Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Daten zu einer Quelle hinzufügen Aurora-DB-Cluster und es abzufragen
Zum Erstellen einer Null-ETL-Integration, die Daten von Amazon Aurora in Amazon Redshift repliziert, müssen Sie eine Datenbank im Ziel erstellen.
Stellen Sie für Verbindungen mit Amazon Redshift zunächst eine Verbindung mit Ihrem Amazon-Redshift-Cluster oder Ihrer Arbeitsgruppe her und erstellen Sie eine Datenbank mit einem Verweis auf Ihre Integrations-ID. Anschließend können Sie Daten zum Quell-DB-Cluster von Aurora hinzufügen und diese in Amazon Redshift oder Amazon SageMaker replizieren.
Themen
Erstellen einer Zieldatenbank
Bevor Sie nach der Erstellung einer Integration mit der Replikation von Daten in Amazon Redshift beginnen können, müssen Sie in Ihrem Ziel-Data-Warehouse eine Datenbank erstellen. Diese Datenbank muss einen Verweis auf die Integrations-ID enthalten. Sie können die Amazon-Redshift-Konsole oder Query Editor v2 verwenden, um die Datenbank zu erstellen.
Anleitungen zum Erstellen einer Zieldatenbank finden Sie unter Erstellen einer Zieldatenbank in Amazon Redshift.
Daten zur Quelle hinzufügen DB-Cluster
Nachdem Sie Ihre Integration konfiguriert haben, können Sie den Quell-DB-Cluster von Aurora mit Daten füllen, die Sie in Ihr Data Warehouse replizieren möchten.
Anmerkung
Es gibt Unterschiede zwischen den Datentypen in Amazon Aurora und dem Ziel-Analyse-Warehouse. Eine Tabelle mit Datentypzuordnungen finden Sie unter Unterschiede zwischen den Datentypen Aurora und Amazon Redshift Redshift-Datenbanken.
Stellen Sie zunächst mit dem MySQL- oder PostgreSQL-Client Ihrer Wahl eine Verbindung zum Quell-DB-Cluster her. Anleitungen finden Sie unter Herstellen einer Verbindung mit einem Amazon Aurora-DB-Cluster.
Erstellen Sie dann eine Tabelle und fügen Sie eine Zeile mit Beispieldaten ein.
Wichtig
Stellen Sie sicher, dass die Tabelle über einen Primärschlüssel verfügt. Andernfalls kann sie nicht in das Ziel-Data-Warehouse repliziert werden.
Die PostgreSQL-Dienstprogramme pg_dump und pg_restore erstellen zunächst Tabellen ohne Primärschlüssel und fügen ihn anschließend hinzu. Wenn Sie eines dieser Dienstprogramme verwenden, empfehlen wir, zuerst ein Schema zu erstellen und dann Daten in einem separaten Befehl zu laden.
MySQL
Im folgenden Beispiel wird das Dienstprogramm MySQL Workbench
CREATE DATABASEmy_db; USEmy_db; CREATE TABLEbooks_table(ID int NOT NULL, Title VARCHAR(50) NOT NULL, Author VARCHAR(50) NOT NULL, Copyright INT NOT NULL, Genre VARCHAR(50) NOT NULL, PRIMARY KEY (ID)); INSERT INTObooks_tableVALUES (1, 'The Shining', 'Stephen King', 1977, 'Supernatural fiction');
PostgreSQL
Das folgende Beispiel verwendet das interaktive PostgreSQL-Terminal psql. Schließen Sie beim Herstellen einer Verbindung mit dem Cluster die benannte Datenbank ein, die Sie beim Erstellen der Integration angegeben haben.
psql -hmycluster.cluster-123456789012.us-east-2.rds.amazonaws.com -p 5432 -Uusername-dnamed_db; named_db=> CREATE TABLEbooks_table(ID int NOT NULL, Title VARCHAR(50) NOT NULL, Author VARCHAR(50) NOT NULL, Copyright INT NOT NULL, Genre VARCHAR(50) NOT NULL, PRIMARY KEY (ID)); named_db=> INSERT INTObooks_tableVALUES (1, 'The Shining', 'Stephen King', 1977, 'Supernatural fiction');
Abfragen Ihres Aurora Daten in Amazon Redshift
Nachdem Sie Daten zum Aurora-DB-Cluster hinzugefügt haben, werden sie in die Zieldatenbank repliziert und können abgefragt werden.
