Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Datenquellen
Im vorherigen Abschnitt haben wir gelernt, dass ein Schema die Form Ihrer Daten definiert. Wir haben jedoch nie erklärt, woher diese Daten stammen. In echten Projekten ist Ihr Schema wie ein Gateway, das alle Anfragen an den Server verarbeitet. Wenn eine Anfrage gestellt wird, fungiert das Schema als einziger Endpunkt, der mit dem Client verbunden ist. Das Schema greift auf Daten aus der Datenquelle zu, verarbeitet sie und leitet sie zurück an den Client weiter. Sehen Sie sich die folgende Infografik an:
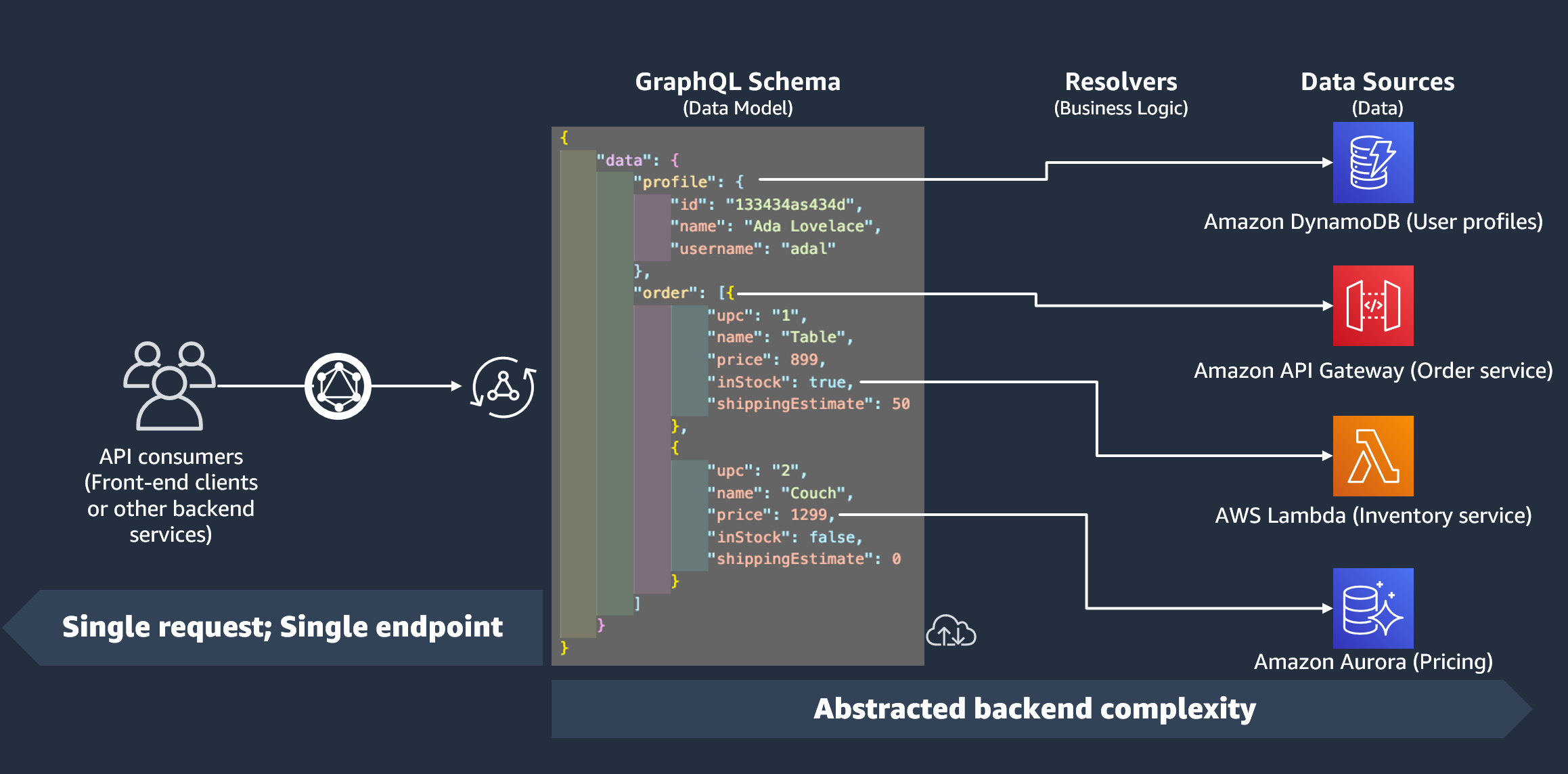
AWS AppSync und GraphQL implementieren hervorragend Backend For Frontend (BFF) -Lösungen. Sie arbeiten zusammen, um die Komplexität skalierbar zu reduzieren, indem sie das Backend abstrahieren. Wenn Ihr Service unterschiedliche Datenquellen und/oder Microservices verwendet, können Sie im Wesentlichen einen Teil der Komplexität abstrahieren, indem Sie die Form der Daten jeder Quelle (Untergraph) in einem einzigen Schema (Supergraph) definieren. Das bedeutet, dass Ihre GraphQL-API nicht auf die Verwendung einer Datenquelle beschränkt ist. Sie können Ihrer GraphQL-API eine beliebige Anzahl von Datenquellen zuordnen und in Ihrem Code angeben, wie sie mit dem Dienst interagieren sollen.
