Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Lokale sekundäre Indizes
Einige Anwendungen müssen Daten nur mithilfe der Basistabelle des Primärschlüssels abfragen. Es kann jedoch Situationen geben, in denen ein alternativer Sortierschlüssel hilfreich wäre. Um Ihrer Anwendung verschiedene Sortierschlüssel zur Auswahl anzubieten, können Sie einen oder mehrere lokale sekundäre Indizes in einer Amazon-DynamoDB-Tabelle erstellen und Query- oder Scan-Anforderungen für diese Indizes generieren.
Themen
Schritt 6: Verwenden eines lokalenx sekundären Indexes
Betrachten Sie als Beispiel die Thread-Tabelle. Diese Tabelle ist nützlich für eine Anwendung wie AWS -Diskussionsforen
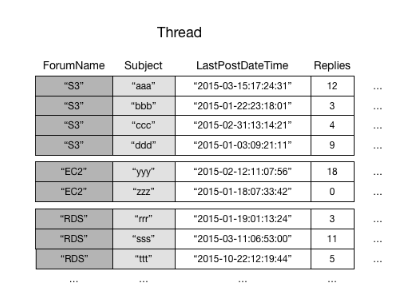
DynamoDB speichert alle Elemente mit demselben Partitionsschlüsselwert fortlaufend. In diesem Beispiel könnte mit einem bestimmten ForumName eine Query-Operation sofort alle Threads für dieses Forum ermitteln. Innerhalb einer Gruppe von Elementen mit demselben Partitionsschlüsselwert werden die Elemente nach Sortierschlüsselwert sortiert. Wenn der Sortierschlüssel (Subject) in der Abfrage auch angegeben ist, kann DynamoDB die Ergebnisse, die zurückgegeben werden, einschränken und z. B. alle Threads im Forum „S3“ mit einem Subject, der mit „A“ beginnt, zurückgeben.
Einige Anforderungen erfordern komplexere Datenzugriffsmuster. Zum Beispiel:
-
Welche Forum-Threads erhalten die meisten Ansichten und Antworten?
-
Welcher Thread in einem bestimmten Forum enthält die meisten Nachrichten?
-
Wie viele Threads wurden in einem bestimmten Forum in einem angegebenen Zeitraum gepostet?
Um diese Fragen zu beantworten, würde die Query-Aktion nicht ausreichen. Stattdessen müssen Sie die gesamte Tabelle Scan. Bei einer Tabelle mit Millionen von Elementen würde dabei der bereitgestellte Lesedurchsatz größtenteils aufgebraucht und der Vorgang würde sehr lange dauern.
Sie können jedoch einen oder mehrere lokale sekundäre Indizes für Nicht-Schlüsselattribute angeben, z. B. Replies oder LastPostDateTime.
Ein lokaler sekundärer Index verwaltet einen alternativen Sortierschlüssel für einen bestimmten Partitionsschlüsselwert. Ein lokaler sekundärer Index enthält auch eine Kopie einiger oder aller Attribute aus seiner Basistabelle. Sie geben beim Erstellen der Tabelle an, welche Attribute in den lokalen sekundären Index projiziert werden. Die Daten in einem lokalen sekundären Index werden durch denselben Partitionsschlüssel strukturiert wie die Basistabelle, jedoch mit einem anderen Sortierschlüssel. Auf diese Weise können Sie in dieser anderen Dimension effizient auf Datenelemente zugreifen. Wenn Sie eine größere Abfrage- oder Scanflexibilität benötigen, können Sie bis zu fünf lokale sekundäre Indizes pro Tabelle erstellen.
Angenommen, eine Anwendung muss alle Threads ermitteln, die in den letzten drei Monaten in einem bestimmten Forum veröffentlicht wurden. Ohne lokalen sekundären Index müsste die Anwendung eine Scan-Aktion für die gesamte Thread-Tabelle ausführen und alle Beiträge, die nicht innerhalb des Zeitraums gepostet wurden, verwerfen. Mit einem lokalen sekundären Index könnte eine Query-Operation LastPostDateTime verwenden, um Daten schnell zu finden.
Das folgende Diagramm zeigt einen lokalen sekundären Index mit dem Namen LastPostIndex. Beachten Sie, dass der Partitionsschlüssel mit dem Schlüssel der Thread-Tabelle übereinstimmt, der Sortierschlüssel jedoch LastPostDateTime ist.
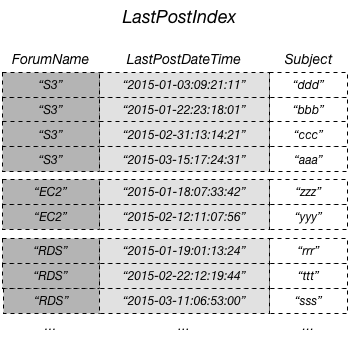
Jeder lokale sekundäre Index muss die folgenden Bedingungen erfüllen:
-
Der Partitionsschlüssel ist mit dem Schlüssel der Basistabelle identisch.
