Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Auto Scaling Valkey- und Redis OSS-Cluster
Voraussetzungen
ElastiCache Auto Scaling ist auf Folgendes beschränkt:
-
Valkey- oder Redis OSS-Cluster (Clustermodus aktiviert), auf denen Valkey 7.2 oder Redis OSS 6.0 oder höher ausgeführt wird
-
Cluster mit Datenklassierung (Clustermodus aktiviert), auf denen Valkey 7.2 oder Redis OSS 7.0.7 oder höher ausgeführt wird
-
Instance-Größen - Large, XLarge, 2xLarge
-
Instance-Familien – R7g, R6g, R6gd, R5, M7g, M6g, M5, C7gn
-
Auto Scaling in ElastiCache wird nicht für Cluster unterstützt, die in globalen Datenspeichern, Outposts oder Local Zones ausgeführt werden.
Automatisches Kapazitätsmanagement mit ElastiCache Auto Scaling mit Valkey oder Redis OSS
ElastiCache Auto Scaling mit Valkey oder Redis OSS ist die Möglichkeit, die gewünschten Shards oder Repliken in Ihrem Service automatisch zu erhöhen oder zu verringern. ElastiCache ElastiCache nutzt den Application Auto Scaling Scaling-Dienst, um diese Funktionalität bereitzustellen. Weitere Informationen finden Sie unter Application Auto Scaling. Um die automatische Skalierung zu verwenden, definieren und wenden Sie eine Skalierungsrichtlinie an, die von Ihnen CloudWatch zugewiesene Metriken und Zielwerte verwendet. ElastiCache Auto Scaling verwendet die Richtlinie, um die Anzahl der Instanzen als Reaktion auf tatsächliche Workloads zu erhöhen oder zu verringern.
Sie können die verwenden AWS Management Console , um eine Skalierungsrichtlinie anzuwenden, die auf einer vordefinierten Metrik basiert. Eine predefined metric ist in einer Aufzählung definiert, sodass Sie sie im Code durch einen Namen angeben oder in der AWS Management Console verwenden können. Benutzerdefinierte Metriken können nicht über die AWS Management Console ausgewählt werden. Alternativ können Sie entweder die AWS CLI oder die Application Auto Scaling-API verwenden, um eine Skalierungsrichtlinie anzuwenden, die auf einer vordefinierten oder benutzerdefinierten Metrik basiert.
ElastiCache für Valkey und Redis unterstützt OSS die Skalierung für die folgenden Dimensionen:
-
Shards — Automatische add/remove Shards im Cluster, ähnlich wie manuelles Online-Resharding. In diesem Fall löst ElastiCache Auto Scaling die Skalierung in Ihrem Namen aus.
-
Replikate — Automatische add/remove Replikate im Cluster, ähnlich wie bei manuellen Increase/Decrease Replikatvorgängen. ElastiCache auto Skalierung für Valkey- und adds/removes Redis-OSS-Replikate einheitlich für alle Shards im Cluster.
ElastiCache für Valkey und Redis unterstützt OSS die folgenden Arten von Richtlinien für die automatische Skalierung:
-
Skalierungsrichtlinien für die Ziel-Nachverfolgung— Erhöhen oder verringern Sie die Anzahl shards/replicas , mit der Ihr Service ausgeführt wird, basierend auf einem Zielwert für eine bestimmte Metrik. Dies ähnelt der Art und Weise, wie ein Thermostat die Temperatur in Ihrem Zuhause konstant hält. Sie wählen eine Temperatur aus und der Thermostat erledigt den Rest.
-
Geplante Skalierung für Ihre Anwendung. — ElastiCache Für Valkey und Redis kann OSS Auto Scaling die Anzahl der ausgeführten shards/replicas Dienste je nach Datum und Uhrzeit erhöhen oder verringern.
