Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Anzeigen detaillierter Serviceaktivitäten und des Betriebsstatus auf der Servicedetailseite
Wenn Sie Ihre Anwendung instrumentieren, ordnet Amazon CloudWatch Application Signals alle Dienste zu, die Ihre Anwendung erkennt. Auf der Servicedetailseite erhalten Sie einen Überblick über Ihre Services, Operationen, Abhängigkeiten, Canarys und Client-Anforderungen für einen einzelnen Service. Gehen Sie wie folgt vor, um Servicedetailseite aufzurufen:
-
Öffnen Sie die CloudWatch -Konsole
. -
Wählen Sie im linken Navigationsbereich im Abschnitt Application Signals die Option Services aus.
-
Wählen Sie den Namen eines beliebigen Service aus den Tabellen Services, Top-Services oder „Abhängigkeiten“ aus.
Unter schedule-visits sehen Sie das Kontolabel und die ID unter dem Namen des Service.
Die Servicedetailseite ist in vier Registerkarten unterteilt:
-
Überblick: Auf dieser Registerkarte sehen Sie einen einzelnen Service, einschließlich der Anzahl der Operationen, Abhängigkeiten, Synthetics und Client-Seiten. Auf der Registerkarte werden die wichtigsten Metriken für Ihren gesamten Service, die wichtigsten Operationen und Abhängigkeiten angezeigt. Zu diesen Metriken gehören Zeitreihendaten zu Latenz, Störungen und Fehlern bei allen Serviceoperationen für diesen Service.
-
Serviceoperationen: Auf dieser Registerkarte sehen Sie eine Liste der von Ihrem Service aufgerufenen Operationen und interaktive Diagramme mit wichtigen Metriken zur Messung des Zustands der einzelnen Operationen. Sie können einen Datenpunkt in einem Diagramm auswählen, um Informationen zu Ablaufverfolgungen, Protokollen oder Metriken abzurufen, die mit diesem Datenpunkt verknüpft sind.
-
Abhängigkeiten: Auf dieser Registerkarte sehen Sie eine Liste der von Ihrem Service aufgerufenen Abhängigkeiten sowie eine Liste von Metriken für diese Abhängigkeiten.
-
Synthetics-Canarys: Auf dieser Registerkarte finden Sie eine Liste von Synthetics-Canarys, die Benutzeraufrufe an Ihren Service simulieren, sowie wichtige Leistungsmetriken für diese Canarys.
-
Client-Seiten: Auf dieser Registerkarte finden Sie eine Liste von Client-Seiten, die Ihren Service aufrufen, sowie Metriken zur Messung der Qualität der Client-Interaktionen mit Ihrer Anwendung.
-
Zugehörige Metriken: Auf dieser Registerkarte können Sie zugehörige Metriken korrelieren, z. B. Standardmetriken, Laufzeitmetriken und benutzerdefinierte Metriken für einen Service, seine Operationen oder Abhängigkeiten.
Aufrufen Ihrer Serviceübersicht
Auf der Seite mit der Serviceübersicht können Sie sich eine allgemeine Zusammenfassung der Metriken für alle Serviceoperationen an einem einzigen Standort ansehen. Überprüfen Sie die Leistung aller Operationen, Abhängigkeiten, Client-Seiten und Synthetics-Canarys, die mit Ihrer Anwendung interagieren. Anhand dieser Informationen können Sie ermitteln, worauf Sie sich konzentrieren sollten, um Probleme zu identifizieren, Fehler zu beheben und Optimierungsmöglichkeiten zu finden.
Wählen Sie unter Servicedetails einen Link aus, um Informationen zu einem bestimmten Service anzuzeigen. Für Services, die in Amazon EKS gehostet werden, sehen Sie auf der Seite mit den Servicedetails beispielsweise Informationen zu Cluster, Namespace und Workload. Für Services, die in Amazon ECS oder Amazon EC2 gehostet werden, wird auf der Seite mit den Servicedetails der Wert Umgebung angezeigt.
Unter Services auf der Registerkarte Überblick wird eine Zusammenfassung der folgenden Informationen angezeigt:
-
Operationen: Auf dieser Registerkarte können Sie den Zustand Ihrer Serviceoperationen einsehen. Der Zustand wird durch Service Level Indicators (SLIs) bestimmt, die als Teil eines Service Level Objective (SLO) definiert sind.
-
Abhängigkeiten: Auf dieser Registerkarte finden Sie die wichtigsten Abhängigkeiten der von Ihrer Anwendung aufgerufenen Services, aufgelistet nach Fehlerrate, sowie den Zustand Ihrer Serviceabhängigkeiten. Der Zustand wird durch Service Level Indicators (SLIs) bestimmt, die als Teil eines Service Level Objective (SLO) definiert sind.
-
Synthetics-Canarys: Auf dieser Registerkarte sehen Sie das Ergebnis simulierter Aufrufe von Endpunkten oder APIs, die mit Ihrem Service verknüpft sind, sowie die Anzahl der fehlgeschlagenen Canarys.
-
Kundenseiten — Verwenden Sie diese Registerkarte, um die wichtigsten Seiten zu sehen, die von Clients aufgerufen wurden, bei denen asynchrone Fehler JavaScript und XML- (AJAX-) Fehler aufgetreten sind.
Die folgende Abbildung zeigt einen Überblick über Ihre Services:

Auf der Registerkarte Überblick wird außerdem ein Diagramm der Abhängigkeiten mit der höchsten Latenz für alle Services angezeigt. Verwenden Sie die Latenzmetriken p99, p90 und p50, um schnell zu bewerten, welche Abhängigkeiten zur gesamten Servicelatenz beitragen:

Das obige Diagramm zeigt beispielsweise, dass 99 % der Anforderungen, die an die Abhängigkeit customer-service gesendet wurden, in etwa 4.950 Millisekunden abgeschlossen wurden. Die anderen Abhängigkeiten nahmen weniger Zeit in Anspruch.
Diagramme, die die vier Top-Serviceoperationen nach Latenz darstellen, zeigen das Volumen der Anforderungen, die Verfügbarkeit, die Störungsrate und die Fehlerquote für diese Services, wie im folgenden Bild zu sehen ist:

Im Abschnitt Servicedetails werden die Details des Service angezeigt, einschließlich Konto-ID und Kontolabel.
