Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Migrieren mithilfe von Oracle Transportable Tablespaces
Sie können die Oracle-Funktion Transportable Tablespaces verwenden, um eine Reihe von Tabellenbereichen aus einer On-Premises-Oracle-Datenbank in eine DB-Instance von RDS für Oracle zu kopieren. Auf physischer Ebene übertragen Sie Quell- und Metadatendateien mithilfe von Amazon EFS oder Amazon S3 auf Ihre Ziel-DB-Instance. Die Funktion „Transportable Tablespaces“ verwendet das Paket rdsadmin.rdsadmin_transport_util. Informationen zur Syntax und Semantik dieses Pakets finden Sie unter Transport von Tabellenbereichen.
Blogbeiträge, in denen erklärt wird, wie Tablespaces transportiert werden, finden Sie unter Migrieren von Oracle-Datenbanken zur AWS Verwendung von transportierbarem Tablespace und Amazon RDS for Oracle Transportable
Überblick über Transportable Tablespaces von Oracle
Ein Transportable-Tablespace-Set besteht aus Datendateien für den Satz von Tabellenbereichen, der transportiert wird, und einer Export-Dump-Datei, die Metadaten zu den Tabellenbereichen enthält. In einer physischen Migrationslösung wie Transportable Tablespaces übertragen Sie physische Dateien: Datendateien, Konfigurationsdateien und Data-Pump-Dump-Dateien.
Themen
Vor- und Nachteile von Transportable Tablespaces
Wir empfehlen, Transportable Tablespaces zu verwenden, wenn Sie einen oder mehrere große Tabellenbereiche mit minimalen Ausfallzeiten zu RDS migrieren müssen. Transportable Tablespaces bieten gegenüber der logischen Migration die folgenden Vorteile:
-
Die Ausfallzeiten sind geringer als bei den meisten anderen Oracle-Migrationslösungen.
-
Da die Transportable-Tablespaces-Funktion nur physische Dateien kopiert, werden Datenintegritätsfehler und logische Beschädigungen vermieden, die bei der logischen Migration auftreten können.
-
Es ist keine zusätzliche Lizenz erforderlich.
-
Sie können einen Satz Tabellenbereiche zwischen verschiedenen Plattformen und Endianness-Typen migrieren, z. B. von einer Oracle-Solaris-Plattform nach Linux. Der Transport von Tabellenbereichen zu und von Windows-Servern wird jedoch nicht unterstützt.
Anmerkung
Linux wurde vollständig getestet und wird vollständig unterstützt. Nicht alle UNIX-Varianten wurden getestet.
Wenn Sie Transportable Tablespaces verwenden, können Sie Daten entweder mit Amazon S3 oder mit Amazon EFS transportieren:
-
Wenn Sie EFS verwenden, verbleiben Ihre Backups für die Dauer des Imports im EFS-Dateisystem. Sie können die Dateien anschließend entfernen. Bei dieser Methode müssen Sie keinen EBS-Speicher für Ihre DB-Instance bereitstellen. Aus diesem Grund empfehlen wir, Amazon EFS anstelle von S3 zu verwenden. Weitere Informationen finden Sie unter Amazon-EFS-Integration.
-
Wenn Sie S3 verwenden, laden Sie RMAN-Backups auf den EBS-Speicher herunter, der an Ihre DB-Instance angehängt ist. Die Dateien verbleiben während des Imports in Ihrem EBS-Speicher. Nach dem Import können Sie diesen Speicherplatz freigeben, der Ihrer DB-Instance zugewiesen bleibt.
Der Hauptnachteil von Transportable Tablespaces besteht darin, dass Sie relativ fortgeschrittene Kenntnisse über Oracle Database benötigen. Weitere Informationen finden Sie unter Transporting Tablespaces Between Databases
Einschränkungen für Transportable Tablespaces
Oracle-Database-Beschränkungen für Transportable Tablespaces gelten, wenn Sie diese Funktion in RDS für Oracle verwenden. Weitere Informationen finden Sie unter Limitations on Transportable Tablespaces
-
Weder die Quell- noch die Zieldatenbank kann Standard Edition 2 (SE2) verwenden. Es wird nur die Enterprise Edition unterstützt.
-
Sie können eine Oracle-Database-11g-Datenbank nicht als Quelle verwenden. Die plattformübergreifende Funktion für Transportable-RMAN-Tablespaces basiert auf dem RMAN-Transportmechanismus, den Oracle Database 11g nicht unterstützt.
-
Mithilfe von Transportable Tablespaces können Sie keine Daten aus einer DB-Instance von RDS für Oracle migrieren. Mit Transportable Tablespaces können Sie nur Daten zu einer DB-Instance von RDS für Oracle migrieren.
-
Das Windows-Betriebssystem wird nicht unterstützt.
