Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
AWS AppSync Übersicht über die Resolver-Mapping-Vorlage
Anmerkung
Wir unterstützen jetzt hauptsächlich die APPSYNC_JS-Laufzeit und ihre Dokumentation. Bitte erwägen Sie, die APPSYNC_JS-Laufzeit und ihre Anleitungen hier zu verwenden.
AWS AppSync ermöglicht es Ihnen, auf GraphQL-Anfragen zu antworten, indem Sie Operationen an Ihren Ressourcen ausführen. Für jedes GraphQL-Feld, für das Sie eine Abfrage oder Mutation ausführen möchten, muss ein Resolver angehängt werden, um mit einer Datenquelle zu kommunizieren. Die Kommunikation erfolgt in der Regel über Parameter oder Operationen, die für die Datenquelle einzigartig sind.
Resolver sind die Verbindungen zwischen GraphQL und einer Datenquelle. Sie erklären, AWS AppSync wie Sie eine eingehende GraphQL-Anfrage in Anweisungen für Ihre Backend-Datenquelle übersetzen und wie Sie die Antwort von dieser Datenquelle zurück in eine GraphQL-Antwort übersetzen. Sie sind in der Apache Velocity Template Language (VTL)
Es gibt zwei Arten von Resolvern, die Mapping-Vorlagen auf AWS AppSync leicht unterschiedliche Weise nutzen:
-
Resolver für Einheiten
-
Pipeline-Resolver
Resolver für Einheiten
Unit-Resolver sind eigenständige Einheiten, die nur eine Anfrage- und Antwortvorlage enthalten. Verwenden Sie diese für einfache, einzelne Operationen, wie das Auflisten von Elementen aus einer einzelnen Datenquelle.
-
Vorlagen anfordern: Nehmen Sie die eingehende Anfrage, nachdem ein GraphQL-Vorgang analysiert wurde, und konvertieren Sie sie in eine Anforderungskonfiguration für den ausgewählten Datenquellenvorgang.
-
Antwortvorlagen: Interpretieren Sie Antworten aus Ihrer Datenquelle und ordnen Sie sie der Form des GraphQL-Feldausgabetyps zu.
Pipeline-Resolver
Pipeline-Resolver enthalten eine oder mehrere Funktionen, die in sequentieller Reihenfolge ausgeführt werden. Jede Funktion umfasst eine Anforderungsvorlage und eine Antwortvorlage. Ein Pipeline-Resolver hat auch eine Vorher-Vorlage und eine Nachher-Vorlage, die die Reihenfolge der Funktionen, die die Vorlage enthält, umgeben. Die Vorlage after ist dem GraphQL-Feldausgabetyp zugeordnet. Pipeline-Resolver unterscheiden sich von Unit-Resolvern darin, wie die Antwortvorlage die Ausgabe abbildet. Ein Pipeline-Resolver kann jeder gewünschten Ausgabe zugeordnet werden, einschließlich der Eingabe für eine andere Funktion oder der After-Vorlage des Pipeline-Resolvers.
Mit Pipeline-Resolver-Funktionen können Sie allgemeine Logik schreiben, die Sie für mehrere Resolver in Ihrem Schema wiederverwenden können. Funktionen sind direkt an eine Datenquelle angehängt und enthalten wie ein Unit-Resolver dasselbe Vorlagenformat für Anfragen und Antworten.
Das folgende Diagramm zeigt den Prozessablauf eines Unit-Resolvers auf der linken Seite und eines Pipeline-Resolvers auf der rechten Seite.
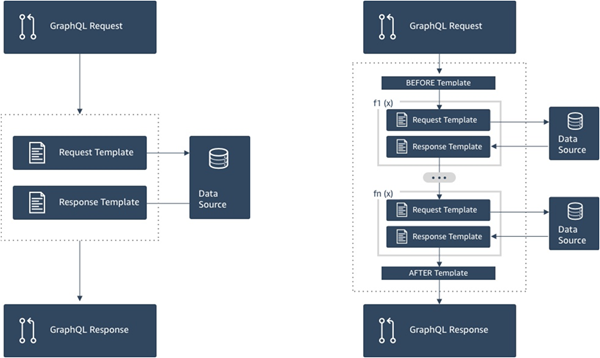
Pipeline-Resolver enthalten einen Großteil der Funktionen, die Unit-Resolver unterstützen, und mehr, allerdings auf Kosten einer etwas höheren Komplexität.
