Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Durchführen eines Machbarkeitsnachweises mit Amazon Aurora
Im Folgenden wird beschrieben, wie ein Machbarkeitsnachweises für Aurora eingerichtet und ausgeführt wird. Ein Machbarkeitsnachweis ist eine Untersuchung, die Sie selbst durchführen, um herauszufinden, ob Aurora für Ihre Anwendung geeignet ist. Mithilfe des Machbarkeitsnachweises können Sie die Aurora-Funktionen leichter im Rahmen Ihrer eigenen Datenbankanwendungen verstehen und Aurora mit Ihrer aktuellen Datenbankumgebung vergleichen. Er kann auch aufzeigen, wie groß der erforderliche Aufwand für das Verschieben von Daten, Portieren von SQL-Code, Leistungsoptimierung und Anpassen Ihrer aktuellen Verwaltungsverfahren ist.
In diesem Thema finden Sie eine Übersicht und schrittweise Skizzierung der wichtigsten Verfahren und Entscheidungen im Zusammenhang mit der Ausführung eines Machbarkeitsnachweises, wie im Folgenden aufgelistet. Eine ausführliche Anleitung finden Sie unter den Links zur vollständigen Dokumentation für bestimmte Themen.
Übersicht über einen Aurora-Machbarkeitsnachweis
Wenn Sie einen Machbarkeitsnachweis für Amazon Aurora durchführen, lernen Sie, was mit dem Portieren Ihrer vorhanden Daten und SQL-Anwendungen zu Aurora verbunden ist. Sie üben die wichtigsten Aspekte von Aurora im großen Umfang unter Verwendung eines Datenvolumens und von Aktivitäten, die für Ihre Produktionsumgebung repräsentativ sind. Ziel ist es, sich davon zu überzeugen, dass die Vorteile von Aurora den Herausforderungen gewachsen sind, denen Ihre vorherige Datenbankinfrastruktur nicht mehr gerecht wurde. Am Ende des Machbarkeitsnachweises haben Sie einen gründlichen Plan für die Durchführung von Benchmark-Tests und Anwendungstests im größeren Maßstab. An dieser Stelle haben Sie eine Vorstellung von den wichtigsten Arbeitsschritten auf Ihrem Weg zu einer Produktionsbereitstellung.
Mit den folgenden Ratschlägen zu bewährten Methoden lassen sich geläufige Fehler vermeiden, die beim Durchführen von Benchmark-Tests Probleme bereiten können. Dieses Thema behandelt jedoch keine schrittweise Anleitung für Benchmark-Tests und Leistungsoptimierung. Diese Verfahren hängen von Ihrer Workload ab und welche Aurora-Funktionen Sie benutzen. Detaillierte Informationen können Sie der leistungsbezogenen Dokumentation entnehmen, z. B. Verwalten von Performance und Skalierung für einen Aurora-DB-Cluster, Amazon Aurora MySQL-Leistungserweiterungen, Leistung und Skalierung für Amazon Aurora PostgreSQL und Überwachung der Datenbanklast mit eingeschaltetem Performance Insights Amazon Aurora.
Die Informationen in diesem Thema gelten hauptsächlich für Anwendungen, bei denen Ihre Organisation den Code verfasst und das Schema entwirft und von denen die MySQL- und PostgreSQL-Open-Source-Datenbank-Engines unterstützt werden. Wenn Sie eine kommerzielle Anwendung testen oder eine Anwendung, die von einem Anwendungs-Framework generiert wurde, haben Sie möglicherweise nicht die Flexibilität, alle Richtlinien anzuwenden. Erkundigen Sie sich in solchen Fällen bei Ihrem AWS Ansprechpartner, ob es Best Practices oder Fallstudien von Aurora für Ihre Art von Anwendung gibt.
1. Identifizieren Ihrer Ziele
Wenn Sie Aurora als Teil des Machbarkeitsnachweises auswerten, wählen Sie die vorzunehmenden Messungen aus und wie der Erfolg der Übung zu bewerten ist.
Sie müssen sicherstellen, dass die gesamte Funktionalität Ihre Anwendung mit Aurora kompatibel ist. Da die Aurora-Hauptversionen wire-kompatibel mit entsprechenden Hauptversionen von MySQL und PostgreSQL sind, sind die meisten für diese Engines entwickelten Anwendungen ebenfalls mit Aurora kompatibel. Sie müssen die Kompatibilität jedoch weiterhin je nach Anwendung validieren.
So wirken sich beispielsweise einige der Konfigurationsoptionen, die Sie beim Einrichten eines Aurora-Clusters ausgewählt haben, darauf aus, ob Sie bestimmte Datenbankfunktionen verwenden können oder sollten. Sie können mit einem Aurora-Allzweck-Cluster beginnen der als bereitgestellt bezeichnet wird. Danach können Sie entscheiden, ob eine spezialisierte Konfiguration wie z. B. Serverless oder Parallelabfrage Vorteile für Ihre Workload bietet.
Anhand der folgenden Fragen können Sie Ihre Ziele leichter identifizieren und quantifizieren:
-
Unterstützt Aurora alle funktionalen Anwendungsfälle Ihrer Workload?
-
An welcher Datensatzgröße und Laststufe sind Sie interessiert? Können Sie auf diese Stufe skalieren?
-
Was sind Ihre spezifischen Anforderungen für Abfragedurchsatz und Latenz? Können Sie sie erreichen?
-
Was ist die akzeptable Mindestmenge an geplanten oder nicht geplanten Ausfallzeiten für Ihre Workload? Können Sie sie erzielen?
-
Was sind die erforderlichen Metriken für Betriebseffizienz? Können Sie sie genau überwachen?
-
Unterstützt Aurora Ihre spezifischen geschäftlichen Ziele, z. B. Kostenreduzierung, Zunahme der Bereitstellung oder Bereitstellungsgeschwindigkeit? Haben Sie eine Methode zur Quantifizierung dieser Ziele?
-
Können Sie alle Sicherheits- und Compliance-Anforderung für Ihre Workload erfüllen?
Nehmen Sie sich etwas Zeit, sich mit Aurora-Datenbank-Engines und -Plattformfunktionen weiter vertraut zu machen, und sehen Sie Servicedokumentation ein. Notieren Sie sich alle Funktionen, die Ihnen helfen können, die von Ihnen angestrebten Ergebnisse zu erzielen. Eine davon könnte die Workload-Konsolidierung sein, die im AWS Datenbank-Blogbeitrag So planen und optimieren Sie Amazon Aurora mit MySQL-Kompatibilität für konsolidierte Workloads
2. Verständnis der Workload-Eigenschaften
Bewerten Sie Aurora im Kontext Ihres beabsichtigten Anwendungsfalls. Aurora ist eine gute Wahl für Online-Transaktionsverarbeitungs-Workloads (OLTP). Sie können auch Berichte für den Cluster mit den Echtzeit-OLTP-Daten ausführen, ohne einen separaten Data Warehouse-Cluster bereitzustellen. Sie können erkennen, ob Ihr Anwendungsfall in diese Kategorien fällt, indem Sie die folgenden Merkmale überprüfen:
-
Hohe Parallelität mit Dutzenden, Hunderten oder Tausenden gleichzeitigen Clients.