Wie Sie in der Infografik sehen können, enthält das GraphQL-Schema alle Informationen, die Clients benötigen, um Daten anzufordern. Das bedeutet, dass alles in einer einzigen Anfrage verarbeitet werden kann und nicht in mehreren Anfragen, wie es bei REST der Fall ist. Diese Anfragen durchlaufen das Schema, das der einzige Endpunkt des Dienstes ist. Wenn Anfragen verarbeitet werden, führt ein Resolver (im nächsten Abschnitt erklärt) seinen Code aus, um die Daten aus der entsprechenden Datenquelle zu verarbeiten. Wenn die Antwort zurückgegeben wird, wird der mit der Datenquelle verknüpfte Untergraph mit den Daten im Schema gefüllt.
AWS AppSync unterstützt viele verschiedene Datenquellentypen. In der folgenden Tabelle werden wir jeden Typ beschreiben, einige der Vorteile der einzelnen Typen auflisten und nützliche Links für zusätzlichen Kontext bereitstellen.
| Datenquelle | Description | Vorteile | Zusätzliche Informationen |
|---|---|---|---|
| Amazon DynamoDB | „Amazon DynamoDB ist ein vollständig verwalteter NoSQL-Datenbankservice, der schnelle und vorhersehbare Leistung mit nahtloser Skalierbarkeit bietet. Mit DynamoDB können Sie den Verwaltungsaufwand für den Betrieb und die Skalierung verteilter Datenbanken verringern, sodass Sie sich nicht um Hardwarebereitstellung, Einrichtung und Konfiguration, Replikation, Software-Patching oder Cluster-Skalierung kümmern müssen. DynamoDB bietet auch Verschlüsselung im Ruhezustand, wodurch der betriebliche Aufwand und die Komplexität, die mit dem Schutz sensibler Daten verbunden sind, entfallen.“ |
|
|
| AWS Lambda | "AWS Lambda ist ein Rechendienst, mit dem Sie Code ausführen können, ohne Server bereitstellen oder verwalten zu müssen. Lambda führt Ihren Code auf einer hochverfügbaren Recheninfrastruktur aus und führt die gesamte Verwaltung der Rechenressourcen durch, einschließlich Server- und Betriebssystemwartung, Kapazitätsbereitstellung und automatischer Skalierung sowie Protokollierung. Mit Lambda müssen Sie lediglich Ihren Code in einer der von Lambda unterstützten Sprachlaufzeiten bereitstellen.“ |
|
|
| OpenSearch | „Amazon OpenSearch Service ist ein verwalteter Service, der es einfach macht, OpenSearch Cluster in der AWS Cloud bereitzustellen, zu betreiben und zu skalieren. Amazon OpenSearch Service unterstützt OpenSearch ältere Elasticsearch-Betriebssysteme (bis zu 7.10, die endgültige Open-Source-Version der Software). Wenn Sie einen Cluster erstellen, haben Sie die Option, die Suchmaschine zu verwenden. OpenSearchist eine vollständig quelloffene Such- und Analyse-Engine für Anwendungsfälle wie Protokollanalysen, Anwendungsüberwachung in Echtzeit und Clickstream-Analyse. Weitere Informationen finden Sie in der OpenSearch-Dokumentation Amazon OpenSearch Service stellt alle Ressourcen für Ihren OpenSearch Cluster bereit und startet ihn. Außerdem werden ausgefallene OpenSearch Serviceknoten automatisch erkannt und ersetzt, wodurch der mit selbstverwalteten Infrastrukturen verbundene Aufwand reduziert wird. Sie können Ihren Cluster mit einem einzigen API-Aufruf oder mit ein paar Klicks in der Konsole skalieren.“ |
|
|
| HTTP-Endpunkte | Sie können HTTP-Endpunkte als Datenquellen verwenden. AWS AppSync kann Anfragen mit den relevanten Informationen wie Parametern und Nutzdaten an die Endpunkte senden. Die HTTP-Antwort wird dem Resolver zugänglich gemacht, der die endgültige Antwort zurückgibt, nachdem er seine Operation (en) abgeschlossen hat. |
|
|
| Amazon EventBridge | "EventBridge ist ein serverloser Service, der Ereignisse verwendet, um Anwendungskomponenten miteinander zu verbinden, sodass Sie leichter skalierbare, ereignisgesteuerte Anwendungen erstellen können. Verwenden Sie ihn, um Ereignisse aus Quellen wie selbst entwickelten Anwendungen, AWS Diensten und Software von Drittanbietern an Verbraucheranwendungen in Ihrem Unternehmen weiterzuleiten. EventBridge bietet eine einfache und konsistente Methode zum Erfassen, Filtern, Transformieren und Bereitstellen von Ereignissen, sodass Sie schnell neue Anwendungen erstellen können.“ |
|
|
| Relationale Datenbanken | „Amazon Relational Database Service (Amazon RDS) ist ein Webservice, der die Einrichtung, den Betrieb und die Skalierung einer relationalen Datenbank in der AWS Cloud erleichtert. Er bietet kosteneffiziente, anpassbare Kapazität für eine relationale Datenbank nach Industriestandard und verwaltet allgemeine Datenbankverwaltungsaufgaben.“ |
|
|
| Keine Datenquelle | Wenn Sie nicht vorhaben, einen Datenquellendienst zu verwenden, können Sie ihn auf einstellennone. Eine none Datenquelle ist zwar immer noch explizit als Datenquelle kategorisiert, aber kein Speichermedium. Trotzdem ist es in bestimmten Fällen immer noch nützlich, um Daten zu manipulieren und weiterzuleiten. |
|
Tipp
Weitere Informationen zur Interaktion zwischen Datenquellen finden Sie AWS AppSync unter Anhängen einer Datenquelle.