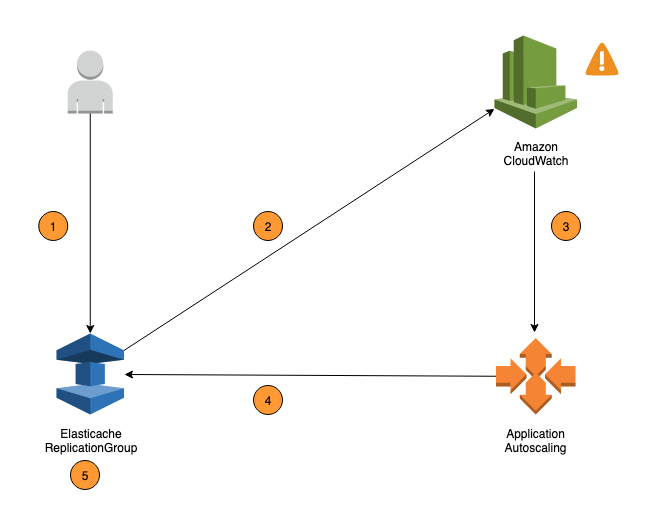
Die folgenden Schritte fassen den auto Skalierungsprozess ElastiCache für Valkey und Redis OSS zusammen, wie im vorherigen Diagramm dargestellt:
-
Sie erstellen eine ElastiCache Auto Scaling-Richtlinie für Ihre Replikationsgruppe.
-
ElastiCache Auto Scaling erstellt in Ihrem Namen ein Paar CloudWatch Alarme. Jedes Paar stellt die Ober- und Untergrenze für Metriken dar. Diese CloudWatch Alarme werden ausgelöst, wenn die tatsächliche Auslastung des Clusters über einen längeren Zeitraum von Ihrer Zielauslastung abweicht. Sie können jetzt -Alarme in der -Konsole anzeigen.
-
Wenn der konfigurierte Metrikwert Ihre Zielauslastung für einen bestimmten Zeitraum überschreitet (oder unter das Ziel fällt), wird ein Alarm CloudWatch ausgelöst, der Auto Scaling zur Bewertung Ihrer Skalierungsrichtlinie auslöst.
-
ElastiCache Auto Scaling gibt eine Modifizierungsanforderung aus, um Ihre Clusterkapazität anzupassen.
-
ElastiCache verarbeitet die Modifizierungsanforderung und erhöht (oder verringert) die Shards/Replicas Clusterkapazität dynamisch, sodass sie sich Ihrer Zielauslastung annähert.
Um zu verstehen, wie ElastiCache Auto Scaling funktioniert, nehmen wir an, Sie haben einen Cluster mit dem NamenUsersCluster. Durch die Überwachung der CloudWatch Metriken bestimmen Sie die maximale Anzahl an Shards, die der Cluster benötigt, wenn der Verkehr seinen Höhepunkt erreicht, und die Mindestanzahl an Shards, wenn der Verkehr am niedrigsten Punkt ist. UsersCluster Sie legen auch einen Zielwert für die CPU-Auslastung für den UsersCluster Cluster fest. ElastiCache Auto Scaling verwendet seinen Target-Tracking-Algorithmus, um sicherzustellen, dass die bereitgestellten Shards von UsersCluster nach Bedarf angepasst werden, sodass die Auslastung auf oder nahe dem Zielwert bleibt.
Anmerkung
Die Skalierung kann viel Zeit in Anspruch nehmen und erfordert zusätzliche Cluster-Ressourcen, damit die Shards wieder ausgeglichen werden können. ElastiCache Auto Scaling ändert die Ressourceneinstellungen nur, wenn die tatsächliche Arbeitslast über einen längeren Zeitraum von mehreren Minuten erhöht (oder reduziert) bleibt. Der Auto Scaling Target-Tracking-Algorithmus versucht, die Zielauslastung langfristig auf oder nahe dem von Ihnen gewählten Wert zu halten.
