Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Einen Bewertungsbericht für mehrere Server erstellen in AWS Schema Conversion Tool
Erstellen Sie einen Bewertungsbericht für mehrere Server, um die beste Zielrichtung für Ihre gesamte Umgebung zu ermitteln.
In einem Bewertungsbericht für mehrere Server werden mehrere Server anhand der Eingaben bewertet, die Sie für jede Schemadefinition angeben, die Sie bewerten möchten. Ihre Schemadefinition enthält Verbindungsparameter für den Datenbankserver und den vollständigen Namen jedes Schemas. Erstellt nach der Bewertung jedes AWS SCT Schemas einen zusammenfassenden, aggregierten Bewertungsbericht für die Datenbankmigration zwischen Ihren verschiedenen Servern. Dieser Bericht zeigt die geschätzte Komplexität für jedes mögliche Migrationsziel.
Sie können ihn verwenden AWS SCT , um einen Bewertungsbericht für mehrere Server für die folgenden Quell- und Zieldatenbanken zu erstellen.
| Quelldatenbank | Zieldatenbank |
|---|---|
|
Amazon Redshift |
Amazon Redshift |
|
Azure SQL Database |
Aurora MySQL, Aurora PostgreSQL, MySQL, PostgreSQL |
|
Azure Synapse-Analytik |
Amazon Redshift |
|
BigQuery |
Amazon Redshift |
|
Greenplum |
Amazon Redshift |
|
IBM Db2 für z/OS |
Amazon Aurora MySQL-kompatible Edition (Aurora MySQL), Amazon Aurora PostgreSQL-kompatible Edition (Aurora PostgreSQL), MySQL, PostgreSQL |
|
IBM Db2 (LUW) |
Aurora MySQL, Aurora PostgreSQL, MariaDB, MySQL, PostgreSQL |
|
Microsoft SQL Server |
Aurora MySQL, Aurora PostgreSQL, Amazon Redshift, Babelfish für Aurora PostgreSQL, MariaDB, Microsoft SQL Server, MySQL, PostgreSQL |
|
MySQL |
Aurora PostgreSQL, MySQL, PostgreSQL |
|
Netezza |
Amazon Redshift |
|
Oracle |
Aurora MySQL, Aurora PostgreSQL, Amazon Redshift, MariaDB, MySQL, Oracle, PostgreSQL |
|
PostgreSQL |
Aurora MySQL, Aurora PostgreSQL, MySQL, PostgreSQL |
|
SAP ASE |
Aurora MySQL, Aurora PostgreSQL, MariaDB, MySQL, PostgreSQL |
|
Snowflake |
Amazon Redshift |
|
Teradata |
Amazon Redshift |
|
Vertica |
Amazon Redshift |
Durchführung einer Multiserver-Assessment
Gehen Sie wie folgt vor, um eine Multiserverbewertung mit durchzuführen. AWS SCT Sie müssen kein neues Projekt erstellen, AWS SCT um eine Multiserverbewertung durchzuführen. Bevor Sie beginnen, stellen Sie sicher, dass Sie eine Datei mit kommagetrennten Werten (CSV) mit Datenbankverbindungsparametern vorbereitet haben. Stellen Sie außerdem sicher, dass Sie alle erforderlichen Datenbanktreiber installiert haben, und legen Sie den Speicherort der Treiber in den AWS SCT Einstellungen fest. Weitere Informationen finden Sie unter Installation von JDBC-Treibern für AWS Schema Conversion Tool.
Um eine Multiserver-Bewertung durchzuführen und einen zusammengefassten Zusammenfassungsbericht zu erstellen
-
Wählen Sie AWS SCT unter Datei, Neue Multiserverbewertung aus. Das Dialogfeld Neue Multiserver-Bewertung wird geöffnet.