Ihre Service-Vorgänge anzeigen
Wenn Sie Ihre Anwendung instrumentieren, erkennt Application Signals alle Serviceoperationen, die Ihre Anwendung aufruft. Auf der Registerkarte Serviceoperationen sehen Sie eine Tabelle mit Serviceoperationen und Metriken, mit denen die Leistung einer ausgewählten Operation gemessen wird. Zu diesen Metriken gehören der SLI-Status, die Anzahl der Abhängigkeiten, Latenz, Volumen, Störungen, Fehler und Verfügbarkeit, wie im folgenden Bild zu sehen ist:
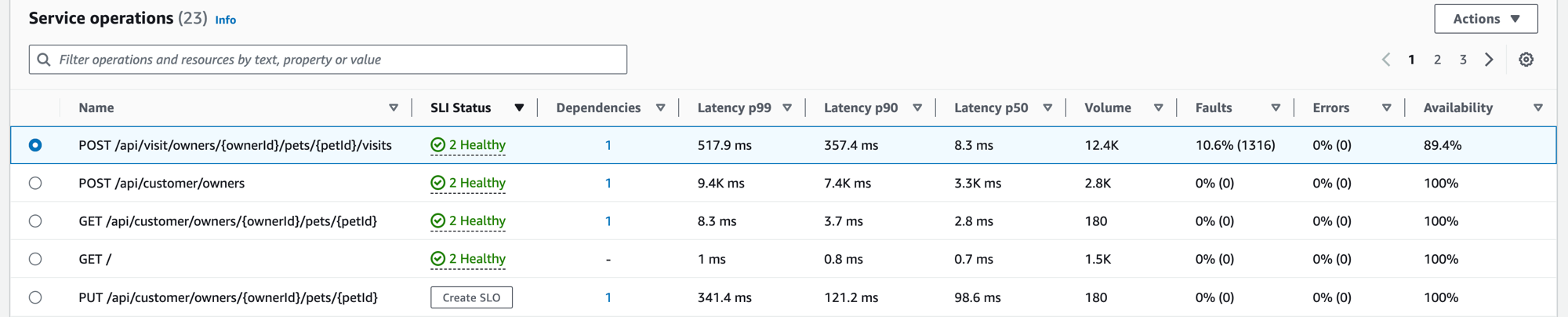
Filtern Sie die Tabelle, um die Suche nach einer Serviceoperation zu erleichtern. Wählen Sie dazu eine oder mehrere Eigenschaften aus dem Filter-Textfeld aus. Bei der Auswahl der einzelnen Eigenschaften werden Sie durch die Filter-Kriterien geführt und der vollständige Filter wird unter dem Filter-Textfeld angezeigt. Sie können jederzeit Filter löschen auswählen, um den Tabellenfilter zu entfernen.
Wählen Sie den SLI-Status für eine Operation aus, um ein Popup mit einem Link zu einer fehlerhaften SLIs und einem Link zu allen SLOs für die Operation anzuzeigen, wie in der folgenden Tabelle zu sehen ist.
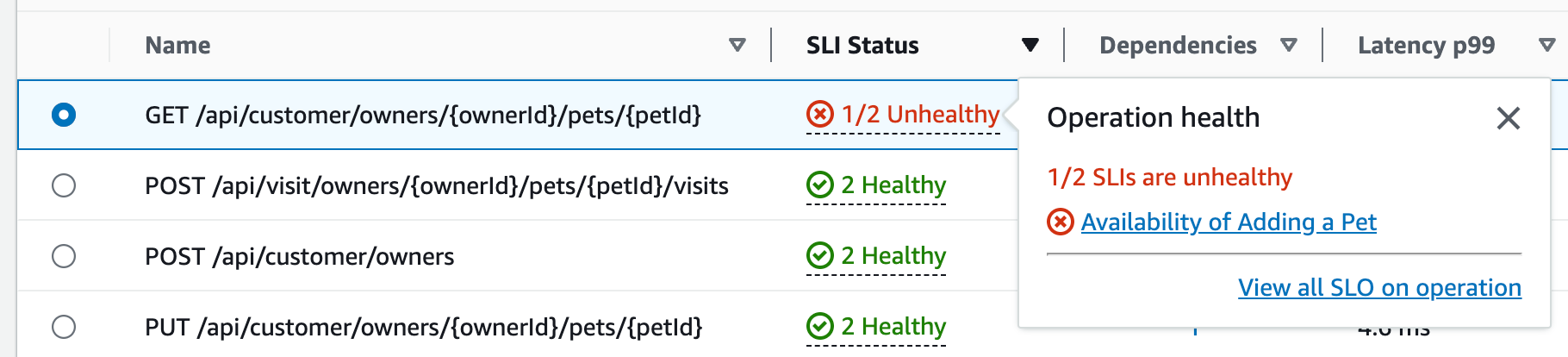
In der Tabelle mit den Serviceoperationen werden der SLI-Status, die Anzahl der fehlerfreien oder fehlerhaften SLIs und die Gesamtzahl der SLOs für jede Operation aufgeführt.
Anhand von SLIs können Sie die Latenz, die Verfügbarkeit und andere Betriebsmetriken überwachen, mit denen der Betriebszustand eines Service gemessen wird. Mit einem SLO können Sie die Leistung und den Zustand Ihrer Services und Operationen prüfen.
Gehen Sie wie folgt vor, um ein SLO zu erstellen:
-
Wenn für eine Operation keine SLOs erstellt wurden, wählen Sie in der Spalte SLI-Status die Schaltfläche SLO erstellen aus.
-
Wenn für eine Operation bereits ein SLO vorhanden ist, gehen Sie wie folgt vor:
-
Wählen Sie das Optionsfeld neben dem Namen der Operation aus.
-
Wählen Sie über den Abwärtspfeil Aktionen oben rechts in der Tabelle die Option SLO erstellen aus.
-
Weitere Informationen finden Sie unter Servicelevel-Ziele (SLOs).
In der Spalte Abhängigkeiten wird die Anzahl der Abhängigkeiten angezeigt, die dieser Vorgang aufruft. Wählen Sie diese Zahl, um die Registerkarte Abhängigkeiten zu öffnen, die nach dem ausgewählten Vorgang gefiltert ist.
Anzeigen von Metriken zu Serviceoperationen, korrelierten Ablaufverfolgungen und Anwendungsprotokollen
Application Signals korreliert die Kennzahlen des Servicebetriebs mit AWS X-Ray Traces, CloudWatch Container Insights und Anwendungsprotokollen. Verwenden Sie diese Metriken, um Probleme mit dem Betriebszustand zu beheben. Gehen Sie wie folgt vor, um Metriken als grafische Informationen anzuzeigen:
-
Wählen Sie in der Tabelle Serviceoperationen eine Serviceoperation aus, um oberhalb der Tabelle eine Reihe von Diagrammen für die ausgewählte Operation anzuzeigen, mit Metriken für Volumen und Verfügbarkeit, Latenz sowie Störungen und Fehler.
-
Bewegen Sie den Mauszeiger auf einen Punkt in einem Diagramm, um weitere Informationen zu sehen.
-
Wählen Sie einen Punkt aus, um einen Diagnosebereich zu öffnen, in dem korrelierte Ablaufverfolgungen, Metriken und Anwendungsprotokolle für den ausgewählten Punkt im Diagramm angezeigt werden.
Das folgende Bild zeigt den Tooltip, der eingeblendet wird, wenn Sie den Mauszeiger auf einen Punkt im Diagramm bewegen, und den Diagnosebereich, der angezeigt wird, wenn Sie auf einen Punkt klicken. Der Tooltip enthält Informationen zum zugehörigen Datenpunkt im Diagramm Störungen und Fehler. Der Bereich enthält korrelierte Ablaufverfolgungen, wichtigste Faktoren und Anwendungsprotokolle zum ausgewählten Punkt.
