Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Verwalten Aurora PostgreSQL Verbindungsabwanderung mit Pooling
Wenn Clientanwendungen so oft eine Verbindung herstellen und trennen, dass sich die Reaktionszeit des Aurora PostgreSQL DB-Clusters verlangsamt, erfährt der Cluster Verbindungsprobleme. Jede neue Verbindung zum Aurora PostgreSQL DB-Cluster-Endpunkt verbraucht Ressourcen und reduziert so die Ressourcen, die zur Verarbeitung der tatsächlichen Workload verwendet werden können. Verbindungsprobleme sollten Sie anhand einiger der unten beschriebenen bewährten Methoden lösen.
Für den Anfang können Sie die Antwortzeiten auf Aurora PostgreSQL DB-Clustern mit hohen Verbindungsproblemvorkommnissen verbessern. Sie können beispielsweise einen Verbindungspooler wie RDS-Proxy verwenden. Ein Verbindungspooler stellt einen Cache mit gebrauchsfertigen Verbindungen für Clients bereit. Fast alle Versionen von Aurora PostgreSQL unterstützen RDS-Proxy. Weitere Informationen finden Sie unter Amazon-RDS-Proxy mit Aurora PostgreSQL.
Wenn Ihre spezielle Version von Aurora PostgreSQL RDS Proxy nicht unterstützt, können Sie einen anderen PostgreSQL-kompatiblen Verbindungspooler verwenden, z. B. PgBouncer Weitere Informationen finden Sie auf der Website. PgBouncer
Um zu sehen, ob Ihr Aurora-PostgreSQL-DB-Cluster vom Verbindungspooling profitieren kann, können Sie die postgresql.log-Datei für Verbindungen und Verbindungstrennungen prüfen. Sie können Performance Insights auch verwenden, um herauszufinden, wie viel Verbindungsprobleme in Ihrem Aurora PostgreSQL DB-Cluster auftreten. Im Folgenden finden Sie Informationen zu beiden Themen.
Verbindungen und Verbindungstrennungen protokollieren
Die PostgreSQL log_connections- und log_disconnections-Parameter können Verbindungen und Verbindungsabbrüche zur Writer-Instance des Aurora-PostgreSQL-DB-Clusters. Diese Parameter sind standardmäßig deaktiviert. Um diese Parameter zu aktivieren, verwenden Sie eine benutzerdefinierte Parametergruppe, und aktivieren Sie sie, indem Sie den Wert in 1 ändern. Weitere Informationen zu benutzerdefinierten DB-Parametergruppen finden Sie unter DB-Cluster-Parametergruppen für Amazon-Aurora-DB-Cluster. Um die Einstellungen zu überprüfen, stellen Sie mithilfe von psql eine Verbindung zu Ihrem DB-Cluster-Endpunkt für Aurora PostgreSQL her und fragen Sie wie folgt ab.
labdb=>SELECT setting FROM pg_settings WHERE name = 'log_connections';setting --------- on (1 row)labdb=>SELECT setting FROM pg_settings WHERE name = 'log_disconnections';setting --------- on (1 row)
Wenn beide Parameter aktiviert sind, erfasst das Protokoll alle neuen Verbindungen und Verbindungsabbrüche. Sie sehen den Benutzer und die Datenbank für jede neue autorisierte Verbindung. Beim Verbindungstrennungen wird auch die Sitzungsdauer protokolliert, wie im folgenden Beispiel gezeigt.
2022-03-07 21:44:53.978 UTC [16641] LOG: connection authorized: user=labtek database=labdb application_name=psql
2022-03-07 21:44:55.718 UTC [16641] LOG: disconnection: session time: 0:00:01.740 user=labtek database=labdb host=[local]
Um Ihre Anwendung auf Verbindungsprobleme zu überprüfen, aktivieren Sie diese Parameter, falls sie noch nicht aktiviert sind. Sammeln Sie dann Daten im PostgreSQL-Protokoll zur Analyse, indem Sie Ihre Anwendung mit einer realistischen Workload und einem realistischen Zeitraum ausführen. Sie können die Protokolldatei in der RDS-Konsole anzeigen. Wählen Sie die Writer-Instance Ihres Aurora-PostgreSQL-DB-Clusters aus und klicken Sie dann auf den Tab Logs & Ereignisse. Weitere Informationen finden Sie unter Anzeigen und Auflisten von Datenbank-Protokolldateien.
