Amazon RDS zero-ETL integrations
An Amazon RDS zero-ETL integration with Amazon Redshift and Amazon SageMaker AI enables near real-time analytics and machine learning (ML) using data from RDS. It's a fully managed solution for making transactional data available in your analytics destination after it is written to an RDS database. Extract, transform, and load (ETL) is the process of combining data from multiple sources into a large, central data warehouse.
A zero-ETL integration makes the data in your RDS database available in Amazon Redshift or an Amazon SageMaker AI lakehouse in near real-time. Once that data is in the target data warehouse or data lake, you can power your analytics, ML, and AI workloads using the built-in capabilities, such as machine learning, materialized views, data sharing, federated access to multiple data stores and data lakes, and integrations with Amazon SageMaker AI, Quick, and other AWS services.
To create a zero-ETL integration, you specify an RDS database as the source, and a supported data warehouse or lakehouse as the target. The integration replicates data from the source database into the target data warehouse or lakehouse.
The following diagram illustrates this functionality for zero-ETL integration with Amazon Redshift:
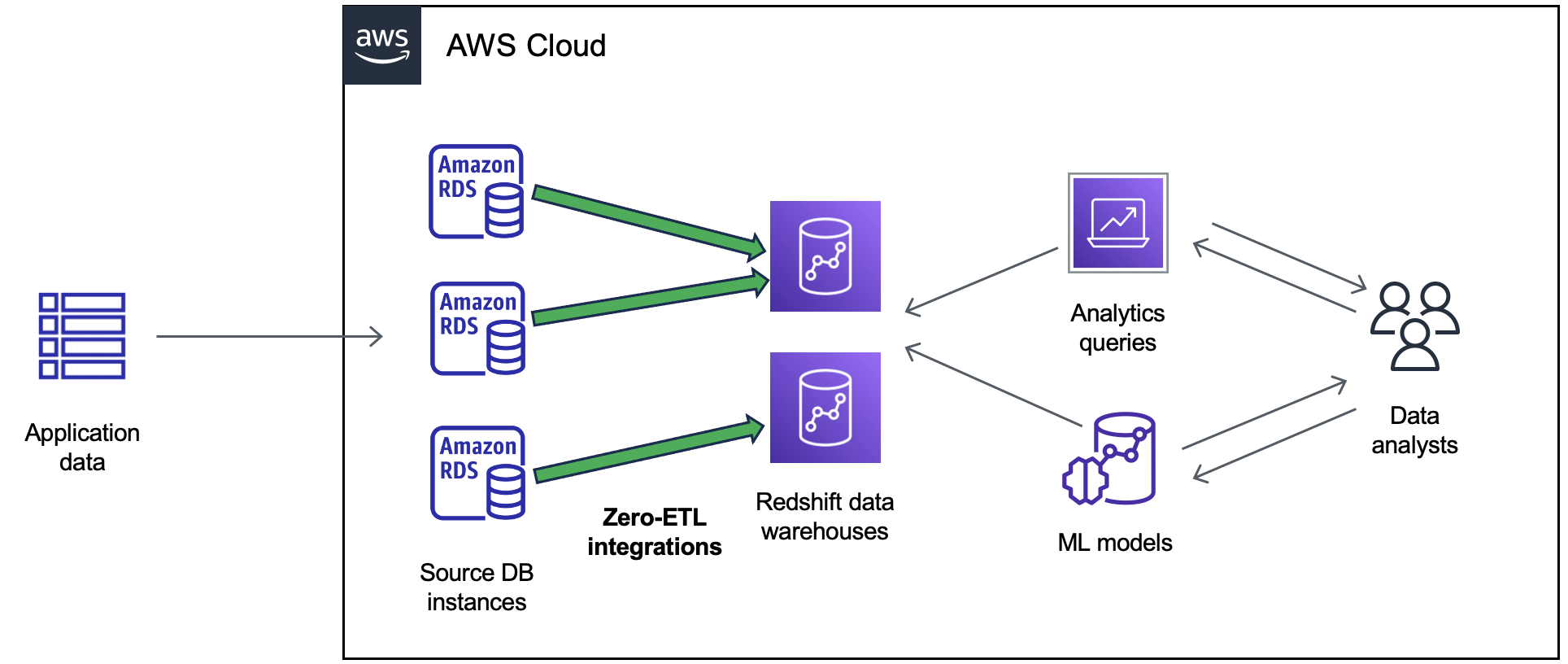
The following diagram illustrates this functionality for zero-ETL integration with an Amazon SageMaker AI lakehouse:

The integration monitors the health of the data pipeline and recovers from issues when possible. You can create integrations from multiple RDS databases into a single target data warehouse or lakehouse enabling you to derive insights across multiple applications.