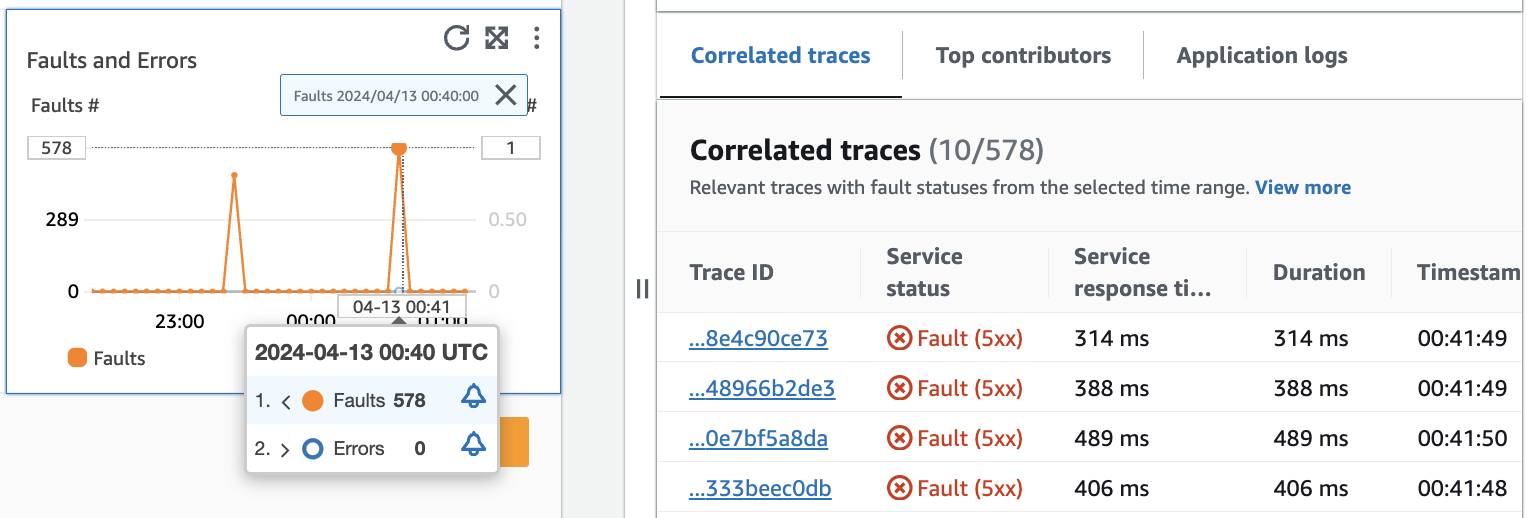
Korrelierte Ablaufverfolgungen
Zugehörige Ablaufverfolgungen ansehen, um das zugrunde liegende Problem mit einer Ablaufverfolgung zu ermitteln. Sie können überprüfen, ob sich korrelierte Ablaufverfolgungen oder damit zusammenhängende Serviceknoten ähnlich verhalten. Um korrelierte Traces zu untersuchen, wählen Sie eine Trace-ID aus der Tabelle Korrelierte Traces aus, um die Seite mit den X-Ray Trace-Details für die gewählte Trace zu öffnen. Die Seite mit den Ablaufverfolgungsdetails enthält eine Übersicht der Serviceknoten, die der ausgewählten Ablaufverfolgung zugeordnet sind, sowie eine Zeitleiste mit Ablaufverfolgungssegmenten.
Wichtigste Faktoren
Wichtigste Faktoren ansehen, um die Haupt-Eingabequellen für eine Metrik zu finden. Gruppieren Sie die Faktoren nach verschiedenen Komponenten, um nach Ähnlichkeiten innerhalb der Gruppe zu suchen und zu verstehen, wie sich das Ablaufverfolgungsverhalten zwischen den Faktoren unterscheidet.
Auf der Registerkarte Wichtigste Faktoren finden Sie Metriken für Aufrufvolumen, Verfügbarkeit, durchschnittliche Latenz, Fehler und Störungen für jede Gruppe. Das folgende Beispielbild zeigt die wichtigsten Faktoren für eine Reihe von Metriken für eine Anwendung, die auf einer Amazon-EKS-Plattform bereitgestellt wurde:
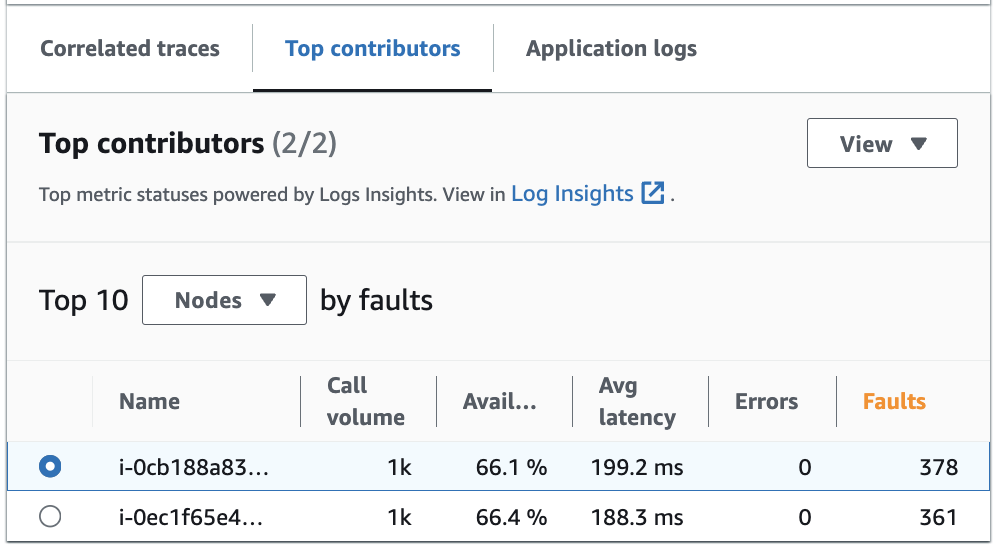
Die wichtigsten Faktoren enthalten die folgenden Metriken:
-
Aufrufvolumen: Anhand des Aufrufvolumens können Sie die Anzahl der Anforderungen pro Zeitintervall für eine Gruppe ermitteln.
-
Verfügbarkeit: Mithilfe der Verfügbarkeit können Sie sehen, wie lange (in Prozent) für eine Gruppe keine Störungen festgestellt wurden.
-
Durchschnittliche Latenz: Anhand der Latenz können Sie die durchschnittliche Dauer ausgeführter Anforderungen für eine Gruppe in einem Zeitintervall überprüfen, das davon abhängt, wie lange es her ist, dass die untersuchten Anforderungen gestellt wurden. Anforderungen, die vor weniger als 15 Tagen gestellt wurden, werden in Intervallen von 1 Minute ausgewertet. Anforderungen, die vor 15 bis 30 Tagen gestellt wurden, werden in Intervallen von 5 Minuten ausgewertet. Wenn Sie beispielsweise Anforderungen untersuchen, die vor 15 Tagen eine Störung verursacht haben, entspricht die Metrik für das Aufrufvolumen der Anzahl der Anforderungen pro 5-Minuten-Intervall.