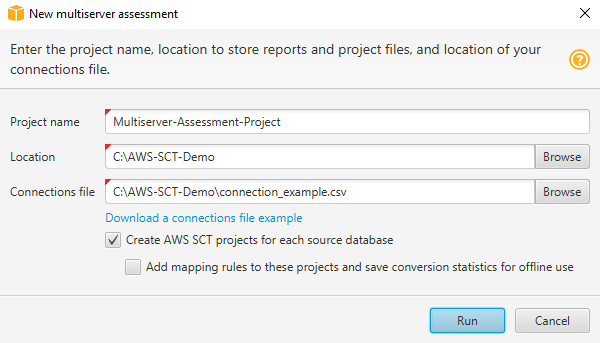
-
Wählen Sie Beispiel für eine Verbindungsdatei herunterladen, um eine leere Vorlage einer CSV-Datei mit Datenbankverbindungsparametern herunterzuladen.
-
Geben Sie Werte für Projektname, Speicherort (zum Speichern von Berichten) und Verbindungsdatei (eine CSV-Datei) ein.
-
Wählen Sie AWS SCT Projekte für jede Quelldatenbank erstellen, um nach der Erstellung des Bewertungsberichts automatisch Migrationsprojekte zu erstellen.
-
Wenn die Option AWS SCT Projekte für jede Quelldatenbank erstellen aktiviert ist, können Sie Zuordnungsregeln zu diesen Projekten hinzufügen auswählen und Konvertierungsstatistiken für die Offline-Verwendung speichern. In diesem Fall AWS SCT fügt jedem Projekt Zuordnungsregeln hinzu und speichert die Metadaten der Quelldatenbank im Projekt. Weitere Informationen finden Sie unter Verwenden Sie den Offline-Modus in AWS Schema Conversion Tool.
-
Klicken Sie auf Ausführen.
Es erscheint ein Fortschrittsbalken, der das Tempo der Datenbankbewertung anzeigt. Die Anzahl der Ziel-Engines kann sich auf die Laufzeit der Bewertung auswirken.
-
Wählen Sie Ja, wenn die folgende Meldung angezeigt wird: Die vollständige Analyse aller Datenbankserver kann einige Zeit dauern. Möchten Sie fortfahren?
Wenn der Multiserver-Assessment-Bericht fertig ist, wird ein entsprechender Bildschirm angezeigt.
-
Wählen Sie Bericht öffnen, um den zusammengefassten Bewertungsbericht anzuzeigen.
AWS SCT Generiert standardmäßig einen aggregierten Bericht für alle Quelldatenbanken und einen detaillierten Bewertungsbericht für jeden Schemanamen in einer Quelldatenbank. Weitere Informationen finden Sie unter Suchen und Anzeigen von Berichten.
Wenn die Option AWS SCT Projekte für jede Quelldatenbank erstellen aktiviert ist, AWS SCT wird für jede Quelldatenbank ein leeres Projekt erstellt. AWS SCT erstellt auch Bewertungsberichte, wie zuvor beschrieben. Nachdem Sie diese Bewertungsberichte analysiert und das Migrationsziel für jede Quelldatenbank ausgewählt haben, fügen Sie Zieldatenbanken zu diesen leeren Projekten hinzu.
Wenn die Option Zuordnungsregeln zu diesen Projekten hinzufügen und Konvertierungsstatistiken für die Offline-Verwendung speichern aktiviert ist, AWS SCT wird für jede Quelldatenbank ein Projekt erstellt. Diese Projekte enthalten die folgenden Informationen:
Ihre Quelldatenbank und eine virtuelle Zieldatenbankplattform. Weitere Informationen finden Sie unter Zuordnung zu virtuellen Zielen im AWS Schema Conversion Tool.
Eine Zuordnungsregel für dieses Quell-Ziel-Paar. Weitere Informationen finden Sie unter Zuordnung von Datentypen.
Ein Bewertungsbericht zur Datenbankmigration für dieses Quell-Ziel-Paar.
Metadaten des Quellschemas, mit denen Sie dieses AWS SCT Projekt im Offline-Modus verwenden können. Weitere Informationen finden Sie unter Verwenden Sie den Offline-Modus in AWS Schema Conversion Tool.
Eine CSV-Eingabedatei wird vorbereitet
Um Verbindungsparameter als Eingabe für den Multiserver-Assessmentbericht bereitzustellen, verwenden Sie eine CSV-Datei, wie im folgenden Beispiel gezeigt.