-
Großes Volumen von schneller Abfragen (Millisekunden bis Sekunden).
-
Kurze Echtzeit-Transaktionen.
-
Hoch selektive Abfragemuster mit indexbasierten Suchvorgängen.
-
Für HTAP können analytische Abfragen die Vorteile der Parallelabfrage von Aurora nutzen.
Einer der Schlüsselfaktoren, der bei der Auswahl Ihrer Datenbankoptionen eine Rolle spielt, ist die Geschwindigkeit der Daten. Hohe Geschwindigkeit bedeutet, dass Daten sehr häufig eingefügt und aktualisiert werden. Ein solches System kann Tausende von Verbindungen und Hunderttausende gleichzeitiger Abfragen haben, die gleichzeitig aus einer Datenbank gelesen und in sie geschrieben werden. Abfragen bei Systemen hoher Geschwindigkeit betreffen gewöhnlich eine relativ kleine Anzahl von Zeilen und greifen in der Regel auf mehrere Spalten in derselben Zeile zu.
Aurora ist auf die Verarbeitung von Daten hoher Geschwindigkeit ausgelegt. Abhängig von der Workload kann ein Aurora-Cluster mit einer einzigen r4.16xlarge-DB-Instance mehr als 600 000 SELECT-Anweisungen pro Sekunden verarbeiten. Auch hier kann ein solcher Cluster je nach Workload 200 000 INSERT, UPDATE und DELETE-Anweisungen pro Sekunde verarbeiten. Aurora ist eine Zeilenspeicher-Datenbank und eignet sich ideal für hochvolumige, hochdurchsatzstarke und hochgradig parallelisierte OLTP-Workloads.
Aurora kann außerdem Berichtsabfragen in demselben Cluster durchführen, der die OLTP-Workload verarbeitet. Aurora unterstützt bis zu 15 Replikate, die jeweils innerhalb von 10-20 Millisekunden der primären Instance liegen. Analysten können OLTP-Daten in Echtzeit abfragen, ohne die Daten in einen separaten Data Warehouse-Cluster kopieren zu müssen. Mit Aurora-Clustern, die die Parallelabfragefunktion nutzen, können Sie viele der Verarbeitungs-, Filterungs- und Aggregationsvorgänge in das stark verteilte Aurora-Speichersubsystem verlagern.
Nutzen Sie diese Planungsphase, um sich mit den Funktionen von Aurora, anderen AWS Diensten AWS-Managementkonsole, dem und dem vertraut zu machen AWS CLI. Finden Sie auch heraus, wie diese mit anderen Tools funktionieren, die Sie bei dem Machbarkeitsnachweis verwenden möchten.
3. Üben Sie mit dem AWS-Managementkonsole oder AWS CLI
Üben Sie als nächsten Schritt mit dem AWS-Managementkonsole oder dem AWS CLI, um sich mit diesen Tools und Aurora vertraut zu machen.
Übe mit dem AWS-Managementkonsole
Die folgenden ersten Aktivitäten mit Aurora-Datenbankclustern dienen hauptsächlich dazu, dass Sie sich mit der AWS-Managementkonsole Umgebung vertraut machen und die Einrichtung und Änderung von Aurora-Clustern üben können. Wenn Sie die MySQL-compatible und PostgreSQL-compatible Datenbank-Engines mit Amazon RDS verwenden, können Sie bei der Verwendung von Aurora auf diesem Wissen aufbauen.
Durch Nutzung des freigegebenen Speichermodells von Aurora und von Funktionen wie Replikation und Snapshots können Sie gesamte Datenbank-Cluster wie andere Arten von Objekten verwenden, die Sie ganz nach Wunsch bearbeiten. Sie können Aurora-Cluster während des Machbarkeitsnachweises einrichten, außer Betrieb nehmen und ihre Kapazität häufig ändern. Sie sind nicht an frühzeitige Entscheidungen bezüglich Kapazität, Datenbankeinstellungen und physisches Daten-Layout gebunden.
Richten Sie zum Einsteig einen leeren Aurora-Cluster ein. Wählen Sie als Kapazitätstyp provisioned (bereitgestellt) und unter regional den Standort für Ihre anfänglichen Experimente aus.
Stellen Sie mit einem Client-Programm, wie z. B. einer SQL-Befehlszeilen-Anwendung, eine Verbindung mit diesem Cluster her. Anfänglich stellen Sie eine Verbindung über den Cluster-Endpunkt her. Sie stellen eine Verbindung mit diesem Endpunkt her, um Schreibvorgänge wie Data Definition Language (DDL)-Anweisungen und Extract, Transform, Load (ETL)-Prozesse durchzuführen. An späterer Stelle im Machbarkeitsnachweis verbinden Sie abfrageintensive Sitzungen über den Reader-Endpunkt, der die Abfrage-Workload über mehrere DB-Instances im Cluster verteilt.
Skalieren Sie den Cluster horizontal, indem Sie weitere Aurora Replicas hinzufügen. Informationen zu diesen Verfahren finden Sie unter Replikation mit Amazon Aurora. Skalieren Sie die DB-Instances nach oben oder unten, indem Sie die AWS Instance-Klasse ändern. Verstehen Sie, wie Aurora diese Art von Vorgängen vereinfacht, sodass Sie später nicht wieder von vorne beginnen müssen, sollte Ihre anfängliche Schätzung der Systemkapazität falsch sein.
Erstellen Sie einen Snapshot und stellen Sie ihn in einem anderen Cluster wieder her.
Stellen Sie durch Untersuchen der Cluster-Metriken fest, welche Aktivitäten im Zeitverlauf auftreten und wie sich die Metriken auf die DB-Instances im Cluster beziehen.
Es ist nützlich, sich am Anfang damit vertraut zu machen, wie man diese Dinge macht. AWS-Managementkonsole Wenn Sie die Verwendungsmöglichkeiten von Aurora verstehen, können Sie dazu übergehen, diese Operationen mithilfe der AWS CLI zu automatisieren. In den folgenden Abschnitten finden Sie weitere Informationen zu den Verfahren und bewährten Methoden für diese Aktivitäten während des Machbarkeitsnachweises.
Übe mit dem AWS CLI
Wir empfehlen, Bereitstellungs- und Verwaltungsverfahren selbst im Rahmen eines Machbarkeitsnachweises zu automatisieren. Machen Sie sich dazu mit dem vertraut, AWS CLI falls Sie es noch nicht getan haben. Wenn Sie die MySQL-compatible und PostgreSQL-compatible Datenbank-Engines mit Amazon RDS verwenden, können Sie bei der Verwendung von Aurora auf diesem Wissen aufbauen.
Aurora wirkt sich in der Regel auf Gruppen von DB-Instances aus, die als Cluster angeordnet sind. Viele Operationen bestehen daher daraus, zu bestimmen, welche DB-Instances zu einem Cluster gehören, und dann administrative Operationen als Schleife für alle Instances auszuführen.
Sie können beispielsweise Schritte automatisieren, um Aurora-Cluster zu erstellen und sie dann mit größeren Instance-Klassen nach oben oder mit zusätzlichen DB-Instances horizontal zu skalieren. Auf diese Weise können Sie beliebige Phasen des Machbarkeitsnachweises wiederholen und Was-wäre-wenn-Szenarien mit unterschiedlichen Konfigurationen von Aurora-Clustern zu erkunden.