-
Sie können Tabellenbereiche nicht in eine Datenbank auf einer niedrigeren Versionsebene transportieren. Die Zieldatenbank muss sich auf der gleichen oder einer höheren Versionsebene wie die Quelldatenbank befinden. Sie können beispielsweise keine Tabellenbereiche von Oracle Database 21c in Oracle Database 19c transportieren.
-
Sie können keine administrativen Tabellenbereiche wie
SYSTEMundSYSAUXtransportieren. -
Sie können keine Objekte transportieren, die keine Daten sind, wie PL/SQL Pakete, Java-Klassen, Ansichten, Trigger, Sequenzen, Benutzer, Rollen und temporäre Tabellen. Um Nicht-Daten-Objekte zu transportieren, erstellen Sie sie manuell oder verwenden Sie den Data-Pump-Metadaten-Export und -Import. Weitere Informationen finden Sie im Supportdokument auf My Oracle Support Note 1454872.1
. -
Sie können keine Tabellenbereiche transportieren, die verschlüsselt sind oder verschlüsselte Spalten verwenden.
-
Wenn Sie Dateien mit Amazon S3 übertragen, beträgt die maximal unterstützte Dateigröße 5 TiB.
-
Wenn die Quelldatenbank Oracle-Optionen wie „Spatial“ verwendet, können Sie keine Tabellenbereiche transportieren, es sei denn, in der Zieldatenbank sind dieselben Optionen konfiguriert.
-
In einer Oracle-Replikatkonfiguration können Sie Tabellenbereiche nicht in eine DB-Instance von RDS für Oracle transportieren. Um dieses Problem zu umgehen, können Sie alle Replikate löschen, die Tabellenbereiche transportieren und die Replikate dann neu erstellen.
Voraussetzungen für Transportable Tablespaces
Führen Sie als Erstes die folgenden Schritte aus:
-
Lesen Sie die Anforderungen für Transportable Tablespaces, die in den folgenden Support-Dokumenten von Oracle beschrieben werden:
-
Planen Sie für eine Endianismuskonvertierung. Wenn Sie die Quellplattform-ID angeben, konvertiert RDS für Oracle den Endianismus automatisch. Informationen zur Suche von Plattform-IDs finden Sie unter Data Guard Support for Heterogeneous Primary and Physical Standbys in Same Data Guard Configuration (Doc ID 413484.1)
(Data Guard-Unterstützung für heterogene primäre und physische Standbys in derselben Data Guard-Konfiguration (Dok-ID 413484.1). -
Stellen Sie sicher, dass die Transportable-Tablespace-Funktion auf Ihrer Ziel-DB-Instance aktiviert ist. Die Funktion ist nur aktiviert, wenn Sie beim Ausführen der folgenden Abfrage keine
ORA-20304-Fehlermeldung erhalten:SELECT * FROM TABLE(rdsadmin.rdsadmin_transport_util.list_xtts_orphan_files);Wenn die Transportable-Tablespace-Funktion nicht aktiviert ist, starten Sie Ihre DB-Instance neu. Weitere Informationen finden Sie unter Eine DB-Instance DB-Cluster neu starten.
-
Vergewissern Sie sich, dass die Zeitzonendatei in den Quell- und Zieldatenbanken identisch ist.
-
Überprüfen Sie, ob die Datenbankzeichensätze der Quell- und Zieldatenbanken die beiden folgenden Anforderungen erfüllen:
-
Die Zeichensätze sind identisch.
-
Die Zeichensätze sind kompatibel. Eine Liste der Kompatibilitätsanforderungen finden Sie in der Oracle-Database-Dokumentation unter General Limitations on Transporting Data
.
-
-
Wenn Sie planen, Dateien mit Amazon S3 zu übertragen, gehen Sie wie folgt vor:
-
Stellen Sie sicher, dass ein Amazon S3 S3-Bucket für Dateiübertragungen verfügbar ist und dass sich der Amazon S3 S3-Bucket in derselben AWS Region wie Ihre DB-Instance befindet. Weitere Anleitungen finden Sie unter Erstellen eines Buckets im Amazon Simple Storage Service Handbuch "Erste Schritte".
-
Bereiten Sie den Amazon-S3-Bucket auf die Amazon-RDS-Integration vor, indem Sie die Anleitungen unter Konfigurieren von IAM-Berechtigungen für die Integration von RDS für Oracle in Amazon S3 befolgen.
-
-
Wenn Sie planen, Dateien mit Amazon EFS zu übertragen, stellen Sie sicher, dass Sie EFS gemäß den Anweisungen in Amazon-EFS-Integration konfiguriert haben.
-
Wir empfehlen dringend, automatische Backups in Ihrer Ziel-DB-Instance zu aktivieren. Da der Schritt zum Importieren von Metadaten potenziell fehlschlagen kann, ist es wichtig, dass Sie Ihre DB-Instance in den Zustand vor dem Import zurückversetzen können, sodass Sie Ihre Tabellenbereiche nicht erneut sichern, übertragen und importieren müssen.