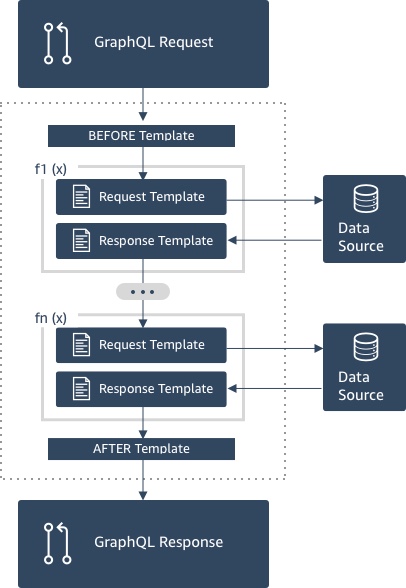
Aufbau eines Pipeline-Resolvers
Ein Pipeline-Resolver besteht aus einer Vorlage vor der Zuordnung, einer Vorlage nach der Zuordnung und einer Liste von Funktionen. Jede Funktion verfügt über eine Vorlage für die Zuordnung von Anfragen und Antworten, die sie anhand einer Datenquelle ausführt. Da ein Pipeline-Resolver die Ausführung an eine Liste von Funktionen delegiert, ist er mit keiner Datenquelle verknüpft. Unit-Resolver und -Funktionen sind Primitive, die Operation auf Datenquellen auszuführen. Weitere Informationen finden Sie in der Übersicht über die Resolver-Mapping-Vorlagen.
Vorlage vor dem Zuordnen
Mit der Vorlage für die Anforderungszuweisung eines Pipeline-Resolvers oder dem Schritt Before können Sie einige Vorbereitungslogik ausführen, bevor Sie die definierten Funktionen ausführen.
Funktionsliste
Die Liste der Funktionen eines Pipeline-Resolvers wird nacheinander ausgeführt. Das von der Zuweisungsvorlage für Anforderungen des Pipeline-Resolvers ausgewertete Ergebnis wird der ersten Funktion als $ctx.prev.result zur Verfügung gestellt. Alle Funktionsausgaben werden der jeweils nächsten Funktion als $ctx.prev.result zur Verfügung gestellt.
Nachher-Zuweisungsvorlage
Die Response-Mapping-Vorlage eines Pipeline-Resolvers oder der After-Schritt ermöglicht es Ihnen, eine endgültige Zuordnungslogik von der Ausgabe der letzten Funktion zum erwarteten GraphQL-Feldtyp durchzuführen. Die Ausgabe der letzten Funktion in der Funktionsliste ist in der Zuweisungsvorlage des Pipeline-Resolvers als $ctx.prev.result oder $ctx.result verfügbar.
Ablauf der Ausführung
Bei einem Pipeline-Resolver, der aus zwei Funktionen besteht, stellt die folgende Liste den Ausführungsablauf dar, wenn der Resolver aufgerufen wird:
-
Pipeline-Resolver Vor dem Zuordnen der Vorlage
-
Funktion 1: Zuweisungsvorlage für Anforderungen der Funktion
-
Funktion 1: Aufruf der Datenquelle
-
Funktion 1: Zuweisungsvorlage für Antworten der Funktion
-
Funktion 2: Zuweisungsvorlage für Anforderungen der Funktion
-
Funktion 2: Aufruf der Datenquelle
-
Funktion 2: Zuweisungsvorlage für Antworten der Funktion
-
Pipeline-Resolver Nach der Zuordnung der Vorlage
Anmerkung
Der Ausführungsablauf des Pipeline-Resolvers ist unidirektional und statisch im Resolver definiert.
Nützliche Dienstprogramme für Apache Velocity Template Language (VTL)
Wenn die Komplexität einer Anwendung steigt, verbessern VTL-Dienstprogramme und -Richtlinien die Produktivität der Entwicklung. Die folgenden Dienstprogramme unterstützen die Arbeit mit Pipeline-Resolvern.