-
Fehler: Die Anzahl der Fehler pro Gruppe, die über ein Zeitintervall gemessen wurden.
-
Störungen: Die Anzahl der Störungen pro Gruppe über ein Zeitintervall.
Wichtigste Faktoren mit Amazon EKS oder Kubernetes
Verwenden Sie Informationen über die wichtigsten Mitwirkenden für Anwendungen, die auf Amazon EKS bereitgestellt werdenKubernetes, oder um nach Knoten, Pod und Knoten gruppierte Betriebszustandsmetriken anzuzeigen PodTemplateHash. Es gelten folgende Definitionen:
-
Ein Pod ist eine Gruppe von einem oder mehreren Docker-Containern, die sich Speicher und Ressourcen teilen. Ein Pod ist die kleinste Einheit, die auf einer Kubernetes-Plattform bereitgestellt werden kann. Gruppieren Sie nach Pods, um zu überprüfen, ob Fehler mit Pod-spezifischen Einschränkungen zusammenhängen.
-
Ein Knoten ist ein Server, auf dem Pods ausgeführt werden. Gruppieren Sie nach Knoten, um zu überprüfen, ob Fehler mit knotenspezifischen Einschränkungen zusammenhängen.
-
Ein Pod-Template-Hash wird verwendet, um eine bestimmte Version einer Bereitstellung zu finden. Gruppieren Sie nach Pod-Template-Hash, um zu überprüfen, ob Fehler mit einer bestimmten Bereitstellung zusammenhängen.
Wichtigste Faktoren mit Amazon EC2
Verwenden Sie Informationen zu den wichtigsten Faktoren für Anwendungen, die in Amazon EKS bereitgestellt sind, um nach Instance-ID und Auto-Scaling-Gruppe gruppierte Betriebszustandsmetriken anzuzeigen. Es gelten folgende Definitionen:
-
Eine Instance-ID ist eine eindeutige ID für die Amazon-EC2-Instance, die Ihr Service ausführt. Gruppieren Sie nach Instance-ID, um zu überprüfen, ob Fehler mit einer bestimmten Amazon-EC2-Instance zusammenhängen.
-
Eine Auto-Scaling-Gruppe ist eine Sammlung von Amazon-EC2-Instances, mit denen Sie die Ressourcen, die Sie für die Bearbeitung Ihrer AnwendungsAnforderungen benötigen, hoch- oder herunterskalieren können. Gruppieren Sie nach Auto-Scaling-Gruppe, wenn Sie überprüfen möchten, ob Fehler auf die Instances innerhalb der Gruppe beschränkt sind.
Wichtigste Faktoren mit einer benutzerdefinierten Plattform
Verwenden Sie Informationen zu den wichtigsten Faktoren für Anwendungen, die mit benutzerdefinierter Instrumentierung bereitgestellt sind, um nach Hostname gruppierte Betriebszustandsmetriken anzuzeigen. Es gelten folgende Definitionen:
-
Ein Hostname identifiziert ein Gerät, z. B. einen Endpunkt oder eine Amazon-EC2-Instance, die mit einem Netzwerk verbunden ist. Gruppieren Sie nach Hostnamen, um zu überprüfen, ob Fehler mit einem bestimmten physischen oder virtuellen Gerät zusammenhängen.
Wichtigste Faktoren in Log Insights und Container Insights ansehen
In Log Insights können Sie die automatische Abfrage, die Metriken für Ihre wichtigsten Faktoren generiert hat, anzeigen und bearbeiten. In Container Insights können Sie Metriken zur Infrastrukturleistung nach Gruppen wie Pods oder Knoten anzeigen. Sie können Cluster, Knoten oder Workloads nach Ressourcenverbrauch sortieren. Dadurch können Anomalien schnell identifiziert und Risiken proaktiv gemindert werden, bevor das Benutzererlebnis beeinträchtigt wird. In diesem Bild sehen Sie, wie Sie diese Optionen auswählen können:
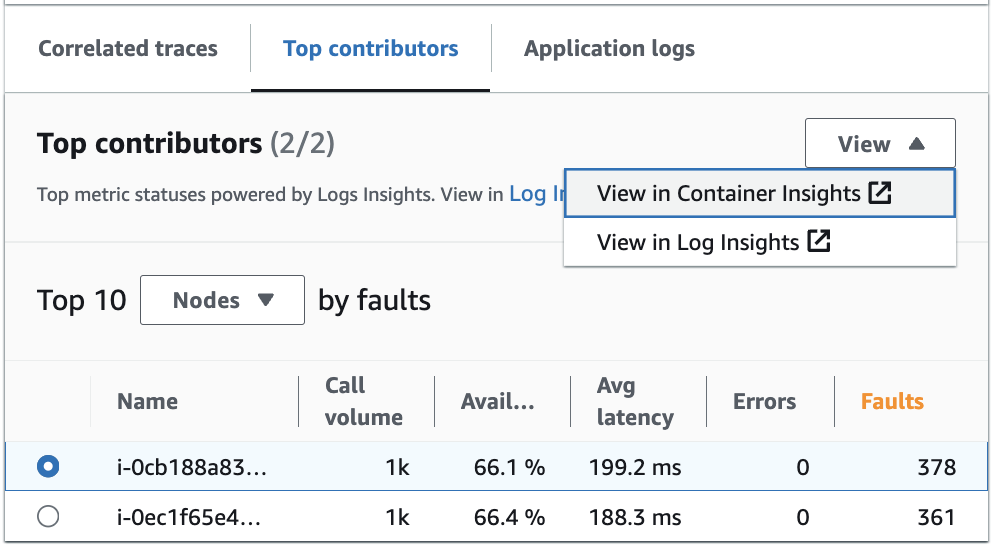
In Container Insights können Sie Metriken für Ihren Amazon-EKS- oder Amazon-ECS-Container einsehen, die spezifisch für die Gruppierung Ihrer wichtigsten Faktoren sind. Wenn Sie für einen EKS-Container beispielsweise nach Pod gruppiert haben, um die wichtigsten Faktoren zu generieren, zeigt Container Insights für Ihren Pod gefilterte Metriken und Statistiken an.
In Log Insights können Sie die Abfrage, die die Metriken generiert hat, unter Wichtigste Faktoren wie folgt ändern:
-
Wählen Sie In Log Insights anzeigen aus. Die Logs Insights-Seite, die geöffnet wird, enthält eine automatisch generierte Abfrage, die die folgenden Informationen enthält:
-
den Namen der Protokoll-Cluster-Gruppe
-
Die Operation, mit der Sie ermittelt haben CloudWatch.
-
die Zusammenfassung der Betriebszustandsmetrik, mit der im Diagramm interagiert wurde
Die Protokollergebnisse werden automatisch gefiltert, um die Daten der letzten fünf Minuten anzuzeigen, bevor Sie den Datenpunkt im Servicediagramm auswählen.