Sie können auch die Protokolldatei von der Konsole herunterladen und die folgende Befehlssequenz verwenden. Diese Sequenz ermittelt die Gesamtzahl der autorisierten und unterbrochenen Verbindungen pro Minute.
grep "connection authorized\|disconnection: session time:" postgresql.log.2022-03-21-16|\ awk {'print $1,$2}' |\ sort |\ uniq -c |\ sort -n -k1
In der Beispielausgabe sehen Sie einen Anstieg der autorisierten Verbindungen, gefolgt von Verbindungsabbrüchen ab 16:12:10.
.....
,......
.........
5 2022-03-21 16:11:55 connection authorized:
9 2022-03-21 16:11:55 disconnection: session
5 2022-03-21 16:11:56 connection authorized:
5 2022-03-21 16:11:57 connection authorized:
5 2022-03-21 16:11:57 disconnection: session
32 2022-03-21 16:12:10 connection authorized:
30 2022-03-21 16:12:10 disconnection: session
31 2022-03-21 16:12:11 connection authorized:
27 2022-03-21 16:12:11 disconnection: session
27 2022-03-21 16:12:12 connection authorized:
27 2022-03-21 16:12:12 disconnection: session
41 2022-03-21 16:12:13 connection authorized:
47 2022-03-21 16:12:13 disconnection: session
46 2022-03-21 16:12:14 connection authorized:
41 2022-03-21 16:12:14 disconnection: session
24 2022-03-21 16:12:15 connection authorized:
29 2022-03-21 16:12:15 disconnection: session
28 2022-03-21 16:12:16 connection authorized:
24 2022-03-21 16:12:16 disconnection: session
40 2022-03-21 16:12:17 connection authorized:
42 2022-03-21 16:12:17 disconnection: session
40 2022-03-21 16:12:18 connection authorized:
40 2022-03-21 16:12:18 disconnection: session
.....
,......
.........
1 2022-03-21 16:14:10 connection authorized:
1 2022-03-21 16:14:10 disconnection: session
1 2022-03-21 16:15:00 connection authorized:
1 2022-03-21 16:16:00 connection authorized:
Anhand dieser Informationen können Sie entscheiden, ob Ihr Workload von einem Verbindungspooler profitieren kann. Für detailliertere Analysen können Sie Performance Insights verwenden.
Erkennen eines Verbindungsproblems mit Performance Insights
Sie können Performance Insights verwenden, um das Ausmaß der Verbindungsabwanderung in Ihrem Aurora PostgreSQL-Compatible Edition-DB-Cluster zu bewerten. Wenn Sie einen Aurora-PostgreSQL-DB-Cluster erstellen, ist die Einstellung für Performance Insights standardmäßig aktiviert. Wenn Sie diese Auswahl beim Erstellen des DB-Clusters deaktiviert haben, ändern Sie Ihren Cluster, um die Funktion zu aktivieren. Weitere Informationen finden Sie unter Ändern eines Amazon Aurora-DB-Clusters.
Wenn Performance Insights auf Ihrem Aurora PostgreSQL DB-Cluster ausgeführt wird, können Sie die Metriken auswählen, die Sie überwachen möchten. Sie können über den Navigationsbereich der -Konsole auf Performance Insights zugreifen. Sie können auch auf Performance Insights vom Tab Überwachung der Writer-Instance für Ihren Aurora PostgreSQL DB-Cluster, wie in der folgenden Abbildung gezeigt, zugreifen.