-
Der Sortierschlüssel besteht aus genau einem skalaren Attribut.
-
Der Sortierschlüssel der Basistabelle wird in den Index projiziert, wo er als Nicht-Schlüsselattribut fungiert.
In diesem Beispiel lautet der Partitionsschlüssel ForumName und der Sortierschlüssel des lokalen sekundären Indexes lautet LastPostDateTime. Darüber hinaus wird der Sortierschlüsselwert der Basistabelle (in diesem Beispiel Subject) in den Index projiziert, ist jedoch kein Bestandteil des Indexschlüssels. Wenn eine Anwendung eine Liste basierend auf ForumName und LastPostDateTime benötigt, kann sie eine Query-Anforderung für LastPostIndex erstellen. Die Abfrageergebnisse sind nach LastPostDateTime sortiert und können in auf- oder absteigender Reihenfolge zurückgegeben werden. Die Abfrage kann auch Schlüsselbedingungen anwenden, z. B. nur Elemente zurückgeben mit einem LastPostDateTime innerhalb einer bestimmten Zeitspanne.
Jeder lokale sekundäre Index enthält automatisch die Partitions- und Sortierschlüssel der Basistabelle. Nicht-Schlüsselattribute können Sie optional in den Index projizieren. Wenn Sie den Index abfragen, kann DynamoDB diese projizierten Attribute effizient abrufen. Beim Abfragen eines lokalen sekundären Indizes können auch Attribute abgerufen werden, die nicht in den Index projiziert sind. DynamoDB ruft diese Attribute automatisch aus der Basistabelle ab, jedoch mit größerer Latenz und höheren Kosten für den bereitgestellten Durchsatz.
Für alle lokale sekundäre Indizes können Sie bis zu 10 GB Daten pro eindeutigem Partitionsschlüsselwert speichern. Diese Abbildung enthält alle Elemente in der Basistabelle sowie alle Elemente in den Indizes, die denselben Partitionsschlüsselwert haben. Weitere Informationen finden Sie unter Elementauflistungen in lokalen sekundären Indizes.
Attributprojektionen
Mit LastPostIndex könnte eine Anwendung ForumName und LastPostDateTime als Abfragekriterien verwenden. Um jedoch zusätzliche Attribute abzurufen, muss DynamoDB zusätzliche Lesevorgänge für die Thread-Tabelle ausführen. Diese zusätzlichen Lesevorgänge werden als Abrufe bezeichnet. Diese können die Gesamtgröße des bereitgestellten Durchsatzes, der für eine Abfrage erforderlich ist, erhöhen.
Angenommen, Sie möchten eine Webseite mit einer Liste aller Threads in „S3“ und der Anzahl der Antworten für jeden Thread füllen, sortiert nach der letzten Antwort, date/time beginnend mit der neuesten Antwort. Zum Auffüllen dieser Liste benötigen Sie die folgenden Attribute:
-
Subject -
Replies -
LastPostDateTime
Die beste Möglichkeit, diese Daten abzufragen und Abrufoperationen zu vermeiden, ist, das Attribut Replies aus der Tabelle in den lokalen sekundären Index zu projizieren, wie in diesem Diagramm dargestellt:
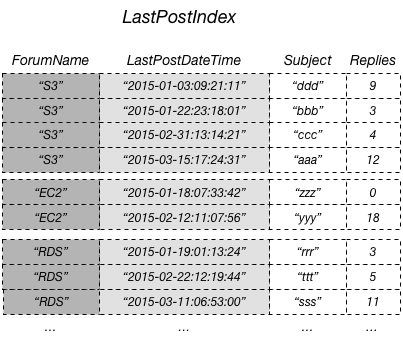
Eine Projektion ist der Satz von Attributen, die aus einer Tabelle in einen sekundären Index kopiert werden. Der Partitionsschlüssel und der Sortierschlüssel der Tabelle werden immer in den Index projiziert. Sie können andere Attribute projizieren, um die Abfrageanforderungen Ihrer Anwendung zu unterstützen. Wenn Sie einen Index abfragen, kann Amazon DynamoDB auf jedes Attribut in der Projektion zugreifen, als ob sich diese Attribute in einer eigenen Tabelle befinden.