-
-
Zum Bearbeiten der Abfrage ersetzen Sie den generierten Text durch Ihre Änderungen. Mit dem Abfragegenerator können Sie auch eine neue Abfrage generieren oder die bestehende Abfrage aktualisieren.
Anwendungsprotokolle
Verwenden Sie die Abfrage auf der Registerkarte Anwendungsprotokolle, um protokollierte Informationen für Ihre aktuelle Protokollgruppe und Ihren aktuellen Service zu generieren und einen Zeitstempel einzufügen. Eine Protokollgruppe ist eine Gruppe von Protokollstreams, die Sie beim Konfigurieren Ihrer Anwendung definieren können.
Mit einer Protokollgruppe können Sie Protokolle mit ähnlichen Merkmalen organisieren, zum Beispiel folgende:
-
Protokolle von einer bestimmten Organisation, Quelle oder Funktion
-
Protokolle, die von einem bestimmten Benutzer aufgerufen werden
-
Protokolle für einen bestimmten Zeitraum
Verwenden Sie diese Protokollstreams, um bestimmte Gruppen oder Zeitrahmen im Blick zu behalten. Sie können auch Überwachungsregeln, Alarme und Benachrichtigungen für diese Protokollgruppen einrichten. Informationen zu Protokollgruppen finden Sie unter Arbeiten mit Protokollgruppen und Protokollstreams.
Die Abfrage der Anwendungsprotokolle gibt die Protokolle, die wiederkehrenden Textmuster und die grafischen Visualisierungen Ihrer Protokollgruppen zurück.
Um die Abfrage auszuführen, wählen Sie Abfrage in Logs Insights ausführen aus, um die automatisch generierte Abfrage auszuführen oder die Abfrage zu ändern. Zum Bearbeiten der Abfrage ersetzen Sie den automatisch generierten Text durch Ihre Änderungen. Mit dem Abfragegenerator können Sie auch eine neue Abfrage generieren oder die bestehende Abfrage aktualisieren.
Das folgende Bild zeigt die Beispielabfrage, die auf der Grundlage des ausgewählten Punkts im Servicebetriebsdiagramm automatisch generiert wird:
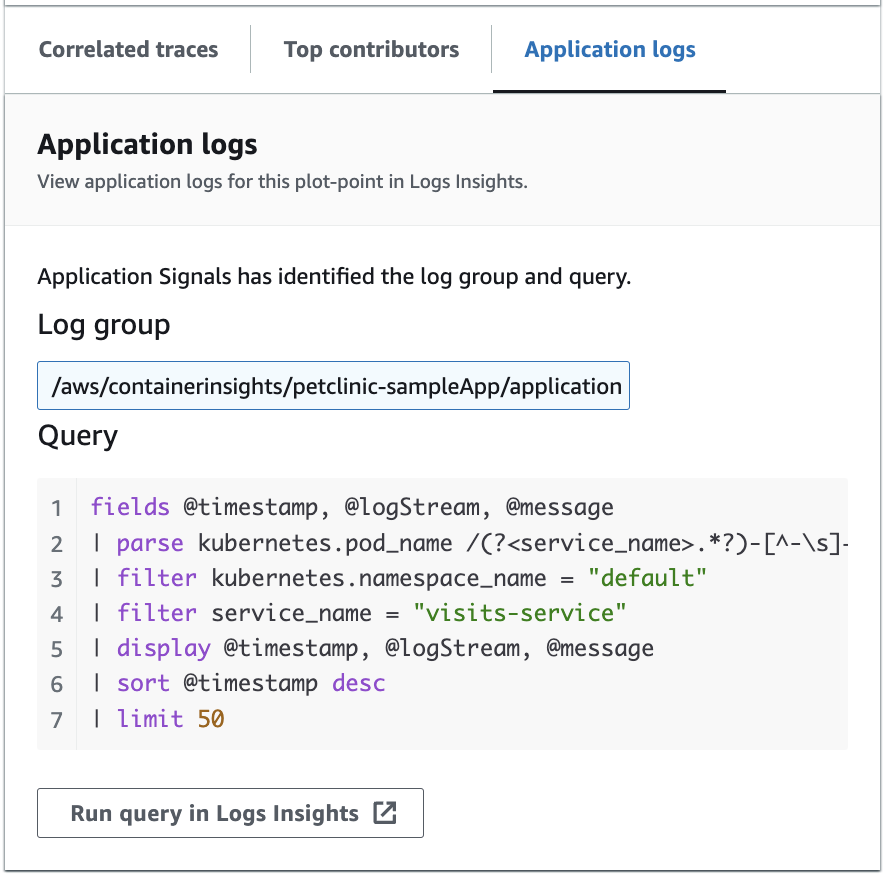
In der vorherigen Abbildung CloudWatch hat die Protokollgruppe, die Ihrem ausgewählten Punkt zugeordnet ist, automatisch erkannt und in eine generierte Abfrage aufgenommen.
Ihre Service-Abhängigkeiten anzeigen
Wählen Sie die Registerkarte Abhängigkeiten, um die Abhängigkeiten-Tabelle und eine Reihe von Metriken für die Abhängigkeiten aller Service-Vorgänge oder eines einzelnen Vorgangs anzuzeigen. Die Tabelle enthält eine Liste der Abhängigkeiten, die von Application Signals erkannt wurden, einschließlich Metriken für SLI-Status, Latenz, Aufrufvolumen, Störungsrate, Fehlerrate und Verfügbarkeit.
Wählen Sie oben auf der Seite einen Vorgang aus der Dropdown-Liste aus, um die zugehörigen Abhängigkeiten anzuzeigen, oder wählen Sie Alle aus, um die Abhängigkeiten für alle Operationen anzuzeigen.
Filtern Sie die Tabelle, um die Suche nach dem, was Sie suchen, zu erleichtern, indem Sie eine oder mehrere Eigenschaften aus dem Filter-Textfeld auswählen. Bei der Auswahl der einzelnen Eigenschaften werden Sie durch die Filter-Kriterien geführt und der vollständige Filter wird unter dem Filter-Textfeld angezeigt. Sie können jederzeit Filter löschen auswählen, um den Tabellenfilter zu entfernen. Wählen Sie oben rechts in der Tabelle die Option Nach Abhängigkeit gruppieren aus, um Abhängigkeiten nach Service- und Vorgangsnamen zu gruppieren. Wenn die Gruppierung aktiviert ist, können Sie eine Gruppe von Abhängigkeiten mit dem +-Symbol neben dem Namen der Abhängigkeit erweitern oder reduzieren.

In der Spalte Abhängigkeit wird der Name des Abhängigkeits-Services angezeigt, während in der Spalte Remote-Vorgang der Name der Serviceoperation angezeigt wird. In der Spalte SLI-Status wird die Anzahl der fehlerfreien oder fehlerhaften SLIs und die Gesamtzahl der SLIs für jede Abhängigkeit angezeigt. Beim Aufrufen von AWS Diensten wird in der Spalte Ziel die AWS Ressource angezeigt, z. B. die DynamoDB-Tabelle oder die Amazon SNS SNS-Warteschlange.