So fragen Sie die replizierten Daten ab
-
Navigieren Sie zur Amazon Redshift-Konsole und wählen Sie im linken Navigationsbereich die Option Query Editor v2 aus.
-
Stellen Sie eine Verbindung mit Ihrem Cluster oder Ihrer Arbeitsgruppe her und wählen Sie Ihre aus der Integration erstellte Datenbank im Dropdown-Menü aus (destination_database in diesem Beispiel). Anleitungen zum Erstellen einer Zieldatenbank finden Sie unter Erstellen einer Zieldatenbank in Amazon Redshift.
-
Verwenden Sie eine SELECT-Anweisung, um Ihre Daten abzufragen. In diesem Beispiel können Sie den folgenden Befehl ausführen, um alle Daten aus der Tabelle auszuwählen, die Sie im Quell-DB-Cluster von Aurora erstellt haben:
SELECT * frommy_db."books_table";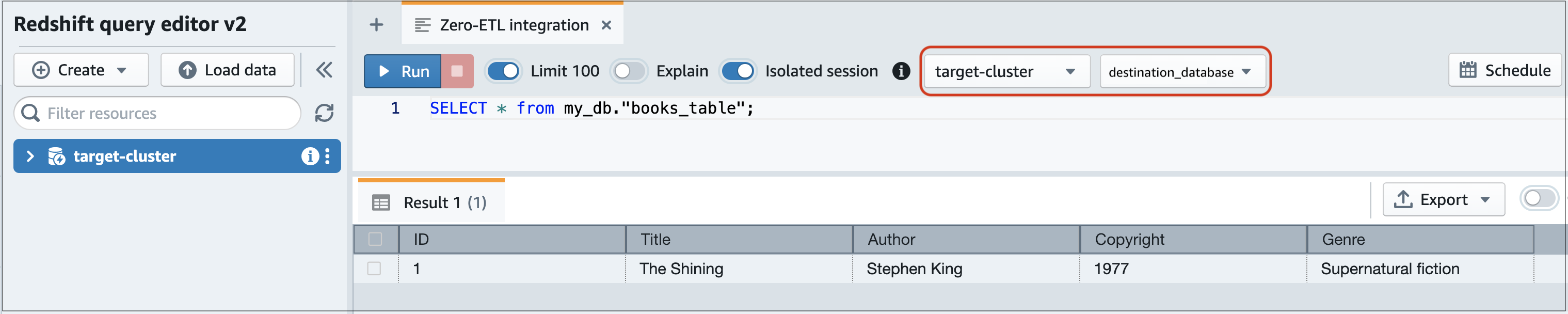
-
my_db -
books_table
-
Sie können die Daten auch mit einem Befehlszeilen-Client abfragen. Beispiel:
destination_database=# select * frommy_db."books_table"; ID | Title | Author | Copyright | Genre | txn_seq | txn_id ----+–------------+---------------+-------------+------------------------+----------+--------+ 1 | The Shining | Stephen King | 1977 | Supernatural fiction | 2 | 12192
Anmerkung
Um zwischen Groß- und Kleinschreibung zu unterscheiden, verwenden Sie doppelte Anführungszeichen (" ") für Schema-, Tabellen- und Spaltennamen. Weitere Informationen finden Sie unter enable_case_sensitive_identifier.
Unterschiede zwischen den Datentypen Aurora und Amazon Redshift Redshift-Datenbanken
Die folgenden Tabellen zeigen die Zuordnungen der Datentypen von Aurora MySQL und Aurora PostgreSQL zu den entsprechenden Zieldatentypen. Amazon Aurora unterstützt derzeit nur diese Datentypen für Null-ETL-Integrationen.