Wenn Sie einen sekundären Index erstellen, müssen Sie die Attribute angeben, die in den Index projiziert werden. DynamoDB bietet hierfür drei verschiedene Optionen:
-
KEYS_ONLY – Jeder Eintrag im Index besteht nur aus dem Tabellenpartitionsschlüssel und Sortierschlüsselwerten, sowie den Indexschlüsselwerten. Die Option
KEYS_ONLYführt zu dem kleinstmöglichen sekundären Index. -
INCLUDE – Zusätzlich zu den in
KEYS_ONLYbeschriebenen Attributen, enthält der sekundäre Index andere Nicht-Schlüsselattribute, die Sie angeben. -
ALL – Der sekundäre Index enthält alle Attribute der Quelltabelle. Da alle Tabellendaten im Index dupliziert werden, wird führt eine
ALL-Projektion zu dem größtmöglichen sekundären Index.
Im vorherigen Diagramm wird das Nicht-Schlüsselattribut in Replies in LastPostIndex projiziert. Eine Anwendung kann LastPostIndex anstelle der vollständigen Thread-Tabelle abfragen, um eine Webseite mi tSubject, Replies und LastPostDateTime auszufüllen. Wenn alle anderen Nicht-Schlüsselattribute abgefragt werden, muss DynamoDB diese Attribute aus der Thread-Tabelle abrufen.
Von der Anwendungsseite aus betrachtet, ist das Abrufen zusätzlicher Attribute aus der Basistabelle automatisch und transparent. Es muss keine Anwendungslogik umgeschrieben werden. Beachten Sie jedoch, dass dieses Abrufen den Leistungsvorteil, den ein lokaler sekundärer Index bietet, erheblich einschränken kann.
Wenn Sie die Attribute zum Projizieren in einen lokalen sekundären Index auswählen, müssen Sie die Differenz der Kosten des bereitgestellten Durchsatzes und der Speicherkosten berücksichtigen:
-
Wenn Sie nur auf wenige Attribute mit möglichst niedriger Latenz zugreifen müssen, erwägen Sie, nur diese Attribute in einen lokalen sekundären Index zu projizieren. Je kleiner der Index, desto geringer die Speicher- und somit die Schreibkosten. Wenn Sie Attribute gelegentlich abrufen müssen, können die Kosten für den bereitgestellten Durchsatz die längerfristigen Kosten für die Speicherung dieser Attribute aufwiegen.
-
Greift Ihre Anwendung häufig auf einige Nicht-Schlüsselattribute zu, sollten Sie erwägen, diese Attribute in einen lokalen sekundären Index zu projizieren. Die zusätzlichen Speicherkosten für den lokalen sekundären Index wiegen die Kosten für die Durchführung häufiger Tabellen-Scans auf.
-
Wenn Sie auf die meisten Nicht-Schlüsselattribute in regelmäßigen Abständen zugreifen müssen, können Sie diese Attribute – oder sogar die gesamte Basistabelle – in einen lokalen sekundären Index projizieren. Auf diese Weise erhalten Sie maximale Flexibilität und den niedrigsten Verbrauch des bereitgestellten Durchsatzes, da kein Abrufen erforderlich ist. Die Speicherkosten erhöhen oder verdoppeln sich allerdings sogar, wenn Sie alle Attribute projizieren.
-
Wenn Ihre Anwendung eine Tabelle selten abfragen, jedoch viele Schreibvorgänge oder Updates für die Daten in der Tabelle durchführen muss, erwägen Sie das Projizieren von KEYS_ONLY. Der wäre nur klein, stünde aber weiterhin bei Bedarf für Abfrageaktivitäten zur Verfügung.
Erstellen eines lokalen sekundären Index
Um einen oder mehrere lokale sekundäre Indizes für eine Tabelle zu erstellen, verwenden Sie den LocalSecondaryIndexes-Parameter der Operation CreateTable. Lokale sekundäre Indizes für eine Tabelle werden erstellt, wenn die Tabelle erstellt wird. Wenn Sie eine Tabelle löschen, werden alle lokalen sekundären Indizes in dieser Tabelle ebenfalls gelöscht.
Sie müssen ein Nicht-Schlüsselattribut angeben, das als Sortierschlüssel des lokalen sekundären Indizes dient. Das Attribut, das Sie auswählen, muss ein skalarer String, Number oder Binary sein. Andere Skalar-, Dokument- und Satztypen sind nicht zulässig. Eine vollständige Liste der Datentypen finden Sie unter Datentypen.
Wichtig
Für Tabellen mit lokalen sekundären Indizes besteht eine Größenbeschränkung von 10 GB pro Partitionsschlüsselwert. Eine Tabelle mit lokalem sekundärem Index kann eine beliebige Anzahl von Elementen speichern, solange die Gesamtgröße eines Partitionsschlüsselwerts 10 GB nicht überschreitet. Weitere Informationen finden Sie unter Größenlimit der Elementauflistung.
Sie können Attribute jeden Datentyps in einen lokalen sekundären Index projizieren. Dazu zählen skalare Werte, Dokumente und Sätze. Eine vollständige Liste der Datentypen finden Sie unter Datentypen.
