Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Verwenden globaler sekundärer Indizes für materialisierte Aggregationsabfragen in DynamoDB
Die Wartung von Aggregationen, die beinahe in Echtzeit ausgeführt werden, und Schlüsselmetriken für Daten, die sich schnell verändern, wird zunehmend wichtiger für Unternehmen, um schnell Entscheidungen treffen zu können. Beispielsweise möchte eine Musikbibliothek ihre am häufigsten heruntergeladenen Songs nahezu in Echtzeit präsentieren, oder eine E-Commerce-Plattform muss möglicherweise Trendprodukte nach Kategorien anzeigen.
Da DynamoDB keine systemeigenen Aggregationsoperationen wie SUM oder COUNT elementübergreifend unterstützt, würde die Berechnung dieser Werte beim Lesen das Scannen einer großen Anzahl von Elementen erfordern — was langsam und teuer sein kann. Stattdessen können Sie Aggregationen vorab berechnen, wenn sich Daten ändern, und die Ergebnisse als reguläre Elemente in Ihrer Tabelle speichern. Dieses Muster wird als materialisierte Aggregation bezeichnet.
Themen
Beispielszenario und Zugriffsmuster
Stellen Sie sich eine Musikbibliotheksanwendung mit den folgenden Anforderungen vor:
Die Anwendung zeichnet einzelne Lied-Downloads mit hoher Lautstärke (Tausende pro Sekunde) auf.
Benutzer müssen die am häufigsten heruntergeladenen Songs für einen bestimmten Monat mit einer Latenz im einstelligen Millisekundenbereich sehen.
Die Anwendung muss auch Abfragen wie „Die 10 besten Songs dieses Monats“ und „Alle Songs, die in einem bestimmten Monat heruntergeladen wurden“ unterstützen.
Bei dieser Größenordnung kann es teuer sein, die Anzahl der Downloads zum Zeitpunkt des Lesens zu berechnen, indem alle Download-Datensätze gescannt werden. Stattdessen können Sie eine fortlaufende Zählung beibehalten, die bei jedem Download aktualisiert wird, und diese so speichern, dass effiziente Abfragen unterstützt werden.
Warum Aggregationen vorab berechnen
Es gibt verschiedene Ansätze zur Berechnung von Aggregationen. In der folgenden Tabelle werden gängige Alternativen verglichen und erklärt, warum die materialisierte Aggregation in DynamoDB für diese Art von Anwendungsfall oft am besten geeignet ist.
| Ansatz | Kompromisse | Wann sollte dies verwendet werden? |
|---|---|---|
| Zum Zeitpunkt des Lesens scannen und zählen | Erfordert das Lesen aller Download-Datensätze für jede Abfrage. Die Latenz wächst mit dem Datenvolumen und verbraucht erhebliche Lesekapazität. | Nur für sehr kleine Datensätze geeignet, bei denen die Latenz kein Problem darstellt. |
| Externer Aggregationsspeicher (z. B. Amazon ElastiCache) | Erhöht die betriebliche Komplexität durch einen separaten Service, der verwaltet werden muss. Erfordert Synchronisationslogik zwischen DynamoDB und dem Cache. | Wenn Sie Lesevorgänge unter einer Millisekunde oder eine komplexe Aggregationslogik benötigen, die über einfache Zählungen hinausgeht. |
| Application-level Aggregation beim Schreiben | Koppelt die Aggregationslogik an den Schreibpfad. Wenn die Anwendung nach der Aufzeichnung des Downloads, aber vor der Aktualisierung der Anzahl fehlschlägt, wird die Aggregation inkonsistent. | Wenn Sie eine synchrone, stark konsistente Aggregation benötigen und zusätzliche Schreiblatenz tolerieren können. |
| Materialisierte Aggregation mit Streams und Lambda | Entkoppelt die Aggregation vom Schreibpfad. Die Aggregation ist letztendlich konsistent (in der Regel Sekunden später). Fügt Lambda-Aufrufkosten hinzu. | Wenn Sie Aggregationen nahezu in Echtzeit mit geringer Leselatenz benötigen und eine eventuelle Konsistenz tolerieren können. Dieser Ansatz wird auf dieser Seite beschrieben. |
Der Ansatz der materialisierten Aggregation hält den Schreibpfad einfach (zeichnet einfach den Download auf), verlagert die Aggregation in einen asynchronen Prozess und speichert das Ergebnis in DynamoDB, wo es mit einer Latenz im einstelligen Millisekundenbereich abgefragt werden kann.
