Connecting to Amazon Aurora Global Database
Each Aurora Global Database comes with a writer endpoint that is automatically updated by Aurora to route requests to the current writer instance of the primary DB cluster. With the writer endpoint, you don't have to modify your connection string after you change the location of the primary Region using the managed Aurora Global Database switchover and failover capabilities. To learn more about using the writer endpoint along with Aurora Global Database switchover and failover, see Using switchover or failover in Amazon Aurora Global Database. For information about connecting to an Aurora Global Database with RDS Proxy, see Using RDS Proxy with Aurora global databases.
Topics
Choosing the endpoint that meets your application needs
Connecting to an Aurora Global Database depends on your need to read or write from the database and the AWS Region you want to route your requests to. Here are a few typical use cases:
-
Routing requests to the writer instance: Connect to the Aurora Global Database writer endpoint if you need to run data manipulation language (DML) and data definition language (DDL) statements, or if you need strong consistency between reads and writes. That endpoint routes requests to the writer instance in your global database's primary cluster. This endpoint is automatically updated to route requests to the writer instance, eliminating the need to update your application each time you change the writer location in your global cluster. You can also use the global endpoint to send cross-Region read/write requests to your writer.
Note
If you set up your global database before the Aurora Global Database writer endpoint was available, your application might connect to the cluster endpoint of the primary cluster. In this case, we recommend switching your connection settings to use the global writer endpoint instead. Doing so avoids the need to change your connection settings after every Aurora Global Database switchover or failover.
The first part of the writer endpoint name is the name of your Aurora Global Database. Thus, if you rename your Aurora Global Database, the writer endpoint name changes, and any code that uses it must be updated with the new name.
-
Scaling reads closer to your application's region: To scale read-only requests in the same or nearby AWS Region as your application, connect to the reader endpoint of the primary or secondary Aurora clusters.
-
Scaling reads with occasional cross-region writes: For occasional DML statements such as for maintenance and data cleanup, connect to the reader endpoint of a secondary cluster that has write forwarding enabled. With write forwarding, Aurora automatically forwards the write statements to the writer in the primary Region of your Aurora Global Database. Write forwarding provides the following benefits:
-
You don't need to do the heavy lifting to establish connectivity between the secondary and primary clusters to send cross-region writes.
-
You don't need to split read and write requests in the application.
-
You don't need to develop complex logic to manage consistency for read-after-write requests.
However, with write forwarding, you do need to update your application code or configuration to connect to the newly promoted primary Region's reader endpoint after performing a cross-Region failover or switchover. We recommend that you monitor the latency of operations done through write forwarding, to check overhead of processing the write requests. Finally, write forwarding doesn't support certain MySQL or PostgreSQL operations, such as making data definition language (DDL) changes or
SELECT FOR UPDATEstatements.To learn more about using write forwarding across AWS Regions, see Using write forwarding in an Amazon Aurora global database.
-
For details about the different kinds of Aurora endpoints, see Connecting to an Amazon Aurora DB cluster.
Viewing the endpoints of an Amazon Aurora global database
When you view an Aurora Global Database in the console, you can see all of the endpoints associated with all of its clusters. The following figure shows an example of the types of endpoints you see when you view the details for your primary DB cluster:
-
Global writer – The single read/write endpoint that always points to the current writer DB instance for the global database cluster.
-
Writer – The connection endpoint for read/write requests to the primary DB cluster in the global database cluster.
-
Reader – The connection endpoint for read-only requests to a primary or secondary DB cluster in the global database cluster. To minimize latency, choose whichever reader endpoint is in your AWS Region or the AWS Region closest to you.