Lesen von Daten aus einem lokalen sekundären Index
Sie können Elemente aus einem lokalen sekundären Index mit dem Befehl Query und Scan verwenden. Die GetItem- und BatchGetItem-Operationen können für einen lokalen sekundären Index nicht verwendet werden.
Abfragen eines lokalen sekundären Indexes
In einer DynamoDB-Tabelle müssen der kombinierte Partitionsschlüsselwert und der Sortierschlüsselwert für jedes Element eindeutig sein. In einem lokalen sekundären Index müssen die Sortierschlüsselwerte für einen bestimmten Partitionsschlüsselwert jedoch nicht eindeutig sein. Wenn mehrere Elemente mit demselben Sortierschlüsselwert im lokalen sekundären Index vorhanden sind, gibt eine Query-Operation alle Elemente mit demselben Partitionsschlüsselwert zurück. In der Antwort werden die übereinstimmenden Elemente nicht in einer bestimmten Reihenfolge zurückgegeben.
Sie können einen lokalen sekundären Index mit Eventually-Consistent- oder Strongly-Consistent-Lesevorgängen abfragen. Um die Art der Konsistenz anzugeben, verwenden Sie den Parameter ConsistentRead der Query-Operation. Bei einem Strongly-Consistent-Lesevorgang von einem lokalen sekundären Index werden immer die zuletzt aktualisierten Werte zurückgegeben. Wenn die Abfrage weitere Attribute aus der Basistabelle abrufen muss, sind diese Attribute in Bezug auf den Index konsistent.
Beispiel
Betrachten Sie die folgenden Daten, die von einer Query-Operation zum Abfragen von Daten aus den Diskussionsbeiträgen in einem bestimmten Forum zurückgegeben werden:
{ "TableName": "Thread", "IndexName": "LastPostIndex", "ConsistentRead": false, "ProjectionExpression": "Subject, LastPostDateTime, Replies, Tags", "KeyConditionExpression": "ForumName = :v_forum and LastPostDateTime between :v_start and :v_end", "ExpressionAttributeValues": { ":v_start": {"S": "2015-08-31T00:00:00.000Z"}, ":v_end": {"S": "2015-11-31T00:00:00.000Z"}, ":v_forum": {"S": "EC2"} } }
Vorgänge in dieser Abfrage:
-
DynamoDB greift auf
LastPostIndexmit dem PartitionsschlüsselForumNamezu, um die Indexelemente für „EC2“ zu ermitteln. Alle Indexelemente mit diesem Schlüssel werden nebeneinander gespeichert, um ein schnelles Abrufen zu ermöglichen. -
In diesem Forum verwendet DynamoDB den Index, um die Schlüssel, die der angegebenen
LastPostDateTime-Bedingung entsprechen, zu suchen. -
Da das Attribut
Repliesin den Index projiziert wird, kann DynamoDB dieses Attribut abrufen, ohne zusätzlichen bereitgestellten Durchsatz zu verbrauchen. -
Das Attribut
Tagswird nicht in den Index projiziert, sodass DynamoDB auf dieThread-Tabelle zugreifen muss, um dieses Attribut abzurufen. -
Die Ergebnisse werden sortiert nach
LastPostDateTime. Die Indexeinträge sind nach Partitionsschlüsselwert und dann nach Sortierschlüsselwert sortiert undQuerygibt sie in der Reihenfolge, in der sie gespeichert werden, zurück. (Sie können den ParameterScanIndexForwardverwenden, um die Ergebnisse in absteigender Reihenfolge anzuzeigen.)
Da das Attribut Tags nicht in den lokalen sekundären Index projiziert wird, muss DynamoDB zusätzliche Lesekapazitätseinheiten verbrauchen, um dieses Attribut aus der Basistabelle abzurufen. Wenn Sie diese Abfrage häufig ausführen müssen, sollten Sie Tags in LastPostIndex verwenden, um das Abrufen von der Basistabelle zu vermeiden. Wenn Sie jedoch nur gelegentlich auf Tags zugreifen müssen, lohnen sich die zusätzlichen Speicherkosten für das Projizieren von Tags in den Index möglicherweise nicht.
Scannen eines lokalen sekundären Indexes
Sie können Scan verwenden, um alle Daten aus einem lokalen sekundären Index abzurufen. Geben Sie dazu den Namen der Basistabelle sowie den Indexnamen in der Abfrage an. Mit einer Scan-Operation liest DynamoDB alle Daten im Index und gibt sie an die Anwendung zurück. Sie können auch anfordern, dass nur einige der Daten zurückgegeben und die verbleibenden Daten verworfen werden. Verwenden Sie dazu den Parameter FilterExpression der Scan-API. Weitere Informationen finden Sie unter Filterausdrücke für Scan.