Tabellendesign
Dieser Entwurf verwendet eine einzelne Tabelle mit zwei Elementtypen, die denselben Partitionsschlüssel () verwenden, aber unterschiedliche Sortierschlüsselmuster verwenden, um zwischen ihnen zu unterscheiden: songID
Datensätze herunterladen — Einzelne Download-Ereignisse. Der Sortierschlüssel ist der
DownloadID(eine eindeutige Kennung für jeden Download).Monatliche Aggregationselemente — Anzahl der Pre-computed Downloads pro Song pro Monat. Der Sortierschlüssel gibt das
YYYY-MMFormat des Monats an (z. B.2018-01). Diese Elemente enthalten auch einDownloadCountAttribut mit der laufenden Summe.
Nur die monatlichen Aggregationselemente enthalten das Month Attribut. Diese Unterscheidung ist wichtig für das später beschriebene, spärliche GSI-Design.
Das folgende Diagramm zeigt das Tabellenlayout mit beiden Elementtypen:
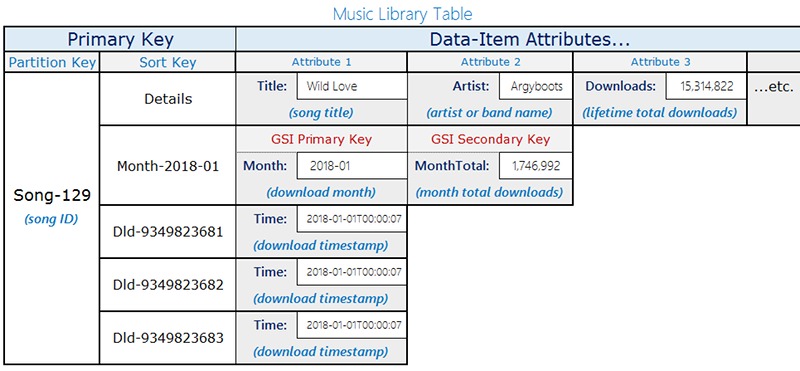
| Elementart | Partitionsschlüssel (SongID) | Sortierschlüssel | Zusätzliche Attribute |
|---|---|---|---|
| Datensatz herunterladen | song1 |
download-abc123 |
UserID, Timestamp |
| Monatliche Aggregation | song1 |
2018-01 |
Month=2018-01,
DownloadCount=1,746,992 |
Aggregationspipeline mit Streams und AWS Lambda
Die Aggregationspipeline funktioniert wie folgt:
Wenn ein Song heruntergeladen wird, schreibt die Anwendung mit
Partition-Key=songIDundSort-Key=DownloadIDein neues Element in die Tabelle.DynamoDB Streams erfasst diesen Schreibvorgang als Stream-Record.
Eine Lambda-Funktion, die an den Stream angehängt ist, verarbeitet den neuen Datensatz. Sie identifiziert den
songIDund den aktuellen Monat und aktualisiert dann das entsprechende monatliche Aggregationselement, indem das Attribut inkrementiert wird.DownloadCountDas aktualisierte Aggregationselement ist dann für Abfragen über den globalen Index mit geringer Dichte verfügbar.
Die Lambda-Funktion verwendet einen UpdateItem Aufruf mit einem ADD Ausdruck, um die Anzahl der Downloads atomar zu erhöhen. Dadurch werden Wettlaufbedingungen beim Lesen, Ändern und Schreiben vermieden:
import boto3 dynamodb = boto3.resource('dynamodb') table = dynamodb.Table('MusicLibrary') def handler(event, context): for record in event['Records']: if record['eventName'] == 'INSERT': new_image = record['dynamodb']['NewImage'] song_id = new_image['songID']['S'] # Derive the month from the download timestamp timestamp = new_image['Timestamp']['S'] month = timestamp[:7] # Extract YYYY-MM table.update_item( Key={ 'songID': song_id, 'SK': month }, UpdateExpression='ADD DownloadCount :inc SET #m = :month', ExpressionAttributeNames={ '#m': 'Month' }, ExpressionAttributeValues={ ':inc': 1, ':month': month } )
Anmerkung
Wenn eine Lambda-Ausführung nach dem Schreiben des aktualisierten Aggregationswerts fehlschlägt, kann der Stream-Datensatz erneut versucht werden. Da der ADD Vorgang die Anzahl bei jeder Ausführung erhöht, würde ein erneuter Versuch die Anzahl für denselben Download mehrmals erhöhen, sodass Sie einen ungefähren Wert erhalten. Für die meisten Anwendungsfälle in den Bereichen Analytik und Bestenlisten ist diese geringe Fehlerquote akzeptabel. Wenn Sie genaue Zahlen benötigen, sollten Sie erwägen, eine Idempotenzlogik hinzuzufügen, z. B. indem Sie einen Bedingungsausdruck verwenden, der überprüft, ob die spezifische Zahl bereits verarbeitet wurde. DownloadID
Sparsamer GSI-Entwurf
Um die aggregierten Ergebnisse effizient abzufragen, erstellen Sie einen globalen sekundären Index mit dem folgenden Schlüsselschema:
GSI-Partitionsschlüssel:
Month(Zeichenfolge)GSI-Sortierschlüssel:
DownloadCount(Zahl)
Dieser globale Index ist spärlich, da nur die monatlichen Aggregationselemente das Attribut enthalten. Month Die einzelnen Download-Datensätze haben dieses Attribut nicht und werden daher automatisch aus dem Index ausgeschlossen. Das bedeutet, dass der globale Index nur die vorberechneten Aggregationselemente enthält — einen kleinen Teil der gesamten Elemente in der Tabelle.