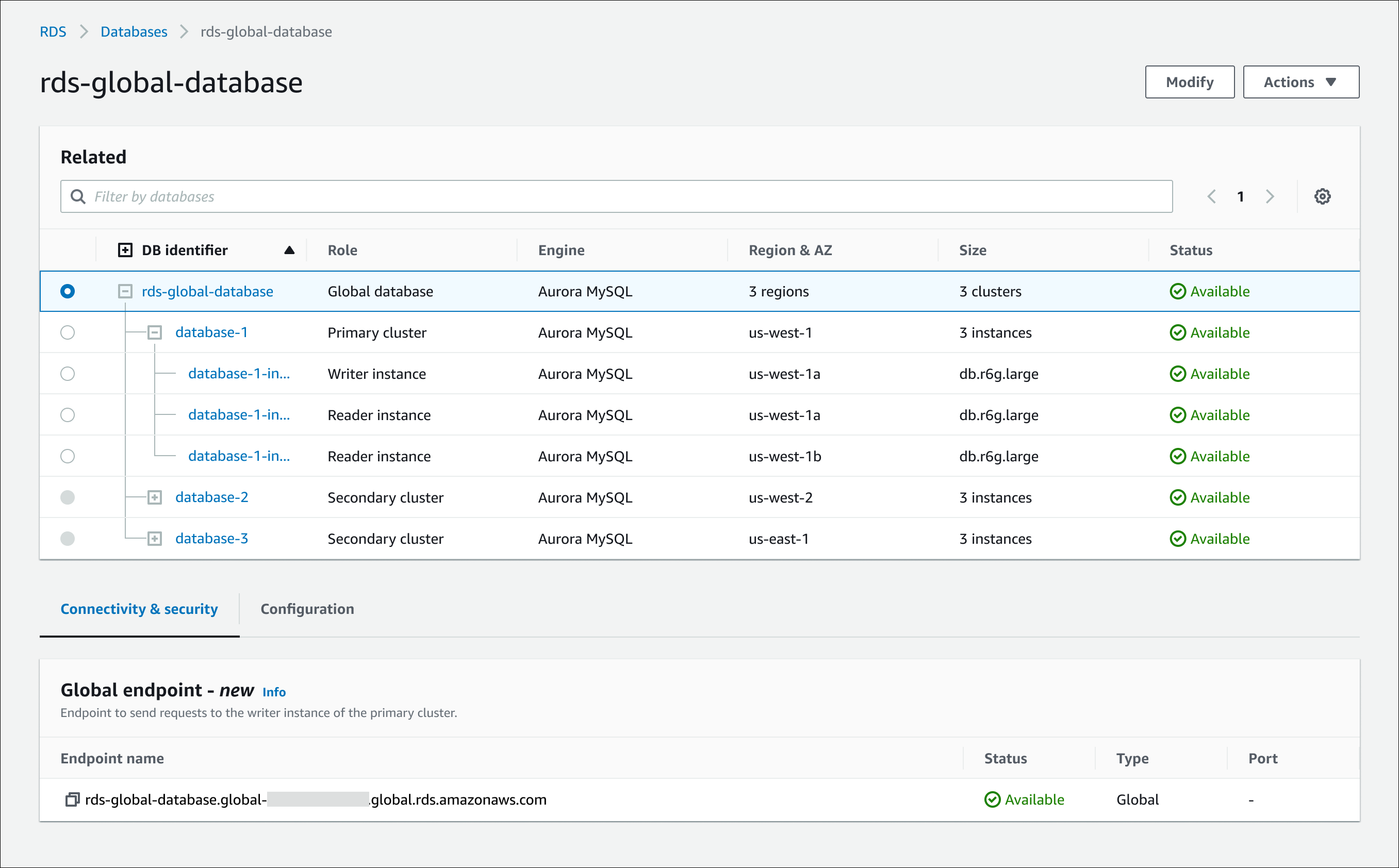
To view the endpoints of a global database
-
Sign in to the AWS Management Console and open the Amazon RDS console at https://console.aws.amazon.com/rds/
. -
In the navigation pane, choose Databases.
-
In the list, choose the global database, or the primary or secondary DB cluster whose endpoints you want to view.
-
Choose the Connectivity & security tab to see the endpoint details. The endpoints displayed depend on the type of cluster you selected, as follows:
-
Global database – The global writer endpoint.
-
Primary DB cluster – The global writer endpoint, and the cluster endpoint and reader endpoint for the primary cluster.