Phase 1: Einrichten Ihres Quell-Hosts
In diesem Schritt kopieren Sie die von My Oracle Support bereitgestellten Transportable-Tablespaces-Skripts und richten die erforderlichen Konfigurationsdateien ein. In den folgenden Schritten führt der Quell-Host die Datenbank aus, die die Tabellenbereiche enthält, die zu Ihrer Ziel-Instance transportiert werden sollen.
So richten Sie Ihren Quell-Host ein
-
Melden Sie sich als Eigentümer Ihres Oracle-Basisverzeichnisses bei Ihrem Quell-Host an.
-
Stellen Sie sicher, dass Ihre Umgebungsvariablen
ORACLE_HOMEundORACLE_SIDauf Ihre Quelldatenbank verweisen. -
Melden Sie sich als Administrator bei Ihrer Datenbank an und stellen Sie sicher, dass die Zeitzonenversion, der DB-Zeichensatz und der nationale Zeichensatz mit denen in Ihrer Zieldatenbank übereinstimmen.
SELECT * FROM V$TIMEZONE_FILE; SELECT * FROM NLS_DATABASE_PARAMETERS WHERE PARAMETER IN ('NLS_CHARACTERSET','NLS_NCHAR_CHARACTERSET'); -
Richten Sie das Transportable-Tablespace-Dienstprogramm wie im Oracle-Support-Hinweis 2471245.1
beschrieben ein. Das Setup beinhaltet die Bearbeitung der
xtt.properties-Datei auf Ihrem Quell-Host. Die folgendextt.properties-Beispieldatei spezifiziert Backups von drei Tabellenbereichen im/dsk1/backups-Verzeichnis. Dies sind die Tabellenbereiche, die Sie zu Ihrer Ziel-DB-Instance transportieren möchten. Es gibt auch die Quell-Plattform-ID an, um den Endianismus automatisch zu konvertieren.Anmerkung
Gültige Plattform-IDs finden Sie unter Data Guard Support for Heterogeneous Primary and Physical Standbys in Same Data Guard Configuration (Doc ID 413484.1)
(Data Guard-Unterstützung für heterogene primäre und physische Standbys in derselben Data Guard-Konfiguration (Dok-ID 413484.1). #linux system platformid=13#list of tablespaces to transport tablespaces=TBS1,TBS2,TBS3#location where backup will be generated src_scratch_location=/dsk1/backups#RMAN command for performing backup usermantransport=1
Phase 2: Vorbereiten des vollständigen Tabellenbereich-Backups
In dieser Phase sichern Sie Ihre Tabellenbereiche zum ersten Mal, übertragen die Backups auf Ihren Ziel-Host und stellen sie dann mithilfe der Prozedur rdsadmin.rdsadmin_transport_util.import_xtts_tablespaces wieder her. Wenn diese Phase abgeschlossen ist, befinden sich die ersten Tabellenbereich-Backups auf Ihrer Ziel-DB-Instance und können mit inkrementellen Backups aktualisiert werden.
Themen
Schritt 1: Sichern der Tabellenbereiche auf Ihrem Quell-Host
In diesem Schritt verwenden Sie das xttdriver.pl-Skript, um ein vollständiges Backup Ihrer Tabellenbereiche zu erstellen. Die Ausgabe von xttdriver.pl wird in der Umgebungsvariablen TMPDIR gespeichert.
So sichern Sie Ihre Tabellenbereiche
-
Wenn sich Ihre Tablespaces im schreibgeschützten Modus befinden, melden Sie sich als Benutzer mit der entsprechenden
ALTER TABLESPACEBerechtigung bei Ihrer Quelldatenbank an und versetzen Sie Ihre Tablespaces in den Modus. read/write Andernfalls überspringen Sie diesen Schritt und gehen Sie direkt zum nächsten.Das folgende Beispiel versetzt
tbs1, und in den Modus.tbs2tbs3read/writeALTER TABLESPACE tbs1 READ WRITE; ALTER TABLESPACE tbs2 READ WRITE; ALTER TABLESPACE tbs3 READ WRITE; -
Sichern Sie Ihre Tabellenbereiche mithilfe des
xttdriver.pl-Skripts. Optional können Sie--debugangeben, damit das Skript im Debug-Modus ausgeführt wird.export TMPDIR=location_of_log_filescdlocation_of_xttdriver.pl$ORACLE_HOME/perl/bin/perl xttdriver.pl --backup
Schritt 2: Übertragen der Backup-Dateien auf Ihre Ziel-DB-Instance
In diesem Schritt kopieren Sie die Sicherungs- und Konfigurationsdateien von Ihrem Scratch-Speicherort in Ihre Ziel-DB-Instance. Wählen Sie eine der folgenden Optionen:
-
Wenn Quell- und Ziel-Host ein Amazon-EFS-Dateisystem gemeinsam nutzen, verwenden Sie ein Betriebssystem-Dienstprogramm wie
cp, um Ihre Sicherungsdateien und dieres.txt-Datei von Ihrem Scratch-Speicherort in ein freigegebenes Verzeichnis zu kopieren. Fahren Sie anschließend fort mit der unter Schritt 3: Importieren der Tabellenbereiche in Ihre Ziel-DB-Instance beschriebenen Anleitung. -
Wenn Sie Ihre Backups in einem Amazon-S3-Bucket bereitstellen müssen, führen Sie die folgenden Schritte aus.
