Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Verwenden Sie einen externen Hive-Metastore
Sie können den Amazon-Athena-Daten-Connector für den externen Hive-Metastore verwenden, um Datensätze in Amazon S3 abzufragen in denen ein Apache-Hive-Metastore verwendet wird. Es ist keine Migration von Metadaten zum erforderlich. AWS Glue Data Catalog In der Athena-Managementkonsole konfigurieren Sie eine Lambda-Funktion für die Kommunikation mit dem Hive-Metastore, der sich in Ihrem privaten Bereich befindet, VPC und verbinden ihn dann mit dem Metastore. Die Verbindung von Lambda zu Ihrem Hive-Metastore ist durch einen privaten VPC Amazon-Kanal gesichert und nutzt nicht das öffentliche Internet. Sie können Ihren eigenen Lambda-Funktionscode angeben oder die Standardimplementierung des Athena-Daten-Connectors für externen Hive-Metastore verwenden.
Themen
- Übersicht über die Funktionen
- Workflow
- Überlegungen und Einschränkungen
- Athena mit einem Apache Hive-Metastore Connect
- Verwenden Sie den AWS Serverless Application Repository , um einen Hive-Datenquellenconnector bereitzustellen
- Athena mithilfe einer vorhandenen Ausführungsrolle mit einem Hive-Metastore Connect IAM
- Konfigurieren Sie Athena für die Verwendung eines bereitgestellten Hive-Metastore-Connectors
- Lassen Sie den Katalognamen in externen Hive-Metastore-Abfragen weg
- Mit Hive-Ansichten arbeiten
- Verwenden Sie die AWS CLI mit Hive-Metastoren
- Ändern Sie den externen Hive-Metastore-Konnektor von Athena
Übersicht über die Funktionen
Mit dem Athena-Daten-Connector für den externen Hive-Metastore können Sie die folgenden Aufgaben ausführen:
-
Verwenden Sie die Athena-Konsole, um benutzerdefinierte Kataloge zu registrieren und Abfragen damit auszuführen.
-
Definieren Sie Lambda-Funktionen für verschiedene externe Hive-Metastores und verbinden Sie sie in Athena-Abfragen.
-
Verwenden Sie die AWS Glue Data Catalog und Ihre externen Hive-Metastore in derselben Athena-Abfrage.
-
Geben Sie einen Katalog im Kontext der Abfrageausführung als aktuellen Standardkatalog an. Dadurch entfällt die Notwendigkeit, Datenbanknamen in Ihren Abfragen Katalognamen voranzustellen. Anstatt die Syntax
catalog.database.tabledatabase.table -
Verwenden Sie eine Vielzahl von Tools, um Abfragen auszuführen, die auf externe Hive-Metastores verweisen. Sie können die Athena-Konsole, die AWS CLI, Athena und die AWS SDK aktualisierten Athena APIs JDBC und Treiber verwenden. ODBC Die aktualisierten Treiber unterstützen benutzerdefinierte Kataloge.
API-Support
Athena Data Connector for External Hive Metastore unterstützt API Katalogregistrierungsvorgänge und Metadatenoperationen. API
-
Katalogregistrierung – Registrieren Sie benutzerdefinierte Kataloge für externe Hive-Metastores und Verbunddatenquellen.
-
Metadaten — Verwenden Sie MetadatenAPIs, um Datenbank- und Tabelleninformationen für AWS Glue alle Kataloge bereitzustellen, die Sie bei Athena registrieren.
-
JAVASDKAthena-Client — Verwenden Sie die Katalogregistrierung APIsAPIs, Metadaten und Unterstützung für Kataloge im
StartQueryExecutionBetrieb im aktualisierten Athena-Java-Client. SDK
Referenz-Implementierung
Athena bietet eine Referenzimplementierung für die Lambda-Funktion, die sich mit externen Hive-Metastores verbindet. Die Referenzimplementierung wird GitHub als Open-Source-Projekt bei Athena Hive
Die Referenzimplementierung ist als die folgenden beiden AWS SAM Anwendungen in der AWS Serverless Application Repository () verfügbar. SAR Sie können jede dieser Anwendungen verwenden, SAR um Ihre eigenen Lambda-Funktionen zu erstellen.