Name,Description,Secret Manager Key,Server IP,Port,Service Name,Database name,BigQuery path,Source Engine,Schema Names,Use Windows Authentication,Login,Password,Use SSL,Trust store,Key store,SSL authentication,Target Engines Sales,,,192.0.2.0,1521,pdb,,,ORACLE,Q4_2021;FY_2021,,user,password,,,,,POSTGRESQL;AURORA_POSTGRESQL Marketing,,,ec2-a-b-c-d.eu-west-1.compute.amazonaws.com,1433,,target_audience,,MSSQL,customers.dbo,,user,password,,,,,AURORA_MYSQL HR,,,192.0.2.0,1433,,employees,,MSSQL,employees.%,true,,,,,,,AURORA_POSTGRESQL Customers,,secret-name,,,,,,MYSQL,customers,,,,,,,,AURORA_POSTGRESQL Analytics,,,198.51.100.0,8195,,STATISTICS,,DB2LUW,BI_REPORTS,,user,password,,,,,POSTGRESQL Products,,,203.0.113.0,8194,,,,TERADATA,new_products,,user,password,,,,,REDSHIFT
Im vorherigen Beispiel werden die beiden Schemanamen für die Datenbank durch ein Semikolon getrennt. Sales Außerdem werden die beiden Zieldatenbank-Migrationsplattformen für die Datenbank durch ein Semikolon voneinander getrennt. Sales
Außerdem verwendet das vorherige Beispiel die Verbindung AWS Secrets Manager zur Customers Datenbank und die Windows-Authentifizierung, um eine Verbindung zur Datenbank herzustellen. HR
Sie können eine neue CSV-Datei erstellen oder eine Vorlage für eine CSV-Datei von herunterladen AWS SCT und die erforderlichen Informationen eingeben. Stellen Sie sicher, dass die erste Zeile Ihrer CSV-Datei dieselben Spaltennamen wie im vorherigen Beispiel enthält.
Um eine Vorlage der CSV-Eingabedatei herunterzuladen
Fangen Sie an AWS SCT.
Wählen Sie „Datei“ und anschließend „Neues Multiserver-Assessment“.
Wählen Sie „Beispiel für eine Verbindungsdatei herunterladen“ aus.
Stellen Sie sicher, dass Ihre CSV-Datei die folgenden Werte enthält, die von der Vorlage bereitgestellt werden:
-
Name — Die Textbeschriftung, mit der Sie Ihre Datenbank identifizieren können. AWS SCT zeigt dieses Textlabel im Bewertungsbericht an.
-
Beschreibung — Ein optionaler Wert, mit dem Sie zusätzliche Informationen zur Datenbank angeben können.
-
Secret Manager Key — Der Name des Secrets, das Ihre Datenbankanmeldeinformationen speichert, in der AWS Secrets Manager. Um Secrets Manager zu verwenden, stellen Sie sicher, dass Sie AWS Profile in speichern AWS SCT. Weitere Informationen finden Sie unter Konfiguration AWS Secrets Manager in der AWS Schema Conversion Tool.
Wichtig
AWS SCT ignoriert den Secret Manager-Schlüsselparameter, wenn Sie die Server-IP -, Port -, Anmelde - und Kennwortparameter in die Eingabedatei aufnehmen.
-
Server-IP — Der DNS-Name (Domain Name Service) oder die IP-Adresse Ihres Quelldatenbankservers.
-
Port — Der Port, der für die Verbindung zu Ihrem Quelldatenbankserver verwendet wird.
-
Dienstname — Wenn Sie einen Dienstnamen verwenden, um eine Verbindung zu Ihrer Oracle-Datenbank herzustellen, der Name des Oracle-Dienstes, zu dem die Verbindung hergestellt werden soll.
-
Datenbankname — Der Datenbankname. Verwenden Sie für Oracle-Datenbanken die Oracle-System-ID (SID).