-
Secondary DB cluster – The cluster endpoint and reader endpoint for the secondary cluster. On a secondary cluster, the cluster endpoint displays a status of inactive because it doesn't handle write requests. You can still connect to the cluster endpoint, but only for read queries.
-
To view the global cluster's writer endpoint, use the AWS CLI describe-global-clusters command, as in the following example.
aws rds describe-global-clusters --regionaws_region{ "GlobalClusters": [ { "GlobalClusterIdentifier": "global_cluster_id", "GlobalClusterResourceId": "cluster-unique_string", "GlobalClusterArn": "arn:aws:rds::123456789012:global-cluster:global_cluster_id", "Status": "available", "Engine": "aurora-mysql", "EngineVersion": "5.7.mysql_aurora.2.11.2", "GlobalClusterMembers": [ ... ], "Endpoint": "global_cluster_id.global-unique_string.global.rds.amazonaws.com" } ] }
To view the cluster and reader endpoints for member DB clusters of the global cluster, use the AWS CLI
describe-db-clusters command, as in the
following example. The values returned for Endpoint and ReaderEndpoint are the
cluster and reader endpoints, respectively.
aws rds describe-db-clusters --regionprimary_region--db-cluster-identifierdb_cluster_id{ "DBClusters": [ { "AllocatedStorage": 1, "AvailabilityZones": [ "az_1", "az_2", "az_3" ], "BackupRetentionPeriod": 1, "DBClusterIdentifier": "db_cluster_id", "DBClusterParameterGroup": "default.aurora-mysql5.7", "DBSubnetGroup": "default", "Status": "available", "EarliestRestorableTime": "2023-08-01T18:21:11.301Z", "Endpoint": "db_cluster_id.cluster-unique_string.primary_region.rds.amazonaws.com", "ReaderEndpoint": "db_cluster_id.cluster-ro-unique_string.primary_region.rds.amazonaws.com", "MultiAZ": false, "Engine": "aurora-mysql", "EngineVersion": "5.7.mysql_aurora.2.11.2", "ReadReplicaIdentifiers": [ "arn:aws:rds:secondary_region:123456789012:cluster:db_cluster_id" ], "DBClusterMembers": [ { "DBInstanceIdentifier": "db_instance_id", "IsClusterWriter": true, "DBClusterParameterGroupStatus": "in-sync", "PromotionTier": 1 } ], ... "TagList": [], "GlobalWriteForwardingRequested": false } ] }
To view the global cluster's writer endpoint, use the RDS API DescribeGlobalClusters operation. To view the cluster and reader endpoints for member DB clusters of the global cluster, use the RDS API DescribeDBClusters operation.
Considerations with using Global writer endpoints
You can make effective use of the Aurora Global Database writer endpoints by following these guidelines and best practices:
-
To minimize disruption after a cross-Region failover or switchover, you can set up VPC connectivity between your application compute and your primary and secondary AWS Regions. For example, suppose that you have applications or client systems that are running in the same VPC as the primary cluster. If the secondary cluster is promoted, the global writer endpoint automatically changes to point to that cluster. Although the global writer endpoint lets you avoid changing the connection settings for your application, your applications can't access the IP addresses in the newly promoted primary AWS Region's VPC until you set up networking between the two VPCs. See Amazon VPC-to-Amazon VPC connectivity options to evaluate different options for setting up this connectivity.
-
The global writer endpoint update after a global database failover or switchover can take a long time depending upon your Domain Name Service (DNS) caching duration. See Amazon Aurora MySQL Database Administrator's Handbook to learn more. Aurora Global Database emits an RDS Event when it sees the DNS change on the global writer endpoint. You can use the event to devise strategies to ensure the DNS cache doesn't extend beyond the time after the event is generated. For more information, see DB cluster events.
-
Aurora Global Database replicates data asynchronously. The cross-Region failover methods can result in some write transaction data that wasn't replicated to the chosen secondary before the failover initiated. Although Aurora attempts on best-effort basis to block writes in the original primary AWS Region, failover can be susceptible to split-brain issues. The considerations to minimize data loss and split-brain risk apply to Aurora Global Database writer endpoints as well. For more information, see Performing managed failovers for Aurora global databases.
