Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Resolver
In den vorherigen Abschnitten haben Sie sich mit den Komponenten des Schemas und der Datenquelle vertraut gemacht. Jetzt müssen wir uns damit befassen, wie das Schema und die Datenquellen interagieren. Alles beginnt mit dem Resolver.
Ein Resolver ist eine Codeeinheit, die regelt, wie die Daten dieses Felds aufgelöst werden, wenn eine Anfrage an den Dienst gestellt wird. Resolver sind an bestimmte Felder innerhalb Ihrer Typen in Ihrem Schema angehängt. Sie werden am häufigsten verwendet, um die Zustandsänderungsoperationen für Ihre Abfrage-, Mutations- und Abonnement-Feldoperationen zu implementieren. Der Resolver verarbeitet die Anfrage eines Clients und gibt dann das Ergebnis zurück. Dabei kann es sich um eine Gruppe von Ausgabetypen wie Objekten oder Skalaren handeln:
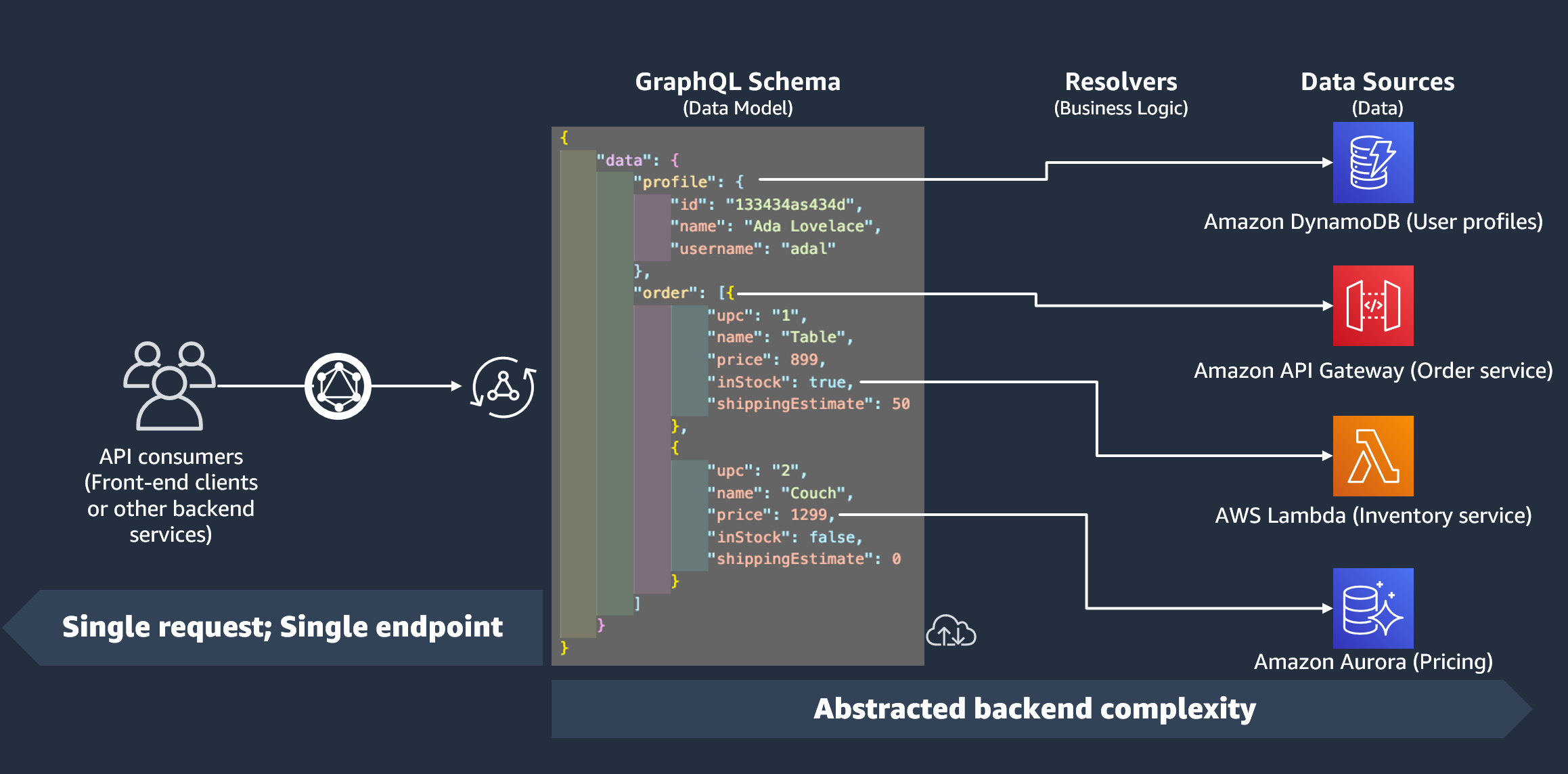
Laufzeit des Resolvers
AWS AppSync In müssen Sie zunächst eine Laufzeit für Ihren Resolver angeben. Eine Resolver-Runtime gibt die Umgebung an, in der ein Resolver ausgeführt wird. Sie bestimmt auch die Sprache, in der Ihre Resolver geschrieben werden. AWS AppSync unterstützt derzeit APPSYNC_JS für JavaScript und Velocity Template Language (VTL). Weitere Informationen finden Sie unter JavaScript Laufzeitfunktionen für Resolver und Funktionen für JavaScript oder Referenz zum Resolver Mapping Template Utility für VTL.