Für Auto Scaling sind IAM-Berechtigungen erforderlich
ElastiCache für Valkey und Redis OSS wird Auto Scaling durch eine Kombination der APIs ElastiCache, CloudWatch, und Application Auto Scaling ermöglicht. Cluster werden mit Application Auto Scaling erstellt und aktualisiert ElastiCache CloudWatch, Alarme werden mit erstellt und Skalierungsrichtlinien werden erstellt. Zusätzlich zu den Standard-IAM-Berechtigungen für das Erstellen und Aktualisieren von Clustern muss der IAM-Benutzer, der auf die ElastiCache Auto Scaling Scaling-Einstellungen zugreift, über die entsprechenden Berechtigungen für die Dienste verfügen, die dynamische Skalierung unterstützen. In dieser neuesten Richtlinie haben wir mit der Aktion Unterstützung für die vertikale Skalierung von Memcached hinzugefügt. elasticache:ModifyCacheCluster IAM-Benutzer müssen die Berechtigung haben, die Aktionen in der folgenden Beispielrichtlinie zu verwenden:
Service-linked Rolle
Der auto Skalierungsdienst ElastiCache für Valkey und Redis OSS benötigt außerdem die Erlaubnis, Ihre Cluster und CloudWatch Alarme zu beschreiben, sowie Berechtigungen, Ihre ElastiCache Zielkapazität in Ihrem Namen zu ändern. Wenn Sie Auto Scaling für Ihren Cluster aktivieren, wird eine dienstverknüpfte Rolle mit dem Namen AWSServiceRoleForApplicationAutoScaling_ElastiCacheRG erstellt. Diese dienstbezogene Rolle gewährt ElastiCache Auto Scaling-Berechtigungen, um die Alarme für Ihre Richtlinien zu beschreiben, die aktuelle Kapazität der Flotte zu überwachen und die Kapazität der Flotte zu ändern. Die serviceverknüpfte Rolle ist die Standardrolle für ElastiCache Auto Scaling. Weitere Informationen finden Sie unter Service-linked Rollen ElastiCache für Redis OSS Auto Scaling im Application Auto Scaling Scaling-Benutzerhandbuch.
Bewährte Methoden für die Auto Scaling
Wir empfehlen vor der Registrierung für Auto Scaling Folgendes:
-
Verwenden Sie nur eine Tracking-Metrik – Ermitteln Sie, ob Ihr Cluster über CPU- oder datenintensive Workloads verfügt, und verwenden Sie eine entsprechende vordefinierte Metrik, um die Skalierungsrichtlinie zu definieren.
-
Engine-CPU:
ElastiCachePrimaryEngineCPUUtilization(Shard-Dimension) oderElastiCacheReplicaEngineCPUUtilization(Replikatdimension) -
Datenbanknutzung:
ElastiCacheDatabaseCapacityUsageCountedForEvictPercentageDiese Skalierungsrichtlinie funktioniert am besten, wenn „maxmemory-policy“ im Cluster auf „noeviction“ festgelegt ist.
Wir empfehlen Ihnen, mehrere Richtlinien pro Dimension auf dem Cluster zu vermeiden. ElastiCache Für Valkey und Redis OSS skaliert Auto Scaling das skalierbare Ziel, wenn irgendwelche Richtlinien für die Zielverfolgung bereit sind, aber es wird nur dann skaliert, wenn alle Ziel-Tracking-Richtlinien (mit aktiviertem Scale-In-Teil) skalierbar sind. Wenn mehrere Richtlinien das skalierbare Ziel anweisen, gleichzeitig zu herauf oder herunter zu skalieren, skaliert auf Grundlage der Richtlinie, die die größte Kapazität für das Herauf- und Herunterskalieren bietet.
-
-
Maßgeschneiderte Metriken für Target Tracking — Seien Sie vorsichtig, wenn Sie benutzerdefinierte Metriken für Target Tracking verwenden, da die automatische Skalierung am besten für die Skalierung geeignet ist — out/in proportional zu den Änderungen der für die Richtlinie ausgewählten Metriken. Wenn solche Metriken, die sich nicht proportional zu den Skalierungsaktionen ändern, zur Richtlinienerstellung verwendet werden, kann dies zu kontinuierlichen Auf- oder Abskalierungsaktionen führen, was sich auf Verfügbarkeit oder Kosten auswirken kann.