Machen Sie sich mit den Fähigkeiten und Einschränkungen von Infrastruktur-Bereitstellungstools wie vertrau AWS CloudFormation. Sie stellen möglicherweise fest, dass von Ihnen im Kontext des Machbarkeitsnachweises durchgeführte Aktivitäten nicht für den Produktionseinsatz geeignet sind. Das CloudFormation Verhalten bei Änderungen besteht beispielsweise darin, eine neue Instance zu erstellen und die aktuelle Instance einschließlich ihrer Daten zu löschen. Weitere Einzelheiten zu diesem Verhalten finden Sie unter Aktualisierungsverhalten von Stack-Ressourcen im AWS CloudFormation -Benutzerhandbuch.
4. Erstellen Ihres Aurora-Clusters
Mit Aurora können Sie Was-wäre-wenn-Szenarien erkunden, indem Sie DB-Instances zum Cluster hinzufügen und die DB-Instances auf leistungsfähigere Instance-Klassen hochskalieren. Sie können auch Cluster mit anderen Konfigurationseinstellungen erstellen, um die gleiche Workload parallel auszuführen. Mit Aurora haben Sie sehr viel Flexibilität zum Einrichten, Außerbetriebnehmen und Neukonfigurieren von DB-Clustern. Angesichts dieser Optionen ist es hilfreich, diese Methoden in den frühen Phasen des Machbarkeitsnachweises auszuprobieren. Allgemeine Verfahren zum Erstellen von Aurora-Clustern finden Sie unter Erstellen eines Amazon Aurora-DB Clusters.
Starten Sie nach Möglichkeit mit einem Cluster mit den folgenden Einstellungen. Überspringen Sie diesen Schritt nur, wenn Ihnen bestimmte Anwendungsfälle vorschweben. So können Sie diesen Schritt beispielsweise überspringen, wenn für Ihren Anwendungsfall eine besondere Art von Aurora-Cluster erforderlich ist. Oder Sie können ihn überspringen, wenn Sie an einer bestimmten Kombination von Datenbank-Engine und -Version interessiert sind.
-
Deaktivieren Sie Easy create (Einfache Erstellung). Wir empfehlen, dass Sie sich für den Machbarkeitsnachweis über alle von Ihnen gewählten Einstellungen bewusst sind, sodass Sie anschließend identische oder geringfügig andere Cluster erstellen können.
-
Verwenden Sie eine aktuelle DB-Engine-Version. Diese Kombinationen aus Datenbank-Engine und -Version sind weitgehend mit anderen Aurora-Funktionen kompatibel und werden von Kunden in großem Umfang für Produktionsanwendungen genutzt.
-
Aurora-MySQL-Version 3.x (mit MySQL 8.0 kompatibel)
-
Aurora-PostgreSQL-Version 15.x oder 16.x
-
-
Wählen Sie als Vorlage Dev/Test aus. Die Wahl dieser Option ist für Ihre Machbarkeitsnachweis-Aktivitäten ohne Bedeutung.
-
Wählen Sie für DB instance class (DB-Instance-Klasse) die Option Memory optimized classes (Speicheroptimierte Klassen) und eine der xlarge-Instance-Klassen aus. Sie können die Instance-Klasse zu einem späteren Zeitpunkt nach oben oder unten skalieren.
-
Wählen Sie unter Multi-AZ Deployment die Option Aurora Replica oder Reader Node in einer anderen AZ erstellen aus. Viele der nützlichsten Aspekte von Aurora betreffen Cluster aus mehreren DB-Instances. Es ist sinnvoll, immer mit mindestens zwei DB-Instances in einem neuen Cluster zu beginnen. Beim Testen unterschiedlicher Szenarien mit hoher Verfügbarkeit ist es hilfreich, für die zweite DB-Instance eine andere Availability Zone zu verwenden.
-
Halten Sie sich bei der Wahl von Namen für die DB-Instances an eine generische Namenskonvention. Bezeichnen Sie eine Cluster-DB-Instance nicht als „Writer“, da verschiedene DB-Instances diese Rollen nach Bedarf annehmen. Wir empfehlen, so etwas wie
clustername-az-serialnumberzu verwenden, z. B.myprodappdb-a-01. Durch diese Angaben werden die DB-Instance und ihre Platzierung eindeutig identifiziert. -
Legen Sie eine lange Aufbewahrungsfrist für Backups des Aurora-Clusters fest. Eine lange Aufbewahrungsfrist ermöglicht Ihnen, für einen Zeitraum von bis zu 35 Tagen eine zeitpunktbezogene Wiederherstellung (Point-in-Time Recovery, PITR) durchzuführen. Sie können Ihre Datenbank nach dem Durchführen von Tests mit DDL- und Data Manipulation Language (DML)-Anweisungen auf einen bekannten Zustand zurücksetzen. Eine Wiederherstellung ist auch möglich, wenn Sie versehentlich Daten löschen oder ändern.
-
Aktivieren Sie beim Erstellen des Clusters zusätzliche Wiederherstellungs-, Protokollierungs- und Überwachungsfunktionen. Aktivieren Sie alle Optionen, die unter Rückverfolgung, Performance Insights, Überwachung und Protokollexporte verfügbar sind. Wenn diese Funktionen aktiviert sind, können Sie die Eignung von Funktionen wie Rückverfolgung, erweiterte Überwachung oder Performance Insights for Ihre Workload testen. Auf diese Weise lässt sich während des Machbarkeitsnachweises leicht die Leistung überprüfen und eine Fehlerbehebung durchführen.
5. Einrichten Ihres Schemas
Richten Sie im Aurora-Cluster Datenbanken, Tabellen, Indizes, Fremdschlüssel und andere Schemaobjekte für Ihre Anwendung ein. Wenn Sie von einem anderen System MySQL-compatible oder einem PostgreSQL-compatible Datenbanksystem wechseln, sollten Sie davon ausgehen, dass diese Phase einfach und unkompliziert ist. Sie verwenden für Ihre Datenbank-Engine die gleiche SQL-Syntax und Befehlszeile oder andere Client-Anwendungen, mit denen Sie vertraut sind.
Um SQL-Anweisungen in Ihrem Cluster auszugeben, identifizieren Sie den Cluster-Endpunkt und stellen Sie diesen Wert als Verbindungsparameter für Ihre Client-Anwendung bereit. Sie finden den Cluster-Endpunkt auf der Registerkarte Connectivity (Konnektivität) der Detailseite Ihres Clusters. Der Cluster-Endpunkt ist mit Writer beschriftet. Der andere mit Reader beschriftete Endpunkt stellt eine schreibgeschützte Verbindung dar, die Sie für Endbenutzer bereitstellen können, die Berichte oder andere schreibgeschützte Abfragen ausführen. Unterstützung bei Problemen mit dem Verbinden Ihres Clusters finden Sie unter Herstellen einer Verbindung mit einem Amazon Aurora-DB-Cluster.