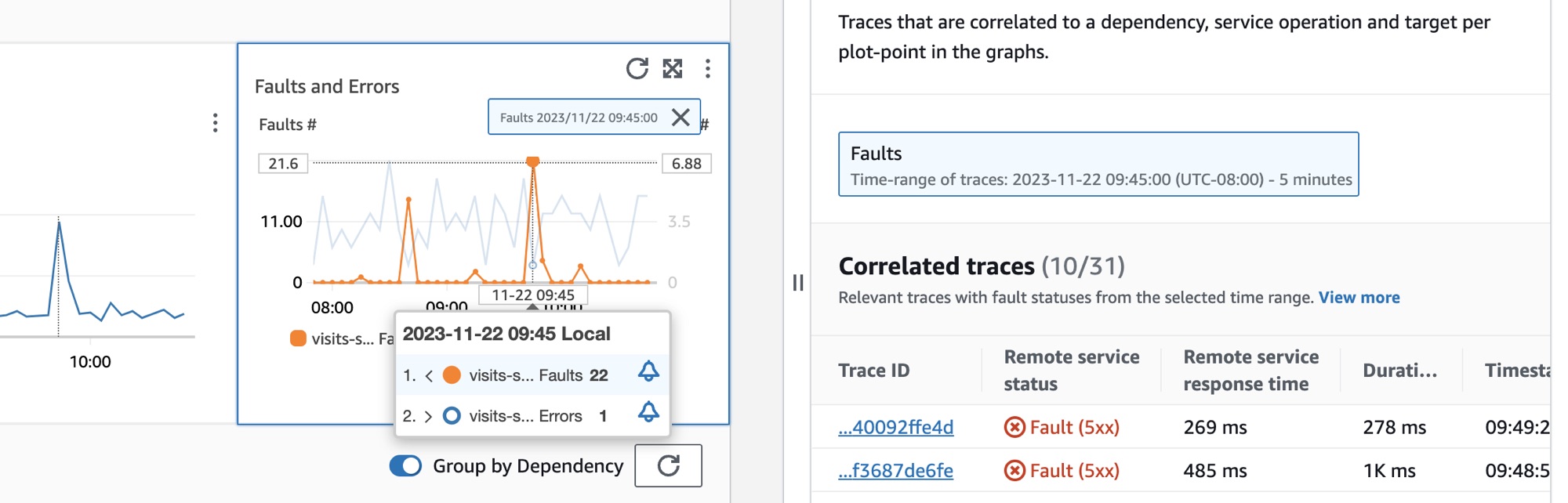
Um eine Abhängigkeit auszuwählen, wählen Sie in der Tabelle Abhängigkeiten die Option neben einer Abhängigkeit aus. Dadurch werden Diagramme angezeigt, die detaillierte Metriken für Aufrufvolumen, Verfügbarkeit, Störungen und Fehler darstellen. Bewegen Sie den Mauszeiger auf einen Punkt in einem Diagramm, um ein Popup mit weiteren Informationen zu öffnen. Wählen Sie einen Punkt in einem Diagramm aus, um einen Diagnosebereich zu öffnen, in dem korrelierte Ablaufverfolgungen für den ausgewählten Punkt im Diagramm angezeigt werden. Wählen Sie eine Trace-ID aus der Tabelle Correlated Traces aus, um die Seite mit den X-Ray Trace-Details für den ausgewählten Trace zu öffnen.
Ihre Synthetics-Canarys anzeigen
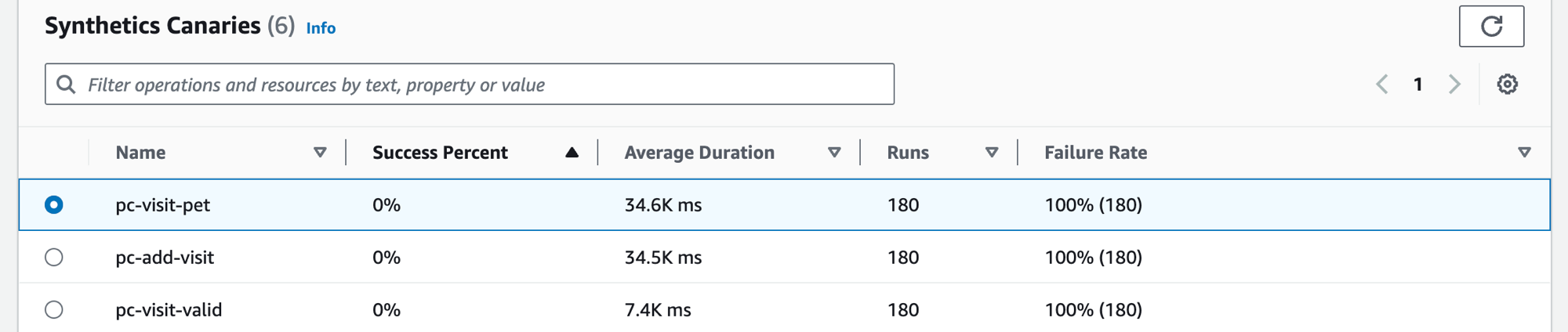
Wählen Sie die Registerkarte Synthetics-Canarys, um die Synthetics-Canarys-Tabelle und eine Reihe von Metriken für jeden Canary in der Tabelle anzuzeigen. Die Tabelle enthält Metriken für den prozentualen Erfolg, die durchschnittliche Dauer, die Ausführungen und die Ausfallrate. Es werden nur Kanarienvögel angezeigt, für die die AWS X-Ray Ablaufverfolgung aktiviert ist.
Mit dem Filtertextfeld in der Synthetics-Canarys-Tabelle können Sie nach relevanten Canarys suchen. Jeder Filter, den Sie erstellen, wird unter dem Filtertextfeld angezeigt. Sie können jederzeit Filter löschen auswählen, um den Tabellenfilter zu entfernen.
Wählen Sie das Optionsfeld neben dem Namen des Canarys aus, um eine Reihe von Registerkarten mit Diagrammen und detaillierten Metriken wie Erfolgsquote, Fehlern und Dauer anzuzeigen. Bewegen Sie den Mauszeiger auf einen Punkt in einem Diagramm, um ein Popup mit weiteren Informationen zu öffnen. Wählen Sie einen Punkt in einem Diagramm aus, um einen Diagnosebereich zu öffnen, in dem korrelierte Canary-Ausführungen für den ausgewählten Punkt angezeigt werden. Wählen Sie eine Canary-Ausführung und dann die Laufzeit aus, um Artefakte für die ausgewählte Canary-Ausführung zu sehen, einschließlich Protokollen, HTTP-Archivdateien (HAR), Screenshots und empfohlene Schritte zur Problembehebung. Wähle Mehr erfahren, um die Seite CloudWatch Synthetics Canaries neben Canary Runs zu öffnen.