-
AthenaHiveMetastoreFunction– Uber-Lambda-Funktion.jar-Datei. Ein „Uber“ JAR (auch bekannt als FAT JAR oder JAR mit Abhängigkeiten) ist eine.jarDatei, die sowohl ein Java-Programm als auch dessen Abhängigkeiten in einer einzigen Datei enthält. -
AthenaHiveMetastoreFunctionWithLayer– Lambda-Ebene und dünne Lambda-Funktions-.jar-Datei.
Workflow
Das folgende Diagramm zeigt, wie Athena mit Ihrem externen Hive-Metastore interagiert.
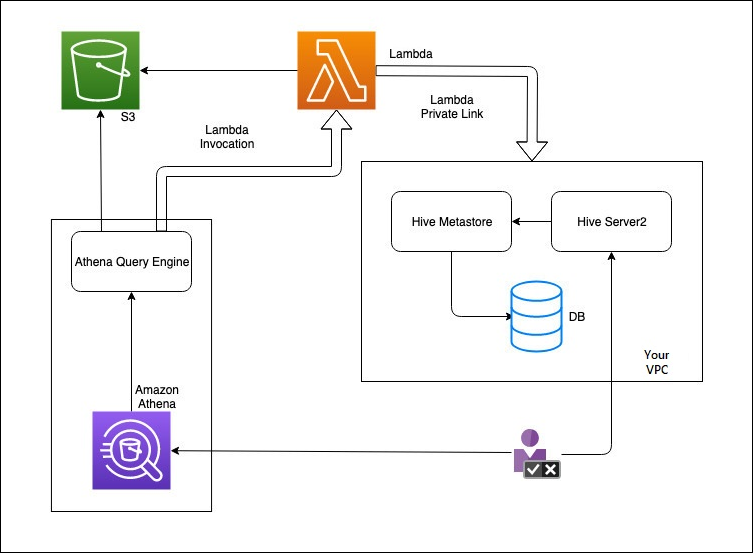
In diesem Workflow befindet sich Ihr mit der Datenbank verbundener Hive-Metastore in Ihrem. VPC Sie verwenden Hive Server2, um Ihren Hive-Metastore mithilfe von Hive zu verwalten. CLI
Der Workflow für die Verwendung externer Hive-Metastores von Athena beinhaltet die folgenden Schritte.
-
Sie erstellen eine Lambda-Funktion, die Athena mit dem Hive-Metastore verbindet, der sich in Ihrem befindet. VPC
-
Sie registrieren einen eindeutigen Katalognamen für Ihren Hive-Metastore und einen entsprechenden Funktionsnamen in Ihrem Konto.
-
Wenn Sie eine Athena DML oder eine DDL Abfrage ausführen, die den Katalognamen verwendet, ruft die Athena-Abfrage-Engine den Lambda-Funktionsnamen auf, den Sie dem Katalognamen zugeordnet haben.
-
Mithilfe dieser AWS PrivateLink Funktion kommuniziert die Lambda-Funktion mit dem externen Hive-Metastore in Ihrem VPC und empfängt Antworten auf Metadatenanfragen. Athena verwendet die Metadaten Ihres externen Hive-Metastores genauso wie die Metadaten des Standard- AWS Glue Data Catalog.
Überlegungen und Einschränkungen
Berücksichtigen Sie bei der Verwendung des Athena-Daten-Connectors für den externen Hive-Metastore die folgenden Punkte:
-
Sie können sie verwendenCTAS, um eine Tabelle in einem externen Hive-Metastore zu erstellen.
-
Sie können es verwenden INSERTINTO, um Daten in einen externen Hive-Metastore einzufügen.
-
DDLDie Unterstützung für externe Hive-Metastore ist auf die folgenden Anweisungen beschränkt.