Wenn Sie Ihr Schema und Ihre Daten von einem anderen Datenbanksystem portieren, müssen Sie an dieser Stelle wahrscheinlich einige Änderungen am Schema vornehmen. Diese Schemaänderungen sind entsprechend der SQL-Syntax und den Funktionen vorzunehmen, die in Aurora verfügbar sind. An dieser Stelle können Sie bestimmte Spalten, Einschränkungen, Auslöser oder andere Schemaobjekte weglassen. Dies kann insbesondere dann hilfreich sein, wenn für die Aurora-Kompatibilität Änderungen an Objekten erforderlich sind, die für Ihren beabsichtigten Machbarkeitsnachweis jedoch nicht signifikant sind.
Wenn Sie von einem Datenbanksystem mit einer anderen zugrunde liegenden Engine als der von Aurora migrieren, sollten Sie die Verwendung von AWS Schema Conversion Tool (AWS SCT) in Betracht ziehen, um den Prozess zu vereinfachen. Einzelheiten finden Sie im AWS -Schema-Conversion-Tool- Benutzerhandbuch. Allgemeine Informationen zu Migrations- und Portierungsaktivitäten finden Sie im AWS Whitepaper Migrieren Ihrer Datenbanken zu Amazon Aurora
Während dieser Phase können Sie Ihr Schema-Setup auf Ineffizienzen untersuchen, z. B. bei Ihrer Indizierungsstrategie oder bei anderen Tabellenstrukturen, wie z. B. partitionierten Tabellen. Solche Ineffizienzen können verstärkt werden, wenn Sie Ihre Anwendung in einem Cluster mit mehreren DB-Instances und einer hohen Workload bereitstellen. Erwägen Sie, ob Sie solche Aspekte der Leistung zu diesem Zeitpunkt oder bei späteren Aktivitäten wie z. B. einem vollständigen Benchmark-Test, optimieren können.
6. Importieren Ihrer Daten
Während des Machbarkeitsnachweises verlagern Sie die Daten, oder eine repräsentative Stichprobe, von Ihrem ehemaligem Datenbanksystem. Richten Sie nach Möglichkeit mindestens einige Daten in Ihren Tabellen ein. Dadurch wird das Testen der Kompatibilität aller Datentypen und Schema-Funktionen ermöglicht. Wenn Sie eine Übung der grundlegenden Aurora-Funktionen durchgeführt haben, skalieren Sie die Datenmenge nach oben. Zu dem Zeitpunkt, wenn Sie Ihren Machbarkeitsnachweis fertigstellen, sollten Sie Ihre ETL-Tools, Abfragen und Gesamt-Workload mit einem Dataset testen, das groß genug für genaue Schlussfolgerungen ist.
Sie können mehrere Methoden zum Importieren von physischen oder logischen Sicherungsdaten in Aurora verwenden. Einzelheiten finden Sie unter Migrieren von Daten zu einem Amazon Aurora MySQL-DB-Cluster oder Migrieren von Daten nach Amazon Aurora mit PostgreSQL-Kompatibilität, abhängig von der Datenbank-Engine, die Sie bei dem Machbarkeitsnachweis verwenden.
Experimentieren Sie mit den ETL-Tools und Technologien, die Sie in Betracht ziehen. Sehen Sie, welche am besten Ihren Anforderungen genügen. Berücksichtigen Sie sowohl Durchsatz als auch Flexibilität. Einige ETL-Tools führen z. B. einmalige Übertragungen durch, während andere fortlaufende Replikationen von dem alten System zu Aurora umfassen.
Wenn Sie von einem MySQL-compatible System zu Aurora MySQL migrieren, können Sie die nativen Datenübertragungstools verwenden. Das Gleiche gilt, wenn Sie von einem PostgreSQL-compatible System zu Aurora PostgreSQL migrieren. Wenn Sie von einem Datenbanksystem migrieren, das eine andere zugrunde liegende Engine verwendet als Aurora, können Sie mit der AWS Database Migration Service (AWS DMS) experimentieren. Einzelheiten dazu AWS DMS finden Sie im AWS Database Migration Service Benutzerhandbuch.
Einzelheiten zu Migrations- und Portierungsaktivitäten finden Sie im AWS Whitepaper Aurora-Migrationshandbuch
7. Portieren Ihres SQL-Codes
Der zum Ausprobieren von SQL und zugehörigen Anwendungen erforderliche Aufwand variiert je nach den unterschiedlichen Fällen. Der Umfang des Aufwands hängt insbesondere davon ab, ob Sie von einem PostgreSQL-compatible ODER-System MySQL-compatible oder einem anderen System wechseln.
-
Wenn Sie von RDS für MySQL oder RDS für PostgreSQL portieren, sind die SQL-Änderungen klein genug, sodass Sie den SQL-Originalcode mit Aurora ausprobieren und erforderliche Änderungen manuell einfügen können.
-
Wenn Sie von einer lokalen Datenbank portieren, die mit MySQL oder PostgreSQL kompatibel ist, können Sie den SQL-Originalcode ebenfalls ausprobieren und erforderliche Änderungen manuell einfügen.
-
Wenn Sie von einer anderen kommerziellen Datenbank portieren, sind die erforderlichen SQL-Änderungen etwas umfangreicher. Erwägen Sie in diesem Fall die Verwendung von AWS SCT.
Während dieser Phase können Sie Ihr Schema-Setup auf Ineffizienzen untersuchen, z. B. bei Ihrer Indizierungsstrategie oder bei anderen Tabellenstrukturen, wie z. B. partitionierten Tabellen. Erwägen Sie, ob Sie solche Aspekte der Leistung zu diesem Zeitpunkt oder bei späteren Aktivitäten wie z. B. einem vollständigen Benchmark-Test, optimieren können.
Sie können die Logik der Datenbankverbindung in Ihrer Anwendung überprüfen. Um die Vorteile der verteilten Verarbeitung von Aurora nutzen zu können, müssen Sie möglicherweise separate Verbindungen für Lese- und Schreibvorgänge und relativ kurze Sitzungen für Abfrageoperationen verwenden. Weitere Informationen zu Verbindungen finden Sie unter 9. Verbinden mit Aurora.
Überlegen Sie, ob Sie Kompromisse eingehen und Abstriche machen müssen, um in Ihrer Produktionsdatenbank Probleme zu vermeiden. Berücksichtigen Sie in der Zeitplanung des Machbarkeitsnachweises die Vornahme von Verbesserungen am Schemadesign und an Abfragen. Um zu beurteilen, ob sich Leistung, Betriebskosten und Skalierbarkeit leicht verbessern lassen, probieren Sie die ursprünglichen und die abgewandelten Anwendungen nebeneinander in verschiedenen Aurora-Clustern aus.
