Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Anzeige reaktiver Anomalien
In einem Einblick können Sie sich Anomalien für Amazon RDS-Ressourcen ansehen. Auf einer Seite mit reaktiven Erkenntnissen können Sie im Abschnitt Aggregierte Metriken eine Liste von Anomalien mit entsprechenden Zeitplänen einsehen. Es gibt auch Abschnitte, in denen Informationen zu Protokollgruppen und Ereignissen im Zusammenhang mit den Anomalien angezeigt werden. Für kausale Anomalien in einem reaktiven Einblick gibt es jeweils eine entsprechende Seite mit Einzelheiten zu der Anomalie.
Anzeige der detaillierten Analyse einer reaktiven RDS-Anomalie
In dieser Phase können Sie die Anomalie genauer untersuchen, um detaillierte Analysen und Empfehlungen für Ihre Amazon RDS-DB-Instances zu erhalten.
Die detaillierte Analyse ist nur für Amazon RDS-DB-Instances verfügbar, für die Performance Insights aktiviert ist.
Um zur Seite mit den Details zur Anomalie vorzudringen
-
Suchen Sie auf der Insight-Seite nach einer aggregierten Metrik mit dem Ressourcentyp AWS/RDS.
-
Wählen Sie die Option Details anzeigen aus.
Die Seite mit den Details zur Anomalie wird angezeigt. Der Titel beginnt mit Database Performance Anomaly und gibt der Ressource den Namen Show. Die Konsole verwendet standardmäßig die Anomalie mit dem höchsten Schweregrad, unabhängig davon, wann die Anomalie aufgetreten ist.
-
(Optional) Wenn mehrere Ressourcen betroffen sind, wählen Sie eine andere Ressource aus der Liste oben auf der Seite aus.
Im Folgenden finden Sie Beschreibungen der Komponenten der Detailseite.
Übersicht über Ressourcen
Der obere Bereich der Detailseite ist die Ressourcenübersicht. In diesem Abschnitt werden die Leistungsanomalien zusammengefasst, die bei Ihrer Amazon RDS-DB-Instance aufgetreten sind.
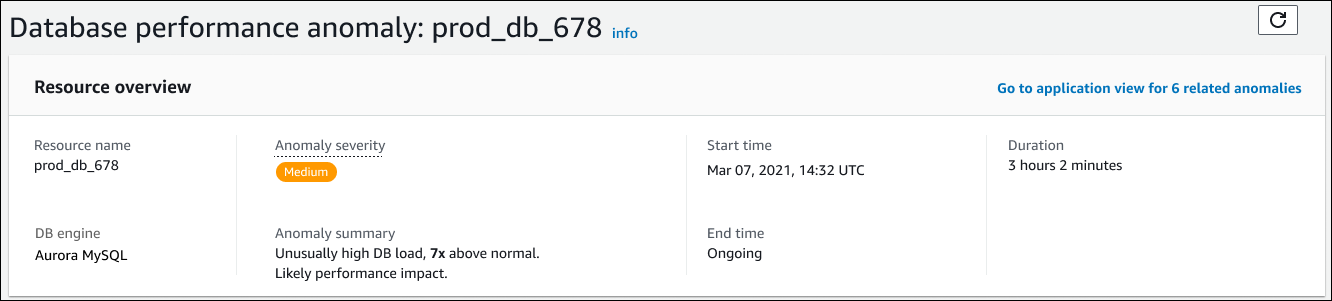
Dieser Abschnitt enthält die folgenden Felder:
-
Ressourcenname — Der Name der DB-Instance, bei der die Anomalie auftritt. In diesem Beispiel hat die Ressource den Namen prod_db_678.
-
DB-Engine — Der Name der DB-Instance, bei der die Anomalie aufgetreten ist. In diesem Beispiel ist die Engine Aurora MySQL.
-
Schweregrad der Anomalie — Das Maß für die negativen Auswirkungen der Anomalie auf Ihre Instance. Mögliche Schweregrade sind Hoch, Mittel und Niedrig.
-
Zusammenfassung der Anomalie — Eine kurze Zusammenfassung des Problems. Eine typische Zusammenfassung lautet „Ungewöhnlich hohe Datenbanklast“.
-
Startzeit und Endzeit — Die Zeit, zu der die Anomalie begann und endete. Wenn die Endzeit „Fortlaufend“ ist, tritt die Anomalie immer noch auf.
-
Dauer — Die Dauer des anomalen Verhaltens. In diesem Beispiel besteht die Anomalie weiterhin und tritt seit 3 Stunden und 2 Minuten auf.
