Data filtering for Aurora zero-ETL integrations
Aurora zero-ETL integrations support data filtering, which lets you control which data is replicated from your source Aurora DB cluster to your target data warehouse. Instead of replicating the entire database, you can apply one or more filters to selectively include or exclude specific tables. This helps you optimize storage and query performance by ensuring that only relevant data is transferred. Currently, filtering is limited to the database and table levels. Column- and row-level filtering are not supported.
Data filtering can be useful when you want to:
-
Join certain tables from two or more different source clusters, and you don't need complete data from either cluster.
-
Save costs by performing analytics using only a subset of tables rather than an entire fleet of databases.
-
Filter out sensitive information—such as phone numbers, addresses, or credit card details—from certain tables.
You can add data filters to a zero-ETL integration using the AWS Management Console, the AWS Command Line Interface (AWS CLI), or the Amazon RDS API.
If the integration has a provisioned cluster as its target, the cluster must be on patch 180 or higher to use data filtering.
Topics
Format of a data filter
You can define multiple filters for a single integration. Each filter either includes or
excludes any existing and future database tables that match one of the patterns in the filter
expression. Aurora zero-ETL integrations use Maxwell filter syntax
Each filter has the following elements:
| Element | Description |
|---|---|
| Filter type |
An |
| Filter expression |
A comma-separated list of patterns. Expressions must use Maxwell filter syntax |
| Pattern |
A filter pattern in the format
NoteFor Aurora MySQL, regular expressions are supported in both the database and table name. For Aurora PostgreSQL, regular expressions are supported only in the schema and table name, not in the database name. You can't include column-level filters or denylists. A single integration can have a maximum of 99 total patterns. In the console, you can enter patterns within a single filter expression, or spread them out among multiple expressions. A single pattern can't exceed 256 characters in length. |
Important
If you select an Aurora PostgreSQL source DB cluster, you must specify at least one
data filter pattern. At minimum, the pattern must include a single database
(database-name.*.*
The following image shows the structure of Aurora MySQL data filters in the console:
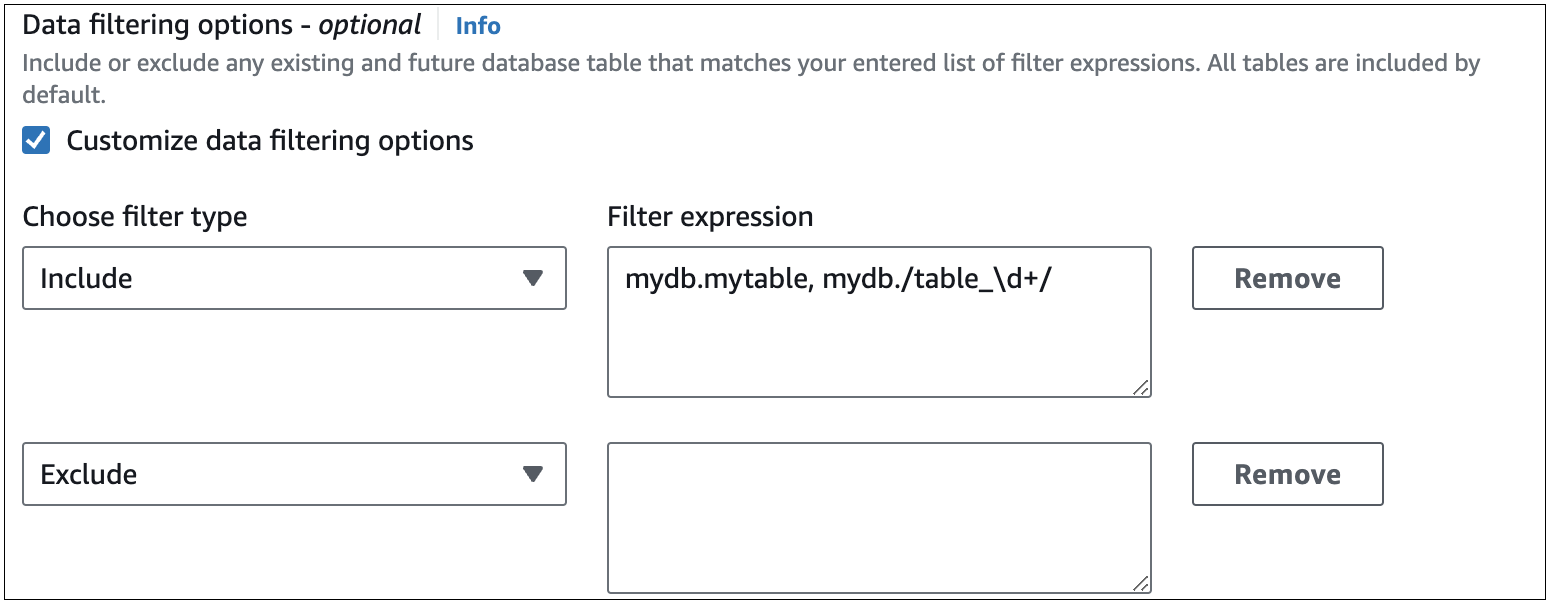
Important
Do not include personally identifying, confidential, or sensitive information in your filter patterns.