Wenn eine Tabelle in dem Quell-DB-Cluster einen nicht unterstützten Datentyp enthält, wird die Tabelle nicht synchronisiert und kann vom Ziel nicht genutzt werden. Das Streaming von der Quelle zum Ziel wird fortgesetzt, aber die Tabelle mit dem nicht unterstützten Datentyp ist nicht verfügbar. Um die Tabelle zu reparieren und im Ziel verfügbar zu machen, müssen Sie die grundlegende Änderung manuell rückgängig machen und dann die Integration aktualisieren, indem Sie ALTER DATABASE...INTEGRATION
REFRESH ausführen.
Anmerkung
Null-ETL-Integrationen mit einem Amazon SageMaker-Lakehouse können nicht aktualisiert werden. Löschen Sie stattdessen die Integration und erstellen Sie sie erneut.
Aurora MySQL
| Aurora-MySQL-Datentyp | Zieldatentyp | Description | Einschränkungen |
|---|---|---|---|
| INT | INTEGER | 4-Byte-Ganzzahl mit Vorzeichen | Keine |
| SMALLINT | SMALLINT | 2-Byte-Ganzzahl mit Vorzeichen | Keine |
| TINYINT | SMALLINT | 2-Byte-Ganzzahl mit Vorzeichen | Keine |
| MEDIUMINT | INTEGER | 4-Byte-Ganzzahl mit Vorzeichen | Keine |
| BIGINT | BIGINT | 8-Byte-Ganzzahl mit Vorzeichen | Keine |
| INT UNSIGNED | BIGINT | 8-Byte-Ganzzahl mit Vorzeichen | Keine |
| TINYINT UNSIGNED | SMALLINT | 2-Byte-Ganzzahl mit Vorzeichen | Keine |
| MEDIUMINT UNSIGNED | INTEGER | 4-Byte-Ganzzahl mit Vorzeichen | Keine |
| BIGINT UNSIGNED | DECIMAL(20,0) | Genauer Zahlenwert mit wählbarer Genauigkeit | Keine |
| DECIMAL(P,S) = NUMERIC(P,S) | DECIMAL (p,s) | Genauer Zahlenwert mit wählbarer Genauigkeit |
Eine Genauigkeit von mehr als 38 und eine Skalierung von mehr als 37 werden nicht unterstützt. |
| DECIMAL(P,S) UNSIGNED = NUMERIC(P,S) UNSIGNED | DECIMAL (p,s) | Genauer Zahlenwert mit wählbarer Genauigkeit |
Eine Genauigkeit von mehr als 38 und eine Skalierung von mehr als 37 werden nicht unterstützt. |
| FLOAT4/REAL | REAL | Gleitkommazahl mit einfacher Genauigkeit | Keine |
| FLOAT4/REAL UNSIGNIERT | REAL | Gleitkommazahl mit einfacher Genauigkeit | Keine |
| DOUBLE/REAL/FLOAT8 | DOUBLE PRECISION | Double (Gleitkommazahl mit doppelter Genauigkeit) | Keine |
| DOUBLE/REAL/FLOAT8 UNSIGNIERT | DOUBLE PRECISION | Double (Gleitkommazahl mit doppelter Genauigkeit) | Keine |
| BIT(N) | VARBYTE(8) | Variable-length binärer Wert | Keine |
| BINARY(n) | VARBYTE(n) | Variable-length binärer Wert | Keine |
| VARBINARY (n) | VARBYTE(n) | Variable-length binärer Wert | Keine |
| CHAR(n) | VARCHAR (n) | Variable-length Zeichenkettenwert | Keine |
| VARCHAR (n) | VARCHAR (n) | Variable-length Zeichenkettenwert | Keine |
| TEXT | VARCHAR(65535) | Variable-length Zeichenkettenwert mit bis zu 65.535 Zeichen | Keine |
| TINYTEXT | VARCHAR(255) | Variable-length Zeichenkettenwert bis zu 255 Zeichen | Keine |
| MEDIUMTEXT | VARCHAR(65535) | Variable-length Zeichenkettenwert bis zu 65.535 Zeichen | Keine |
| LONGTEXT | VARCHAR(65535) | Variable-length Zeichenkettenwert bis zu 65.535 Zeichen | Keine |
| ENUM | VARCHAR(1020) | Variable-length Zeichenkettenwert bis zu 1.020 Zeichen | Keine |
| SET | VARCHAR(1020) | Variable-length Zeichenkettenwert bis zu 1.020 Zeichen | Keine |
| DATE | DATUM | Kalenderdatum (Jahr, Monat, Tag) | Keine |
| DATETIME | TIMESTAMP (ZEITSTEMPEL) | Datum und Uhrzeit (ohne Zeitzone) | Keine |
| TIMESTAMP(p) | TIMESTAMP (ZEITSTEMPEL) | Datum und Uhrzeit (ohne Zeitzone) | Keine |
| TIME | VARCHAR(18) | Variable-length Zeichenkettenwert bis zu 18 Zeichen | Keine |
| JAHR | VARCHAR(4) | Variable-length Zeichenkettenwert bis zu 4 Zeichen | Keine |
| JSON | SUPER | Semistrukturierte Daten oder Dokumente als Werte | Keine |
Aurora PostgreSQL
Zero-ETL Integrationen für unterstützt keine benutzerdefinierten Datentypen oder Datentypen, die durch Erweiterungen erstellt wurden.
