Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Migration von Hadoop-Workloads zu Amazon EMR mit AWS Schema Conversion Tool
Um Apache Hadoop-Cluster zu migrieren, stellen Sie sicher, dass Sie AWS SCT Version 1.0.670 oder höher verwenden. Machen Sie sich auch mit der Befehlszeilenschnittstelle (CLI) von vertraut AWS SCT. Weitere Informationen finden Sie unter CLI-Referenz für AWS Schema Conversion Tool.
Überblick über die Migration
Die folgende Abbildung zeigt das Architekturdiagramm der Migration von Apache Hadoop zu Amazon EMR.
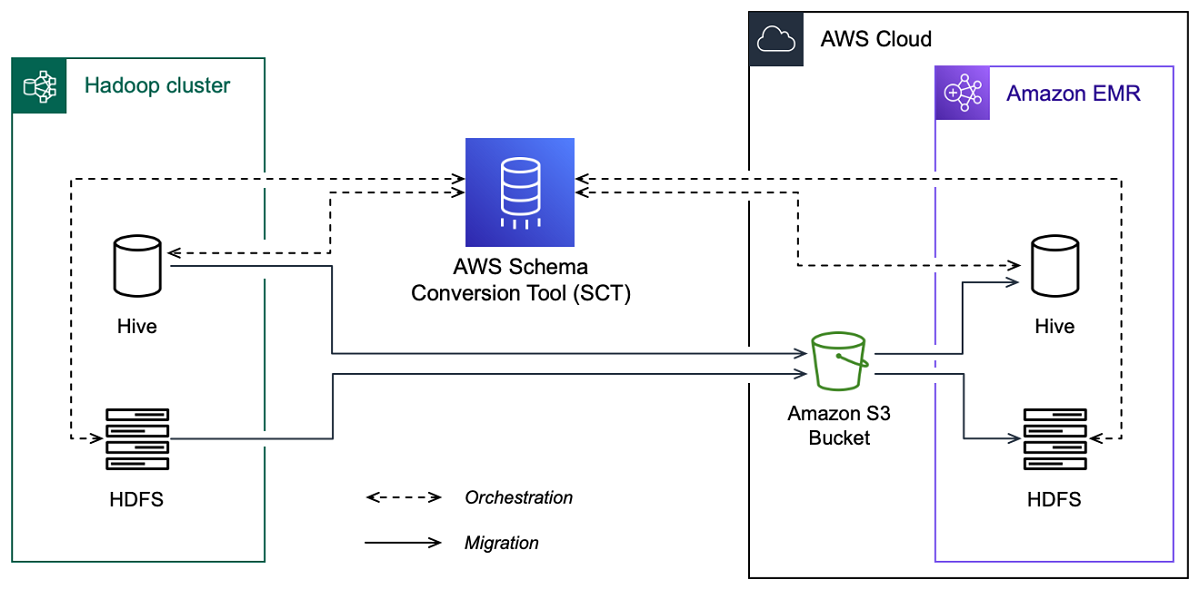
AWS SCT migriert Daten und Metadaten von Ihrem Hadoop-Quell-Cluster in einen Amazon S3 S3-Bucket. Als Nächstes werden Ihre Hive-Quellmetadaten AWS SCT verwendet, um Datenbankobjekte im Amazon EMR Hive-Zielservice zu erstellen. Optional können Sie Hive so konfigurieren, dass es als Metastore verwendet. AWS Glue Data Catalog In diesem Fall AWS SCT migriert Ihre Hive-Quellmetadaten in den. AWS Glue Data Catalog
Anschließend können AWS SCT Sie die Daten von einem Amazon S3-Bucket zu Ihrem Amazon EMR HDFS-Zielservice migrieren. Alternativ können Sie die Daten in Ihrem Amazon S3 S3-Bucket belassen und als Datenspeicher für Ihre Hadoop-Workloads verwenden.
Um die Hapood-Migration zu starten, erstellen Sie Ihr AWS SCT CLI-Skript und führen es aus. Dieses Skript enthält den kompletten Befehlssatz zur Ausführung der Migration. Sie können eine Vorlage des Hadoop-Migrationsskripts herunterladen und bearbeiten. Weitere Informationen finden Sie unter CLI-Szenarien abrufen.