Schreibvorgänge und lokale sekundäre Indizes
DynamoDB synchronisiert automatisch alle lokalen sekundären Indizes mit ihren jeweiligen Basistabellen. Anwendungen schreiben niemals direkt in einen Index. Allerdings ist es wichtig, zu wissen, welche Auswirkungen es hat, wie DynamoDB diese Indizes verwaltet.
Beim Erstellen eines lokalen sekundären Indizes geben Sie ein Attribut als Sortierschlüssel für den Index an. Außerdem bestimmen Sie einen Datentyp für dieses Attribut. Das bedeutet, dass wenn Sie ein Element in die Basistabelle schreiben und das Element ein Indexschlüsselattribut definiert, der entsprechende Typ dem Datentyp des Indexschlüsselschemas entsprechen muss. Im Fall von LastPostIndex wird der Sortierschlüssel LastPostDateTime im Index als Datentyp String definiert. Wenn Sie versuchen, der Tabelle Thread ein Element hinzuzufügen und einen anderen Datentyp für LastPostDateTime (wie z. B. Number) anzugeben, gibt DynamoDB eine ValidationException aufgrund der fehlenden Übereinstimmung des Datentyps zurück.
Es ist nicht notwendig, eine 1:1-Beziehung zwischen den Elementen in einer Basistabelle und den Elementen in einem lokalen sekundären Index herzustellen. In der Tat kann dieses Verhalten für viele Anwendungen vorteilhaft sein.
Eine Tabelle mit vielen lokalen sekundären Indizes verursacht höhere Kosten für Schreibaktivitäten als Tabellen mit weniger Indizes. Weitere Informationen finden Sie unter Überlegungen im Hinblick auf die bereitgestellte Durchsatzkapazität für lokale sekundäre Indizes.
Wichtig
Für Tabellen mit lokalen sekundären Indizes besteht eine Größenbeschränkung von 10 GB pro Partitionsschlüsselwert. Eine Tabelle mit lokalem sekundärem Index kann eine beliebige Anzahl von Elementen speichern, solange die Gesamtgröße eines Partitionsschlüsselwerts 10 GB nicht überschreitet. Weitere Informationen finden Sie unter Größenlimit der Elementauflistung.
Überlegungen im Hinblick auf die bereitgestellte Durchsatzkapazität für lokale sekundäre Indizes
Wenn Sie eine Tabelle in DynamoDB erstellen, stellen Sie Lese- und Schreibkapazitätseinheiten für den erwarteten Workload der Tabelle bereit. Dieser Workload umfasst Lese- und Schreibaktivitäten in den lokalen sekundären Indizes der Tabelle.
Die aktuellen Preise für die bereitgestellte Durchsatzkapazität finden Sie unter Amazon-DynamoDB-Preise
Lesekapazitätseinheiten
Wenn Sie einen lokalen sekundären Index abfragen, hängt die Anzahl der verbrauchten Lesekapazitätseinheiten davon ab, wie auf die Daten zugegriffen wird.
Ähnlich wie Tabellenabfragen kann eine Indexabfrage auch entweder Eventually-Consistent- oder Strongly-Consistent-Lesevorgänge abhängig vom Wert ConsistentRead verwenden. Ein Strongly-Consistent-Lesevorgang belegt eine Lesekapazitätseinheit, ein Eventually-Consistent-Lesevorgang verbraucht nur die Hälfte. Daher können Sie Ihre Kosten für Lesekapazitätseinheiten durch Auswählen von Eventually Consistent-Lesevorgängen reduzieren.
Für Indexabfragen, die nur Indexschlüssel und projizierte Attribute anfordern, berechnet DynamoDB die bereitgestellten Leseaktivitäten auf die gleiche Weise wie für Tabellenabfragen. Der einzige Unterschied besteht darin, dass die Berechnung auf der Größe der Indexeinträge und nicht auf der Größe des Elements in der Basistabelle beruht. Die Anzahl der Lesekapazitätseinheiten ist die Summe aller projizierten Attributgrößen sämtlicher zurückgegebener Elemente. Das Ergebnis wird dann auf den nächsten 4 KB-Grenzwert aufgerundet. Weitere Informationen darüber, wie DynamoDB die bereitgestellte Durchsatznutzung berechnet, finden Sie unter DynamoDB – Modus mit bereitgestellter Kapazität.