Einzelheiten zu Migrations- und Portierungsaktivitäten finden Sie im AWS Whitepaper Aurora-Migrationshandbuch
8. Angeben der Konfigurationseinstellungen
Als Teil des Aurora-Machbarkeitsnachweises können Sie auch die Datenbank-Konfigurationsparameter überprüfen. Sie haben Ihre MySQL- oder PostgreSQL-Konfigurationseinstellungen möglicherweise bereits für Leistung und Skalierbarkeit in Ihrer aktuellen Umgebung optimiert. Das Aurora-Speichersubsystem wird für eine verteilte Cloud-basierte Umgebung mit einem Speichersubsystem hoher Geschwindigkeit angepasst und optimiert. Dies hat zur Folge, dass viele ehemaligen Einstellungen der Datenbank-Engine nicht anwendbar sind. Wir empfehlen, Ihre anfänglichen Experimente mit Aurora-Standard-Konfigurationseinstellungen durchzuführen. Wenden Sie Einstellungen von Ihrer aktuellen Umgebung nur dann erneut an, falls Engpässe bezüglich der Leistung und Skalierbarkeit auftreten. Wenn Sie daran interessiert sind, können Sie sich im AWS Datenbank-Blog „Einführung in die Aurora-Speicher-Engine
Aurora erleichtert die Wiederverwendung der optimalen Konfigurationseinstellungen für eine bestimmte Anwendung oder einen bestimmten Anwendungsfall. Anstatt für jede DB-Instance eine separate Konfigurationsdatei zu bearbeiten, verwalten Sie Parametersätze, die Sie ganzen Clustern oder bestimmten DB-Instances zuweisen. So gilt die Zeitzoneneinstellung beispielsweise für alle DB-Instances im Cluster und Sie könne die Größeneinstellung des Seiten-Caches für jede DB-Instance anpassen.
Sie beginnen mit einem der Standard-Parametersätze und wenden nur auf die Parameter Änderungen an, die optimiert werden müssen. Details zur Arbeit mit Parametergruppen finden Sie unter Amazon Aurora-DB-Cluster und DB-Instance-Parameter. Konfigurationseinstellungen, die für Aurora-Cluster anwendbar oder nicht anwendbar sind, finden Sie unter Aurora MySQL Konfigurationsparameter oder Amazon-Aurora-PostgreSQL-Parameter, abhängig von Ihrer Datenbank-Engine.
9. Verbinden mit Aurora
Wie Sie beim Erstellen des anfänglichen Schemas und Daten-Setups und beim Ausführen von Beispielabfragen festgestellt haben, können Sie eine Verbindung mit verschiedenen Endpunkten in einem Aurora-Cluster herstellen. Welcher Endpunkt zu verwenden ist, hängt davon ab, ob die Operation ein Lesevorgang, wie z. B. eine SELECT-Anweisung, oder ein Schreibvorgang, wie z. B. eine CREATE- oder INSERT-Anweisung ist. Während Sie die Workload auf einem Aurora-Cluster erhöhen und mit Aurora-Funktionen experimentieren, ist es wichtig, dass Ihre Anwendung je Operation dem entsprechenden Endpunkt zuweist.
Wenn Sie den Cluster-Endpunkt für Schreibvorgänge verwenden, stellen Sie immer eine Verbindung zu einer DB-Instance im Cluster her, die über entsprechende read/write Funktionen verfügt. Standardmäßig verfügt nur eine DB-Instance in einem Aurora-Cluster über read/write Funktionen. Diese DB-Instance wird als die primäre Instance bezeichnet. Wenn die ursprüngliche primäre Instance ausfällt, aktiviert Aurora einen Failover-Mechanismus und eine andere DB-Instance wird zur primären Instance.
Durch Weiterleiten von SELECT-Anweisungen an den Reader-Endpunkt verteilen Sie gleichermaßen die Arbeit von Verarbeitungsabfragen auf die DB-Instances im Cluster. Mithilfe der Round-Robin-DNS-Auflösung wird jede Reader-Verbindung einer anderen DB-Instance zugewiesen. Wenn die meisten Abfragevorgänge auf den schreibgeschützten DB-Aurora Replicas durchgeführt werden, verringert sich die Last auf der primären Instance, sodass sie mehr DDL- und DML-Anweisungen verarbeiten kann.
Durch Nutzung dieser Endpunkte wird die Abhängigkeit von hartcodierten Hostnamen reduziert und Ihre Anwendung kann bei DB-Instance-Ausfällen schneller wiederhergestellt werden.
Anmerkung
Aurora verfügt auch über benutzerdefinierte Endpunkte, die Sie erstellen. Diese Endpunkte müssen bei einem Machbarkeitsnachweis gewöhnlich nicht berücksichtigt werden.
Die Aurora Replicas unterliegen einer Replica-Verzögerung. Diese Verzögerung dauert gewöhnlich aber nur 10 bis 20 Milliseconds an. Sie können die Replikationsverzögerung überwachen und entscheiden, ob sie innerhalb des Bereichs Ihrer Datenkonsistenzanforderungen liegt. In einigen Fällen erfordern Ihre Leseabfragen unter Umständen starke Lesekonsistenz (Lesen-nach-Schreiben-Konsistenz). In diesen Fällen können Sie für sie weiterhin den Cluster-Endpunkt anstatt des Reader-Endpunkts verwenden.
Um die Aurora-Funktionen bei der verteilten Parallelausführung voll nutzen zu können, müssen Sie möglicherweise Änderungen an der Verbindungslogik vornehmen. Sie möchten vermeiden, dass alle Leseanforderungen an die primäre Instance gesendet werden. Die schreibgeschützten Aurora Replicas stehen mit genau denselben Daten für die Verarbeitung von SELECT-Anweisungen bereit. Kodieren Sie Ihre Anwendungslogik so, dass für jede Art von Vorgang der entsprechende Endpunkt verwendet wird. Befolgen Sie diese allgemeinen Richtlinien:
-
Vermeiden Sie es, eine einzelne hartcodierte Verbindungszeichenfolge für alle Datenbanksitzungen zu verwenden.
-
Sofern praktikabel, schließen Sie Schreiboperationen wie DDL- und DML-Anweisungen in Funktionen in Ihrem Client-Anwendungscode ein. Auf diese Weise können Sie bewirken, dass verschiedene Arten von Vorgängen bestimmte Verbindungen nutzen.
-
Machen Sie separate Funktionen für Abfrageoperationen. Aurora weist jede neue Verbindung mit dem Reader-Endpunkt einem anderen Aurora-Replikat zu, um die Last leseintensiver Anwendungen auszugleichen.
-
Schließen Sie bei Operationen mit Abfragesätzen die Verbindung mit dem Reader-Endpunkt und öffnen Sie sie erneut, wenn jeder Satz zugehöriger Abfragen abgeschlossen wurde. Nutzen Sie Verbindungspooling, sofern diese Funktion in Ihrem Software-Stack verfügbar ist. Durch die Weiterleitung von Abfragen zu verschiedenen Verbindungen kann Aurora die Lese-Workload leichter unter den DB-Instances im Cluster verteilen.
Allgemeine Informationen zur Verbindungsverwaltung und zu Endpunkten für Aurora finden Sie unter Herstellen einer Verbindung mit einem Amazon Aurora-DB-Cluster. Detaillierte Einblicke zu diesem Thema finden Sie in Aurora MySQL Database Administrator’s Handbook – Connection Management
10. Ausführen Ihrer Workload
Wenn Schema, Daten und Konfigurationseinstellungen vorhanden sind, können Sie mit der Arbeit mit dem Cluster beginnen, indem Sie Ihre Workload ausführen. Verwenden Sie im Machbarkeitsnachweis eine Workload, die die Hauptaspekte Ihrer Produktions-Workload widerspiegelt. Wir empfehlen, Entscheidungen über die Leistung immer anhand realer Tests und Workloads zu treffen und nicht anhand synthetischer Benchmarks wie Sysbench oder. TPC-C Sofern praktikabel, erfassen Sie immer Messungen basierend auf eigenem Schema, eigenen Abfragen und eigenen Verwendungsvolumen.