Topics
Benefits
RDS zero-ETL integrations have the following benefits:
-
Help you derive holistic insights from multiple data sources.
-
Eliminate the need to build and maintain complex data pipelines that perform extract, transform, and load (ETL) operations. Zero-ETL integrations remove the challenges that come with building and managing pipelines by provisioning and managing them for you.
-
Reduce operational burden and cost, and let you focus on improving your applications.
-
Let you leverage the target destination's analytics and ML capabilities to derive insights from transactional and other data, to respond effectively to critical, time-sensitive events.
Key concepts
As you get started with zero-ETL integrations, consider the following concepts:
- Integration
-
A fully managed data pipeline that automatically replicates transactional data and schemas from an RDS database to a data warehouse or catalog.
- Source database
-
The RDS database where data is replicated from. You can specify a Single-AZ or Multi-AZ DB instance, or a Multi-AZ DB cluster (for RDS for MySQL only).
- Target
-
The data warehouse or lakehouse where the data is replicated to. There are two types of data warehouse: a provisioned cluster data warehouse and a serverless data warehouse. A provisioned cluster data warehouse is a collection of computing resources called nodes, which are organized into a group called a cluster. A serverless data warehouse is comprised of a workgroup that stores compute resources, and a namespace that houses the database objects and users. Both data warehouses run an analytics engine and contain one or more databases.
A target lakehouse consists of catalogs, databases, tables, and views. For more information about lakehouse architecture, see SageMaker Lakehouse components in the Amazon SageMaker AI Unified Studio User Guide.
Multiple source databases can write to the same target.
For more information, see Data warehouse system architecture in the Amazon Redshift Developer Guide.
Limitations
The following limitations apply to RDS zero-ETL integrations.
Topics
General limitations
-
The source database must be in the same Region as the target.
-
You can't rename a database if it has existing integrations.
-
You can't create multiple integrations between the same source and target databases.
-
You can't delete a database that has existing integrations. You must delete all associated integrations first.
-
If you stop the source database, the last few transactions might not be replicated to the target until you resume the database.
-
You can’t delete an integration if the source database is stopped.
-
If your database is the source of a blue/green deployment, the blue and green environments can't have existing zero-ETL integrations during switchover. You must delete the integration first and switch over, then recreate it.
-
You can't create an integration for a source database that has another integration being actively created.
-
When you initially create an integration, or when a table is being resynchronized, data seeding from the source to the target can take 20-25 minutes or more depending on the size of the source database. This delay can lead to increased replica lag.
-
Some data types aren't supported. For more information, see Data type differences between RDS and Amazon Redshift databases.
-
System tables, temporary tables, and views aren't replicated to target warehouses.
-
Performing DDL commands (for example
ALTER TABLE) on a source table can trigger a table resynchronization, making the table unavailable for querying while it's resynchronizing. For more information, see One or more of my Amazon Redshift tables requires a resync.
RDS for MySQL limitations
-
Your source database must be running a supported version of RDS for MySQL. For a list of supported versions, see Supported Regions and DB engines for Amazon RDS zero-ETL integrations.