Ein spärlicher globaler Index bietet zwei wichtige Vorteile:
Niedrigere Kosten — Da nur Aggregationselemente in den Index repliziert werden, verbrauchen Sie im Vergleich zu einem Index, der jedes Element in der Tabelle umfasst, deutlich weniger Schreibkapazität und Speicherplatz.
Schnellere Abfragen — Der Index enthält nur die Daten, die Sie abfragen müssen, sodass Lesevorgänge effizient sind und Ergebnisse mit einer Latenz im einstelligen Millisekundenbereich zurückgegeben werden.
Weitere Hinweise zur Funktionsweise von Indizes mit geringer Dichte finden Sie unter. Verwendung von Sparse Indexes
Den GSI abfragen
Wenn der globale Index mit geringer Dichte eingerichtet ist, können Sie verschiedene Arten von Abfragen effizient beantworten:
Holen Sie sich den Song, der in einem bestimmten Monat am häufigsten heruntergeladen wurde:
aws dynamodb query \ --table-name "MusicLibrary" \ --index-name "MonthDownloadsIndex" \ --key-condition-expression "#m = :month" \ --expression-attribute-names '{"#m": "Month"}' \ --expression-attribute-values '{":month": {"S": "2018-01"}}' \ --scan-index-forward false \ --limit 1
Bei Einstellung ScanIndexForward auf werden die Ergebnisse DownloadCount in absteigender Reihenfolge false sortiert und es wird nur der Titel Limit=1 zurückgegeben, der am häufigsten gespielt wird.
Ruft die 10 besten Songs für einen bestimmten Monat ab:
aws dynamodb query \ --table-name "MusicLibrary" \ --index-name "MonthDownloadsIndex" \ --key-condition-expression "#m = :month" \ --expression-attribute-names '{"#m": "Month"}' \ --expression-attribute-values '{":month": {"S": "2018-01"}}' \ --scan-index-forward false \ --limit 10
Erhalte alle Songs, die in einem bestimmten Monat heruntergeladen wurden (sortiert nach Anzahl der Downloads):
aws dynamodb query \ --table-name "MusicLibrary" \ --index-name "MonthDownloadsIndex" \ --key-condition-expression "#m = :month" \ --expression-attribute-names '{"#m": "Month"}' \ --expression-attribute-values '{":month": {"S": "2018-01"}}' \ --scan-index-forward false
Überlegungen
Beachten Sie bei der Implementierung dieses Musters Folgendes:
Eventuelle Konsistenz — Die Aggregationswerte werden asynchron über DynamoDB Streams und Lambda aktualisiert. Zwischen der Aufzeichnung eines Downloads und der Aktualisierung der Aggregation liegt in der Regel eine Verzögerung von einigen Sekunden. Das bedeutet, dass der GSI Daten nahezu in Echtzeit wiedergibt, keine Echtzeitdaten.
Lambda-Parallelität — Wenn Ihre Tabelle ein hohes Schreibvolumen hat, können mehrere Lambda-Aufrufe versuchen, dasselbe Aggregationselement gleichzeitig zu aktualisieren. Die atomare
ADDOperation handhabt dies sicher, aber Sie sollten die Lambda-Parallelität und die Drosselungsmetriken überwachen, um sicherzustellen, dass Ihre Funktion mit dem Stream Schritt halten kann.GSI-Schreibkapazität — Da die dünn besetzte GSI nur Aggregationselemente enthält, benötigt sie deutlich weniger Schreibkapazität als die Basistabelle. Sie sollten jedoch dennoch genügend Kapazität bereitstellen (oder den On-Demand-Modus verwenden), um die Geschwindigkeit der Aggregationsaktualisierungen bewältigen zu können.
Ungefähre Anzahl — Wie bereits erwähnt, können Lambda-Wiederholungen dazu führen, dass die Anzahl leicht überzählt wird. Implementieren Sie für Anwendungsfälle, die genaue Zählungen erfordern, Idempotenzprüfungen in der Lambda-Funktion.
