Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Optimierung der Speicherparameter für Aurora PostgreSQL
In Amazon Aurora PostgreSQL können Sie mehrere Parameter verwenden, die die Speichermenge steuern, die für verschiedene Verarbeitungsaufgaben verwendet wird. Wenn eine Aufgabe mehr Speicher beansprucht als die für einen bestimmten Parameter festgelegte Menge, verwendet Aurora PostgreSQL andere Ressourcen für die Verarbeitung, z. B. durch Schreiben auf die Festplatte. Dies kann dazu führen, dass Ihr Aurora PostgreSQL DB-Cluster langsamer wird oder möglicherweise angehalten wird, mit einem Fehler bei unzureichendem Arbeitsspeicher.
Die Standardeinstellung für jeden Speicherparameter kann normalerweise die beabsichtigten Verarbeitungsaufgaben verarbeiten. Sie können jedoch auch Ihre speicherbezogenen Parameter von Aurora PostgreSQL DB-Cluster optimieren. Sie führen diese Optimierung durch, um sicherzustellen, dass genügend Speicher für die Verarbeitung Ihrer spezifischen Workload zugewiesen ist.
Nachstehend finden Sie Informationen über Parameter, die die Speicherverwaltung steuern. Sie können auch lernen, wie Sie die Speicherauslastung bewerten.
Überprüfen und Einstellen von Parameterwerten
Zu den Parametern, die Sie festlegen können, um den Speicher zu verwalten und die Speicherauslastung Ihres Aurora PostgreSQL DB-Clusters zu bewerten, gehören die folgenden:
work_mem– Gibt die Speichermenge an, die der Aurora PostgreSQL DB-Cluster für interne Sortiervorgänge und Hash-Tabellen verwendet, bevor er in temporäre Plattendateien schreibt.log_temp_files– Protokolliert die Erstellung temporärer Dateien, Dateinamen und -größen. Wenn dieser Parameter aktiviert ist, wird für jede temporäre Datei, die erstellt wird, ein Protokolleintrag gespeichert. Aktivieren Sie diese Option, um zu sehen, wie oft Ihr Aurora PostgreSQL DB-Cluster auf die Festplatte schreiben muss. Schalten Sie es wieder aus, nachdem Sie Informationen über die temporäre Dateigenerierung Ihres Aurora PostgreSQL DB-Clusters gesammelt haben, um eine übermäßige Protokollierung zu vermeiden.logical_decoding_work_mem– Gibt die Speichermenge (in Kilobyte) an, die von jedem internen Neuordnungspuffer vor dem Schreiben auf die Festplatte genutzt werden soll. Dieser Speicher wird für die logische Dekodierung verwendet, ein Prozess zur Erstellung eines Replikats. Dies erfolgt durch Konvertieren von Daten aus der Write-Ahead-Log-Datei (WAL) in die logische Streaming-Ausgabe, die vom Ziel benötigt wird.Der Wert dieses Parameters erstellt einen einzelnen Puffer mit der für jede Replikationsverbindung angegebenen Größe. Standardmäßig sind es 65 536 KB. Nachdem dieser Puffer gefüllt ist, wird der Überschuss als Datei auf die Festplatte geschrieben. Um Plattenaktivität zu minimieren, können Sie den Wert dieses Parameters auf einen viel höheren Wert setzen als den von
work_mem.
Dies sind alles dynamische Parameter, sodass Sie sie für die aktuelle Sitzung ändern können. Stellen Sie dazu eine Verbindung mit dem Aurora PostgreSQL DB-Cluster mit „psql“ und unter Verwendung der SET-Anweisung, wie unten angezeigt.
SET parameter_name TO parameter_value;Sitzungseinstellungen sind nur für die Dauer der Sitzung gültig. Wenn die Sitzung endet, kehrt der Parameter auf seine Einstellung in der DB-Cluster-Parametergruppe zurück. . Bevor Sie Parameter ändern, überprüfen Sie zunächst die aktuellen Werte, indem Sie die pg_settings-Tabelle wie folgt abfragen.
SELECT unit, setting, max_val FROM pg_settings WHERE name='parameter_name';
Um zum Beispiel den Wert des work_mem-Parameters zu finden, stellen Sie eine Verbindung zur Writer-Instance des Aurora PostgreSQL DB-Clusters her und führen Sie die folgende Abfrage aus.