Bei Indexabfragen, die Attribute lesen, die nicht in den lokalen sekundären Index projiziert werden, muss DynamoDB diese Attribute zusätzlich zum Lesen der projizierten Attribute aus dem Index aus der Basistabelle abrufen. Diese Abrufe treten auf, wenn Sie nicht projizierte Attribute in die Parameter Select oder ProjectionExpression der Query-Operation einbeziehen. Das Abrufen verursacht zusätzliche Latenz bei Abfrageantworten und verursacht auch höhere Kosten für den bereitgestellten Durchsatz: Zusätzlich zu den zuvor beschriebenen Lesevorgängen aus dem lokalen sekundären Index werden Ihnen Lesekapazitätseinheiten für jedes abgerufene Basistabellenelement in Rechnung gestellt. Diese Kosten fallen nicht nur für die angeforderten Attribute an, sondern für jedes Element, das aus der Tabelle gelesen wird.
Die maximale Größe der von einer Query-Operation zurückgegebenen Ergebnisse beträgt 1 MB. Diese umfasst die Größen aller Attributnamen und Werte sämtlicher zurückgegebenen Elemente. Wenn jedoch eine Abfrage für einen lokalen sekundären Index veranlasst, dass DynamoDB Elementattribute aus der Basistabelle abruft, kann die maximale Größe der Daten in den Ergebnissen niedriger sein. In diesem Fall setzt sich die Ergebnisgröße aus folgender Summe zusammen:
-
Die Größe der übereinstimmenden Elemente im Index wird auf die nächste 4 KB aufgerundet.
-
Die Größe der einzelnen übereinstimmenden Elemente in der Basistabelle wird für jedes einzelne Element auf die nächste 4 KB aufgerundet.
Mit dieser Formel beträgt die maximale Größe der von einer Abfrageoperation zurückgegebenen Ergebnisse 1 MB.
Nehmen wir als Beispiel eine Tabelle, in der die Größe jedes Element 300 Byte beträgt. Es gibt einen lokalen sekundären Index in dieser Tabelle, aber nur 200 Byte pro Element werden in den Index projiziert. Angenommen, Sie führen eine Query-Operation für diesen Index aus, die Abfrage erfordert Tabellenabrufe für jedes Element und die Abfrage gibt vier Elemente zurück. DynamoDB fasst Folgendes zusammen:
-
Die Größe der übereinstimmenden Elemente im Index: 200 Byte × 4 Elemente = 800 Byte. Dieser Wert wird dann auf 4 KB aufgerundet.
-
Die Größe der einzelnen übereinstimmenden Elemente in der Basistabelle: (300 Byte, auf 4 KB aufgerundet) × 4 Elemente = 16 KB.
Die Gesamtgröße der Daten im Ergebnis beträgt somit 20 KB.
Schreibkapazitätseinheiten
Wenn ein Element in einer Tabelle hinzugefügt, aktualisiert oder gelöscht wird, verbraucht die Aktualisierung der lokalen sekundären Indizes bereitgestellte Schreibkapazitätseinheiten für die Tabelle. Die gesamten bereitgestellten Durchsatzkosten für einen Schreibvorgang sind die Summe der Schreibkapazitätseinheiten, die durch das Schreiben in die Tabelle verbraucht werden, und denjenigen, die durch die Aktualisierung der lokalen sekundären Indizes verbraucht werden.
Die Kosten für das Schreiben eines Elements in einen lokalen Sekundärindex hängen von mehreren Faktoren ab:
-
Wenn Sie ein neues Element in die Tabelle schreiben, die ein indiziertes Attribut definiert, oder ein vorhandenes Element zum Definieren eines zuvor nicht definierten indizierten Attributs aktualisieren, ist ein Schreibvorgang erforderlich, um das Element in den Index einzufügen.
-
Wenn eine Aktualisierung der Tabelle den Wert eines indizierten Schlüsselattributs (von A in B) ändert, sind zwei Schreibvorgänge erforderlich, und zwar einer zum Löschen des vorherigen Elements aus dem Index und einer zum Schreiben des neuen Elements in den Index.
-
Wenn ein Element im Index vorhanden war, ein Schreibvorgang in der Tabelle jedoch dazu führte, dass das indizierte Attribut gelöscht wurde, ist ein Schreibvorgang erforderlich, um die alte Elementprojektion im Index zu löschen.
-
Wenn ein Element nicht im Index vorhanden ist, bevor oder nachdem das Element aktualisiert wird, fallen keine zusätzlichen Kosten für das Schreiben in den Index an.
Alle diese Faktoren setzen voraus, dass die Größe der einzelnen Elemente im Index kleiner oder gleich der 1-KB- Elementgröße für das Berechnen der Schreibkapazitätseinheiten ist. Größere Indexeinträge erfordern zusätzliche Schreibkapazitätseinheiten. Sie können Ihre Kosten für Schreibvorgänge minimieren, indem Sie überlegen, welche Attribute Ihre Abfragen zurückgeben müssen, und nur diese Attribute in den Index projizieren.