Wählen Sie in der Performance-Insights-Konsole Metriken verwalten. Wählen Sie die folgenden Metriken aus, um die Verbindungs- und Trennungsaktivitäten Ihres Aurora PostgreSQL DB-Clusters zu analysieren. Dies sind alles Metriken von PostgreSQL.
xact_commit– Die Anzahl von committeter Transaktionen.total_auth_attempts– Die Anzahl von versuchten authentifizierten Benutzerverbindungen pro Minute.numbackends– Die Anzahl der Backends, die derzeit mit der Datenbank verbunden sind.
Wählen Sie zum Speichern der Einstellungen und Anzeigen der Verbindungsaktivität Grafik aktualisieren.
In der folgenden Abbildung sehen Sie die Auswirkungen der Ausführung von pgbench mit 100 Benutzern. Die Linie, die Verbindungen zeigt, ist konstant nach oben geneigt. Weitere Informationen zu pgbench finden Sie unter pgbench
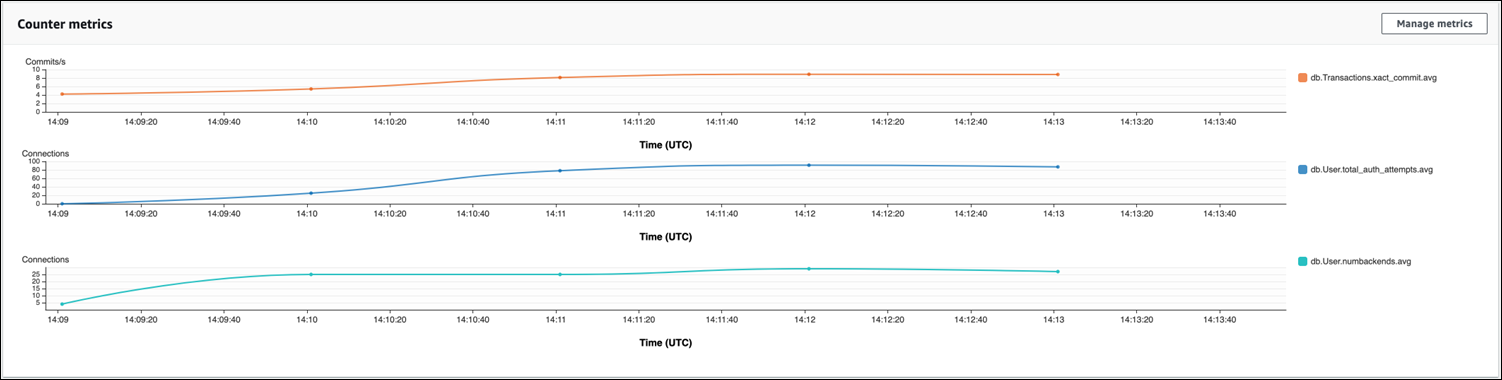
Das Bild zeigt, dass das Ausführen einer Workload mit nur 100 Benutzern ohne Verbindungspooler zu einem signifikanten Anstieg der Anzahl von total_auth_attempts während der gesamten Dauer der Workloadverarbeitung führt. Beachten Sie, dass es am besten ist, total_auth_attempts möglichst bei Null zu halten.