SELECT unit, setting, max_val, pg_size_pretty(max_val::numeric) FROM pg_settings WHERE name='work_mem';unit | setting | max_val | pg_size_pretty ------+----------+-----------+---------------- kB | 1024 | 2147483647| 2048 MB (1 row)
Um Parametereinstellungen so zu ändern, dass sie bestehen bleiben, müssen Sie eine benutzerdefinierte DB-Cluster-Parametergruppe verwenden. . Nach dem Trainieren Ihrer Aurora PostgreSQL DB-Cluster mit unterschiedlichen Werten für diese Parameter unter Verwendung der SET-Anweisung können Sie eine benutzerdefinierte Parametergruppe erstellen und auf Ihre Parametergruppe Aurora PostgreSQL DB-Cluster anwenden. Weitere Informationen finden Sie unter Parametergruppen für Amazon Aurora.
Den Arbeitsspeicherparameter verstehen
Der Arbeitsspeicherparameter (work_mem) gibt die maximale Speichermenge an, die Aurora PostgreSQL zur Verarbeitung komplexer Abfragen verwenden kann. Zu komplexen Abfragen gehören solche, die Sortier- oder Gruppierungsvorgänge beinhalten, also Abfragen, die die folgenden Klauseln verwenden:
ORDER BY
DISTINCT
GROUP BY
JOIN (MERGE und HASH)
Der Abfrageplaner beeinflusst indirekt, wie Ihr Aurora PostgreSQL DB-Cluster Arbeitsspeicher verwendet. Der Abfrageplaner generiert Ausführungspläne für die Verarbeitung von SQL-Anweisungen. Ein bestimmter Plan kann eine komplexe Abfrage in mehrere Arbeitseinheiten aufteilen, die parallel ausgeführt werden können. Wenn möglich, verwendet Aurora PostgreSQL die Speichermenge, die im work_mem-Parameter für jede Sitzung vor dem Schreiben auf die Festplatte für jeden parallelen Prozess angegeben ist.
Mehrere Datenbankbenutzer, die mehrere Operationen gleichzeitig ausführen und mehrere Arbeitseinheiten parallel generieren, können den zugewiesenen Arbeitsspeicher Ihres Aurora PostgreSQL DB-Clusters erschöpfen. Dies kann dazu führen, dass zu viele temporäre Dateien und Festplatten erstellt werden I/O, oder schlimmer noch, es kann zu einem Fehler aufgrund unzureichender Speicherkapazität führen.
Identifizieren temporärer Dateiverwendung
Immer, wenn der für die Verarbeitung von Abfragen erforderliche Speicher den im work_mem-Parameter angegebenen Wert übersteigt, werden die Arbeitsdaten in einer temporären Datei auf die Festplatte ausgelagert. Sie können sehen, wie oft dies geschieht, indem Sie den log_temp_files-Parameter aktivieren. Standardmäßig ist dieser Parameter deaktiviert (Einstellung auf -1). Um alle temporären Dateiinformationen zu erfassen, setzen Sie diesen Parameter auf 0. Setzen Sie log_temp_files auf eine andere positive Ganzzahl, um temporäre Dateiinformationen für Dateien zu erfassen, die dieser Datenmenge entsprechen oder größer sind (in Kilobyte). In der folgenden Abbildung sehen Sie ein Beispiel von. AWS Management Console
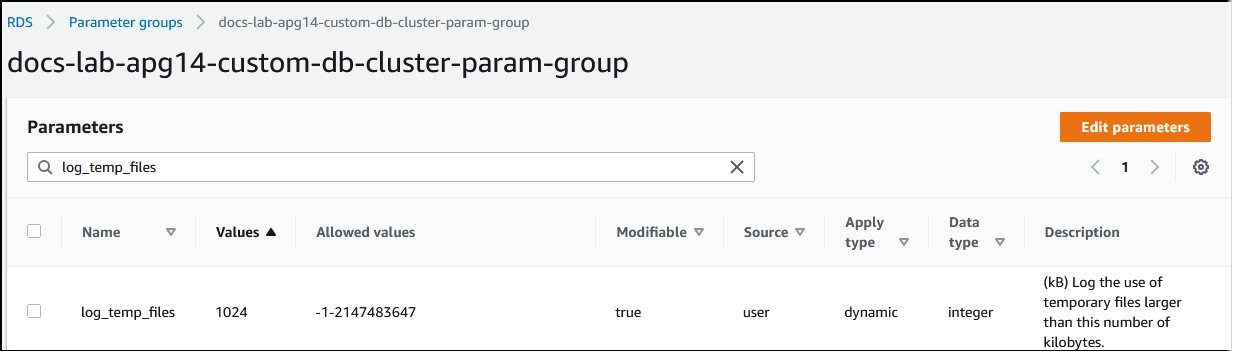
Nachdem Sie die temporäre Dateiprotokollierung konfiguriert haben, können Sie mit Ihrer eigenen Workload testen, ob Ihre Arbeitsspeichereinstellung ausreichend ist. Sie können eine Workload auch mithilfe von pgbench simulieren, einer einfachen Benchmarking-Anwendung aus der PostgreSQL-Community.