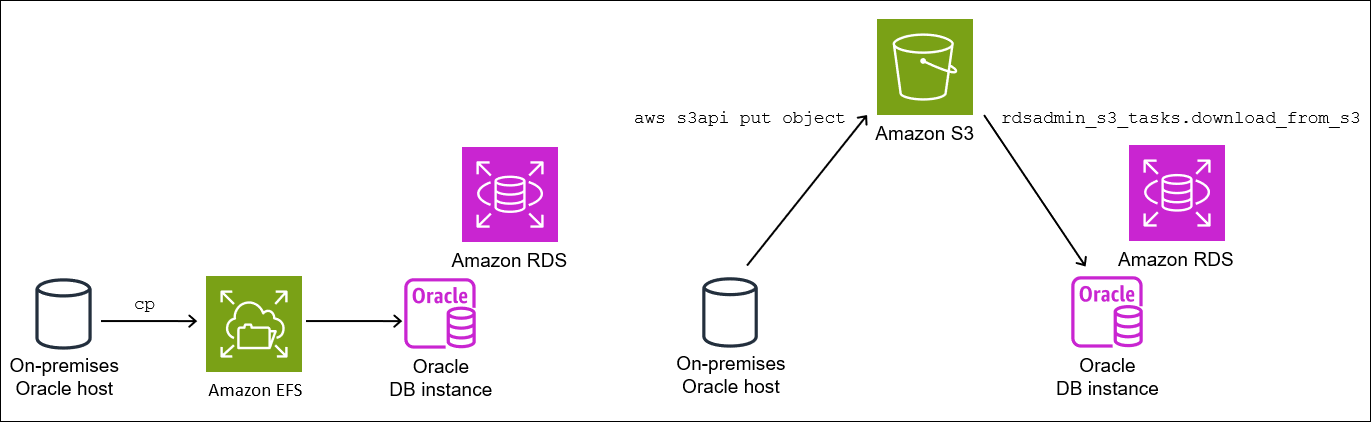
Schritt 2.2: Hochladen der Backups in Ihren Amazon-S3-Bucket
Laden Sie Ihre Backups und die res.txt-Datei aus Ihrem Scratch-Verzeichnis in Ihren Amazon-S3-Bucket hoch. Weitere Informationen finden Sie unter Hochladen von Objekten im Benutzerhandbuch von Amazon Simple Storage Service.
Schritt 2.3: Herunterladen der Backups aus Ihrem Amazon-S3-Bucket in Ihre Ziel-DB-Instance
In diesem Schritt verwenden Sie die Prozedur rdsadmin.rdsadmin_s3_tasks.download_from_s3, um Ihre Backups auf Ihre DB-Instance von RDS für Oracle herunterzuladen.
So laden Sie Ihre Backups aus Ihrem Amazon-S3-Bucket herunter
-
Starten Sie SQL*Plus oder Oracle SQL Developer und melden Sie sich bei Ihrer DB-Instance von RDS für Oracle an.
-
Laden Sie die Backups aus dem Amazon S3 S3-Bucket auf Ihre Ziel-DB-Instance herunter, indem Sie das Amazon RDS-Verfahren verwenden
rdsadmin.rdsadmin_s3_tasks.download_from_s3, um Dateien von Ihrem Amazon S3 S3-Bucket auf Ihre DB-Instance herunterzuladen. Das folgende Beispiel lädt alle Dateien von einem Amazon S3-Bucket mit dem Namenamzn-s3-demo-bucketDATA_PUMP_DIREXEC UTL_FILE.FREMOVE ('DATA_PUMP_DIR', 'res.txt'); SELECT rdsadmin.rdsadmin_s3_tasks.download_from_s3( p_bucket_name => 'amzn-s3-demo-bucket', p_directory_name => 'DATA_PUMP_DIR') AS TASK_ID FROM DUAL;Die Anweisung
SELECTgibt die ID der Aufgabe in einemVARCHAR2-Datentyp zurück. Weitere Informationen finden Sie unter Hochladen von Dateien aus einem Amazon S3-Bucket zu einer Oracle-DB-Instance.