$ctx.stash
Der Stash ist ein SpeicherMap, der in jedem Resolver und jeder Funktionszuordnungsvorlage verfügbar ist. Eine Stash-Instanz bleibt während einer einzigen Resolver-Instance bestehen. Daher können Sie den Stash nutzen, um beliebige Daten zwischen Zuweisungsvorlagen für Anforderungen und Antworten und Funktionen in einem Pipeline-Resolver zu übergeben. Der Stash stellt dieselben Methoden bereit wie die Java-Map-Datenstruktur
$ctx.prev.result
Das $ctx.prev.result stellt das Ergebnis der vorherigen Operation dar, die im Pipeline-Resolver ausgeführt wurde.
Wenn es sich bei der vorherigen Operation um die Before-Mapping-Vorlage des Pipeline-Resolvers handelte, $ctx.prev.result stellt dies die Ausgabe der Auswertung der Vorlage dar und wird der ersten Funktion in der Pipeline zur Verfügung gestellt. Wenn die vorherige Operation die erste Funktion betraf, steht $ctx.prev.result für die Ausgabe der ersten Funktion und wird der zweiten Funktion in der Pipeline zur Verfügung gestellt. Wenn die vorherige Operation die letzte Funktion war, stellt sie die Ausgabe der letzten Funktion $ctx.prev.result dar und wird für die After-Mapping-Vorlage des Pipeline-Resolvers verfügbar gemacht.
#return(data: Object)
Die Richtlinie #return(data: Object) ist hilfreich, wenn Sie vorzeitig aus einer beliebigen Zuweisungsvorlage zurückspringen müssen. #return(data: Object) entspricht in Programmiersprachen dem Schlüsselwort return, da es aus dem nächsten Logikblock-Scope zurückspringt. Wenn Sie daher in einer Resolver-Zuweisungsvorlage #return verwenden, erfolgt ein Rücksprung vom Resolver. Wenn #return(data: Object) in einer Resolver-Zuweisungsvorlage verwendet wird, wird für das GraphQL-Feld data festgelegt. Wenn Sie #return(data: Object) in einer Funktionszuweisungsvorlage verwenden, erfolgt ein Rücksprung aus der Funktion und es wird entweder die nächste Funktion in der Pipeline oder die Resolver-Zuweisungsvorlage für Antworten ausgeführt.
#return
Dies ist dasselbe wie#return(data: Object), null wird aber stattdessen zurückgegeben.
$util.error
Das Dienstprogramm $util.error ist nützlich, um ein Feldfehler auszulösen. Wenn Sie $util.error in einer Funktionszuweisungsvorlage verwenden, wird sofort ein Feldfehler ausgelöst, der verhindert, dass nachfolgende Funktionen ausgeführt werden. Weitere Informationen und weitere $util.error Signaturen finden Sie in der Referenz zum Resolver Mapping Template Utility.
$util.appendError
$util.appendError lässt sich mit $util.error() vergleichen, mit dem großen Unterschied, dass die Auswertung der Zuweisungsvorlage nicht unterbrochen wird. Stattdessen wird signalisiert, dass das Feld zwar eine Fehlermeldung hervorrief, die Beurteilung der Vorlage jedoch abgeschlossen wurde und infolgedessen Daten zurückgegeben wurden. Die Verwendung von $util.appendError in einer Funktion hat keine Auswirkungen auf die Ausführung des Pipeline-Ablaufs. Weitere Informationen und weitere $util.error Signaturen finden Sie in der Referenz zum Resolver Mapping Template Utility.