| Datentyp von Aurora PostgreSQL | Amazon-Redshift-Datentyp | Description | Einschränkungen |
|---|---|---|---|
| Array | SUPER | Semistrukturierte Daten oder Dokumente als Werte | Keine |
| bigint | BIGINT | 8-Byte-Ganzzahl mit Vorzeichen | Keine |
| BIGSERIAL | BIGINT | 8-Byte-Ganzzahl mit Vorzeichen | Keine |
| bit varying(n) | VARBYTE(n) | Variable-length Binärwert bis zu 16.777.216 Byte | Keine |
| BIT(N) | VARBYTE(n) | Variable-length Binärwert bis zu 16.777.216 Byte | Keine |
| BIT, BIT VARYING | VARBYTE(16777216) | Variable-length Binärwert bis zu 16.777.216 Byte | Keine |
| boolesch | BOOLEAN | Logischer boolescher Wert () true/false | Keine |
| bytea | VARBYTE(16777216) | Variable-length Binärwert bis zu 16.777.216 Byte | Keine |
| CHAR(n) | CHAR(n) | Fixed-length Zeichenkettenwert bis zu 65.535 Byte | Keine |
| char varying(n) | VARCHAR(65535) | Variable-length Zeichenkettenwert bis zu 65.535 Zeichen | Keine |
| cid | BIGINT |
8-Byte-Ganzzahl mit Vorzeichen |
Keine |
| CIDR |
VARCHAR(19) |
Variable-length Zeichenkettenwert bis zu 19 Zeichen |
Keine |
| date | DATUM | Kalenderdatum (Jahr, Monat, Tag) |
Werte über 294.276 A.D. werden nicht unterstützt |
| double precision | DOUBLE PRECISION | Double (Gleitkommazahlen mit doppelter Genauigkeit) | Subnormale Werte werden nicht vollständig unterstützt |
|
gtsvector |
VARCHAR(65535) |
Variable-length Zeichenkettenwert mit bis zu 65.535 Zeichen |
Keine |
| INET |
VARCHAR(19) |
Variable-length Zeichenkettenwert bis zu 19 Zeichen |
Keine |
| Ganzzahl | INTEGER | 4-Byte-Ganzzahl mit Vorzeichen | Keine |
|
int2vector |
SUPER | Semistrukturierte Daten oder Dokumente als Werte | Keine |
| Intervall | INTERVAL | Dauer | Es werden nur INTERVAL-Typen unterstützt, die einen Qualifier des Typs „Jahr zu Monat“ oder „Tag zu Sekunde“ angeben. |
| json | SUPER | Semistrukturierte Daten oder Dokumente als Werte | Keine |
| JSONB | SUPER | Semistrukturierte Daten oder Dokumente als Werte | Keine |
| jsonpath | VARCHAR(65535) | Variable-length Zeichenkettenwert bis zu 65.535 Zeichen | Keine |
|
MACADDR |
VARCHAR (17) | Variable-length Zeichenkettenwert bis zu 17 Zeichen | Keine |
|
macaddr8 |
VARCHAR(23) | Variable-length Zeichenkettenwert bis zu 23 Zeichen | Keine |
| money | DECIMAL(20,3) | Währungsbetrag | Keine |
| Name | VARCHAR(64) | Variable-length Zeichenkettenwert bis zu 64 Zeichen | Keine |
| numeric(p,s) | DECIMAL (p,s) | User-defined fester Genauigkeitswert |
|
| oid | BIGINT | 8-Byte-Ganzzahl mit Vorzeichen | Keine |
| oidvector | SUPER | Semistrukturierte Daten oder Dokumente als Werte | Keine |
| pg_brin_bloom_summary | VARCHAR(65535) | Variable-length Zeichenkettenwert mit bis zu 65.535 Zeichen | Keine |