Schritt 3: Importieren der Tabellenbereiche in Ihre Ziel-DB-Instance
Verwenden Sie die Prozedur rdsadmin.rdsadmin_transport_util.import_xtts_tablespaces, um Ihre Tabellenbereiche auf Ihrer Ziel-DB-Instance wiederherzustellen. Diese Prozedur konvertiert die Datendateien automatisch in das richtige Endian-Format.
Wenn Sie den Import von einer anderen Plattform als Linux durchführen, geben Sie beim Aufruf von import_xtts_tablespaces die Quellplattform mithilfe des Parameters p_platform_id an. Überprüfen Sie, ob die von Ihnen angegebene Plattform-ID mit der in der Datei xtt.properties übereinstimmt, die Sie in Schritt 2: Exportieren der Tabellenbereich-Metadaten auf Ihren Quell-Host angegeben haben.
Importieren der Tabellenbereiche in Ihre Ziel-DB-Instance
-
Starten Sie einen Oracle-SQL-Client und melden Sie sich als Hauptbenutzer bei Ihrer DB-Instance von RDS für Oracle an.
-
Führen Sie die Prozedur
rdsadmin.rdsadmin_transport_util.import_xtts_tablespacesaus und geben Sie dabei die zu importierenden Tabellenbereiche und das Verzeichnis mit den Backups an.Im folgenden Beispiel werden die Tablespaces
TBS1TBS2, undTBS3aus dem Verzeichnis importiert.DATA_PUMP_DIRDie Quellplattform ist AIX-Based Systems (64-Bit) mit der Plattform-ID von.6Sie können die Plattform-IDs finden, indem SieV$TRANSPORTABLE_PLATFORMabfragen.VAR task_id CLOB BEGIN :task_id:=rdsadmin.rdsadmin_transport_util.import_xtts_tablespaces( 'TBS1,TBS2,TBS3', 'DATA_PUMP_DIR', p_platform_id => 6); END; / PRINT task_id -
(Optional) Überwachen Sie den Fortschritt, indem Sie die Tabelle
rdsadmin.rds_xtts_operation_infoabfragen. Die Spaltextts_operation_stateenthält den WertEXECUTING,COMPLETEDoderFAILED.SELECT * FROM rdsadmin.rds_xtts_operation_info;Anmerkung
Für lang andauernde Operationen können Sie auch
V$SESSION_LONGOPS,V$RMAN_STATUSundV$RMAN_OUTPUTabfragen. -
Sehen Sie sich das Protokoll des abgeschlossenen Imports an, indem Sie die Task-ID aus dem vorherigen Schritt verwenden.
SELECT * FROM TABLE(rdsadmin.rds_file_util.read_text_file('BDUMP', 'dbtask-'||'&task_id'||'.log'));Stellen Sie sicher, dass der Import erfolgreich abgeschlossen wurde, bevor Sie mit dem nächsten Schritt fortfahren.
Phase 3: Erstellen und Übertragen inkrementeller Backups
In dieser Phase erstellen und übertragen Sie regelmäßig inkrementelle Backups, während die Quelldatenbank aktiv ist. Mit dieser Methode wird die Größe Ihres endgültigen Tabellenbereich-Backups reduziert. Wenn Sie mehrere inkrementelle Backups erstellen, müssen Sie die res.txt-Datei nach dem letzten inkrementellen Backup kopieren, bevor Sie es auf die Ziel-Instance anwenden können.
Die Schritte sind dieselben wie in Phase 2: Vorbereiten des vollständigen Tabellenbereich-Backups, außer dass der Importschritt optional ist.
Phase 4: Transportieren der Tabellenbereiche
In dieser Phase sichern Sie Ihre schreibgeschützten Tabellenbereiche und exportieren Data-Pump-Metadaten, übertragen diese Dateien auf Ihren Ziel-Host und importieren sowohl die Tabellenbereiche als auch die Metadaten.
Themen
Schritt 1: Sichern Ihrer schreibgeschützten Tabellenbereiche
Schritt 2: Exportieren der Tabellenbereich-Metadaten auf Ihren Quell-Host
Schritt 3: (nur Amazon S3) Übertragen der Backup- und Exportdateien auf Ihre Ziel-DB-Instance
Schritt 4: Importieren der Tabellenbereiche in Ihre Ziel-DB-Instance
Schritt 5: Importieren der Tabellenbereich-Metadaten in Ihre Ziel-DB-Instance
Schritt 1: Sichern Ihrer schreibgeschützten Tabellenbereiche
Dieser Schritt ist identisch mit Schritt 1: Sichern der Tabellenbereiche auf Ihrem Quell-Host, mit einem wesentlichen Unterschied: Sie versetzen Ihre Tabellenbereiche in den schreibgeschützten Modus, bevor Sie sie zum letzten Mal sichern.
Im folgenden Beispiel werden tbs1, tbs2 und tbs3 in den schreibgeschützten Modus versetzt.