Stellen Sie sicher, dass Ihr Skript die folgenden Schritte umfasst, damit Sie Ihre Migration von Apache Hadoop zu Amazon S3 und Amazon EMR ausführen können.
Schritt 1: Connect zu Ihren Hadoop-Clustern her
Um die Migration Ihres Apache Hadoop-Clusters zu starten, erstellen Sie ein neues Projekt. AWS SCT Stellen Sie als Nächstes eine Verbindung zu Ihren Quell- und Zielclustern her. Stellen Sie sicher, dass Sie Ihre AWS Zielressourcen erstellen und bereitstellen, bevor Sie mit der Migration beginnen.
In diesem Schritt verwenden Sie die folgenden AWS SCT CLI-Befehle.
CreateProject— um ein neues AWS SCT Projekt zu erstellen.AddSourceCluster— um eine Verbindung zum Quell-Hadoop-Cluster in Ihrem AWS SCT Projekt herzustellen.AddSourceClusterHive— um eine Verbindung zum Quell-Hive-Dienst in Ihrem Projekt herzustellen.AddSourceClusterHDFS— um eine Verbindung zum Quell-HDFS-Dienst in Ihrem Projekt herzustellen.AddTargetCluster— um eine Verbindung zum Amazon EMR-Zielcluster in Ihrem Projekt herzustellen.AddTargetClusterS3— um den Amazon S3 S3-Bucket zu Ihrem Projekt hinzuzufügen.AddTargetClusterHive— um eine Verbindung zum Ziel-Hive-Dienst in Ihrem Projekt herzustellenAddTargetClusterHDFS— um eine Verbindung zum Ziel-HDFS-Dienst in Ihrem Projekt herzustellen
Beispiele für die Verwendung dieser AWS SCT CLI-Befehle finden Sie unterVerbindung zu Apache Hadoop herstellen.
Wenn Sie den Befehl ausführen, der eine Verbindung zu einem Quell- oder Zielcluster herstellt, AWS SCT versucht er, die Verbindung zu diesem Cluster herzustellen. Wenn der Verbindungsversuch fehlschlägt, AWS SCT beendet es die Ausführung der Befehle aus Ihrem CLI-Skript und zeigt eine Fehlermeldung an.
Schritt 2: Richten Sie die Zuordnungsregeln ein
Nachdem Sie eine Verbindung zu Ihren Quell- und Zielclustern hergestellt haben, richten Sie die Zuordnungsregeln ein. Eine Zuordnungsregel definiert das Migrationsziel für einen Quellcluster. Stellen Sie sicher, dass Sie Zuordnungsregeln für alle Quellcluster einrichten, die Sie Ihrem AWS SCT Projekt hinzugefügt haben. Weitere Informationen zu Zuordnungsregeln finden Sie unterZuordnung von Datentypen in der AWS Schema Conversion Tool.
In diesem Schritt verwenden Sie den AddServerMapping Befehl. Dieser Befehl verwendet zwei Parameter, die die Quell- und Zielcluster definieren. Sie können den AddServerMapping Befehl mit dem expliziten Pfad zu Ihren Datenbankobjekten oder mit einem Objektnamen verwenden. Bei der ersten Option geben Sie den Typ des Objekts und seinen Namen an. Bei der zweiten Option geben Sie nur die Objektnamen an.
-
sourceTreePath— der explizite Pfad zu Ihren Quelldatenbankobjekten.targetTreePath— der explizite Pfad zu Ihren Zieldatenbankobjekten. -
sourceNamePath— der Pfad, der nur die Namen Ihrer Quellobjekte enthält.targetNamePath— der Pfad, der nur die Namen Ihrer Zielobjekte enthält.
Im folgenden Codebeispiel wird eine Zuordnungsregel erstellt, die explizite Pfade für die testdb Hive-Quelldatenbank und den EMR-Zielcluster verwendet.
AddServerMapping -sourceTreePath: 'Clusters.HADOOP_SOURCE.HIVE_SOURCE.Databases.testdb' -targetTreePath: 'Clusters.HADOOP_TARGET.HIVE_TARGET' /
Sie können dieses Beispiel und die folgenden Beispiele in Windows verwenden. Um die CLI-Befehle unter Linux auszuführen, stellen Sie sicher, dass Sie die Dateipfade entsprechend für Ihr Betriebssystem aktualisiert haben.