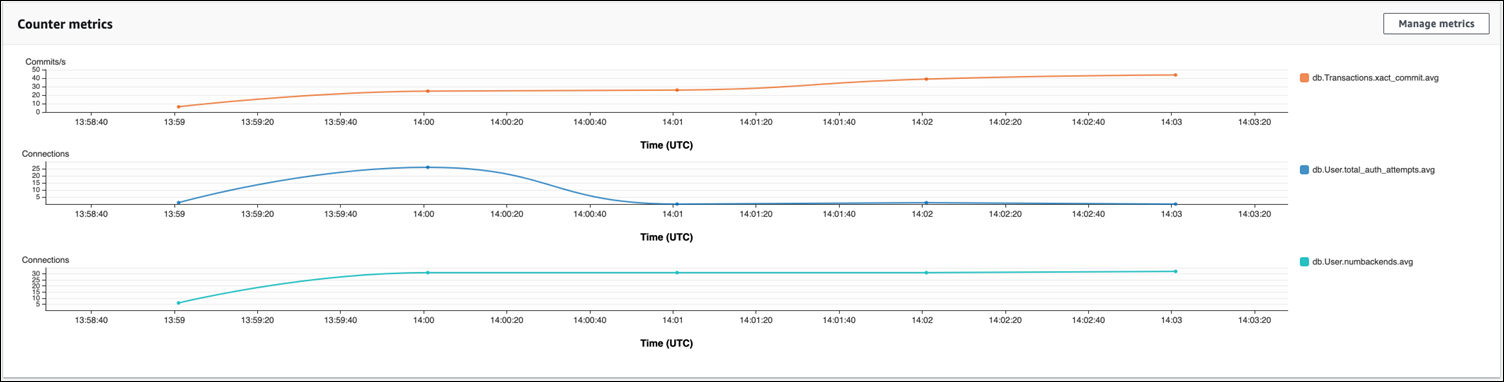
Beim RDS-Proxy-Verbindungspooling nehmen die Verbindungsversuche zu Beginn der Workload zu. Nach dem Einrichten des Verbindungspools sinkt der Durchschnitt. Die für Transaktionen und Backend-Nutzung verwendeten Ressourcen bleiben während der gesamten Workloadverarbeitung konsistent.
Weitere Informationen über die Verwendung von Performance Insights mit Ihrem Aurora-PostgreSQL-DB-Cluster finden Sie unter Überwachung der Datenbanklast mit eingeschaltetem Performance Insights Amazon Aurora. Informationen zum Analysieren der Metriken finden Sie unter Analyse der Metriken mit dem Performance-Insights-Dashboard.
Vorführen der Vorteile von Verbindungspooling
Wie bereits erwähnt, können Sie RDS-Proxy verwenden, um die Leistung zu verbessern, wenn Sie feststellen, dass Ihr Aurora PostgreSQL DB-Cluster ein Verbindungsproblem aufweist. Im Folgenden finden Sie ein Beispiel, das die Unterschiede bei der Verarbeitung einer Workload zeigt, wenn Verbindungen gepoolt werden und wenn sie nicht gepoolt sind. Das Beispiel verwendet pgbench, um einen Transaktionsworkload zu modellieren.
Wie psql ist pgbench eine PostgreSQL-Clientanwendung, die Sie von Ihrem lokalen Client-Computer aus installieren und ausführen können. Sie können es auch über die Amazon-EC2-Instance installieren und ausführen, die Sie für die Verwaltung Ihres Aurora-PostgreSQL-DB-Clusters verwenden. Weitere Informationen finden Sie unter pgbench
Um dieses Beispiel Schritt für Schritt durchzugehen, erstellen Sie zunächst die pgbench-Umgebung in Ihrer Datenbank. Der folgende Befehl ist die grundlegende Vorlage für die Initialisierung der pgbench-Tabellen in der angegebenen Datenbank. In diesem Beispiel wird das standardmäßige Hauptbenutzerkonto, postgres, für die Anmeldung verwendet. Ändern Sie es nach Bedarf für Ihren Aurora-PostgreSQL-DB-Cluster. Sie erstellen die pgbench-Umgebung in einer Datenbank auf der Writer-Instance Ihres Clusters.
Anmerkung
Der Initialisierungsprozess von pgbench löscht Tabellen mit den Namen pgbench_accounts, pgbench_branches, pgbench_history und pgbench_tellers erstellt sie neu. Stellen Sie sicher, dass die Datenbank, die Sie für dbname
pgbench -U postgres -hdb-cluster-instance-1.111122223333.aws-region.rds.amazonaws.com -p 5432 -d -i -s 50dbname
Geben Sie folgende Parameter für pgbench an.
- -d
-
Gibt einen Debugging-Bericht aus, während pgbench ausgeführt wird.
- -h
-
Gibt den Endpunkt der Writer-DB-Instance des Aurora-PostgreSQL-DB-Clusters an.
