Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Funktionsweise von Auto Discovery
Dieser Abschnitt beschreibt, wie Client-Anwendungen ElastiCache-Cluster-Client verwenden, um Cache-Knoten-Verbindungen zu verwalten und mit Datenelementen im Cache zu interagieren.
Herstellen von Verbindungen mit Cache-Knoten
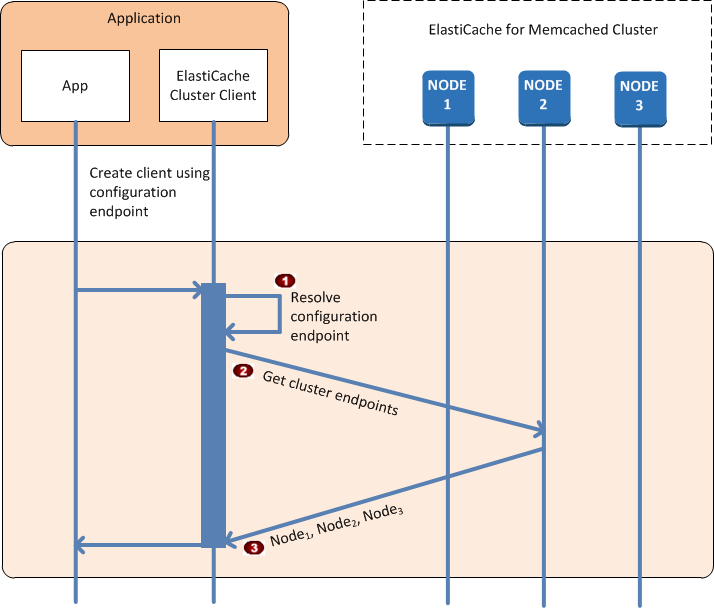
Von der Anwendungsseite aus betrachtet, unterscheidet sich das Herstellen einer Verbindung mit dem Cluster-Konfigurationsendpunkt nicht vom Herstellen einer direkten Verbindung mit einem einzelnen Cache-Knoten. Das folgende Ablaufdiagramm zeigt den Prozess zum Herstellen der Verbindung mit Cache-Knoten.

|
Die Anwendung löst den DNS-Namen des Konfigurationsendpunkts auf. Da der Konfigurationsendpunkt CNAME-Einträge für alle Cache-Knoten verwaltet, wird der DNS-Name in einen der Knoten aufgelöst. Der Client kann dann eine Verbindung mit diesem Knoten herstellen. |

|
Der Client fordert die Konfigurationsinformationen für alle anderen Knoten an. Da jeder Knoten Konfigurationsinformationen für alle Knoten im Cluster verwaltet, kann jeder Knoten auf Anfrage Konfigurationsinformationen an den Client weitergeben. |

|
Der Client empfängt die aktuelle Liste mit den Hostnamen und IP-Adressen der Cache-Knoten. Anschließend kann er eine Verbindung mit allen anderen Knoten im Cluster herstellen. |
Anmerkung
Das Client-Programm aktualisiert seine Liste mit den Hostnamen und IP-Adressen der Cache-Knoten einmal pro Minute. Dieses Abfrageintervall kann bei Bedarf angepasst werden.
Normale Cluster-Operationen
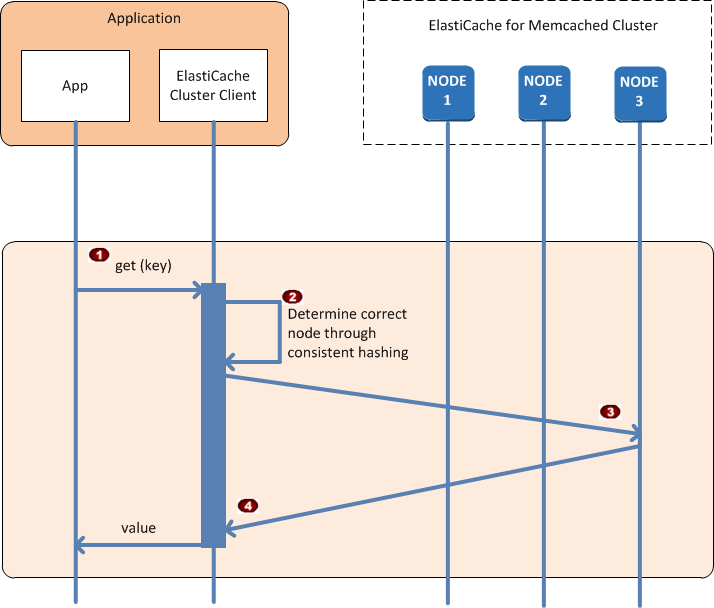
Wenn die Anwendung eine Verbindung zu allen Cache-Knoten hergestellt hat, bestimmt der ElastiCache-Cluster-Client, welche Knoten einzelne Datenelemente speichern sollen und welche Knoten später nach diesen Datenelementen abgefragt werden sollen. Das folgende Ablaufdiagramm zeigt den Prozess für normale Cluster-Operationen.
|
|
Die Anwendung erstellt eine get-Anforderung für ein bestimmtes Datenelement, das durch seinen Schlüssel identifiziert wird. |
|
|
Der Client verwendet einen Hashing-Algorithmus für den Schlüssel, um den Cache-Knoten zu ermitteln, der das Datenelement enthält. |
|
|
Das Datenelement wird vom entsprechenden Knoten angefordert. |