Das folgende Beispiel initialisiert (-i)pgbench, indem es die notwendigen Tabellen und Zeilen für die Ausführung der Tests erstellt. In diesem Beispiel erstellt der Skalierungsfaktor (-s 50) 50 Zeilen in der pgbench_branches-Tabelle, 500 Zeilen in pgbench_tellers und 5 000 000 Zeilen in der pgbench_accounts-Tabelle in der labdbDatenbank.
pgbench -U postgres -h your-cluster-instance-1.111122223333.aws-regionrds.amazonaws.com -p 5432 -i -s 50 labdb
Password:
dropping old tables...
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
creating tables...
generating data (client-side)...
5000000 of 5000000 tuples (100%) done (elapsed 15.46 s, remaining 0.00 s)
vacuuming...
creating primary keys...
done in 61.13 s (drop tables 0.08 s, create tables 0.39 s, client-side generate 54.85 s, vacuum 2.30 s, primary keys 3.51 s)Nach der Initialisierung der Umgebung können Sie den Benchmark für eine bestimmte Zeit (-T) und die Anzahl der Kunden (-c) ausführen. In diesem Beispiel wird auch die -d-Option zur Ausgabe von Debugging-Informationen verwendet, während die Transaktionen vom Aurora PostgreSQL DB-Cluster verarbeitet werden.
pgbench -h -U postgresyour-cluster-instance-1.111122223333.aws-regionrds.amazonaws.com -p 5432 -d -T 60 -c 10labdbPassword:*******pgbench (14.3) starting vacuum...end. transaction type: <builtin: TPC-B (sort of)> scaling factor: 50 query mode: simple number of clients: 10 number of threads: 1 duration: 60 s number of transactions actually processed: 1408 latency average = 398.467 ms initial connection time = 4280.846 ms tps = 25.096201 (without initial connection time)
Weitere Informationen über „pgbench“ finden Sie in pgbench
Sie können den Befehl „psql metacommand“ (\d) verwenden, um die von „pgbench“ erstellten Relationen wie Tabellen, Ansichten und Indizes aufzulisten.
labdb=>\d pgbench_accountsTable "public.pgbench_accounts" Column | Type | Collation | Nullable | Default ----------+---------------+-----------+----------+--------- aid | integer | | not null | bid | integer | | | abalance | integer | | | filler | character(84) | | | Indexes: "pgbench_accounts_pkey" PRIMARY KEY, btree (aid)
Wie in der Ausgabe gezeigt, wird die pgbench_accounts-Tabelle nach der aid-Spalte indiziert. Um sicherzustellen, dass diese nächste Abfrage Arbeitsspeicher verwendet, fragen Sie eine beliebige nicht indizierte Spalte ab, z. B. die im folgenden Beispiel gezeigte.
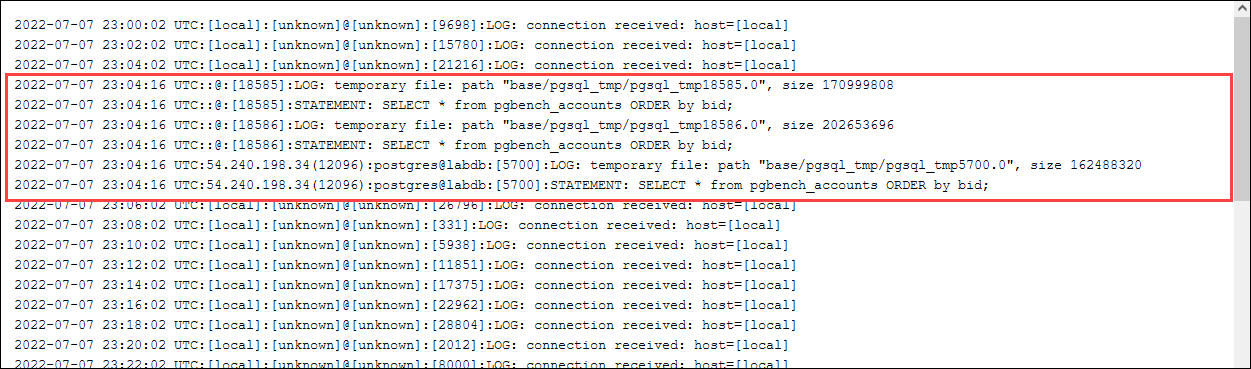
postgres=>SELECT * FROM pgbench_accounts ORDER BY bid;
Überprüfen Sie das Protokoll auf die temporären Dateien. Öffnen Sie dazu die AWS Management Console, wählen Sie die Aurora PostgreSQL DB-Cluster-Instance und wählen Sie dann die Registerkarte Logs & Events aus. Zeigen Sie die Protokolle in der Konsole an oder laden Sie sie zur weiteren Analyse herunter. Wie in der folgenden Abbildung dargestellt, zeigt die Größe der temporären Dateien, die für die Verarbeitung der Abfrage benötigt werden, an, dass Sie erwägen sollten, die für die work_mem-Parameter angegebene Menge zu erhöhen.