| pg_dependencies | VARCHAR(65535) | Variable-length Zeichenkettenwert bis zu 65.535 Zeichen | Keine |
| PG_LSN | VARCHAR (17) | Variable-length Zeichenkettenwert bis zu 17 Zeichen | Keine |
| pg_mcv_list | VARCHAR(65535) | Variable-length Zeichenkettenwert bis zu 65.535 Zeichen | Keine |
| pg_ndistinct | VARCHAR(65535) | Variable-length Zeichenkettenwert bis zu 65.535 Zeichen | Keine |
| pg_node_tree | VARCHAR(65535) | Variable-length Zeichenkettenwert bis zu 65.535 Zeichen | Keine |
| pg_snapshot | VARCHAR(65535) | Variable-length Zeichenkettenwert bis zu 65.535 Zeichen | Keine |
| real | REAL | Gleitkommazahl mit einfacher Genauigkeit | Subnormale Werte werden nicht vollständig unterstützt |
| REFCURSOR | VARCHAR(65535) | Variable-length Zeichenkettenwert bis zu 65.535 Zeichen | Keine |
| smallint | SMALLINT | 2-Byte-Ganzzahl mit Vorzeichen | Keine |
| SMALLSERIAL | SMALLINT | 2-Byte-Ganzzahl mit Vorzeichen | Keine |
| serial | INTEGER | 4-Byte-Ganzzahl mit Vorzeichen | Keine |
| text | VARCHAR(65535) | Variable-length Zeichenkettenwert bis zu 65.535 Zeichen | Keine |
| tid | VARCHAR(23) | Variable-length Zeichenkettenwert bis zu 23 Zeichen | Keine |
| time [(p)] without time zone | VARCHAR(19) | Variable-length Zeichenkettenwert bis zu 19 Zeichen | Die Werte Infinity und -Infinity werden nicht unterstützt. |
| time [(p)] with time zone | VARCHAR (22) | Variable-length Zeichenkettenwert bis zu 22 Zeichen | Die Werte Infinity und -Infinity werden nicht unterstützt. |
| timestamp [(p)] without time zone | TIMESTAMP (ZEITSTEMPEL) | Datum und Uhrzeit (ohne Zeitzone) |
|
| timestamp [(p)] with time zone | TIMESTAMPTZ | Datum und Uhrzeit (mit Zeitzone) |
|
| TSQUERY | VARCHAR(65535) | Variable-length Zeichenkettenwert mit bis zu 65.535 Zeichen | Keine |
| TSVECTOR | VARCHAR(65535) | Variable-length Zeichenkettenwert bis zu 65.535 Zeichen | Keine |
| TXID_SNAPSHOT | VARCHAR(65535) | Variable-length Zeichenkettenwert bis zu 65.535 Zeichen | Keine |
| uuid | VARCHAR (36) | Variable-length 36 Zeichen lange Zeichenfolge | Keine |
| xid | BIGINT | 8-Byte-Ganzzahl mit Vorzeichen | Keine |
| xid8 | DECIMAL(20, 0) | Dezimalzahl mit fester Präzision | Keine |
| xml | VARCHAR(65535) | Variable-length Zeichenkettenwert mit bis zu 65.535 Zeichen | Keine |
DDL-Operationen für Aurora PostgreSQL
Amazon Redshift ist von PostgreSQL abgeleitet und teilt daher aufgrund der gemeinsamen PostgreSQL-Architektur mehrere Funktionen mit Aurora PostgreSQL. Zero-ETL Integrationen nutzen diese Ähnlichkeiten, um die Datenreplikation von nach Amazon Redshift zu optimieren, indem sie Datenbanken nach Namen zuordnen und die gemeinsame Datenbank, das Schema und die Tabellenstruktur nutzen.