Im folgenden Codebeispiel wird eine Zuordnungsregel erstellt, die die Pfade verwendet, die nur die Objektnamen enthalten.
AddServerMapping -sourceNamePath: 'HADOOP_SOURCE.HIVE_SOURCE.testdb' -targetNamePath: 'HADOOP_TARGET.HIVE_TARGET' /
Sie können Amazon EMR oder Amazon S3 als Ziel für Ihr Quellobjekt wählen. Für jedes Quellobjekt können Sie nur ein Ziel in einem einzigen AWS SCT Projekt auswählen. Um das Migrationsziel für ein Quellobjekt zu ändern, löschen Sie die bestehende Zuordnungsregel und erstellen Sie dann eine neue Zuordnungsregel. Verwenden Sie den DeleteServerMapping Befehl, um eine Zuordnungsregel zu löschen. Dieser Befehl verwendet einen der beiden folgenden Parameter.
sourceTreePath— der explizite Pfad zu Ihren Quelldatenbankobjekten.sourceNamePath— der Pfad, der nur die Namen Ihrer Quellobjekte enthält.
Weitere Informationen zu den DeleteServerMapping Befehlen AddServerMapping und finden Sie in der AWS Schema Conversion Tool CLI-Referenz
Schritt 3: Erstellen Sie einen Bewertungsbericht
Bevor Sie mit der Migration beginnen, empfehlen wir, einen Bewertungsbericht zu erstellen. In diesem Bericht werden alle Migrationsaufgaben zusammengefasst und die während der Migration zu erwartenden Maßnahmen detailliert beschrieben. Um sicherzustellen, dass Ihre Migration nicht fehlschlägt, lesen Sie diesen Bericht und gehen Sie vor der Migration auf die Aktionspunkte ein. Weitere Informationen finden Sie unter Bewertungsbericht.
In diesem Schritt verwenden Sie den CreateMigrationReport Befehl. Dieser Befehl verwendet zwei Parameter. Der treePath Parameter ist obligatorisch und der forceMigrate Parameter ist optional.
treePath— der explizite Pfad zu Ihren Quelldatenbankobjekten, für die Sie eine Kopie des Bewertungsberichts speichern.forceMigrate— Wenn diese Option auf gesetzt isttrue, AWS SCT wird die Migration auch dann fortgesetzt, wenn Ihr Projekt einen HDFS-Ordner und eine Hive-Tabelle enthält, die auf dasselbe Objekt verweisen. Der Standardwert istfalse.
Anschließend können Sie eine Kopie des Bewertungsberichts als PDF- oder CSV-Datei (Comma-Separated Value) speichern. Verwenden Sie dazu den Befehl SaveReportPDF oderSaveReportCSV.
Der SaveReportPDF Befehl speichert eine Kopie Ihres Bewertungsberichts als PDF-Datei. Dieser Befehl verwendet vier Parameter. Der file Parameter ist obligatorisch, andere Parameter sind optional.
file— der Pfad zur PDF-Datei und ihr Name.filter— der Name des Filters, den Sie zuvor erstellt haben, um den Umfang Ihrer zu migrierenden Quellobjekte zu definieren.treePath— der explizite Pfad zu Ihren Quelldatenbankobjekten, für die Sie eine Kopie des Bewertungsberichts speichern.namePath— der Pfad, der nur die Namen der Zielobjekte enthält, für die Sie eine Kopie des Bewertungsberichts speichern.
Der SaveReportCSV Befehl speichert Ihren Bewertungsbericht in drei CSV-Dateien. Dieser Befehl verwendet vier Parameter. Der directory Parameter ist obligatorisch, andere Parameter sind optional.
directory— der Pfad zu dem Ordner, in dem die CSV-Dateien AWS SCT gespeichert werden.filter— der Name des Filters, den Sie zuvor erstellt haben, um den Umfang Ihrer zu migrierenden Quellobjekte zu definieren.treePath— der explizite Pfad zu Ihren Quelldatenbankobjekten, für die Sie eine Kopie des Bewertungsberichts speichern.namePath— der Pfad, der nur die Namen der Zielobjekte enthält, für die Sie eine Kopie des Bewertungsberichts speichern.
