Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Analysieren der DB-Last nach Warteereignissen
Wenn das Diagramm der durchschnittlich aktiven Sitzungen einen Engpass anzeigt, können Sie herausfinden, woher die Last kommt. Betrachten Sie dazu die Tabelle mit den Hauptlastelementen unterhalb des Datenbanklast-Diagramms Wählen Sie ein bestimmtes Element, wie z. B. eine SQL-Abfrage oder einen Benutzer, um es aufzuschlüsseln und Details zu diesem Element anzuzeigen.
Die DB-Last, gruppiert nach Wartezeiten und Top-SQL-Abfragen, ist die standardmäßige Ansicht im Performance-Insights-Dashboard. Diese Kombination bietet typischerweise den besten Einblick in Performance-Probleme. DB-Last gruppiert nach Wartezeiten zeigt an, ob Ressourcen- oder Parallelitätsengpässe in der Datenbank vorhanden sind. In diesem Fall zeigt die SQL-Registerkarte der Tabelle der Hauptlastelemente, welche Abfragen diese Last verursachen.
Ihr typischer Workflow für die Diagnose von Performance-Problemen ist folgendermaßen:
-
Überprüfen Sie das Diagramm der durchschnittlich aktiven Sitzungen auf irgendwelche Ereignisse, in denen die Datenbanklast die Max CPU-Linie übersteigt.
-
Wenn ja, schauen Sie sich das Diagramm der durchschnittlich aktiven Sitzungen an und identifizieren Sie, welcher Wartezustand oder welche Zustände primär dafür verantwortlich sind.
-
Identifizieren Sie die zusammengefassten Abfragen, welche die Last verursachen, indem Sie nachsehen, welche Abfragen in der SQL-Registerkarte der Tabelle der Hauptlastelemente hauptsächlich zu diesen Wartezuständen beitragen. Sie finden sie in der Spalte DB Load by Wait (DB-Last nach Wartezuständen).
-
Wählen Sie eine dieser zusammengefassten Abfragen in der Registerkarte SQL aus, um sie zu expandieren und untergeordnete Abfragen anzuzeigen, aus denen sie besteht.
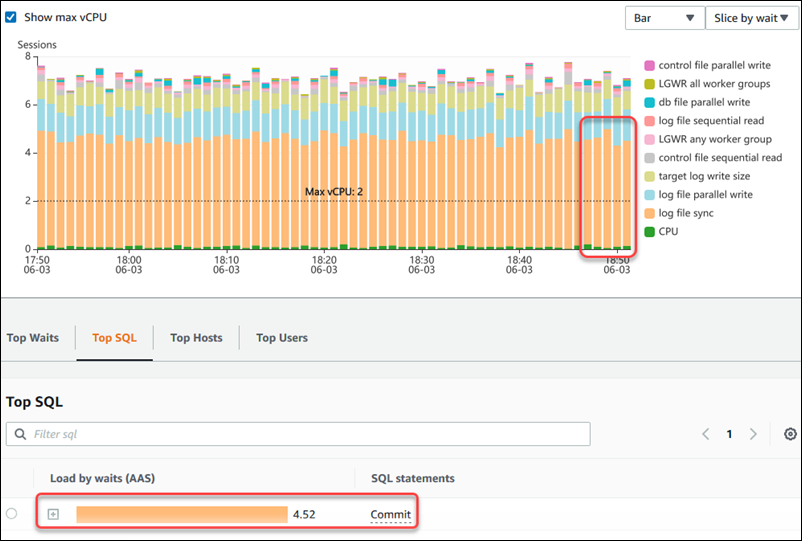
Beispielsweise wird im folgenden Dashboard die Protokolldateisynchronisierung für den größten Teil der DB-Last berücksichtigt. Die Wartezeit für Alle Worker-Gruppen in LGWR ist ebenfalls hoch. Das Diagramm Haupt-SQL zeigt auf, wodurch die Wartezustände der Protokolldatei-Synchronisierung verursacht werden: häufige COMMIT-Anweisungen. In diesem Fall wird durch eine weniger häufige Übergabe mit Commit die DB-Last reduziert.