- -i
-
Initialisiert die pgbench-Umgebung in der Datenbank für die Benchmark-Tests.
- -p
-
Identifiziert den Port, der für Datenbankverbindungen verwendet wird. Die Standardeinstellung für Aurora PostgreSQL ist typischerweise 5432 oder 5433.
- -s
-
Gibt den Skalierungsfaktor an, der zum Füllen der Tabellen mit Zeilen verwendet werden soll. Der Standard-Skalierungsfaktor ist 1, wodurch 1 Zeile in der
pgbench_branches-Tabelle, 10 Zeilen in derpgbench_tellers-Tabelle und 100000 Zeilen in derpgbench_accounts-Tabelle erzeugt werden. - -U
-
Gibt das Benutzerkonto für die Writer-Instance des Aurora-PostgreSQL-DB-Clusters an.
Nachdem die pgbench-Umgebung eingerichtet wurde, können Sie Benchmarking-Tests mit und ohne Verbindungspooling ausführen. Der Standardtest besteht aus einer Reihe von fünf SELECT-, UPDATE- und INSERT-Befehlen pro Transaktion, die für die angegebene Zeit wiederholt ausgeführt werden. Sie können Skalierungsfaktor, Anzahl der Clients und andere Details angeben, um Ihre eigenen Anwendungsfälle zu modellieren.
Der folgende Befehl führt beispielsweise den Benchmark 60 Sekunden lang aus (Option -T, für Zeit) mit 20 gleichzeitigen Verbindungen (Option -c). Mit der Option -C wird der Test jedes Mal mit einer neuen Verbindung ausgeführt, anstatt einmal pro Clientsitzung. Diese Einstellung gibt Ihnen einen Hinweis auf den Verbindungsaufwand.
pgbench -h docs-lab-apg-133-test-instance-1.c3zr2auzukpa.us-west-1.rds.amazonaws.com -U postgres -p 5432 -T 60 -c 20 -C labdbPassword:**********pgbench (14.3, server 13.3) starting vacuum...end. transaction type: <builtin: TPC-B (sort of)> scaling factor: 50 query mode: simple number of clients: 20 number of threads: 1 duration: 60 s number of transactions actually processed: 495 latency average = 2430.798 ms average connection time = 120.330 ms tps = 8.227750 (including reconnection times)
Das Ausführen von pgbench auf der Writer-Instance eines Aurora PostgreSQL DB-Clusters ohne Wiederverwendung von Verbindungen zeigt, dass nur etwa 8 Transaktionen pro Sekunde verarbeitet werden. Dies ergibt insgesamt 495 Transaktionen während des 1-Minutentests.
Wenn Sie Verbindungen wiederverwenden, ist die Antwort des Aurora PostgreSQL DB-Clusters für die Anzahl der Benutzer fast 20-mal schneller. Bei der Wiederverwendung werden insgesamt 9.042 Transaktionen verarbeitet, verglichen mit 495 in derselben Zeit und für dieselbe Anzahl von Benutzerverbindungen. Der Unterschied besteht darin, dass im Folgenden jede Verbindung wiederverwendet wird.
pgbench -h docs-lab-apg-133-test-instance-1.c3zr2auzukpa.us-west-1.rds.amazonaws.com -U postgres -p 5432 -T 60 -c 20 labdbPassword:*********pgbench (14.3, server 13.3) starting vacuum...end. transaction type: <builtin: TPC-B (sort of)> scaling factor: 50 query mode: simple number of clients: 20 number of threads: 1 duration: 60 s number of transactions actually processed: 9042 latency average = 127.880 ms initial connection time = 2311.188 ms tps = 156.396765 (without initial connection time)
Dieses Beispiel zeigt, dass das Pooling von Verbindungen die Reaktionszeiten erheblich verbessern kann. Informationen über die Einrichtung von RDS-Proxy für Ihren Aurora-PostgreSQL-DB-Cluster finden Sie unter Amazon-RDS-Proxy für Aurora.