Resolver-Struktur
Was den Code angeht, können Resolver auf verschiedene Arten strukturiert werden. Es gibt Unit - und Pipeline-Resolver.
Resolver für Einheiten
Ein Unit-Resolver besteht aus Code, der einen einzelnen Anforderungs- und Antworthandler definiert, die für eine Datenquelle ausgeführt werden. Der Anforderungshandler verwendet ein Kontextobjekt als Argument und gibt die Anforderungsnutzdaten zurück, die zum Aufrufen Ihrer Datenquelle verwendet wurden. Der Antworthandler erhält von der Datenquelle eine Nutzlast mit dem Ergebnis der ausgeführten Anfrage zurück. Der Response-Handler wandelt die Nutzlast in eine GraphQL-Antwort um, um das GraphQL-Feld aufzulösen.
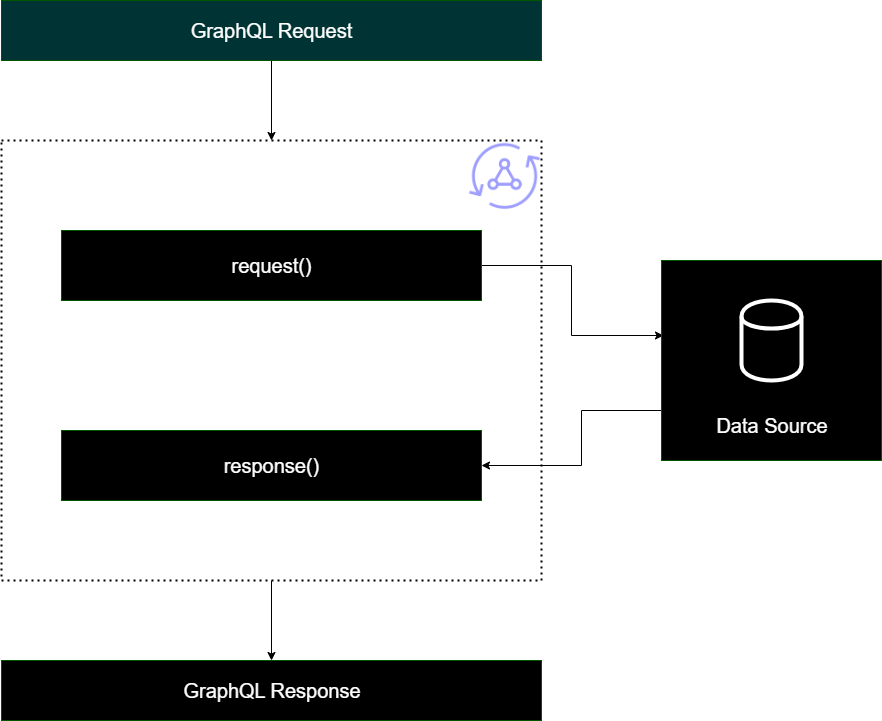
Pipeline-Resolver
Bei der Implementierung von Pipeline-Resolvern gibt es eine allgemeine Struktur, der sie folgen:
-
Schritt vor dem: Wenn eine Anfrage vom Client gestellt wird, werden den Resolvern für die verwendeten Schemafelder (normalerweise Ihre Abfragen, Mutationen, Abonnements) die Anforderungsdaten übergeben. Der Resolver beginnt mit der Verarbeitung der Anforderungsdaten mit einem Before-Step-Handler, der es ermöglicht, einige Vorverarbeitungsvorgänge durchzuführen, bevor die Daten den Resolver passieren.