Wichtig
Wenn Sie Tablespaces auf den schreibgeschützten Modus setzen, beginnt Ihr Ausfallzeitfenster für die Migration. Ab diesem Zeitpunkt können Anwendungen nicht mehr in diese Tablespaces in der Quelldatenbank schreiben. Planen Sie diesen Schritt während eines Wartungsfensters.
ALTER TABLESPACE tbs1 READ ONLY; ALTER TABLESPACE tbs2 READ ONLY; ALTER TABLESPACE tbs3 READ ONLY;
Schritt 2: Exportieren der Tabellenbereich-Metadaten auf Ihren Quell-Host
Exportieren Sie Ihre Tabellenbereich-Metadaten, indem Sie das Dienstprogramm expdp auf Ihrem Quell-Host ausführen. Im folgenden Beispiel werden die Tablespaces TBS1TBS2, und TBS3 in eine Dump-Datei xttdump.dmp im Verzeichnis exportiert. DATA_PUMP_DIR
expdpusername/pwd\ dumpfile=xttdump.dmp\ directory=DATA_PUMP_DIR\ statistics=NONE \ transport_tablespaces=TBS1,TBS2,TBS3\ transport_full_check=y \ logfile=tts_export.log
Wenn DATA_PUMP_DIR es sich um ein gemeinsam genutztes Verzeichnis in Amazon EFS handelt, fahren Sie mit fortSchritt 4: Importieren der Tabellenbereiche in Ihre Ziel-DB-Instance.
Schritt 3: (nur Amazon S3) Übertragen der Backup- und Exportdateien auf Ihre Ziel-DB-Instance
Wenn Sie Amazon S3 verwenden, um Ihre Tabellenbereich-Backups und die Data-Pump-Exportdatei bereitzustellen, führen Sie die folgenden Schritte aus.
Schritt 3.1: Hochladen der Backups und der Dump-Datei von Ihrem Quell-Host in Ihren Amazon-S3-Bucket
Laden Sie Ihre Backup- und Dump-Dateien von Ihrem Quell-Host in Ihren Amazon-S3-Bucket hoch. Weitere Informationen finden Sie unter Hochladen von Objekten im Benutzerhandbuch von Amazon Simple Storage Service.
Schritt 3.2: Herunterladen der Backups und der Dump-Datei aus Ihrem Amazon-S3-Bucket in Ihre DB-Instance
In diesem Schritt verwenden Sie die Prozedur rdsadmin.rdsadmin_s3_tasks.download_from_s3, um Ihre Backups und die Dump-Datei auf Ihre DB-Instance von RDS für Oracle herunterzuladen. Führen Sie die Schritte unter Schritt 2.3: Herunterladen der Backups aus Ihrem Amazon-S3-Bucket in Ihre Ziel-DB-Instance aus.
Schritt 4: Importieren der Tabellenbereiche in Ihre Ziel-DB-Instance
Verwenden Sie die Prozedur rdsadmin.rdsadmin_transport_util.import_xtts_tablespaces, um die Tabellenbereiche wiederherzustellen. Informationen zu Syntax und Semantik dieses Verfahrens finden Sie unter Importieren transportabler Tabellenbereiche in Ihre DB-Instance.
Wichtig
Nachdem Sie Ihren endgültigen Tabellenbereichimport abgeschlossen haben, ist der nächste Schritt das Importieren der Metadaten von Oracle Data Pump. Wenn der Import fehlschlägt, ist es wichtig, dass Sie Ihre DB-Instance in den Zustand vor dem Fehler zurückversetzen. Daher empfehlen wir Ihnen, den Anweisungen unter Erstellen eines DB-Snapshots für eine Single-AZ DB-Instance für Amazon RDS zu folgen und einen DB-Snapshot Ihrer DB-Instance zu erstellen. Der Snapshot enthält alle importierten Tabellenbereiche. Wenn der Import fehlschlägt, müssen Sie den Backup- und Importvorgang nicht wiederholen.
Wenn für Ihre Ziel-DB-Instance automatische Backups aktiviert sind und Amazon RDS nicht erkennt, dass vor dem Import der Metadaten ein gültiger Snapshot initiiert wurde, versucht RDS, einen Snapshot zu erstellen. Abhängig von Ihrer Instance-Aktivität kann dieser Snapshot erfolgreich erstellt werden oder auch nicht. Wenn kein gültiger Snapshot erkannt wird oder ein Snapshot nicht initiiert werden kann, wird der Metadatenimport mit Fehlern beendet.
Importieren der Tabellenbereiche in Ihre Ziel-DB-Instance
-
Starten Sie einen Oracle-SQL-Client und melden Sie sich als Hauptbenutzer bei Ihrer DB-Instance von RDS für Oracle an.
