an Aurora DB cluster that works well with both target tracking and dynamic scaling in Aurora Auto Scaling.
Currently, Aurora supports the following predefined metrics in Aurora Auto Scaling:
-
RDSReaderAverageCPUUtilization – The average value of the
CPUUtilizationmetric in CloudWatch across all Aurora Replicas in the Aurora DB cluster. -
RDSReaderAverageDatabaseConnections – The average value of the
DatabaseConnectionsmetric in CloudWatch across all Aurora Replicas in the Aurora DB cluster.
For more information about the CPUUtilization and DatabaseConnections metrics, see
Amazon CloudWatch metrics for Amazon Aurora.
To use a predefined metric in your scaling policy, you create a target tracking configuration for your scaling
policy. This configuration must include a PredefinedMetricSpecification for the predefined metric
and a TargetValue for the target value of that metric.
Example
The following example describes a typical policy configuration for target-tracking scaling for an Aurora DB
cluster. In this configuration, the RDSReaderAverageCPUUtilization predefined metric is used to
adjust the Aurora DB cluster based on an average CPU utilization of 40 percent across all Aurora Replicas.
{ "TargetValue": 40.0, "PredefinedMetricSpecification": { "PredefinedMetricType": "RDSReaderAverageCPUUtilization" } }
Using a custom metric
By using custom metrics, you can define a target-tracking scaling policy that meets your custom requirements. You can define a custom metric based on any Aurora metric that changes in proportion to scaling.
Not all Aurora metrics work for target tracking. The metric must be a valid utilization metric and describe how busy an instance is. The value of the metric must increase or decrease in proportion to the number of Aurora Replicas in the Aurora DB cluster. This proportional increase or decrease is necessary to use the metric data to proportionally scale out or in the number of Aurora Replicas.
Example
The following example describes a target-tracking configuration for a scaling policy. In this
configuration, a custom metric adjusts an Aurora DB cluster based on an average CPU utilization of 50 percent
across all Aurora Replicas in an Aurora DB cluster named my-db-cluster.
{ "TargetValue": 50, "CustomizedMetricSpecification": { "MetricName": "CPUUtilization", "Namespace": "AWS/RDS", "Dimensions": [ {"Name": "DBClusterIdentifier","Value": "my-db-cluster"}, {"Name": "Role","Value": "READER"} ], "Statistic": "Average", "Unit": "Percent" } }
Using cooldown periods
You can specify a value, in seconds, for ScaleOutCooldown to add a cooldown period for scaling
out your Aurora DB cluster. Similarly, you can add a value, in seconds, for ScaleInCooldown to add a
cooldown period for scaling in your Aurora DB cluster. For more information about ScaleInCooldown
and ScaleOutCooldown, see
TargetTrackingScalingPolicyConfiguration in the Application Auto Scaling
API Reference.
Example
The following example describes a target-tracking configuration for a scaling policy. In this
configuration, the RDSReaderAverageCPUUtilization predefined metric is used to adjust an Aurora
DB cluster based on an average CPU utilization of 40 percent across all Aurora Replicas in that Aurora DB
cluster. The configuration provides a scale-in cooldown period of 10 minutes and a scale-out cooldown period
of 5 minutes.
{ "TargetValue": 40.0, "PredefinedMetricSpecification": { "PredefinedMetricType": "RDSReaderAverageCPUUtilization" }, "ScaleInCooldown": 600, "ScaleOutCooldown": 300 }
Disabling scale-in activity
You can prevent the target-tracking scaling policy configuration from scaling in your Aurora DB cluster by disabling scale-in activity. Disabling scale-in activity prevents the scaling policy from deleting Aurora Replicas, while still allowing the scaling policy to create them as needed.
You can specify a Boolean value for DisableScaleIn to enable or disable scale in activity for
your Aurora DB cluster. For more information about DisableScaleIn, see TargetTrackingScalingPolicyConfiguration in the Application Auto Scaling
API Reference.
Example
The following example describes a target-tracking configuration for a scaling policy. In this
configuration, the RDSReaderAverageCPUUtilization predefined metric adjusts an Aurora DB cluster
based on an average CPU utilization of 40 percent across all Aurora Replicas in that Aurora DB cluster. The
configuration disables scale-in activity for the scaling policy.