-
BigQuery Pfad — der Pfad zur Dienstkonto-Schlüsseldatei für Ihre BigQuery Quelldatenbank. Weitere Hinweise zum Erstellen dieser Datei finden Sie unterRechte für BigQuery als Quelle.
-
Source Engine — Der Typ Ihrer Quelldatenbank. Verwenden Sie einen der folgenden Werte:
AZURE_MSSQL für eine Azure SQL-Datenbank.
AZURE_SYNAPSE für eine Azure Synapse Analytics-Datenbank.
GOOGLE_BIGQUERY für eine Datenbank. BigQuery
DB2ZOS für eine IBM Db2 für Datenbank. z/OS
DB2LUW für eine IBM Db2 LUW-Datenbank.
GREENPLUM für eine Greenplum-Datenbank.
MSSQL für eine Microsoft SQL Server-Datenbank.
MYSQL für eine MySQL-Datenbank.
NETEZZA für eine Netezza-Datenbank.
ORACLE für eine Oracle-Datenbank.
POSTGRESQL für eine PostgreSQL-Datenbank.
REDSHIFT für eine Amazon Redshift Redshift-Datenbank.
SNOWFLAKE für eine Snowflake-Datenbank.
SYBASE_ASE für eine SAP ASE-Datenbank.
TERADATA für eine Teradata-Datenbank.
VERTICA für eine Vertica-Datenbank.
-
Schemanamen — Die Namen der Datenbankschemas, die in den Bewertungsbericht aufgenommen werden sollen.
Verwenden Sie für Azure SQL Database, Azure Synapse Analytics BigQuery, Netezza, SAP ASE, Snowflake und SQL Server das folgende Format des Schemanamens:
db_name.schema_nameErsetzen Sie es durch
db_nameschema_nameSchließen Sie Datenbank- oder Schemanamen ein, die einen Punkt in doppelten Anführungszeichen enthalten, wie folgt:
"database.name"."schema.name".Trennen Sie mehrere Schemanamen wie folgt durch Semikolons voneinander:.
Schema1;Schema2Bei den Datenbank- und Schemanamen wird zwischen Groß- und Kleinschreibung unterschieden.
Verwenden Sie Prozent (
%) als Platzhalter, um eine beliebige Anzahl von Symbolen im Datenbank- oder Schemanamen zu ersetzen. Im vorherigen Beispiel wird Prozent (%) als Platzhalter verwendet, um alle Schemas aus deremployeesDatenbank in den Bewertungsbericht aufzunehmen. -
Windows-Authentifizierung verwenden — Wenn Sie die Windows-Authentifizierung verwenden, um eine Verbindung zu Ihrer Microsoft SQL Server-Datenbank herzustellen, geben Sie true ein. Weitere Informationen finden Sie unter Verwenden der Windows-Authentifizierung bei Verwendung von Microsoft SQL Server als Quelle.
-
Login — Der Benutzername für die Verbindung mit Ihrem Quelldatenbankserver.
-
Passwort — Das Passwort für die Verbindung zu Ihrem Quelldatenbankserver.
-
SSL verwenden — Wenn Sie Secure Sockets Layer (SSL) verwenden, um eine Verbindung zu Ihrer Quelldatenbank herzustellen, geben Sie true ein.
-
Trust Store — Der Trust Store, der für Ihre SSL-Verbindung verwendet werden soll.
-
Schlüsselspeicher — Der Schlüsselspeicher, den Sie für Ihre SSL-Verbindung verwenden möchten.
-
SSL-Authentifizierung — Wenn Sie die SSL-Authentifizierung per Zertifikat verwenden, geben Sie true ein.
-
Target Engines — Die Zieldatenbankplattformen. Verwenden Sie die folgenden Werte, um ein oder mehrere Ziele im Bewertungsbericht anzugeben:
AURORA_MYSQL für eine Aurora MySQL-kompatible Datenbank.
AURORA_POSTGRESQL für eine Aurora PostgreSQL-kompatible Datenbank.
BABELFISH für eine Babelfish for Aurora PostgreSQL-Datenbank.
MARIA_DB für eine MariaDB-Datenbank.
MSSQL für eine Microsoft SQL Server-Datenbank.
