Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Übersicht über den Import von Daten aus Amazon S3-Daten
So importieren Sie S3-Daten in : Amazon RDS
Sammeln Sie zunächst die Details, die Sie der Funktion zur Verfügung stellen müssen. Dazu gehören der Name der Tabelle auf der Ihre RDS for PostgreSQL-DB-Instance sowie der Bucket-Name, der Dateipfad, der Dateityp und der AWS-Region Speicherort der Amazon S3 S3-Daten. Weitere Informationen finden Sie unter Kopieren von Objekten im Benutzerhandbuch zu Amazon Simple Storage Service.
Anmerkung
Der mehrteilige Datenimport aus Amazon S3 wird derzeit nicht unterstützt.
Ermittelt den Namen der Tabelle, in die die
aws_s3.table_import_from_s3-Funktion die Daten importieren soll. Mit dem folgenden Befehl wird beispielsweise eine Tabellet1erstellt, die in späteren Schritten verwendet werden kann.postgres=>CREATE TABLE t1 (col1 varchar(80), col2 varchar(80), col3 varchar(80));Rufen Sie die Details zum Amazon-S3-Bucket und die zu importierenden Daten ab. Öffnen Sie dazu die Amazon S3 S3-Konsole unter https://console.aws.amazon.com/s3/
und wählen Sie Buckets. Suchen Sie den Bucket, der Ihre Daten enthält, in der Liste. Wählen Sie den Bucket aus, öffnen Sie die Seite Objektübersicht und wählen Sie dann Properties (Eigenschaften). Notieren Sie sich den Namen, den Pfad AWS-Region, den und den Dateityp des Buckets. Sie benötigen den Amazon-Ressourcenname (ARN) später, um den Zugriff auf Amazon S3 über eine IAM-Rolle einzurichten. Weitere Informationen finden Sie unter Einrichten des Zugriffs auf einen Amazon-S3-Bucket. In der folgenden Abbildung sehen Sie ein Beispiel.
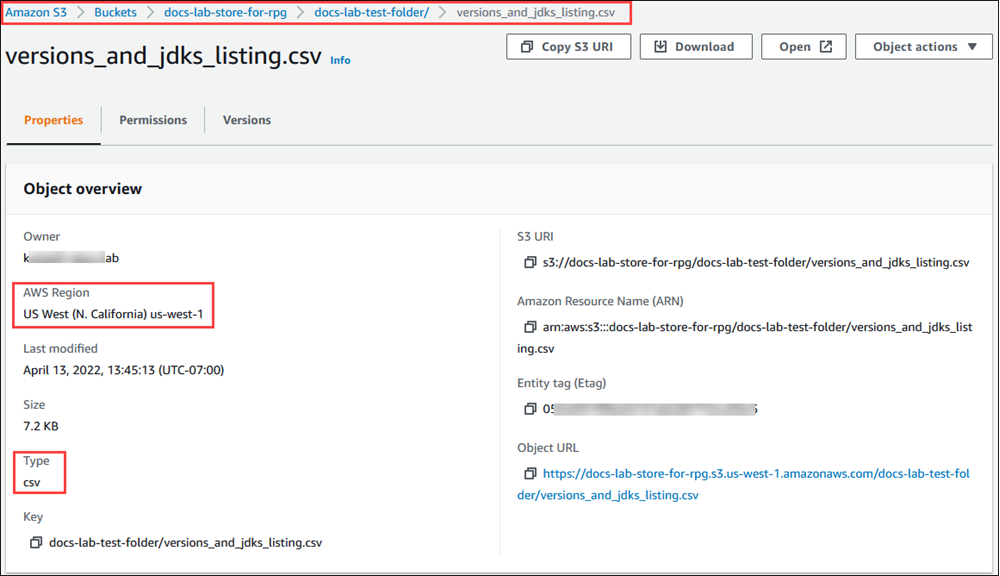
Sie können den Pfad zu den Daten im Amazon S3 S3-Bucket überprüfen, indem Sie den AWS CLI Befehl verwenden
aws s3 cp. Wenn die Informationen korrekt sind, lädt dieser Befehl eine Kopie der Amazon S3-Datei herunter.aws s3 cp s3://amzn-s3-demo-bucket/sample_file_path./-
Richten Sie Berechtigungen auf Ihrer DB-Instance von RDS für PostgreSQL ein, um den Zugriff auf die Datei im Amazon-S3-Bucket zu gestatten. Dazu verwenden Sie entweder eine AWS Identity and Access Management (IAM-) Rolle oder Sicherheitsanmeldedaten. Weitere Informationen finden Sie unter Einrichten des Zugriffs auf einen Amazon-S3-Bucket.
Geben Sie den Pfad und andere gesammelte Amazon S3-Objektdetails (siehe Schritt 2) an die
create_s3_uri-Funktion zum Erstellen eines Amazon S3-URI-Objekts. Weitere Informationen zu dieser Funktion finden Sie unter aws_commons.create_s3_uri. Es folgt ein Beispiel für die Erstellung dieses Objekts während einer psql-Sitzung.postgres=>SELECT aws_commons.create_s3_uri( 'docs-lab-store-for-rpg', 'versions_and_jdks_listing.csv', 'us-west-1' ) AS s3_uri \gsetIm nächsten Schritt übergeben Sie dieses Objekt (
aws_commons._s3_uri_1) an dieaws_s3.table_import_from_s3-Funktion, um die Daten in die Tabelle zu importieren.-
Rufen Sie die
aws_s3.table_import_from_s3-Funktion zum Importieren der Daten aus Amazon S3 in Ihre Tabelle auf. Referenz-Informationen finden Sie unter aws_s3.table_import_from_s3. Beispiele finden Sie unter Daten von Amazon S3 in Ihren ) importieren.