-
Führen Sie die Prozedur
rdsadmin.rdsadmin_transport_util.import_xtts_tablespacesaus und geben Sie dabei die zu importierenden Tabellenbereiche und das Verzeichnis mit den Backups an.Im folgenden Beispiel werden die Tablespaces
TBS1TBS2, undTBS3aus dem Verzeichnis importiert.DATA_PUMP_DIRBEGIN :task_id:=rdsadmin.rdsadmin_transport_util.import_xtts_tablespaces('TBS1,TBS2,TBS3','DATA_PUMP_DIR'); END; / PRINT task_id -
(Optional) Überwachen Sie den Fortschritt, indem Sie die Tabelle
rdsadmin.rds_xtts_operation_infoabfragen. Die Spaltextts_operation_stateenthält den WertEXECUTING,COMPLETEDoderFAILED.SELECT * FROM rdsadmin.rds_xtts_operation_info;Anmerkung
Für lang andauernde Operationen können Sie auch
V$SESSION_LONGOPS,V$RMAN_STATUSundV$RMAN_OUTPUTabfragen. -
Sehen Sie sich das Protokoll des abgeschlossenen Imports an, indem Sie die Task-ID aus dem vorherigen Schritt verwenden.
SELECT * FROM TABLE(rdsadmin.rds_file_util.read_text_file('BDUMP', 'dbtask-'||'&task_id'||'.log'));Stellen Sie sicher, dass der Import erfolgreich abgeschlossen wurde, bevor Sie mit dem nächsten Schritt fortfahren.
-
Folgen Sie den Anweisungen unter Erstellen eines DB-Snapshots für eine Single-AZ DB-Instance für Amazon RDS und erstellen Sie einen manuellen DB-Snapshot.
Schritt 5: Importieren der Tabellenbereich-Metadaten in Ihre Ziel-DB-Instance
In diesem Schritt importieren Sie die Transportable-Tablespace-Metadaten mithilfe der Prozedur rdsadmin.rdsadmin_transport_util.import_xtts_metadata in Ihre DB-Instance von RDS für Oracle. Informationen zu Syntax und Semantik dieses Verfahrens finden Sie unter Importieren von Metadaten transportabler Tabellenbereiche in Ihre DB-Instance. Während des Vorgangs wird der Status des Imports in der Tabelle rdsadmin.rds_xtts_operation_info angezeigt.
Wichtig
Bevor Sie Metadaten importieren, empfehlen wir Ihnen dringend, zu überprüfen, ob nach dem Import Ihrer Tabellenbereiche ein DB-Snapshot erfolgreich erstellt wurde. Wenn der Importschritt fehlschlägt, stellen Sie Ihre DB-Instance wieder her, beheben Sie die Importfehler und versuchen Sie dann erneut, den Import durchzuführen.
Importieren der Data-Pump-Metadaten in Ihre DB-Instance von RDS für Oracle
-
Starten Sie Ihren Oracle-SQL-Client und melden Sie sich als Hauptbenutzer bei Ihrer Ziel-DB-Instance an.
-
Erstellen Sie die Benutzer, denen Schemas in Ihren transportierten Tabellenbereichen gehören, falls diese Benutzer noch nicht existieren.
CREATE USERtbs_ownerIDENTIFIED BYpassword; -
Importieren Sie die Metadaten und geben Sie dabei den Namen der Dump-Datei und deren Verzeichnispfad an.
BEGIN rdsadmin.rdsadmin_transport_util.import_xtts_metadata('xttdump.dmp','DATA_PUMP_DIR'); END; / -
(Optional) Fragen Sie die Transportable-Tablespace-Verlaufstabelle ab, um den Status des Metadatenimports zu sehen.
SELECT * FROM rdsadmin.rds_xtts_operation_info;Wenn der Vorgang abgeschlossen ist, befinden sich Ihre Tabellenbereiche im schreibgeschützten Modus.
-
(Optional) Sehen Sie sich die Protokolldatei an.
Das folgende Beispiel listet den Inhalt des BDUMP-Verzeichnisses auf und fragt dann das Importprotokoll ab.
SELECT * FROM TABLE(rdsadmin.rds_file_util.listdir(p_directory => 'BDUMP')); SELECT * FROM TABLE(rdsadmin.rds_file_util.read_text_file( p_directory => 'BDUMP', p_filename => 'rds-xtts-import_xtts_metadata-2023-05-22.01-52-35.560858000.log'));
Phase 5: Validieren der transportierten Tabellenbereiche
In diesem optionalen Schritt validieren Sie Ihre transportierten Tablespaces mithilfe der Prozedur rdsadmin.rdsadmin_rman_util.validate_tablespace und versetzen Ihre Tablespaces dann in den Modus. read/write
So validieren Sie die transportierten Daten
-
Starten Sie SQL*Plus oder SQL Developer und melden Sie sich als Hauptbenutzer bei Ihrer Ziel-DB-Instance an.