Sofern praktikabel, replizieren Sie die tatsächlichen Bedingungen, unter denen die Anwendung ausgeführt wird. Beispielsweise führen Sie Ihren Anwendungscode in der Regel auf Amazon EC2 EC2-Instances in derselben AWS Region und derselben Virtual Private Cloud (VPC) wie der Aurora-Cluster aus. Wenn Ihre Produktionsanwendung auf mehreren EC2-Instances ausgeführt wird, die sich über mehrere Availability Zones erstrecken, dann richten Sie Ihre Machbarkeitsnachweis-Umgebung genauso ein. Weitere Informationen zu AWS -Regionen finden Sie unter Regionen und Availability Zones im Amazon-RDS-Benutzerhandbuch. Weitere Informationen zum Amazon VPC-Service finden Sie unter Was ist Amazon VPC? im Amazon VPC Benutzerhandbuch.
Nachdem Sie überprüft haben, dass die Grundfunktionen Ihrer Anwendung funktionieren und dass Sie über Aurora auf die Daten zugreifen können, können Sie mit Aspekten des Aurora-Clusters versuchsweise arbeiten. Einige Funktionen, die Sie ausführen sollten, sind gleichzeitige Verbindung mit Load Balancing, gleichzeitige Transaktionen und automatische Replikation.
An dieser Stelle sollten Sie mit den Mechanismen zur Datenübertragung vertraut sein und können mit einem größeren Teil von Beispieldaten Tests ausführen.
In dieser Phase sehen Sie die Auswirkungen von Änderungen an den Konfigurationseinstellungen, wie z. B. Speicherlimits und Verbindungslimits. Betrachten Sie sich erneut die Verfahren, die Sie unter erkundet habe 8. Angeben der Konfigurationseinstellungen.
Sie können auch mit Mechanismen wie Erstellen und Wiederherstellen von Snapshots experimentieren. Sie können beispielsweise Cluster mit unterschiedlichen AWS Instanzklassen, der Anzahl von AWS Replikaten usw. erstellen. Sie können dann auf jedem Cluster den gleichen Snapshot mit Ihrem Schema und allen Ihren Daten wiederherstellen. Einzelheiten zu diesem Zyklus finden Sie unter Erstellen eines DB-Cluster-Snapshots and Wiederherstellen aus einem DB-Cluster-Snapshot.
11. Messen der Leistung
Die bewährten Methoden in diesem Bereich sollen sicherstellen, dass die richtigen Tools und Prozesse eingerichtet werden, um anormales Verhalten während Workload-Vorgängen schnell aufzudecken. Sie sollen außerdem gut sichtbar sein, sodass Sie alle zutreffenden Ursachen zuverlässig identifizieren können.
Durch Ansicht der Registerkarte Monitoring (Überwachung) können Sie immer den aktuellen Zustand des Clusters sehen oder Trends im Zeitverlauf analysieren. Diese Registerkarte ist über die Detailseite der Konsole für jeden Aurora-Cluster oder jede DB-Instance verfügbar. Es zeigt Metriken des CloudWatch Amazon-Überwachungsdienstes in Form von Diagrammen an. Sie können die Metriken nach Name, DB-Instance und Zeitraum filtern.
Wenn sich weitere Optionen auf der Registerkarte Monitoring (Überwachung) befinden, aktivieren Sie "Enhanced Monitoring (Erweiterte Überwachung)" und "Performance Insights" in den Cluster-Einstellungen. Sie können diese Optionen auch zu einem späteren Zeitpunkt aktvieren, sofern Sie sie beim Einrichten des Clusters nicht ausgewählt haben.
Zum Messen der Leistung stützen Sie sich größtenteils auf die Diagramme der Aktivitäten für den gesamten Aurora-Cluster. Sie können überprüfen, ob die Aurora Replicas ähnliche Lade- und Antwortzeiten aufweisen. Sie können auch sehen, wie die Arbeit zwischen der read/write primären Instance und den schreibgeschützten Aurora Replicas aufgeteilt ist. Bei einem Ungleichgewicht zwischen den DB-Instances oder bei einem Problem mit nur einer DB-Instance können Sie die Registerkarte Monitoring (Überwachung) bezüglich dieser spezifischen Instance untersuchen.
Nachdem die Umgebung und die tatsächliche Workload zum Emulieren Ihrer Produktionsumgebung eingerichtet wurden, können Sie die Leistung von Aurora messen. Die wichtigsten zu beantwortenden Fragen sind:
-
Wie viele Abfragen pro Sekunden werden von Aurora verarbeitet? Sie können den Throughput (Durchsatz)-Metriken die Werte für verschiedene Arten von Vorgängen entnehmen.
-
Wie lange braucht Aurora durchschnittlich zum Verarbeiten einer gegebenen Abfrage? Sie können den Latency (Latenz)-Metriken die Werte für verschiedene Arten von Vorgängen entnehmen.
Um die Durchsatz- und Latenzmetriken einzusehen, gehen Sie zur Registerkarte Überwachung für einen bestimmten Aurora-Cluster in der Amazon-RDS-Konsole
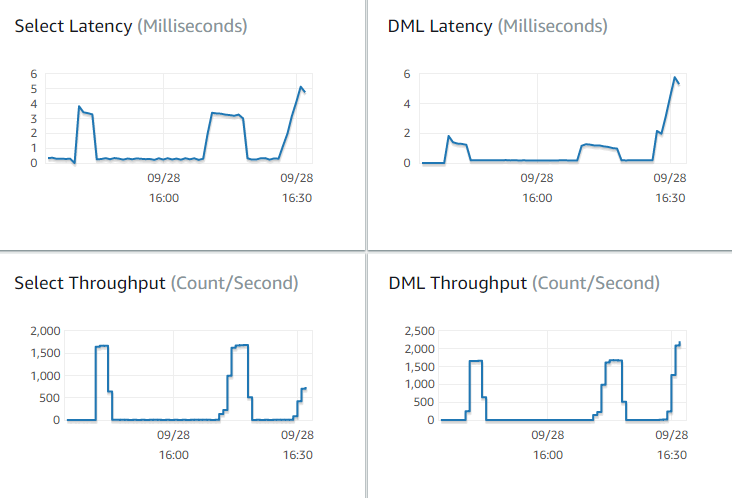
Wenn möglich, stellen Sie Baseline-Werte für diese Metriken in Ihrer aktuellen Umgebung auf. Wenn dies nicht praktikabel ist, erstellen Sie eine Baseline für den Aurora-Cluster, indem Sie eine Workload entsprechend Ihrer Produktionsanwendung ausführen. Führen Sie beispielsweise Ihre Aurora-Workload mit einer ähnlichen Anzahl gleichzeitiger Benutzer und Abfragen aus. Beobachten Sie dann, wie sich die Werte ändern, während Sie mit verschiedenen Instance-Klassen, Cluster-Größen, Konfigurationseinstellungen usw. experimentieren.