MYSQL für eine MySQL-Datenbank.
ORACLE für eine Oracle-Datenbank.
POSTGRESQL für eine PostgreSQL-Datenbank.
REDSHIFT für eine Amazon Redshift Redshift-Datenbank.
Trennen Sie mehrere Ziele, indem Sie Semikolons wie folgt verwenden:.
MYSQL;MARIA_DBDie Anzahl der Ziele wirkt sich auf die Zeit aus, die für die Durchführung der Bewertung benötigt wird.
Suchen und Anzeigen von Berichten
Bei der Multiserver-Assessment werden zwei Arten von Berichten generiert:
-
Ein aggregierter Bericht aller Quelldatenbanken.
-
Ein detaillierter Bewertungsbericht der Zieldatenbanken für jeden Schemanamen in einer Quelldatenbank.
Berichte werden in dem Verzeichnis gespeichert, das Sie im Dialogfeld Neue Multiserver-Bewertung für Speicherort ausgewählt haben.
Um auf die detaillierten Berichte zuzugreifen, können Sie in den Unterverzeichnissen navigieren, die nach Quelldatenbank, Schemaname und Zieldatenbank-Engine organisiert sind.
Aggregierte Berichte enthalten Informationen zur Konvertierungskomplexität einer Zieldatenbank in vier Spalten. Die Spalten enthalten Informationen zur Konvertierung von Codeobjekten, Speicherobjekten, Syntaxelementen und zur Komplexität der Konvertierung.
Das folgende Beispiel zeigt Informationen zur Konvertierung von zwei Oracle-Datenbankschemas nach Amazon RDS for PostgreSQL.

Dieselben vier Spalten werden an die Berichte für jede weitere angegebene Zieldatenbank-Engine angehängt.
Einzelheiten zum Lesen dieser Informationen finden Sie im Folgenden.
Ergebnis für einen aggregierten Bewertungsbericht
Der aggregierte Bewertungsbericht zur Migration von Multiserver-Datenbanken in AWS Schema Conversion Tool ist eine CSV-Datei mit den folgenden Spalten:
-
Server IP address and port -
Secret Manager key -
Name -
Description -
Database name -
Schema name -
Code object conversion % fortarget_database -
Storage object conversion % fortarget_database -
Syntax elements conversion % fortarget_database -
Conversion complexity fortarget_database
Um Informationen zu sammeln, werden vollständige Bewertungsberichte AWS SCT ausgeführt und anschließend die Berichte nach Schemas zusammengefasst.
Im Bericht zeigen die folgenden drei Felder den Prozentsatz der möglichen automatischen Konversionen auf der Grundlage der Bewertung:
- Konvertierung von Codeobjekten (%)
-
Der Prozentsatz der Codeobjekte im Schema, die automatisch oder mit minimalen Änderungen konvertiert werden AWS SCT können. Zu den Codeobjekten gehören Prozeduren, Funktionen, Ansichten und ähnliches.
- Konvertierung von Speicherobjekten%
-
Der Prozentsatz der Speicherobjekte, die SCT automatisch oder mit minimalen Änderungen konvertieren kann. Zu den Speicherobjekten gehören Tabellen, Indizes, Einschränkungen und ähnliches.
- Konvertierung von Syntaxelementen%
-
Der Prozentsatz der Syntaxelemente, die SCT automatisch konvertieren kann. Zu den Syntaxelementen gehören
SELECTFROM,DELETE,, undJOINKlauseln und ähnliches.
Die Berechnung der Konvertierungskomplexität basiert auf dem Konzept der Aktionspunkte. Ein Aktionspunkt spiegelt eine Art von Problem wider, das im Quellcode gefunden wurde und das Sie während der Migration zu einem bestimmten Ziel manuell beheben müssen. Ein Aktionspunkt kann mehrfach vorkommen.
Eine gewichtete Skala gibt den Grad der Komplexität an, mit dem eine Migration durchgeführt werden muss. Die Zahl 1 steht für die niedrigste und die Zahl 10 für die höchste Komplexitätsstufe.