{ "TargetValue": 40.0, "PredefinedMetricSpecification": { "PredefinedMetricType": "RDSReaderAverageCPUUtilization" }, "DisableScaleIn": true }
Applying a scaling policy to an Aurora DB cluster
After registering your Aurora DB cluster with Application Auto Scaling and defining a scaling policy, you apply the scaling policy to the registered Aurora DB cluster. To apply a scaling policy to an Aurora DB cluster, you can use the AWS CLI or the Application Auto Scaling API.
To apply a scaling policy to your Aurora DB cluster, use the put-scaling-policy AWS CLI command with the following parameters:
-
--policy-name– The name of the scaling policy. -
--policy-type– Set this value toTargetTrackingScaling. -
--resource-id– The resource identifier for the Aurora DB cluster. For this parameter, the resource type isclusterand the unique identifier is the name of the Aurora DB cluster, for examplecluster:myscalablecluster. -
--service-namespace– Set this value tords. -
--scalable-dimension– Set this value tords:cluster:ReadReplicaCount. -
--target-tracking-scaling-policy-configuration– The target-tracking scaling policy configuration to use for the Aurora DB cluster.
Example
In the following example, you apply a target-tracking scaling policy named
myscalablepolicy to an Aurora DB cluster named myscalablecluster with
Application Auto Scaling. To do so, you use a policy configuration saved in a file named
config.json.
For Linux, macOS, or Unix:
aws application-autoscaling put-scaling-policy \ --policy-namemyscalablepolicy\ --policy-type TargetTrackingScaling \ --resource-id cluster:myscalablecluster\ --service-namespace rds \ --scalable-dimension rds:cluster:ReadReplicaCount \ --target-tracking-scaling-policy-configurationfile://config.json
For Windows:
aws application-autoscaling put-scaling-policy ^ --policy-namemyscalablepolicy^ --policy-type TargetTrackingScaling ^ --resource-id cluster:myscalablecluster^ --service-namespace rds ^ --scalable-dimension rds:cluster:ReadReplicaCount ^ --target-tracking-scaling-policy-configurationfile://config.json
To apply a scaling policy to your Aurora DB cluster with the Application Auto Scaling API, use the PutScalingPolicy Application Auto Scaling API operation with the following parameters:
-
PolicyName– The name of the scaling policy. -
ServiceNamespace– Set this value tords. -
ResourceID– The resource identifier for the Aurora DB cluster. For this parameter, the resource type isclusterand the unique identifier is the name of the Aurora DB cluster, for examplecluster:myscalablecluster. -
ScalableDimension– Set this value tords:cluster:ReadReplicaCount. -
PolicyType– Set this value toTargetTrackingScaling. -
TargetTrackingScalingPolicyConfiguration– The target-tracking scaling policy configuration to use for the Aurora DB cluster.
Example
In the following example, you apply a target-tracking scaling policy named
myscalablepolicy to an Aurora DB cluster named myscalablecluster with
Application Auto Scaling. You use a policy configuration based on the RDSReaderAverageCPUUtilization
predefined metric.
POST / HTTP/1.1 Host: autoscaling.us-east-2.amazonaws.com Accept-Encoding: identity Content-Length: 219 X-Amz-Target: AnyScaleFrontendService.PutScalingPolicy X-Amz-Date: 20160506T182145Z User-Agent: aws-cli/1.10.23 Python/2.7.11 Darwin/15.4.0 botocore/1.4.8 Content-Type: application/x-amz-json-1.1 Authorization: AUTHPARAMS { "PolicyName": "myscalablepolicy", "ServiceNamespace": "rds", "ResourceId": "cluster:myscalablecluster", "ScalableDimension": "rds:cluster:ReadReplicaCount", "PolicyType": "TargetTrackingScaling", "TargetTrackingScalingPolicyConfiguration": { "TargetValue":40.0, "PredefinedMetricSpecification": { "PredefinedMetricType": "RDSReaderAverageCPUUtilization" } } }