Wenn die Durchsatzwerte niedriger als erwartet sind, untersuchen Sie näher, welche Faktoren sich auf die Datenbank-Leistung Ihrer Workload auswirken. Untersuchen Sie höher als erwartete Latenzwerte gleichermaßen näher. Überwachen Sie hierzu die sekundären Metriken für den DB-Server (CPU, Arbeitsspeicher usw.). Sie können erkennen, ob sich die DB-Instances an ihre Grenzwerte annähern. Auch ist ersichtlich, über wie viel extra Kapazität Ihre DB-Instances für die Verarbeitung weiterer gleichzeitiger Abfragen, Abfragen großer Tabellen usw. verfügt.
Tipp
Richten Sie Alarme ein, um Metrikwerte zu erkennen, die außerhalb der erwarteten Bereiche liegen. CloudWatch
Wenn Sie die ideale Aurora-Cluster-Größe und -Kapazität bewerten, können Sie herausfinden, mit welcher Konfiguration die Spitzenleistung der Anwendung erzielt wird, ohne unnötige Ressourcen bereitzustellen. Ein wichtiger Faktor ist, die angemessene Größe für die DB-Instances im Aurora-Cluster zu finden. Beginnen Sie mit der Wahl einer Instance-Größe mit einer ähnlichen CPU- und Arbeitsspeicher-Kapazität wie Ihre aktuelle Produktionsumgebung. Erfassen Sie Durchsatz- und Latenzwerte für die Workload bei dieser Instance-Größe. Skalieren Sie die Instance dann nach oben auf die nächste Größe. Überprüfen Sie, ob sich die Durchsatz- und Latenzwerte bessern. Skalieren Sie die Instance auch nach unten. Überprüfen Sie, ob die Latenz- und Durchsatzwerte gleich bleiben. Unser Ziel ist, den höchsten Durchsatz bei der geringsten Latenz für die kleinst mögliche Instance zu erreichen.
Tipp
Bemessen Sie Ihre Aurora-Cluster und zugehörigen DB-Instances mit genug vorhandener Kapazität, um plötzlichen, nicht vorhersehbaren Datenverkehrsspitzen gewachsen zu sein. Belassen Sie für geschäftskritische Datenbanken mindestens 20 Prozent an Extrakapazität für CPU und Arbeitsspeicher.
Führen Sie Leistungstests lange genug aus, sodass die Datenbankleistung in einem warmen, stabilen Zustand gemessen wird. Sie müssen die Workload viele Minuten oder sogar einige Stunden lang ausführen, bis dieser stabile Zustand erreicht wird. Gewisse Abweichungen am Anfang der Ausführung sind normal. Diese Abweichungen sind dadurch bedingt, dass jedes Aurora Replica seinen Zwischenspeicher basierend auf den verarbeiteten SELECT-Abfragen aufwärmt.
Aurora weist die beste Leistung bei transaktionalen Workloads mit mehreren gleichzeitigen Benutzern und Abfragen auf. Um sicherzustellen, dass die verarbeitete Last für eine optimale Leistung ausreicht, führen Sie Benchmark-Tests mit Multithreading oder mehrere Instances von Leistungstests gleichzeitig aus. Messen Sie die Leistung mit Hunderten oder sogar Tausenden gleichzeitiger Client-Threads. Simulieren Sie die Anzahl gleichzeitiger Threads, die Sie in Ihrer Produktionsumgebung erwarten. Sie können auch zusätzliche Stresstests mit weiteren Threads durchführen, um die Aurora-Skalierbarkeit zu messen.
12. Ausführen der Aurora-Hochverfügbarkeit
Viele der Hauptfunktionen von Aurora umfassen hohe Verfügbarkeit. Zu diesen Funktionen gehören automatische Replikation, automatisches Failover, automatische Backups mit zeitbezogener Wiederherstellung und die Fähigkeit zum Hinzufügen von DB-Instances zum Cluster. Die Sicherheit und Zuverlässigkeit von Funktionen wie diesen ist für geschäftskritische Anwendungen wichtig.
Die Auswertung dieser Funktionen erfordert eine bestimmte Denkweise. Bei früheren Aktivitäten, wie Leistungsmessungen, beobachten Sie die Systemleistung, wenn alles richtig funktioniert. Beim Testen der hohen Verfügbarkeit müssen Sie Verhalten im Schlimmstfall durchdenken. Sie müssen sich verschiedene Arten von Fehlern vorstellen, selbst wenn solche Bedingungen nur selten auftreten. Sie führen möglicherweise absichtlich Probleme herbei, um sicherzustellen, dass der Systembetrieb richtig und schnell wiederhergestellt wird.
Tipp
Richten Sie für einen Machbarkeitsnachweis alle DB-Instances in einem Aurora-Cluster mit derselben AWS Instance-Klasse ein. Dadurch ist es möglich, Aurora-Verfügbarkeitsfunktionen ohne große Änderungen an der Leistung und Skalierbarkeit auszuprobieren, während Sie DB-Instances offline nehmen, um Fehler zu simulieren.
Wir empfehlen, in jedem Aurora-Cluster mindestens zwei Instances zu verwenden. Die DB-Instances in einem Aurora-Cluster können sich über bis zu drei Availability Zones (AZs) erstrecken. Suchen Sie jede der ersten zwei oder drei DB-Instances in einer anderen AZ. Wenn Sie beginnen, größere Cluster zu verwenden, verteilen Sie Ihre DB-Instances auf alle AZs in Ihrer AWS Region. Dadurch wird die Fähigkeit zur Fehlertoleranz erhöht. Wenn sich ein Problem auf die gesamte AZ auswirkt, kann Aurora ein Failover auf eine DB-Instance in einer anderen AZ durchführen. Wenn Sie einen Cluster mit mehr als drei Instances ausführen, verteilen Sie die DB-Instances so gleichmäßig wie möglich über alle drei AZs.
Tipp
Der Speicher eines Aurora-Clusters ist unabhängig von den DB-Instances. Der Speicher eines jeden Aurora-Clusters erstreckt sich immer über drei AZs.
Wenn Sie die Funktionen für hohe Verfügbarkeit testen, verwenden Sie immer DB-Instances mit identischer Kapazität in Ihrem Test-Cluster. Dadurch lassen sich unvorhersehbare Änderungen in Leistung, Latenz usw. vermeiden, wenn eine DB-Instance die Rolle einer anderen übernimmt.
Informationen zum Simulieren von Fehlerbedingungen zum Testen von Funktionen für hohe Verfügbarkeit finden Sie unter Testen von Amazon Aurora MySQL unter Verwendung von Fehlersimulationsabfragen.
Als Teil Ihrer Machbarkeitsnachweis-Übung besteht ein Ziel darin, die ideale Anzahl von DB-Instances und die optimale Instance-Klasse für diese DB-Instances zu finden. Dazu müssen die Anforderungen für hohe Verfügbarkeit und für Leistung gegeneinander abgewogen werden.
Für Aurora gilt, dass je mehr DB-Instances sich in einem Cluster befinden, desto höher die Vorteile für hohe Verfügbarkeit sind. Mehr DB-Instances verbessern auch die Skalierbarkeit von leseintensiven Anwendungen. Aurora kann mehrere Verbindungen für SELECT-Abfragen unter den schreibgeschützten Aurora-Replikaten verteilen.