-
Validieren Sie die Tabellenbereiche mithilfe der Prozedur
rdsadmin.rdsadmin_rman_util.validate_tablespace.SET SERVEROUTPUT ON BEGIN rdsadmin.rdsadmin_rman_util.validate_tablespace( p_tablespace_name => 'TBS1', p_validation_type => 'PHYSICAL+LOGICAL', p_rman_to_dbms_output => TRUE); rdsadmin.rdsadmin_rman_util.validate_tablespace( p_tablespace_name => 'TBS2', p_validation_type => 'PHYSICAL+LOGICAL', p_rman_to_dbms_output => TRUE); rdsadmin.rdsadmin_rman_util.validate_tablespace( p_tablespace_name => 'TBS3', p_validation_type => 'PHYSICAL+LOGICAL', p_rman_to_dbms_output => TRUE); END; / -
Versetzen Sie Ihre Tablespaces in den Modus. read/write
ALTER TABLESPACETBS1READ WRITE; ALTER TABLESPACETBS2READ WRITE; ALTER TABLESPACETBS3READ WRITE;
Phase 6: Bereinigen übrig gebliebener Dateien
In diesem optionalen Schritt entfernen Sie alle nicht benötigten Dateien. Verwenden Sie das Verfahren rdsadmin.rdsadmin_transport_util.list_xtts_orphan_files, um Datendateien aufzulisten, die nach einem Tablespace-Import verwaist waren, und dann das Verfahren rdsadmin.rdsadmin_transport_util.cleanup_incomplete_xtts_import, um sie zu löschen. Informationen zu Syntax und Semantik dieser Verfahren finden Sie unter Auflisten verwaister Dateien nach einem Tabellenbereichimport und Löschen verwaister Dateien nach einem Tabellenbereichimport.
So bereinigen Sie übrig gebliebene Dateien
-
Entfernen Sie alte Backups
DATA_PUMP_DIRwie folgt:-
Listen Sie die Backup-Dateien auf, indem Sie den Befehl
rdsadmin.rdsadmin_file_util.listdirausführen.SELECT * FROM TABLE(rdsadmin.rds_file_util.listdir(p_directory => 'DATA_PUMP_DIR')); -
Entfernen Sie die Backups nacheinander, indem Sie
UTL_FILE.FREMOVEaufrufen.EXEC UTL_FILE.FREMOVE ('DATA_PUMP_DIR', 'backup_filename');
-
-
Wenn Sie Tabellenbereiche, aber keine Metadaten für diese Tabellenbereiche importiert haben, können Sie die verwaisten Datendateien wie folgt löschen:
-
Listen Sie die verwaisten Datendateien auf, die Sie löschen müssen. Das folgende Beispiel führt die Prozedur
rdsadmin.rdsadmin_transport_util.list_xtts_orphan_filesaus.SQL> SELECT * FROM TABLE(rdsadmin.rdsadmin_transport_util.list_xtts_orphan_files); FILENAME FILESIZE -------------- --------- datafile_7.dbf 104865792 datafile_8.dbf 104865792 -
Löschen Sie die verwaisten Dateien, indem Sie die Prozedur
rdsadmin.rdsadmin_transport_util.cleanup_incomplete_xtts_importausführen.BEGIN rdsadmin.rdsadmin_transport_util.cleanup_incomplete_xtts_import('DATA_PUMP_DIR'); END; /Der Bereinigungsvorgang generiert eine Protokolldatei, die das Namensformat
rds-xtts-delete_xtts_orphaned_files-imYYYY-MM-DD.HH24-MI-SS.FF.logBDUMP-Verzeichnis verwendet. -
Lesen Sie die im vorherigen Schritt generierte Protokolldatei. Das folgende Beispiel zeigt das Protokoll
rds-xtts-delete_xtts_orphaned_files-.2023-06-01.09-33-11.868894000.logSELECT * FROM TABLE(rdsadmin.rds_file_util.read_text_file( p_directory => 'BDUMP', p_filename => 'rds-xtts-delete_xtts_orphaned_files-2023-06-01.09-33-11.868894000.log')); TEXT -------------------------------------------------------------------------------- orphan transported datafile datafile_7.dbf deleted. orphan transported datafile datafile_8.dbf deleted.
-
-
Wenn Sie Tabellenbereiche sowie Metadaten für diese Tabellenbereiche importiert haben, aber auf Kompatibilitätsfehler oder andere Probleme mit Oracle Data Pump gestoßen sind, bereinigen Sie die teilweise transportierten Datendateien wie folgt:
-
Listen Sie die Tabellenbereiche auf, die teilweise transportierte Datendateien enthalten, indem Sie
DBA_TABLESPACESabfragen.SQL> SELECT TABLESPACE_NAME FROM DBA_TABLESPACES WHERE PLUGGED_IN='YES'; TABLESPACE_NAME -------------------------------------------------------------------------------- TBS_3 -
Löschen Sie die Tabellenbereiche und die teilweise transportierten Datendateien.
DROP TABLESPACETBS_3INCLUDING CONTENTS AND DATAFILES;
-