Sie können diesen Parameter für Einzelpersonen und Gruppen unterschiedlich konfigurieren, je nach Ihren betrieblichen Anforderungen. Sie können beispielsweise den work_mem-Parameter auf 8 GB für die Rolle mit dem Namen dev_team festlegen.
postgres=>ALTER ROLEdev_teamSET work_mem=‘8GB';
Mit dieser Einstellung für work_mem wird jeder Rolle, die ein Mitglied der dev_team-Rolle ist, bis zu 8 GB Arbeitsspeicher zugewiesen.
Verwenden von Indizes für schnellere Reaktionszeit
Wenn Ihre Abfragen zu lange dauern, bis Ergebnisse zurückgegeben werden, können Sie überprüfen, ob Ihre Indizes erwartungsgemäß verwendet werden. Aktivieren Sie zuerst \timing, das psql-Metakommando, wie folgt.
postgres=>\timing on
Verwenden Sie nach dem Aktivieren des Timings eine einfache SELECT-Anweisung.
postgres=>SELECT COUNT(*) FROM (SELECT * FROM pgbench_accounts ORDER BY bid) AS accounts;count ------- 5000000 (1 row) Time: 3119.049 ms (00:03.119)
Wie in der Ausgabe gezeigt, dauerte die Ausführung dieser Abfrage etwas mehr als 3 Sekunden. Um die Reaktionszeit zu verbessern, erstellen Sie einen Index für pgbench_accounts wie folgt.
postgres=>CREATE INDEX ON pgbench_accounts(bid);CREATE INDEX
Führen Sie die Abfrage erneut aus und beachten Sie die kürzere Antwortzeit. In diesem Beispiel wurde die Abfrage etwa fünfmal schneller abgeschlossen, in etwa einer halben Sekunde.
postgres=>SELECT COUNT(*) FROM (SELECT * FROM pgbench_accounts ORDER BY bid) AS accounts;count ------- 5000000 (1 row) Time: 567.095 ms
Arbeitsspeicher für logische Dekodierung anpassen
Logische Replikation war in allen Versionen von Aurora PostgreSQL seit seiner Einführung in PostgreSQL Version 10 verfügbar. Wenn Sie die logische Replikation konfigurieren, können Sie auch die logical_decoding_work_mem-Parameter einstellen, um die Speichermenge anzugeben, die der logische Dekodierungsprozess für den Dekodierungs- und Streaming-Prozess verwenden kann.
Bei der logischen Dekodierung werden Write-Ahead-Log-Datensätze (WAL) in SQL-Anweisungen konvertiert, die dann zur logischen Replikation oder einer anderen Aufgabe an ein anderes Ziel gesendet werden. Wenn eine Transaktion in die WAL geschrieben und dann konvertiert wird, muss die gesamte Transaktion in den für logical_decoding_work_mem angegebenen Wert passen. Standardmäßig ist dieser Parameter auf 65 536 KB eingestellt. Jeder Überlauf wird auf den Datenträger geschrieben. Dies bedeutet, dass es erneut von der Festplatte gelesen werden muss, bevor es an sein Ziel gesendet werden kann, wodurch der Gesamtprozess verlangsamt wird.
Sie können den Betrag des Transaktionsüberlaufs in Ihre aktuelle Workload zu einem bestimmten Zeitpunkt bewerten, indem Sie die aurora_stat_file-Funktion wie im folgenden Beispiel gezeigt, verwenden.