-
Funktion (en): Nachdem der vorherige Schritt ausgeführt wurde, wird die Anforderung an die Funktionsliste übergeben. Die erste Funktion in der Liste wird für die Datenquelle ausgeführt. Eine Funktion ist eine Teilmenge des Codes Ihres Resolvers, die einen eigenen Anfrage- und Antworthandler enthält. Ein Request-Handler nimmt die Anforderungsdaten und führt Operationen an der Datenquelle durch. Der Antworthandler verarbeitet die Antwort der Datenquelle, bevor er sie an die Liste zurückgibt. Wenn es mehr als eine Funktion gibt, werden die Anforderungsdaten zur Ausführung an die nächste Funktion in der Liste gesendet. Die Funktionen in der Liste werden seriell in der vom Entwickler festgelegten Reihenfolge ausgeführt. Sobald alle Funktionen ausgeführt wurden, wird das Endergebnis an den nächsten Schritt übergeben.
-
Nach dem Schritt: Der Nachschritt ist eine Handler-Funktion, mit der Sie einige letzte Operationen an der Antwort der endgültigen Funktion ausführen können, bevor Sie sie an die GraphQL-Antwort übergeben.
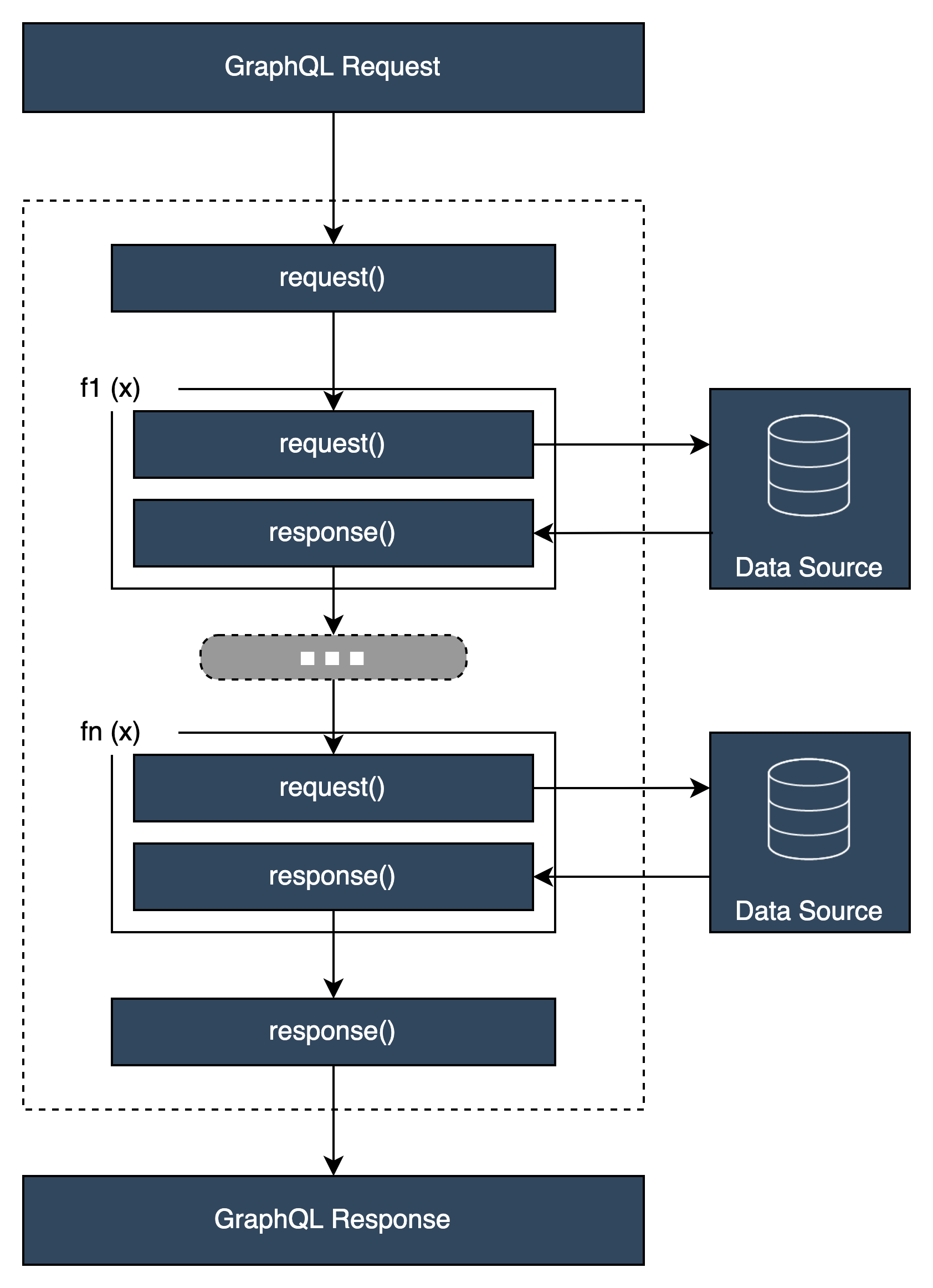
Struktur des Resolver-Handlers
Handler sind normalerweise Funktionen, die aufgerufen Request werden und: Response
export function request(ctx) { // Code goes here } export function response(ctx) { // Code goes here }
In einem Unit-Resolver wird es nur einen Satz dieser Funktionen geben. In einem Pipeline-Resolver wird es einen Satz dieser Funktionen für den Vorher-Nachher-Schritt und einen zusätzlichen Satz pro Funktion geben. Um zu veranschaulichen, wie das aussehen könnte, schauen wir uns einen einfachen Query Typ an:
type Query { helloWorld: String! }
Dies ist eine einfache Abfrage mit einem Feld namens helloWorld TypString. Nehmen wir an, wir möchten immer, dass dieses Feld die Zeichenfolge „Hello World“ zurückgibt. Um dieses Verhalten zu implementieren, müssen wir den Resolver zu diesem Feld hinzufügen. In einem Unit-Resolver könnten wir so etwas hinzufügen:
export function request(ctx) { return {} } export function response(ctx) { return "Hello World" }
Das request kann einfach leer gelassen werden, weil wir keine Daten anfordern oder verarbeiten. Wir können auch davon ausgehen, dass unsere Datenquelle dies istNone, was bedeutet, dass dieser Code keine Aufrufe ausführen muss. Die Antwort gibt einfach „Hello World“ zurück. Um diesen Resolver zu testen, müssen wir eine Anfrage mit dem Abfragetyp stellen:
query helloWorldTest { helloWorld }
Dies ist eine Abfrage namenshelloWorldTest, die das helloWorld Feld zurückgibt. Wenn er ausgeführt wird, führt der helloWorld Field Resolver auch die folgende Antwort aus und gibt sie zurück:
{ "data": { "helloWorld": "Hello World" } }
Konstanten wie diese zurückzugeben, ist das Einfachste, was Sie tun können. In Wirklichkeit werden Sie Eingaben, Listen und mehr zurückgeben. Hier ist ein komplizierteres Beispiel:
type Book { id: ID! title: String } type Query { getBooks: [Book] }
Hier geben wir eine Liste von zurückBooks. Nehmen wir an, wir verwenden eine DynamoDB-Tabelle zum Speichern von Buchdaten. Unsere Handler könnten so aussehen:
/** * Performs a scan on the dynamodb data source */ export function request(ctx) { return { operation: 'Scan' }; } /** * return a list of scanned post items */ export function response(ctx) { return ctx.result.items; }
Unsere Anfrage verwendete einen integrierten Scanvorgang, um nach allen Einträgen in der Tabelle zu suchen, speicherte die Ergebnisse im Kontext und übergab sie dann an die Antwort. In der Antwort wurden die Ergebniselemente übernommen und in der Antwort zurückgegeben:
{ "data": { "getBooks": { "items": [ { "id": "abcdefgh-1234-1234-1234-abcdefghijkl", "title": "book1" }, { "id": "aaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee", "title": "book2" }, ... ] } } }
Resolver-Kontext
In einem Resolver muss jeder Schritt in der Kette von Handlern den Status der Daten aus den vorherigen Schritten kennen. Das Ergebnis eines Handlers kann gespeichert und als Argument an einen anderen übergeben werden. GraphQL definiert vier grundlegende Resolver-Argumente:
| Resolver-Basisargumente | Description |
|---|---|
obj, root, parent, usw. |
Das Ergebnis des übergeordneten Elements. |
args |
Die Argumente, die dem Feld in der GraphQL-Abfrage zur Verfügung gestellt werden. |
context |
Ein Wert, der jedem Resolver zur Verfügung gestellt wird und wichtige Kontextinformationen wie den aktuell angemeldeten Benutzer oder den Zugriff auf eine Datenbank enthält. |
info |
Ein Wert, der feldspezifische Informationen enthält, die für die aktuelle Abfrage relevant sind, sowie die Schemadetails. |