Speicherüberlegungen für lokale sekundäre Indizes
Wenn eine Anwendung ein Element in eine Tabelle schreibt, kopiert DynamoDB automatisch die richtige Teilmenge der Attribute in den lokalen sekundären Index, in dem diese Attribute angezeigt werden sollen. Ihr AWS Konto wird für die Speicherung des Elements in der Basistabelle und auch für die Speicherung von Attributen in allen lokalen Sekundärindizes dieser Tabelle belastet.
Der Speicherplatz, der von einem Indexelement belegt wird, ergibt sich aus der Summe von folgenden Werten:
-
Die Größe in Byte des Primärschlüssels der Basistabelle (Partitionsschlüssel und Sortierschlüssel)
-
Die Größe in Byte des Indexschlüsselattributs
-
Die Größe in Byte der projizierten Attribute (sofern vorhanden)
-
100 Bytes des Overheads pro Indexelement
Um den Speicherbedarf für einen lokalen sekundären Index zu schätzen, können Sie die durchschnittliche Größe eines Elements im Index schätzen und dann mit der Anzahl der Elemente im Index multiplizieren.
Wenn eine Tabelle ein Element enthält, in dem ein bestimmtes Attribut nicht definiert ist, dieses Attribut aber als Indexsortierschlüssel festgelegt ist, schreibt DynamoDB keine Daten für dieses Element in den Index.
Elementauflistungen in lokalen sekundären Indizes
Anmerkung
Dieser Abschnitt betrifft nur Tabellen mit lokalen sekundären Indizes.
In DynamoDB ist eine Elementsammlung eine beliebige Gruppe von Elementen, die denselben Partitionsschlüsselwert in einer Tabelle und allen ihren lokalen sekundären Indizes aufweisen. In den Beispielen in diesem Abschnitt lautet der Partitionsschlüssel für die Thread-Tabelle ForumName und der Partitionsschlüssel für LastPostIndex ist ebenfalls ForumName. Alle Tabellen- und Indexelemente mit demselben ForumName gehören zur selben Elementauflistung. In der Thread-Tabelle und dem LastPostIndex- ist beispielsweise eine Elementauflistung für das EC2-Forum und eine andere Elementauflistung für das RDS-Forum vorhanden.
Das folgende Diagramm zeigt die Elementauflistung für das S3-Forum:
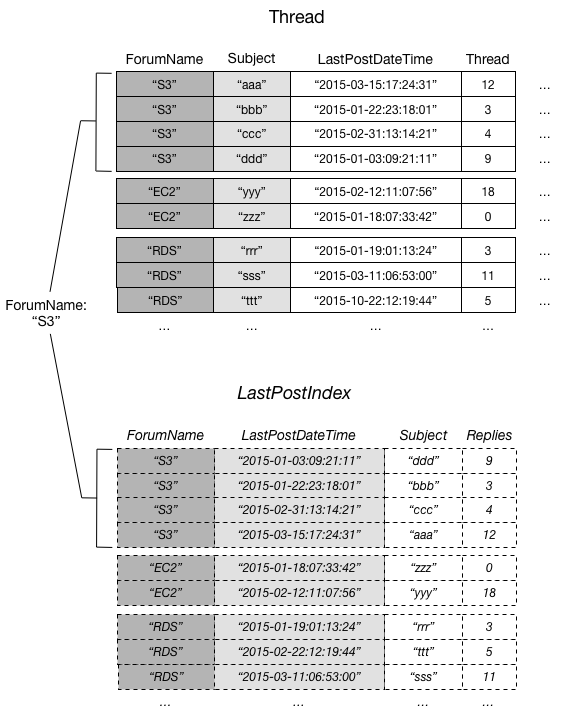
In diesem Diagramm enthält die Elementauflistung alle Elemente von Thread und LastPostIndex, wobei der Partitionsschlüsselwert ForumName „S3“ lautet. Wenn die Tabelle andere lokale sekundäre Indizes enthält, wären alle Elemente in diesen Indizes mit ForumName gleich „S3“ ebenfalls Teil der Elementsammlung.
Sie können eine der folgenden Operationen in DynamoDB verwenden, um Informationen zu Elementauflistungen zu erhalten:
-
BatchWriteItem -
DeleteItem -
PutItem -
UpdateItem -
TransactWriteItems
Jede dieser Operationen unterstützt den Parameter ReturnItemCollectionMetrics. Wenn Sie diesen Parameter auf SIZE festlegen, können Sie Informationen über die Größe der einzelnen Elementauflistung im Index anzeigen.
Beispiel
Nachfolgend finden Sie ein Beispiel aus der Ausgabe einer UpdateItem-Operation für die Thread-Tabelle, mit ReturnItemCollectionMetrics auf SIZE. Das Element, das aktualisiert wurde, hatte den ForumName „EC2“, sodass die Ausgabe Informationen über diese Elementauflistung enthält.