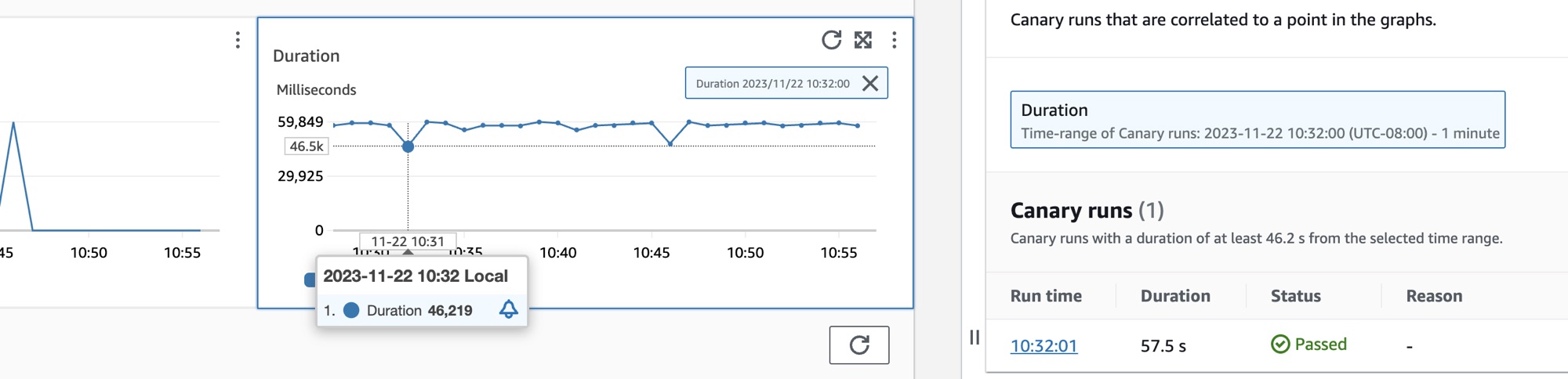
Ihre Kundenseiten anzeigen
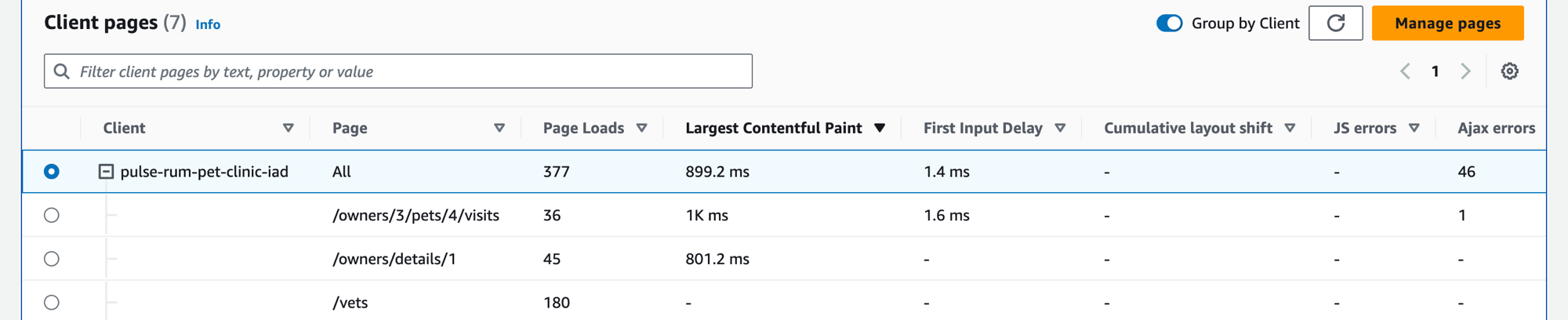
Wählen Sie die Registerkarte Client-Seiten aus, um eine Liste von Client-Webseiten anzuzeigen, die Ihren Service aufrufen. Verwenden Sie die Metriken für die ausgewählte Client-Seite, um die Qualität der Kundenerfahrung bei der Interaktion mit einem Service oder einer Anwendung zu messen. Zu diesen Metriken gehören Seitenladevorgänge, Webdaten und Fehler.
Um Ihre Kundenseiten in der Tabelle anzuzeigen, müssen Sie Ihren CloudWatch RUM-Webclient für die X-Ray Ablaufverfolgung konfigurieren und Application Signals-Metriken für Ihre Kundenseiten aktivieren. Wählen Sie Seiten verwalten aus, um zu verwalten, welche Seiten für Metriken von Application Signals aktiviert sind.
Verwenden Sie das Filtertextfeld, um darunter die gewünschte Client-Seite oder den gewünschten Anwendungsmonitor zu finden. Sie können Filter löschen auswählen, um den Tabellenfilter zu entfernen. Wählen Sie Nach Clients gruppieren, um Client-Seiten nach Clients zu gruppieren. Wenn Sie gruppiert sind, klicken Sie auf das +-Symbol neben einem Client-Namen, um die Zeile zu erweitern und alle Seiten für diesen Client anzuzeigen.
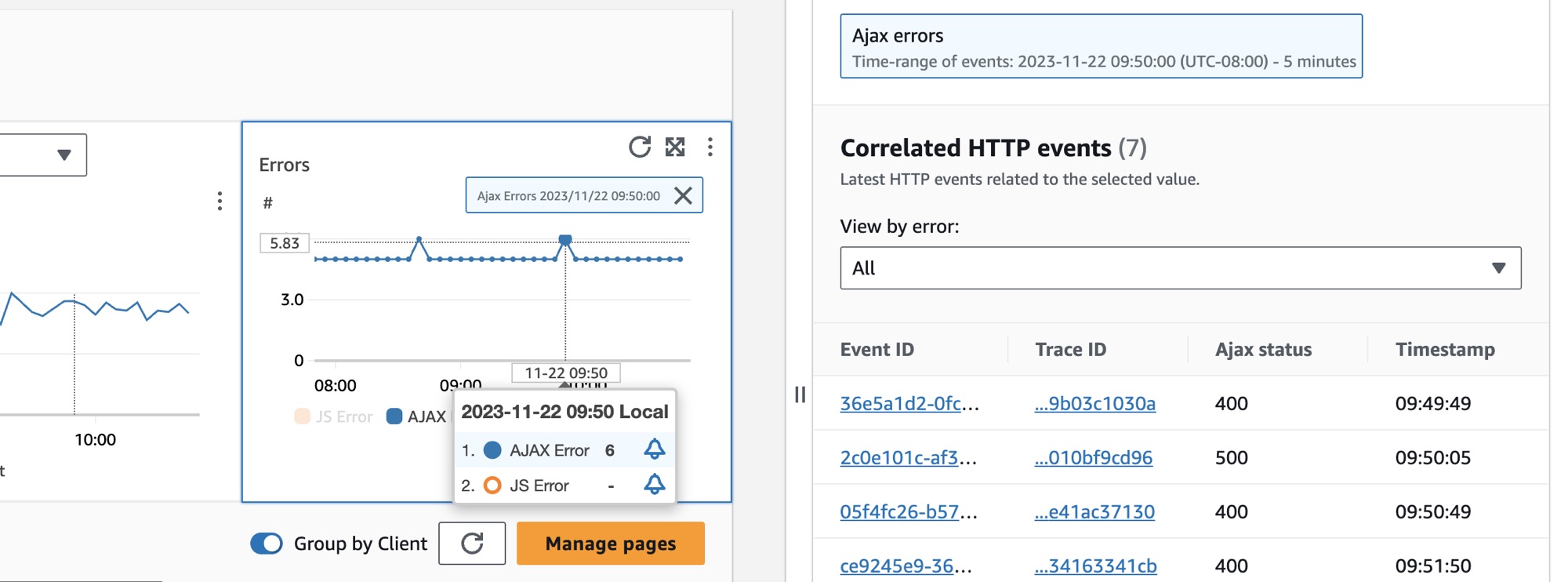
Um eine Client-Seite auszuwählen, wählen Sie in der Client-Seiten-Tabelle die Option neben einer Client-Seite aus. Sie werden eine Reihe von Diagrammen sehen, die detaillierte Metriken anzeigen. Bewegen Sie den Mauszeiger auf einen Punkt in einem Diagramm, um ein Popup mit weiteren Informationen zu öffnen. Wählen Sie einen Punkt in einem Diagramm aus, um einen Diagnosebereich zu öffnen, in dem korrelierte Leistungsnavigationsereignisse für den ausgewählten Punkt im Diagramm angezeigt werden. Wählen Sie eine Event-ID aus der Liste der Navigationsereignisse aus, CloudWatch um die RUM-Seitenansicht für das gewählte Ereignis zu öffnen.