Im folgenden Codebeispiel wird eine Kopie des Bewertungsberichts in der c:\sct\ar.pdf Datei gespeichert.
SaveReportPDF -file:'c:\sct\ar.pdf' /
Im folgenden Codebeispiel wird eine Kopie des Bewertungsberichts als CSV-Dateien im c:\sct Ordner gespeichert.
SaveReportCSV -file:'c:\sct' /
Weitere Informationen zu den SaveReportCSV Befehlen SaveReportPDF und finden Sie in der AWS Schema Conversion Tool CLI-Referenz
Schritt 4: Migrieren Sie Ihren Apache Hadoop-Cluster zu Amazon EMR mit AWS SCT
Nachdem Sie Ihr AWS SCT Projekt konfiguriert haben, starten Sie die Migration Ihres lokalen Apache Hadoop-Clusters zum. AWS Cloud
In diesem Schritt verwenden Sie die Befehle MigrateMigrationStatus, undResumeMigration.
Der Migrate Befehl migriert Ihre Quellobjekte in den Zielcluster. Dieser Befehl verwendet vier Parameter. Stellen Sie sicher, dass Sie den treePath Parameter filter oder angeben. Andere Parameter sind optional.
filter— der Name des Filters, den Sie zuvor erstellt haben, um den Bereich Ihrer zu migrierenden Quellobjekte zu definieren.treePath— der explizite Pfad zu Ihren Quelldatenbankobjekten, für die Sie eine Kopie des Bewertungsberichts speichern.forceLoad— Wenn diese Option auf gesetzt isttrue, AWS SCT werden Datenbank-Metadatenbäume während der Migration automatisch geladen. Der Standardwert istfalse.forceMigrate— Wenn diese Option auf gesetzt isttrue, AWS SCT wird die Migration auch dann fortgesetzt, wenn Ihr Projekt einen HDFS-Ordner und eine Hive-Tabelle enthält, die auf dasselbe Objekt verweisen. Der Standardwert istfalse.
Der MigrationStatus Befehl gibt Informationen über den Migrationsfortschritt zurück. Um diesen Befehl auszuführen, geben Sie den Namen Ihres Migrationsprojekts für den name Parameter ein. Sie haben diesen Namen im CreateProject Befehl angegeben.
Der ResumeMigration Befehl setzt die unterbrochene Migration fort, die Sie mit dem Migrate Befehl gestartet haben. Der ResumeMigration Befehl verwendet keine Parameter. Um die Migration fortzusetzen, müssen Sie eine Verbindung zu Ihren Quell- und Zielclustern herstellen. Weitere Informationen finden Sie unter Verwaltung Ihres Migrationsprojekts.
Das folgende Codebeispiel migriert Daten von Ihrem HDFS-Quellservice zu Amazon EMR.
Migrate -treePath: 'Clusters.HADOOP_SOURCE.HDFS_SOURCE' -forceMigrate: 'true' /
Ausführen Ihres CLI-Skripts
Wenn Sie mit der Bearbeitung Ihres AWS SCT CLI-Skripts fertig sind, speichern Sie es als Datei mit der .scts Erweiterung. Jetzt können Sie Ihr Skript im app Ordner Ihres AWS SCT Installationspfads ausführen. Führen Sie dazu den folgenden Befehl aus.
RunSCTBatch.cmd --pathtoscts "C:\script_path\hadoop.scts"
Ersetzen Sie im vorherigen Beispiel durch script_path den Pfad zu Ihrer Datei mit dem CLI-Skript. Weitere Hinweise zum Ausführen von CLI-Skripts in AWS SCT finden Sie unterSkriptmodus.
Verwaltung Ihres Big-Data-Migrationsprojekts
Nachdem Sie die Migration abgeschlossen haben, können Sie Ihr AWS SCT Projekt für die future Verwendung speichern und bearbeiten.
Verwenden Sie den SaveProject Befehl, um Ihr AWS SCT Projekt zu speichern. Dieser Befehl verwendet keine Parameter.
Das folgende Codebeispiel speichert Ihr AWS SCT Projekt.