Primäre Metrik
Im Abschnitt Primäre Kennzahl wird die zufällige Anomalie zusammengefasst, bei der es sich um die Anomalie auf oberster Ebene innerhalb des Insights handelt. Sie können sich die kausale Anomalie als das allgemeine Problem Ihrer DB-Instance vorstellen.
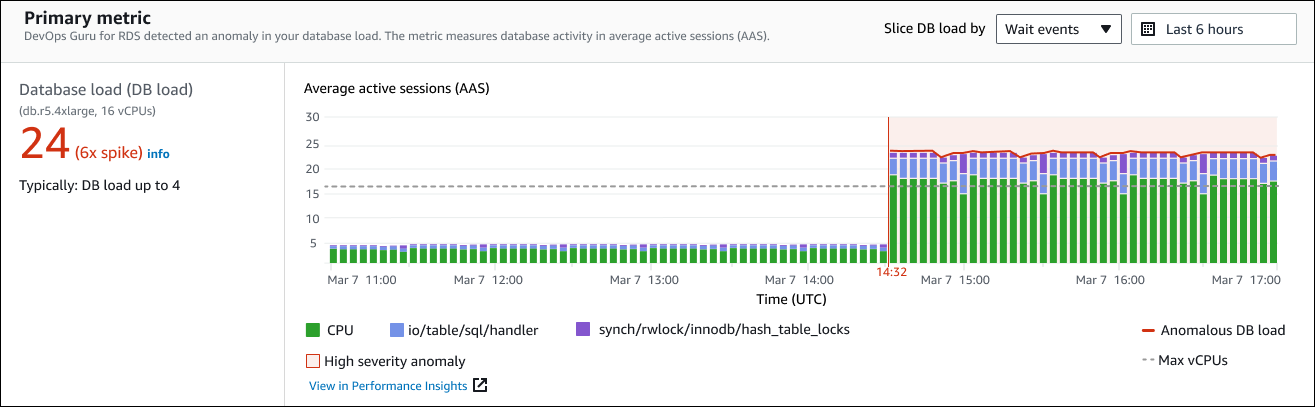
Im linken Bereich finden Sie weitere Informationen zu dem Problem. In diesem Beispiel enthält die Zusammenfassung die folgenden Informationen:
-
Datenbanklast (DB-Load) — Eine Kategorisierung der Anomalie als Problem beim Laden der Datenbank. Die entsprechende Metrik in Performance Insights lautet
DBLoad. Diese Metrik wird auch auf Amazon veröffentlicht CloudWatch. -
db.r5.4xlarge — Die DB-Instance-Klasse. Die Anzahl von vCPUs, die in diesem Beispiel 16 ist, entspricht der gepunkteten Linie im Diagramm der durchschnittlichen aktiven Sitzungen (AAS).
-
24 (6-fache Spitze) — Die Datenbanklast, gemessen in den durchschnittlichen aktiven Sitzungen (AAS) während des im Insight angegebenen Zeitintervalls. Somit waren zu einem beliebigen Zeitpunkt während des Zeitraums der Anomalie durchschnittlich 24 Sitzungen in der Datenbank aktiv. Die Datenbanklast beträgt das Sechsfache der normalen Datenbanklast für diese Instance.
-
Typischerweise: DB-Auslastung bis zu 4 — Der Basiswert der DB-Auslastung, gemessen in AAS, während einer typischen Arbeitslast. Der Wert 4 bedeutet, dass bei normalem Betrieb zu einem bestimmten Zeitpunkt durchschnittlich 4 oder weniger Sitzungen in der Datenbank aktiv sind.
Standardmäßig ist das Lastdiagramm nach Warteereignissen unterteilt. Das bedeutet, dass für jeden Balken im Diagramm der größte farbige Bereich das Warteereignis darstellt, das am meisten zur Gesamtlast der Datenbank beiträgt. Das Diagramm zeigt den Zeitpunkt (in Rot), zu dem das Problem begann. Konzentrieren Sie sich auf die Warteereignisse, die den meisten Platz in der Leiste beanspruchen:
-
CPU -
IO:wait/io/sql/table/handler
Die vorangegangenen Warteereignisse treten für diese Aurora MySQL-Datenbank häufiger als normal auf. Informationen zum Optimieren der Leistung mithilfe von Warteereignissen in Amazon Aurora finden Sie unter Optimieren mit Warteereignissen für Aurora MySQL und Optimieren mit Warteereignissen für Aurora PostgreSQL im Amazon Aurora Aurora-Benutzerhandbuch. Informationen zum Optimieren der Leistung mithilfe von Warteereignissen in RDS for PostgreSQL finden Sie unter Tuning with wait events for RDS for PostgreSQL im Amazon RDS-Benutzerhandbuch.