Anmerkung
Um AJAX-Fehler auf Ihren Kundenseiten zu sehen, verwenden Sie den CloudWatch RUM-Webclient Version 1.15 oder neuer.
Pro Service können bis zu 100 Operationen, Canarys und Client-Seiten sowie bis zu 250 Abhängigkeiten angezeigt werden.
Zugehörige Metriken anzeigen
Verwenden Sie die Registerkarte „Zugehörige Metriken“, um mehrere Metriken zu visualisieren, Korrelationsmuster zu identifizieren und die Hauptursachen von Problemen zu ermitteln.
Die Metriktabelle enthält drei Arten von Metriken:
Standardmetriken: Application Signals erfasst Standard-Anwendungsmetriken von Services, die es entdeckt. Weitere Informationen finden Sie unter Erfasste Standard-Anwendungsmetriken.
Laufzeit-Metriken — Application Signals verwendet das AWS Distro for OpenTelemetry SDK, um automatisch OpenTelemetry-compatible Metriken aus Ihren Java- und Python-Anwendungen zu sammeln. Weitere Informationen finden Sie unter Laufzeitmetriken.
Benutzerdefinierte Metriken: Application Signals ermöglicht Ihnen, benutzerdefinierte Metriken aus Ihrer Anwendung zu generieren. Weitere Informationen finden Sie unter Benutzerdefinierte Metriken mit Application Signals.
Sie können die Registerkarte „Zugehörige Metriken“ über die Registerkarten „Serviceübersicht“, „Serviceoperationen“, „Abhängigkeiten“, „Synthetics-Canarys“ und „RUM“ aufrufen.

-
Im linken Navigationsbereich sind alle Operationen und Abhängigkeiten zunächst nicht ausgewählt.
-
Das Diagramm zeigt am Anfang die Störungsmetrik für die Operation mit der höchsten Störungsrate.
Bevor Sie mit der Korrelationsanalyse beginnen, sollten Sie sichtbare Datenpunkte unter „Serviceoperationen“ oder „Abhängigkeiten“ haben. Analysieren Sie Korrelationen wie folgt:
Öffnen Sie die Seite „Serviceoperationen“ oder „Abhängigkeiten“.
Wählen Sie einen Datenpunkt in einem beliebigen Diagramm aus.
Wählen Sie im rechten Bereich die Option Mit anderen Metriken korrelieren aus.
In der Registerkarte Zugehörige Metriken, die sich jetzt öffnet, sehen Sie:
die ausgewählte Operation oder Abhängigkeit in der linken Navigationsleiste.
die ausgewählte Metrik, grafisch dargestellt in der Tabelle Metriken durchsuchen.
korrelierte Spans, wenn Sie einen Datenpunkt auswählen.
Um mehrere Metriken grafisch darzustellen, wählen Sie eine oder mehrere Metriken in der Ansicht Durchsuchen auf der Registerkarte Zugehörige Metriken aus. Wählen Sie Grafisch dargestellte Metriken aus, um alle entsprechenden Metriken anzuzeigen.
Zum Filtern von Metriken verwenden Sie die Filter im linken Bereich, um die Ansicht auf bestimmte Operationen oder Abhängigkeiten zu begrenzen, und suchen Sie über die Filterleiste in der Tabellenüberschrift nach Namen, Typ oder anderen Attributen. Diese Filteroptionen helfen Ihnen, Muster zu erkennen und Probleme effizienter zu beheben.
Wenn Sie zugehörige Metriken detailliert analysieren möchten, wählen Sie auf der Registerkarte Zugehörige Metriken einen Datenpunkt aus. Dann können Sie Folgendes einsehen:
Wichtigste Mitwirkende — Analysiert Metriken, indem CloudWatch Logs Insights-Abfragen ausgeführt werden. Diese Abfragen verarbeiten Enhanced Metrics Format (EMF)-Datensätze, die Schlüsselattribute für eine detaillierte Analyse der folgenden Elemente enthalten:
Latenzmessungen
Störungsereignisse
Metriken zur Serviceverfügbarkeit
Die folgenden Metriken unterstützen die wichtigsten Faktoren nicht:
OTEL-Metriken
Server-side Span-Metriken
Sie können sich die wichtigsten Mitwirkenden für RED Metrics und Client-side Span Metrics anzeigen lassen.
Korrelierte Spans: Der Bereich „Korrelierte Spans“ funktioniert wie die Registerkarte „Serviceoperationen“. Um Ihnen bei der Ermittlung zugehöriger Ablaufverfolgungen und Metriken zu helfen, funktioniert der Korrelationsmechanismus wie folgt:
Metriknamen werden mit Span-Attributen verglichen
Während des ausgewählten Zeitraums werden übereinstimmende Muster identifiziert
Relevante Ablaufverfolgungsinformationen werden angezeigt
Für eine effektive Analyse Ihrer Metriken und Spans müssen Sie verstehen, wie verschiedene Metriktypen korrelieren. Die wichtigsten Einschränkungen:
OTEL-Metriken korrelieren nicht mit Spans, da sie unabhängige Benennungssysteme verwenden.
So korrelieren Sie Server- oder Client-side Span-Metriken mit Spans:
Fügen Sie Ihrer Konfiguration ein Feld für die Service-Dimension hinzu.
Ohne diese Service-Dimension können Sie die Metriken nicht mit Spans korrelieren.
Protokollanwendungen: Informationen zur Protokollanwendung finden Sie unter Anwendungsprotokolle.