|
Das Datenelement wird an die Anwendung zurückgegeben. |
Weitere Operationen in
In manchen Situationen kann es vorkommen, dass Sie eine Änderung an den Knoten eines Clusters vornehmen. So können Sie beispielsweise einen zusätzlichen Knoten hinzufügen, um zusätzlichen Bedarf zu decken, oder einen Knoten löschen, um in Zeiten geringerer Nachfrage Geld zu sparen. Oder Sie ersetzen einen Knoten, weil er auf die eine oder andere Weise ausgefallen ist.
Bei einer Änderung im Cluster, die eine Aktualisierung der Metadaten auf die Endpunkte des Clusters erfordert, wird diese Änderung auf allen Knoten gleichzeitig vorgenommen. So sind die Metadaten in einem bestimmten Knoten konsistent mit den Metadaten in allen anderen Knoten im Cluster.
In jedem Fall sind die Metadaten für alle Knoten jederzeit konsistent, da sie für alle Knoten im Cluster gleichzeitig aktualisiert werden. Verwenden Sie immer den Konfigurationsendpunkt, um die Endpunkte der verschiedenen Knoten im Cluster zu erhalten. Durch Verwenden des Konfigurationsendpunkts stellen Sie sicher, dass Sie keine Endpunktdaten von einem Knoten erhalten, der "verschwindet".
Hinzufügen eines Knotens
Während der Zeit, in der der Knoten eingerichtet wird, ist sein Endpunkt nicht in den Metadaten enthalten. Sobald der Knoten verfügbar ist, wird er den jeweiligen Metadaten der Cluster-Knoten hinzugefügt. In diesem Szenario sind die Metadaten für alle Knoten konsistent und Sie können mit dem neuen Knoten erst interagieren, sobald er verfügbar ist. Vorher liegen Ihnen keine Informationen darüber vor und Sie interagieren mit den Knoten in Ihrem Cluster so, als ob der neue Knoten nicht vorhanden wäre.
Löschen eines Knotens
Wenn ein Knoten entfernt wird, wird sein Endpunkt erst in den Metadaten gelöscht und anschließend wird der Knoten aus dem Cluster entfernt. In diesem Szenario sind die Metadaten in allen Knoten konsistent und zu keiner Zeit enthalten sie den Endpunkt für den Knoten, der entfernt werden soll, während der Knoten nicht verfügbar ist. Während des Zeitraums, in dem der Knoten entfernt wird, erfolgt keine Meldung in den Metadaten. Demzufolge interagiert Ihre Anwendung nur mit den verbleibenden n-1 Knoten, so als ob der Knoten nicht vorhanden wäre.
Ersetzen eines Knotens
Wenn ein Knoten ausfällt, schaltet ElastiCache diesen Knoten ab und fährt einen Ersatz hoch. Das Ersetzen dauert einige Minuten. Während dieser Zeit zeigen die Metadaten in allen Knoten den Endpunkt für den ausgefallenen Knoten noch an, doch jeder Versuch, mit dem Knoten zu interagieren, schlägt fehl. Daher sollte Ihre Logik immer Logik für Wiederholungsversuche umfassen.