-Beispielvorlage
Angenommen, Sie haben eine DynamoDB-Datenquelle und einen Unit-Resolver für ein Feld mit dem NamengetPost(id:ID!), das einen Post Typ mit der folgenden GraphQL-Abfrage zurückgibt:
getPost(id:1){ id title content }
Ihre Resolver-Vorlage sieht möglicherweise folgendermaßen aus:
{ "version" : "2018-05-29", "operation" : "GetItem", "key" : { "id" : $util.dynamodb.toDynamoDBJson($ctx.args.id) } }
Hierdurch würde der Wert des id-Eingabeparameters von 1 durch ${ctx.args.id} ersetzt und die folgende JSON-Vorlage generiert:
{ "version" : "2018-05-29", "operation" : "GetItem", "key" : { "id" : { "S" : "1" } } }
AWS AppSync verwendet diese Vorlage, um Anweisungen für die Kommunikation mit DynamoDB und das Abrufen von Daten zu generieren (oder gegebenenfalls andere Operationen auszuführen). Nachdem die Daten zurückgegeben wurden, führt AWS AppSync sie durch eine optionale Antwortzuweisungsvorlage, über die Sie die Datengestaltung oder Logik vornehmen können. Wenn wir beispielsweise die Ergebnisse von DynamoDB zurückerhalten, könnten sie wie folgt aussehen:
{ "id" : 1, "theTitle" : "AWS AppSync works offline!", "theContent-part1" : "It also has realtime functionality", "theContent-part2" : "using GraphQL" }
Sie können auch mithilfe der folgenden Antwortzuweisungsvorlage zwei der Felder in einem einzelnen Feld zusammenlegen:
{ "id" : $util.toJson($context.data.id), "title" : $util.toJson($context.data.theTitle), "content" : $util.toJson("${context.data.theContent-part1} ${context.data.theContent-part2}") }
Hier sehen Sie, wie die Daten strukturiert sind, nachdem die Vorlage auf die Daten angewendet wurde:
{ "id" : 1, "title" : "AWS AppSync works offline!", "content" : "It also has realtime functionality using GraphQL" }
Die Daten werden als Antwort folgendermaßen an den Client zurückgegeben:
{ "data": { "getPost": { "id" : 1, "title" : "AWS AppSync works offline!", "content" : "It also has realtime functionality using GraphQL" } } }
Beachten Sie, dass in den meisten Situationen Antwort-Zuweisungsvorlagen einfach der Durchleitung von Daten dienen und der größte Unterschied darin besteht, ob ein einzelnes Element oder eine Liste von Elementen zurückgegeben wird. Für ein einzelnes Element lautet der Pass-Through:
$util.toJson($context.result)
Für Listen lautet der Pass-Through üblicherweise:
$util.toJson($context.result.items)
Weitere Beispiele für Unit- und Pipeline-Resolver finden Sie in den Resolver-Tutorials.
Evaluierte Deserialisierungsregeln für Mapping-Vorlagen
Zuweisungsvorlagen werden zu einer Zeichenfolge ausgewertet. In muss AWS AppSync die Ausgabezeichenfolge einer JSON-Struktur folgen, um gültig zu sein.
Darüber hinaus werden die folgenden Deserialisierungsregeln erzwungen.
Doppelte Schlüssel sind in JSON-Objekten nicht zulässig
Wenn die ausgewertete Zuweisungsvorlagenzeichenfolge ein JSON-Objekt darstellt oder ein Objekt mit doppelten Schlüsseln enthält, gibt die Zuweisungsvorlage die folgende Fehlermeldung zurück:
Duplicate field 'aField' detected on Object. Duplicate JSON keys are not
allowed.
Beispiel für einen doppelten Schlüssel in einer ausgewerteten Anforderungszuweisungsvorlage:
{ "version": "2018-05-29", "operation": "Invoke", "payload": { "field": "getPost", "postId": "1", "field": "getPost" ## key 'field' has been redefined } }
Um diesen Fehler zu beheben, definieren Sie Schlüssel in JSON-Objekten nicht neu.
Nachgestellte Zeichen sind in JSON-Objekten nicht zulässig
Wenn die ausgewertete Zuweisungsvorlagenzeichenfolge ein JSON-Objekt darstellt und nachgestellte Fremdzeichen enthält, gibt die Zuweisungsvorlage die folgende Fehlermeldung zurück:
Trailing characters at the end of the JSON string are not allowed.
Beispiel für nachgestellte Zeichen in einer ausgewerteten Anforderungszuweisungsvorlage:
{ "version": "2018-05-29", "operation": "Invoke", "payload": { "field": "getPost", "postId": "1", } }extraneouschars
Um diesen Fehler zu beheben, stellen Sie sicher, dass evaluierte Vorlagen ausschließlich nach JSON ausgewertet werden.