Data filters in the AWS CLI
When using the AWS CLI to add a data filter, the syntax differs slightly from the console.
You must assign a filter type (Include or Exclude) to each pattern
individually, so you can't group multiple patterns under one filter type.
For example, in the console you can group the following comma-separated patterns under a
single Include statement:
Aurora MySQL
mydb.mytable,mydb./table_\d+/
Aurora PostgreSQL
mydb.myschema.mytable,mydb.myschema./table_\d+/
However, when using the AWS CLI, the same data filter must be in the following format:
Aurora MySQL
'include:mydb.mytable, include:mydb./table_\d+/'
Aurora PostgreSQL
'include:mydb.myschema.mytable, include:mydb.myschema./table_\d+/'
Filter logic
If you don't specify any data filters in your integration, Aurora assumes a default filter of
include:*.*, which replicates all tables to the target data warehouse. However,
if you add at least one filter, the default logic switches to exclude:*.*, which
excludes all tables by default. This lets you explicitly define which databases and tables to
include in replication.
For example, if you define the following filter:
'include: db.table1, include: db.table2'
Aurora evaluates the filter as follows:
'exclude:*.*, include: db.table1, include: db.table2'
Therefore, Aurora only replicates table1 and table2 from the
database named db to the target data warehouse.
Filter precedence
Aurora evaluates data filters in the order you specify. In the AWS Management Console, it processes filter expressions from left to right and top to bottom. A second filter or an individual pattern that follows the first can override it.
For example, if the first filter is Include books.stephenking, it includes
only the stephenking table from the books database. However, if you
add a second filter, Exclude books.*, it overrides the first filter. This
prevents any tables from the books index from being replicated to the target data warehouse.
When you specify at least one filter, the logic starts by assuming
exclude:*.* by default, which automatically excludes all
tables from replication. As a best practice, define filters from broadest to most specific.
Start with one or more Include statements to specify the data to replicate, then
add Exclude filters to selectively remove certain tables.
The same principle applies to filters that you define using the AWS CLI. Aurora evaluates these filter patterns in the order that you specify them, so a pattern might override one that you specify before it.
Aurora MySQL examples
The following examples demonstrate how data filtering works for Aurora MySQL examples zero-ETL integrations:
-
Include all databases and all tables:
'include: *.*' -
Include all tables within the
booksdatabase:'include: books.*' -
Exclude any tables named
mystery:'include: *.*, exclude: *.mystery' -
Include two specific tables within the
booksdatabase:'include: books.stephen_king, include: books.carolyn_keene' -
Include all tables in the
booksdatabase, except for those containing the substringmystery:'include: books.*, exclude: books./.*mystery.*/' -
Include all tables in the
booksdatabase, except those starting withmystery:'include: books.*, exclude: books./mystery.*/' -
Include all tables in the
booksdatabase, except those ending withmystery:'include: books.*, exclude: books./.*mystery/' -
Include all tables in the
booksdatabase that start withtable_, except for the one namedtable_stephen_king. For example,table_moviesortable_bookswould be replicated, but nottable_stephen_king.'include: books./table_.*/, exclude: books.table_stephen_king'
Aurora PostgreSQL examples
The following examples demonstrate how data filtering works for Aurora PostgreSQL zero-ETL integrations:
-
Include all tables within the
booksdatabase:'include: books.*.*' -
Exclude any tables named
mysteryin thebooksdatabase:'include: books.*.*, exclude: books.*.mystery' -
Include one table within the
booksdatabase in themysteryschema, and one table withinemployeedatabase in thefinanceschema:'include: books.mystery.stephen_king, include: employee.finance.benefits' -
Include all tables in the
booksdatabase andscience_fictionschema, except for those containing the substringking:'include: books.science_fiction.*, exclude: books.*./.*king.*/ -
Include all tables in the
booksdatabase, except those with a schema name starting withsci:'include: books.*.*, exclude: books./sci.*/.*' -
Include all tables in the
booksdatabase, except those in themysteryschema ending withking:'include: books.*.*, exclude: books.mystery./.*king/' -
Include all tables in the
booksdatabase that start withtable_, except for the one namedtable_stephen_king. For example,table_moviesin thefictionschema andtable_booksin themysteryschema are replicated, but nottable_stephen_kingin either schema:'include: books.*./table_.*/, exclude: books.*.table_stephen_king'
Adding data filters to an integration
You can configure data filtering using the AWS Management Console, the AWS CLI, or the Amazon RDS API.
Important
If you add a filter after you create an integration, Aurora treats it as if it always existed. It removes any data in the target data warehouse that doesn’t match the new filtering criteria and resynchronizes all affected tables.
To add data filters to a zero-ETL integration
Sign in to the AWS Management Console and open the Amazon RDS console at https://console.aws.amazon.com/rds/
. -
In the navigation pane, choose Zero-ETL integrations. Select the integration that you want to add data filters to, and then choose Modify.