Andererseits wird durch Einschränken der Anzahl von DB-Instances der Replikationsdatenverkehr vom primären Knoten verringert. Der Replikationsdatenverkehr belegt Netzwerkbandbreite, wobei es sich um einen weiteren Aspekt der Gesamtleistung und Skalierbarkeit handelt. Daher ist bei schreibintensiven OLTP-Anwendungen eine kleiner Anzahl großer DB-Instances gegenüber vielen kleinen DB-Instances vorzuziehen.
In einem typischen Aurora-Cluster verarbeitet eine DB-Instance (die primäre Instance) alle DDL- und DML-Anweisungen. Die anderen DB-Instances (die Aurora Replicas) verarbeiten nur SELECT-Anweisungen. Obwohl die DB-Instances nicht genau die gleichen Aufgaben ausführen, raten wir zur Verwendung der gleichen Instance-Klasse für alle DB-Instances im Cluster. Wenn Aurora im Falle eines Ausfalls eine der schreibgeschützten DB-Instances auf die neue primäre Instance hochstuft, hat die primäre Instance auf diese Weise die gleiche Kapazität wie zuvor.
Wenn Sie in demselben Cluster DB-Instances unterschiedlicher Kapazitäten verwenden möchten, richten Sie Failover-Stufen für die DB-Instances ein. Diese Stufen bestimmen die Reihenfolge, in der Aurora Replicas durch den Failover-Mechanismus hochgestuft werden. Platzieren Sie DB-Instances, die sehr viel größer oder kleiner als die anderen sind, in eine niedrigere Failover-Stufe. Dadurch wird sichergestellt, dass sie zuletzt zum Hochstufen ausgewählt werden.
Führen Sie Übungen mit den Wiederherstellungsfunktionen von Aurora, wie automatische zeitbezogene Wiederherstellung, manuelle Snapshots und Wiederherstellung und Cluster-Rückverfolgung, durch. Kopieren Sie gegebenenfalls Snapshots in andere AWS Regionen und stellen Sie sie in anderen AWS Regionen wieder her, um DR-Szenarien nachzuahmen.
Untersuchen Sie die Anforderungen Ihrer Organisation bezüglich Wiederherstellungsdauer (Restore Time Objective, RTO), Wiederherstellungspunkt (Restore Point Objective, RPO) und geografischer Redundanz. Die meisten Organisationen gruppieren diese Elemente unter der großen Kategorie der Notfallwiederherstellung. Bewerten Sie die Aurora-Funktionen für hohe Verfügbarkeit, die in diesem Abschnitt beschrieben werden, im Kontext Ihres Prozesses zur Notfallwiederherstellung, um sicherzustellen,dass Ihre RTO- und RPO-Anforderungen erfüllt werden.
13. Weitere Vorgehensweisen
Am Ende eines erfolgreichen Machbarkeitsnachweises bestätigen Sie, dass Aurora basierend auf der erwarteten Workload eine geeignete Lösung für Sie ist. Durchweg durch den voranstehenden Prozess haben Sie überprüft, wie Aurora in einer realistischen Betriebsumgebung funktioniert und anhand Ihrer Erfolgskriterien gemessen.
Sobald Ihre Datenbankumgebung mit Aurora betriebsbereit ist, können Sie mit detaillierten Evaluierungsschritten fortfahren, die zu Ihrer endgültigen Migration und Produktionsbereitstellung führen. Abhängig von Ihrer Situation sind diese anderen Schritte nicht unbedingt Teil des Machbarkeitsnachweises. Einzelheiten zu Migrations- und Portierungsaktivitäten finden Sie im AWS Whitepaper Aurora-Migrationshandbuch
Erwägen Sie in einem anderen Schritt die Sicherheitskonfigurationen, die für Ihre Workload relevant sind und darauf ausgelegt sind, Ihre Sicherheitsanforderungen in einer Produktionsumgebung zu erfüllen. Planen Sie, welche Kontrollen zum Schutz des Zugriffs auf die Masterbenutzeranmeldedaten des Aurora-Clusters implementiert werden sollen. Definieren Sie die Rollen und Zuständigkeiten von Datenbankbenutzern, um den Zugriff auf die im Aurora-Cluster gespeicherten Daten zu kontrollieren. Berücksichtigen Sie Datenbank-Zugriffsanforderungen für Anwendungen, Skripts und Drittanbieter-Tools und -Services. Informieren Sie sich über AWS Dienste und Funktionen wie die AWS Identity and Access Management (IAM AWS Secrets Manager -) Authentifizierung.
An dieser Stelle sollten Sie die Verfahren und bewährten Methoden für die Ausführung von Benchmark-Tests mit Aurora verstehen. Sie stellen möglicherweise fest, dass eine zusätzliche Leistungsoptimierung erforderlich ist. Einzelheiten finden Sie unter Verwalten von Performance und Skalierung für einen Aurora-DB-Cluster, Amazon Aurora MySQL-Leistungserweiterungen, Leistung und Skalierung für Amazon Aurora PostgreSQL und Überwachung der Datenbanklast mit eingeschaltetem Performance Insights Amazon Aurora. Wenn Sie eine zusätzliche Optimierung vornehmen, stellen Sie sicher, dass Sie mit den Metriken vertraut sind, die Sie während des Machbarkeitsnachweises erfasst haben. Als nächster Schritt können Sie neue Cluster mit verschiedenen Optionen für Konfigurationseinstellungen, Datenbank-Engine und Datenbankversion erstellen. Oder Sie können spezialisierte Arten von Aurora-Clustern erstellen, um die Anforderungen bestimmter Anwendungsfälle zu erfüllen.
Sie können beispielsweise Aurora-Parallel-Abfragecluster für Hybrid transaction/analytical Processing (HTAP) -Anwendungen untersuchen. Wenn eine breite geografische Verteilung für die Notfallwiederherstellung oder zum Minimieren der Latenz von zentraler Bedeutung ist, können Sie globale Aurora-Datenbanken erkunden. Wenn Ihre Arbeitslast intermittierend ist oder Sie Aurora in einem development/test Szenario verwenden, können Sie Aurora Serverless Cluster untersuchen.
Ihre Produktions-Cluster müssen möglicherweise auch eingehende Verbindungen hohen Umfangs verarbeiten. Informationen zu diesen Techniken finden Sie im AWS Whitepaper Aurora MySQL Database Administrator's Handbook — Connection management
Wenn Sie nach dem Machbarkeitsnachweis beschließen, dass Ihr Anwendungsfall nicht für Aurora geeignet ist, erwägen Sie die folgenden anderen AWS -Services:
-
Für rein analytische Anwendungsfälle profitieren Workloads von einem spaltenförmigen Speicherformat und anderen Funktionen, die besser für OLAP-Workloads geeignet sind. AWS Zu den Diensten, die sich mit solchen Anwendungsfällen befassen, gehören die folgenden:
-
Viele Workloads profitieren von einer Kombination aus Aurora mit einem oder mehreren dieser Services. Sie können Daten mit den folgenden Methoden zwischen diesen Services verschieben:
-
Importieren aus Amazon S3, wie im Amazon Aurora Benutzerhandbuch beschrieben
-
Exportieren zu Amazon S3, wie im Amazon Aurora Benutzerhandbuch beschrieben
-
Viele andere gängige ETL-Tools