Vermeiden Sie bei Daten-Tiering-Clustern (Instance-Familie r6gd) die Verwendung speicherbasierter Metriken für die Skalierung.
-
Geplante Skalierung — Wenn Sie feststellen, dass Ihre Arbeitslast deterministisch ist (sie erreicht high/low zu einem bestimmten Zeitpunkt), empfehlen wir, die geplante Skalierung zu verwenden und Ihre Zielkapazität entsprechend den Anforderungen zu konfigurieren. Target Tracking eignet sich am besten für nicht-deterministische Workloads und für einen Cluster für den Betrieb mit der erforderlichen Zielmetrik, indem er aufskaliert, wenn Sie mehr Ressourcen benötigen, und abskaliert, wenn Sie weniger benötigen.
-
Deaktivieren Scale-In — Die automatische Skalierung bei Target Tracking eignet sich am besten für Cluster mit schrittweiser Verteilung increase/decrease der Workloads, da spikes/dip Metriken aufeinanderfolgende Skalierungsschwankungen auslösen können. out/in Um solche Schwankungen zu vermeiden, können Sie mit deaktivierter Abskalierung beginnen. Später können Sie jederzeit manuell nach Ihren Bedürfnissen abskalieren.
-
Testen Sie Ihre Anwendung — Wir empfehlen Ihnen, Ihre Anwendung mit Ihren geschätzten Min/Max Workloads zu testen, um die für den Cluster shards/replicas erforderlichen Mindest-/Höchstwerte zu ermitteln und gleichzeitig Skalierungsrichtlinien zu erstellen, um Verfügbarkeitsprobleme zu vermeiden. Die automatische Skalierung kann bis zum Maximal- und Minimalwert auf- bzw. abskalieren, der für das Ziel konfiguriert wurde.
-
Definition des Zielwerts — Sie können die entsprechenden CloudWatch Metriken für die Clusterauslastung über einen Zeitraum von vier Wochen analysieren, um den Schwellenwert für den Zielwert zu ermitteln. Wenn Sie sich immer noch nicht sicher sind, welchen Wert Sie wählen möchten, empfehlen wir, mit dem minimal unterstützten vordefinierten Metrikwert zu beginnen.
-
AutoScaling On Target Tracking eignet sich am besten für Cluster mit einheitlicher Verteilung der Workloads über alle shards/replicas Dimensionen. Eine ungleichmäßige Verteilung kann zu folgenden Faktoren führen:
-
Skalierung, wenn sie aufgrund der Arbeitslast spike/dip auf einigen heißen shards/replicas Geräten nicht erforderlich ist.
-
Bei Bedarf wird nicht skaliert, da der Gesamtdurchschnitt nahe am Zielwert liegt, obwohl er heiß ist shards/replicas.
-
Anmerkung
Bei der Skalierung Ihres Clusters ElastiCache werden die Funktionen, die in einem der vorhandenen Knoten geladen wurden (zufällig ausgewählt), automatisch auf die neuen Knoten repliziert. Wenn Ihr Cluster über Valkey oder Redis OSS 7.0 oder höher verfügt und Ihre Anwendung Functions
Beachten Sie nach der Registrierung Folgendes AutoScaling:
-
Es gibt Einschränkungen bei den unterstützten Konfigurationen für die automatische Skalierung, daher empfehlen wir, die Konfiguration einer Replikationsgruppe, die für die automatische Skalierung registriert ist, nicht zu ändern. Im Folgenden sind einige Beispiele aufgeführt:
-
Manuelles Ändern des Instance-Typs in nicht unterstützte Typen.
-
Zuordnen der Replikationsgruppe zu einem globalen Datenspeicher.
-
Ändern
ReservedMemoryPercent-Parameter. -
Manuelles increasing/decreasing shards/replicas Überschreiten der Min/Max Kapazität, die bei der Erstellung der Richtlinie konfiguriert wurde.
-