-
Under Source, add one or more
IncludeandExcludestatements.The following image shows an example of data filters for a MySQL integration:
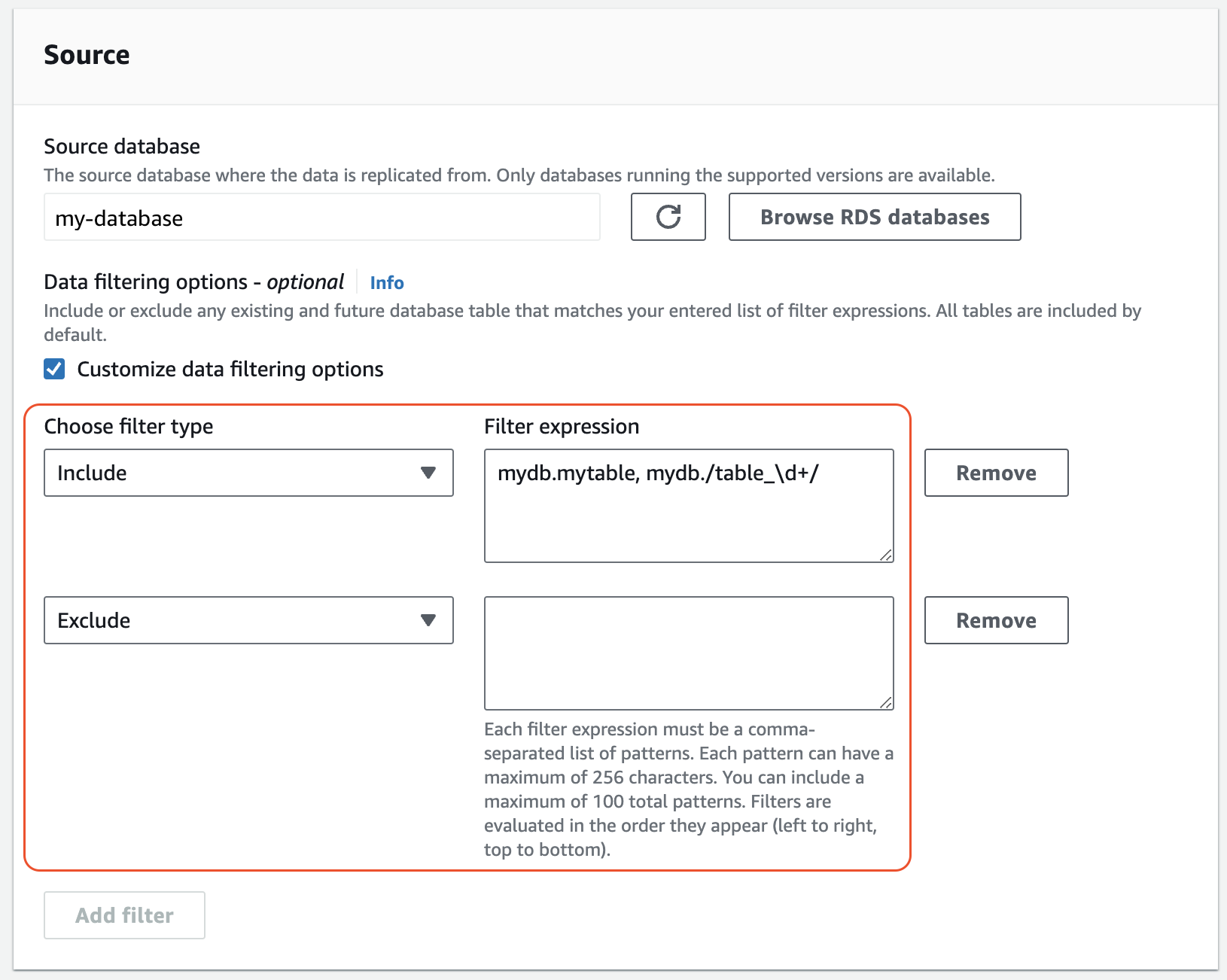
-
When you're satisfied with the changes, choose Continue and Save changes.
To add data filters to a zero-ETL integration using the AWS CLI, call the modify-integration--data-filter parameter with a comma-separated list of
Include and Exclude Maxwell filters.
Example
The following example adds filter patterns to my-integration.
For Linux, macOS, or Unix:
aws rds modify-integration \ --integration-identifiermy-integration\ --data-filter'include: foodb.*, exclude: foodb.tbl, exclude: foodb./table_\d+/'
For Windows:
aws rds modify-integration ^ --integration-identifiermy-integration^ --data-filter'include: foodb.*, exclude: foodb.tbl, exclude: foodb./table_\d+/'
To modify a zero-ETL integration using the RDS API, call the ModifyIntegration operation. Specify the integration identifier and provide a comma-separated list of filter patterns.
Removing data filters from an integration
When you remove a data filter from an integration, Aurora reevaluates the remaining filters as if the removed filter never existed. It then replicates any previously excluded data that now meets the criteria into the target data warehouse. This triggers a resynchronization of all affected tables.