{ ItemCollectionMetrics: { ItemCollectionKey: { ForumName: "EC2" }, SizeEstimateRangeGB: [0.0, 1.0] } }
Das SizeEstimateRangeGB-Objekt zeigt, dass die Größe dieser Elementauflistung zwischen 0 und 1 GB beträgt. DynamoDB aktualisiert diese Größenschätzung in regelmäßigen Abständen, sodass die Zahlen bei der nächsten Änderung des Elements anders lauten können.
Größenlimit der Elementauflistung
Die maximale Größe einer Elementauflistung für eine Tabelle mit einem oder mehreren lokalen sekundären Indizes beträgt 10 GB. Dies gilt nicht für Elementauflistungen in Tabellen ohne lokale sekundäre Indizes und auch nicht für Elementauflistungen in globalen sekundären Indizes. Es sind nur Tabellen mit einem oder mehreren lokalen sekundären Indizes betroffen.
Wenn eine Artikelsammlung den Grenzwert von 10 GB überschreitet, gibt DynamoDB möglicherweise eine zurückItemCollectionSizeLimitExceededException, und Sie können der Artikelsammlung möglicherweise keine weiteren Artikel hinzufügen oder die Größe der Elemente in der Artikelsammlung erhöhen. (Lese- und Schreibvorgänge, die die Größe der Elementauflistung reduzieren, sind nach wie vor zulässig.) Sie können weiterhin Elemente zu anderen Elementauflistungen hinzufügen.
Um die Größe einer Elementauflistung zu reduzieren, können Sie einen der folgenden Schritte ausführen:
-
Löschen Sie alle unnötigen Elemente mit dem betreffenden Partitionsschlüsselwert. Wenn Sie diese Elemente aus der Basistabelle löschen, entfernt DynamoDB auch alle Indexeinträge, die denselben Partitionsschlüsselwert aufweisen.
-
Aktualisieren Sie die Elemente durch Entfernen von Attributen oder durch die Reduzierung der Größe der Attribute. Wenn diese Attribute in lokale sekundäre Indizes projiziert werden, reduziert DynamoDB auch die Größe der entsprechenden Indexeinträge.
-
Erstellen Sie eine neue Tabelle mit demselben Partitions- und Sortierschlüssel und verschieben Sie die Elemente von der alten in die neue Tabelle. Dies ist ein guter Ansatz, wenn eine Tabelle über historische Daten verfügt, auf die selten zugegriffen wird. Sie können auch in Betracht ziehen, diese historischen Daten in Amazon Simple Storage Service (Amazon S3) zu archivieren.
Wenn die Gesamtgröße der Elementsammlung unter 10 GB sinkt, können Sie erneut Elemente mit demselben Partitionsschlüsselwert hinzufügen.
Wir empfehlen als bewährte Methode, Ihre Anwendung zu instrumentieren, um die Größe Ihrer Elementauflistungen zu überwachen. Eine Möglichkeit dazu ist, den Parameter ReturnItemCollectionMetrics auf SIZE festzulegen, sobald Sie BatchWriteItem, DeleteItem, PutItem oder UpdateItem. verwenden. Ihre Anwendung sollte das ReturnItemCollectionMetrics-Objekt in der Ausgabe untersuchen und eine Fehlermeldung protokollieren, wenn eine Elementauflistung einen benutzerdefinierten Grenzwert (z. B. 8 GB) überschreitet. Wenn Sie einen geringeren Wert als 10 GB als Limit festlegen, ist dies ein Frühwarnsystem, da Sie so rechtzeitig erfahren, dass sich eine Elementauflistung dem Limit nähert, und entsprechende Maßnahmen ergreifen können.
Elementauflistungen und Partitionen
In einer Tabelle mit einem oder mehreren lokalen sekundären Indizes wird jede Elementauflistung in einer Partition gespeichert. Die Gesamtgröße einer solchen Elementauflistung ist auf die Kapazität dieser Partition beschränkt: 10 GB. Für eine Anwendung, bei der das Datenmodell Elementauflistungen enthält, deren Größe unbegrenzt ist oder bei denen Sie vernünftigerweise davon ausgehen können, dass einige Elementauflistungen in Zukunft auf mehr als 10 GB anwachsen werden, sollten Sie stattdessen einen globalen sekundären Index verwenden.
Sie sollten Ihre Anwendungen so konzipieren, dass Tabellendaten gleichmäßig auf unterschiedliche Partitionsschlüsselwerte verteilt werden. Für Tabellen mit lokalen sekundären Indizes sollten Ihre Anwendungen keine „Hotspots“ für Lese- und Schreibaktivitäten innerhalb einer einzigen Elementauflistung in einer einzelnen Partition erstellen.