AWS AppSync In kann das Argument context (ctx) alle oben genannten Daten enthalten. Es ist ein Objekt, das pro Anfrage erstellt wird und Daten wie Autorisierungsdaten, Ergebnisdaten, Fehler, Anforderungsmetadaten usw. enthält. Der Kontext ist eine einfache Möglichkeit für Programmierer, Daten zu manipulieren, die aus anderen Teilen der Anfrage stammen. Nimm diesen Ausschnitt noch einmal:
/** * Performs a scan on the dynamodb data source */ export function request(ctx) { return { operation: 'Scan' }; } /** * return a list of scanned post items */ export function response(ctx) { return ctx.result.items; }
Der Anfrage wird der Kontext (ctx) als Argument übergeben; dies ist der Status der Anfrage. Sie führt einen Scan für alle Elemente in einer Tabelle durch und speichert das Ergebnis anschließend wieder im result Kontext unter. Der Kontext wird dann an das Antwortargument übergeben, das auf den zugreift result und seinen Inhalt zurückgibt.
Anfragen und Analyse
Wenn Sie eine Abfrage an Ihren GraphQL-Dienst stellen, muss dieser vor der Ausführung einen Parsing- und Validierungsprozess durchlaufen. Ihre Anfrage wird analysiert und in einen abstrakten Syntaxbaum übersetzt. Der Inhalt des Baums wird validiert, indem mehrere Validierungsalgorithmen anhand Ihres Schemas ausgeführt werden. Nach dem Validierungsschritt werden die Knoten des Baums durchsucht und verarbeitet. Resolver werden aufgerufen, die Ergebnisse werden im Kontext gespeichert und die Antwort wird zurückgegeben. Betrachten Sie beispielsweise diese Abfrage:
query { Person { //object type name //scalar age //scalar } }
Wir kehren Person mit den Feldern A name und age zurück. Wenn Sie diese Abfrage ausführen, sieht der Baum ungefähr so aus:
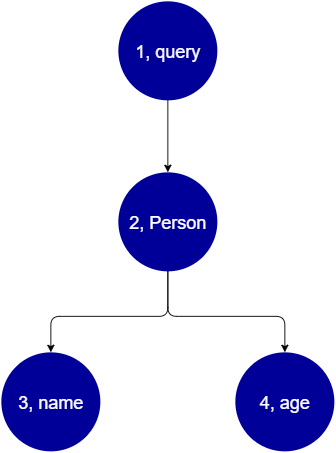
Aus der Baumstruktur geht hervor, dass mit dieser Anfrage der Stamm nach dem Query im Schema gesucht wird. Innerhalb der Abfrage wird das Person Feld aufgelöst. Aus früheren Beispielen wissen wir, dass dies eine Eingabe des Benutzers sein könnte, eine Werteliste usw., die höchstwahrscheinlich an einen Objekttyp gebunden Person ist, der die Felder enthält, die wir benötigen (nameundage). Sobald diese beiden untergeordneten Felder gefunden wurden, werden sie in der angegebenen Reihenfolge (namegefolgt vonage) aufgelöst. Sobald der Baum vollständig aufgelöst ist, ist die Anfrage abgeschlossen und wird an den Client zurückgesendet.