-
Zero-ETL integrations are not supported on both the primary instance and a read replica instance in the same AWS Region.
-
Zero-ETL integrations rely on MySQL binary logging (binlog) to capture ongoing data changes. Don't use binlog-based data filtering, as it can cause data inconsistencies between the source and target databases.
-
Zero-ETL integrations are supported only for databases configured to use the InnoDB storage engine.
-
Foreign key references with predefined table updates aren't supported. Specifically,
ON DELETEandON UPDATErules aren't supported withCASCADE,SET NULL, andSET DEFAULTactions. Attempting to create or update a table with such references to another table will put the table into a failed state. -
You can't create an integration for a source database that uses magnetic storage.
RDS for PostgreSQL limitations
-
The source database must be an RDS for PostgreSQL instance running version 15.7+, 16.3+, or 17.1+. Earlier versions are not supported.
-
RDS for PostgreSQL zero-ETL integrations don't support Multi-AZ DB clusters as source databases.
-
You can't create a zero-ETL integration from an RDS for PostgreSQL read replica instance.
-
PostgreSQL unlogged tables and materialized views are not replicated to Amazon Redshift.
-
Replication of certain PostgreSQL data types, such as geometry data types
and data greater than 64KB, is not supported due to limitations in Amazon Redshift. For more information about data type differences between RDS for PostgreSQL and Amazon Redshift, see RDS for PostgreSQL in the Data type differences section. -
You can't perform a major version upgrade on the source RDS for PostgreSQL instance while it has an active zero-ETL integration. To upgrade the source instance, you must first delete all existing zero-ETL integrations. After the major version upgrade is complete, you can recreate the zero-ETL integrations.
-
If you perform declarative partitioning
transactions on the source DB instance, all affected tables enter a failed state and are no longer accessible. -
If
max_slot_wal_keep_sizeis set to a finite value on the source RDS for PostgreSQL instance, the logical replication slot used by the integration can be invalidated when WAL retention exceeds that size. An invalidated slot stops replication and the integration cannot recover without recreation. We recommend leavingmax_slot_wal_keep_sizeat its PostgreSQL default of-1(unlimited), or setting it large enough to accommodate WAL generated during integration bootstrap and transient lag.
RDS for Oracle limitations
-
The source database must be an RDS for Oracle instance running version 19c Enterprise Edition or Standard Edition 2, July 2019 Release Update or later. Earlier versions are not supported.
-
You can't create a zero-ETL integration from an RDS for Oracle read replica instance.
-
You can't rename a tenant database when there is a zero-ETL integration on that tenant database.
-
A tenant database can have only one zero-ETL integration.
-
RDS for Oracle and Amazon Redshift have some data type differences. For more information, see RDS for Oracle in the Data type differences section.
Amazon Redshift limitations
For a list of Amazon Redshift limitations related to zero-ETL integrations, see Considerations when using zero-ETL integrations with Amazon Redshift in the Amazon Redshift Management Guide.
Amazon SageMaker AI lakehouse limitations
Following is a limitation for Amazon SageMaker AI lakehouse zero-ETL integrations.
-
Catalog names are limited to 19 characters in length.
Quotas
Your account has the following quotas related to RDS zero-ETL integrations. Each quota is per-Region unless otherwise specified.
| Name | Default | Description |
|---|---|---|
| Integrations | 100 | The total number of integrations within an AWS account. |
| Integrations per target | 50 | The number of integrations sending data to a single target data warehouse or lakehouse. |
| Integrations per source instance | 5 | The number of integrations sending data from a single source DB instance. |
In addition, the target warehouse places certain limits on the number of tables allowed in each DB instance or cluster node. For more information about Amazon Redshift quotas and limits, see Quotas and limits in Amazon Redshift in the Amazon Redshift Management Guide.
Supported Regions
RDS zero-ETL integrations are available in a subset of AWS Regions. For a list of supported Regions, see Supported Regions and DB engines for Amazon RDS zero-ETL integrations.