SELECT split_part (filename, '/', 2) AS slot_name, count(1) AS num_spill_files, sum(used_bytes) AS slot_total_bytes, pg_size_pretty(sum(used_bytes)) AS slot_total_size FROM aurora_stat_file() WHERE filename like '%spill%' GROUP BY 1;slot_name | num_spill_files | slot_total_bytes | slot_total_size ------------+-----------------+------------------+----------------- slot_name | 590 | 411600000 | 393 MB (1 row)
Diese Abfrage gibt die Anzahl und Größe der Spill-Dateien auf Ihrem Aurora PostgreSQL DB-Cluster zurück, wenn die Abfrage aufgerufen wird. Bei länger laufenden Workloads befinden sich möglicherweise noch keine Spill-Dateien auf der Festplatte. Um ein Profil lang andauernder Workloads zu erstellen, empfehlen wir Ihnen, eine Tabelle zu erstellen, in der die Informationen der Spill-Datei während der Ausführung der Workload erfasst werden. Sie können die Tabelle wie folgt erstellen.
CREATE TABLE spill_file_tracking AS SELECT now() AS spill_time,* FROM aurora_stat_file() WHERE filename LIKE '%spill%';
Um zu sehen, wie Spill-Dateien während der logischen Replikation verwendet werden, richten Sie einen Publisher und einen Abonnenten ein und starten Sie dann eine einfache Replikation. Weitere Informationen finden Sie unter Einrichten der logischen Replikation für Ihren DB-Cluster von Aurora PostgreSQL. Während der Replikation können Sie einen Auftrag erstellen, der die Ergebnismenge aus der aurora_stat_file()-spill-File-Funktion wie folgt erfasst.
INSERT INTO spill_file_tracking SELECT now(),* FROM aurora_stat_file() WHERE filename LIKE '%spill%';
Verwenden Sie den folgenden psql-Befehl, um den Job einmal pro Sekunde auszuführen.
\watch 0.5
Stellen Sie während der Ausführung des Auftrags eine Verbindung zur Writer-Instance von einer anderen psql-Sitzung her. Verwenden Sie die folgende Reihe von Anweisungen, um eine Workload auszuführen, die die Speicherkonfiguration überschreitet und Aurora PostgreSQL veranlasst, eine Spill-Datei zu erstellen.
labdb=>CREATE TABLE my_table (a int PRIMARY KEY, b int);CREATE TABLElabdb=>INSERT INTO my_table SELECT x,x FROM generate_series(0,10000000) x;INSERT 0 10000001labdb=>UPDATE my_table SET b=b+1;UPDATE 10000001
Diese Anweisungen dauern einige Minuten. Wenn Sie fertig sind, drücken Sie die Strg-Taste und die C-Taste gleichzeitig, um die Überwachungsfunktion zu beenden. Verwenden Sie dann den folgenden Befehl, um eine Tabelle zu erstellen, in der die Informationen über die Verwendung der Spill-Datei des Aurora PostgreSQL DB-Clusters gespeichert werden.
SELECT spill_time, split_part (filename, '/', 2) AS slot_name, count(1) AS spills, sum(used_bytes) AS slot_total_bytes, pg_size_pretty(sum(used_bytes)) AS slot_total_size FROM spill_file_tracking GROUP BY 1,2 ORDER BY 1;spill_time | slot_name | spills | slot_total_bytes | slot_total_size ------------------------------+-----------------------+--------+------------------+----------------- 2022-04-15 13:42:52.528272+00 | replication_slot_name | 1 | 142352280 | 136 MB 2022-04-15 14:11:33.962216+00 | replication_slot_name | 4 | 467637996 | 446 MB 2022-04-15 14:12:00.997636+00 | replication_slot_name | 4 | 569409176 | 543 MB 2022-04-15 14:12:03.030245+00 | replication_slot_name | 4 | 569409176 | 543 MB 2022-04-15 14:12:05.059761+00 | replication_slot_name | 5 | 618410996 | 590 MB 2022-04-15 14:12:07.22905+00 | replication_slot_name | 5 | 640585316 | 611 MB (6 rows)
Die Ausgabe zeigt, dass beim Ausführen des Beispiels fünf Spill-Dateien erstellt wurden, die 611 MB Speicher verbrauchten. Um zu vermeiden, dass auf den Datenträger geschrieben wird, empfehlen wir, den logical_decoding_work_mem-Parameter auf die nächsthöhere Speichergröße, 1024, einzustellen.