Beachten Sie bei der Verwaltung von Null-ETL-Integrationen von Aurora PostgreSQL die folgenden Punkte:
-
Die Isolation wird auf Datenbankebene verwaltet.
-
Die Replikation erfolgt auf Datenbankebene.
-
Datenbanken von Aurora PostgreSQL werden Amazon-Redshift-Datenbanken nach Namen zugeordnet, wobei Daten in die entsprechende umbenannte Redshift-Datenbank fließen, wenn das Original umbenannt wird.
Trotz ihrer Ähnlichkeiten weisen Amazon Redshift und Aurora PostgreSQL wesentliche Unterschiede auf. In den folgenden Abschnitten werden die Systemantworten von Amazon Redshift für gängige DDL-Vorgänge beschrieben.
Datenbankvorgänge
Die folgende Tabelle zeigt die Systemantworten für Datenbank-DDL-Vorgänge.
| DDL-Vorgang | Redshift-Systemantwort |
|---|---|
CREATE DATABASE |
Kein Vorgang |
DROP DATABASE |
Amazon Redshift entfernt alle Daten in der Redshift-Zieldatenbank. |
RENAME DATABASE |
Amazon Redshift entfernt alle Daten in der ursprünglichen Zieldatenbank und synchronisiert die Daten in der neuen Zieldatenbank erneut. Wenn die neue Datenbank nicht existiert, müssen Sie sie manuell erstellen. Anleitungen finden Sie unter Eine Zieldatenbank in Amazon Redshift erstellen. |
Schemavorgänge
Die folgende Tabelle zeigt die Systemantworten für Schema-DDL-Vorgänge.
| DDL-Vorgang | Redshift-Systemantwort |
|---|---|
CREATE SCHEMA |
Kein Vorgang |
DROP SCHEMA |
Amazon Redshift entfernt das ursprüngliche Schema. |
RENAME SCHEMA |
Amazon Redshift entfernt das ursprüngliche Schema und synchronisiert dann die Daten im neuen Schema erneut. |
Tabellenoperationen
Die folgende Tabelle zeigt die Systemantworten auf Tabellen-DDL-Vorgänge.
| DDL-Vorgang | Redshift-Systemantwort |
|---|---|
CREATE TABLE |
Amazon Redshift erstellt die Tabelle. Einige Vorgänge führen dazu, dass die Tabellenerstellung fehlschlägt, z. B. das Erstellen einer Tabelle ohne Primärschlüssel oder das Durchführen einer deklarativen Partitionierung. Weitere Informationen erhalten Sie unter Einschränkungen und Fehlerbehebung bei Null-ETL-Integrationen von Aurora. |
DROP TABLE |
Amazon Redshift entfernt die Tabelle. |
TRUNCATE TABLE |
Amazon Redshift schneidet die Tabelle ab. |
ALTER TABLE
(RENAME...) |
Amazon Redshift benennt die Tabelle oder Spalte um. |
ALTER TABLE (SET
SCHEMA) |
Amazon Redshift entfernt die Tabelle im ursprünglichen Schema und synchronisiert dann die Tabelle im neuen Schema erneut. |
ALTER TABLE (ADD PRIMARY
KEY) |
Amazon Redshift fügt einen Primärschlüssel hinzu und synchronisiert die Tabelle erneut. |
ALTER TABLE (ADD
COLUMN) |
Amazon Redshift fügt eine Spalte zur Tabelle hinzu. |
ALTER TABLE (DROP
COLUMN) |
Amazon Redshift entfernt die Spalte, wenn es sich nicht um eine Primärschlüsselspalte handelt. Andernfalls wird die Tabelle erneut synchronisiert. |
ALTER TABLE (SET
LOGGED/UNLOGGED) |
Wenn Sie die Tabelle in protokolliert ändern, synchronisiert Amazon Redshift die Tabelle erneut. Wenn Sie die Tabelle in nicht protokolliert ändern, entfernt Amazon Redshift die Tabelle. |