SaveProject /
Verwenden Sie den OpenProject Befehl, um Ihr AWS SCT Projekt zu öffnen. Dieser Befehl verwendet einen obligatorischen Parameter. Geben Sie für den file Parameter den Pfad zu Ihrer AWS SCT Projektdatei und deren Namen ein. Sie haben den Projektnamen im CreateProject Befehl angegeben. Stellen Sie sicher, dass Sie dem Namen Ihrer Projektdatei die .scts Erweiterung hinzufügen, um den OpenProject Befehl auszuführen.
Im folgenden Codebeispiel wird das hadoop_emr Projekt aus dem c:\sct Ordner geöffnet.
OpenProject -file: 'c:\sct\hadoop_emr.scts' /
Nachdem Sie Ihr AWS SCT Projekt geöffnet haben, müssen Sie die Quell- und Zielcluster nicht mehr hinzufügen, da Sie sie bereits zu Ihrem Projekt hinzugefügt haben. Um mit Ihren Quell- und Zielclustern arbeiten zu können, müssen Sie eine Verbindung zu ihnen herstellen. Dazu verwenden Sie die ConnectTargetCluster Befehle ConnectSourceCluster und. Diese Befehle verwenden dieselben Parameter wie die AddTargetCluster Befehle AddSourceCluster und. Sie können Ihr CLI-Skript bearbeiten und den Namen dieser Befehle ersetzen, sodass die Liste der Parameter unverändert bleibt.
Das folgende Codebeispiel stellt eine Verbindung zum Quell-Hadoop-Cluster her.
ConnectSourceCluster -name: 'HADOOP_SOURCE' -vendor: 'HADOOP' -host: 'hadoop_address' -port: '22' -user: 'hadoop_user' -password: 'hadoop_password' -useSSL: 'true' -privateKeyPath: 'c:\path\name.pem' -passPhrase: 'hadoop_passphrase' /
Das folgende Codebeispiel stellt eine Verbindung mit dem Amazon EMR-Zielcluster her.
ConnectTargetCluster -name: 'HADOOP_TARGET' -vendor: 'AMAZON_EMR' -host: 'ec2-44-44-55-66.eu-west-1.EXAMPLE.amazonaws.com' -port: '22' -user: 'emr_user' -password: 'emr_password' -useSSL: 'true' -privateKeyPath: 'c:\path\name.pem' -passPhrase: '1234567890abcdef0!' -s3Name: 'S3_TARGET' -accessKey: 'AKIAIOSFODNN7EXAMPLE' -secretKey: 'wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY' -region: 'eu-west-1' -s3Path: 'doc-example-bucket/example-folder' /
Ersetzen Sie es im vorherigen Beispiel hadoop_address durch die IP-Adresse Ihres Hadoop-Clusters. Konfigurieren Sie bei Bedarf den Wert der Port-Variablen. Ersetzen Sie als Nächstes hadoop_user und hadoop_password durch den Namen Ihres Hadoop-Benutzers und das Passwort für diesen Benutzer. Geben Sie für path\name den Namen und den Pfad zur PEM-Datei für Ihren Hadoop-Quellcluster ein. Weitere Informationen zum Hinzufügen Ihrer Quell- und Zielcluster finden Sie unter. Herstellen einer Verbindung zu Apache Hadoop-Datenbanken mit dem AWS Schema Conversion Tool
Nachdem Sie eine Verbindung zu Ihren Quell- und Ziel-Hadoop-Clustern hergestellt haben, müssen Sie eine Verbindung zu Ihren Hive- und HDFS-Services sowie zu Ihrem Amazon S3 S3-Bucket herstellen. Dazu verwenden Sie die BefehleConnectSourceClusterHive,, ConnectSourceClusterHdfs ConnectTargetClusterHiveConnectTargetClusterHdfs, und. ConnectTargetClusterS3 Diese Befehle verwenden dieselben Parameter wie die Befehle, mit denen Sie Hive- und HDFS-Services sowie den Amazon S3 S3-Bucket zu Ihrem Projekt hinzugefügt haben. Bearbeiten Sie das CLI-Skript, um das Add Präfix durch Connect die Befehlsnamen zu ersetzen.