-
ALTER DATABASE SET DBPROPERTIES
-
ALTER TABLE ADD COLUMNS
-
ALTER TABLE ADD PARTITION
-
ALTER TABLE DROP PARTITION
-
ALTER TABLE RENAME PARTITION
-
ALTER TABLE REPLACE COLUMNS
-
ALTER TABLE SET LOCATION
-
ALTER TABLE SET TBLPROPERTIES
-
CREATE DATABASE
-
CREATE TABLE
-
CREATETABLEALS
-
DESCRIBE TABLE
-
DROP DATABASE
-
DROP TABLE
-
SHOW COLUMNS
-
SHOW CREATE TABLE
-
SHOW PARTITIONS
-
SHOW SCHEMAS
-
SHOW TABLES
-
SHOW TBLPROPERTIES
-
-
Die maximale Anzahl registrierter Kataloge beträgt 1.000.
-
Die Kerberos-Authentifizierung wird für Hive-Metastores nicht unterstützt.
-
Um den JDBC Treiber mit einem externen Hive-Metastore oder Verbundabfragen zu verwenden, fügen Sie ihn
MetadataRetrievalMethod=ProxyAPIin Ihre JDBC Verbindungszeichenfolge ein. Informationen zum JDBC Treiber finden Sie unter. Connect zu Amazon Athena her mit JDBC -
Die ausgeblendeten Hive-Spalten
$path,$bucket,$file_size,$file_modified_time,$partition,$row_idkönnen nicht für eine differenzierte Filterung der Zugriffskontrolle verwendet werden. -
In Hive ausgeblendete Systemtabellen wie
example_table$partitionsexample_table$properties
Berechtigungen
Vorab erstellte und benutzerdefinierte Daten-Connectors benötigen möglicherweise Zugriff auf die folgenden Ressourcen, um ordnungsgemäß zu funktionieren. Überprüfen Sie die Informationen für den Connector, den Sie verwenden, um sicherzustellen, dass Sie Ihren VPC richtig konfiguriert haben. Hinweise zu den erforderlichen IAM Berechtigungen zum Ausführen von Abfragen und zum Erstellen eines Datenquellenconnectors in Athena finden Sie unter Zugriff auf den Athena Data Connector für External Hive Metastore zulassen undGewährung von Lambda-Funktionszugriff auf externe Hive-Metastores.
-
Amazon S3 – Zusätzlich zum Schreiben von Abfrageergebnissen zum Athena-Abfrageergebnisspeicherort in Amazon S3 schreiben Daten-Connectors auch zu einem Spill-Bucket in Amazon S3. Konnektivität und Berechtigungen für diesen Amazon-S3-Standort sind erforderlich. Weitere Informationen finden Sie unter Spill-Speicherort in Amazon S3 an späterer Stelle in diesem Thema.
-
Athena – Zugriff ist erforderlich, um den Abfragestatus zu überprüfen und das Overscanning zu verhindern.
-
AWS Glue— Zugriff ist erforderlich, wenn Ihr Konnektor zusätzliche oder primäre Metadaten verwendet AWS Glue .
-
AWS Key Management Service
-
Richtlinien — Hive Metastore, Athena Query Federation und UDFs erfordern Richtlinien zusätzlich zu den. AWS verwaltete Richtlinie: AmazonAthenaFullAccess Weitere Informationen finden Sie unter Identity and Access Management in Athena.
Spill-Speicherort in Amazon S3
Aufgrund des Grenzwerts für Lambda-Funktionsantwortgrößen werden Antworten, die größer als der Schwellenwert sind, an einen Amazon-S3-Speicherort übertragen, den Sie beim Erstellen der Lambda-Funktion angeben. Athena liest diese Antworten direkt von Amazon S3.
Anmerkung
Athena entfernt die Antwortdateien nicht von Amazon S3. Es wird empfohlen, eine Aufbewahrungsrichtlinie einzurichten, um Antwortdateien automatisch zu löschen.