Verwandte Metriken
Im Abschnitt Verwandte Kennzahlen sind die kontextuellen Anomalien aufgeführt, bei denen es sich um spezifische Ergebnisse innerhalb der kausalen Anomalie handelt. Diese Ergebnisse enthalten zusätzliche Informationen zu den Leistungsproblemen.
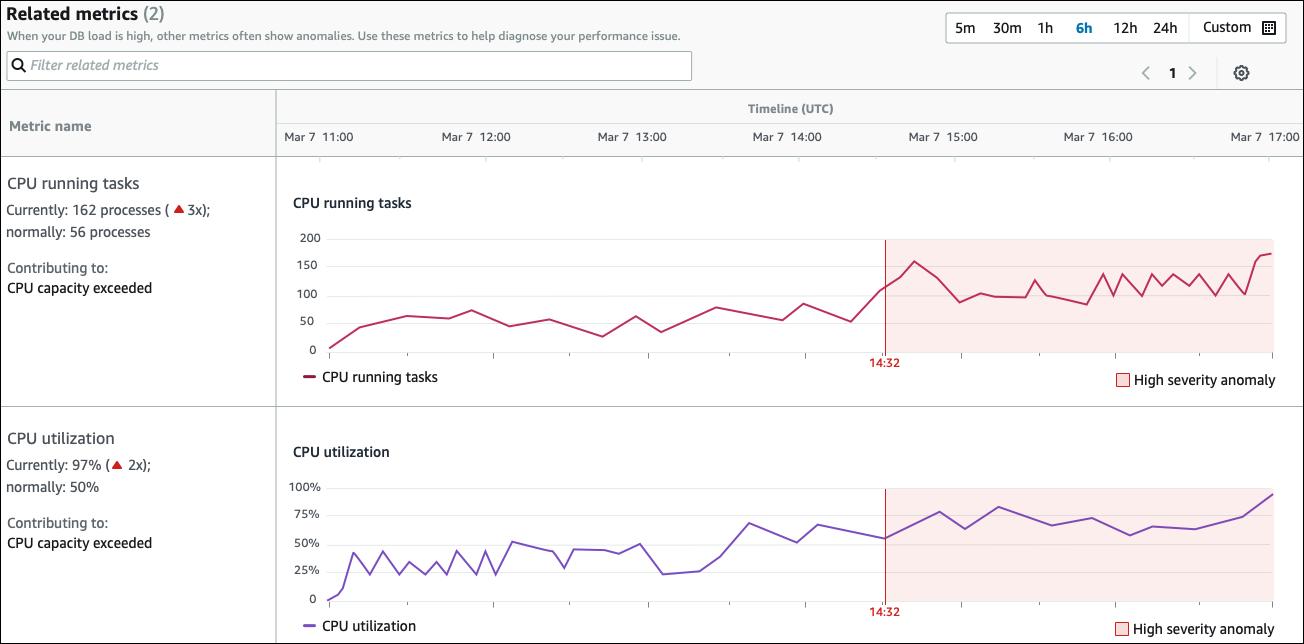
Die Tabelle mit verwandten Metriken hat zwei Spalten: Name der Metriken und Zeitleiste (UTC). Jede Zeile in der Tabelle entspricht einer bestimmten Metrik.
Die erste Spalte jeder Zeile enthält die folgenden Informationen:
-
Name— Der Name der Metrik. In der ersten Zeile wird die Metrik als CPU-laufende Aufgaben identifiziert. -
Aktuell — Der aktuelle Wert der Metrik. In der ersten Zeile ist der aktuelle Wert 162 Prozesse (3x).
-
Normalerweise — Die Basislinie dieser Metrik für diese Datenbank, wenn sie normal funktioniert. DevOpsGuru for RDS berechnet den Ausgangswert als den 95. Perzentilwert im Verlauf einer Woche. Die erste Zeile gibt an, dass 56 Prozesse normalerweise auf der CPU ausgeführt werden.
-
Beitrag zu — Das mit dieser Metrik verbundene Ergebnis. In der ersten Zeile wird die Metrik „CPU running tasks“ mit der Anomalie „CPU-Kapazitätsüberschreitung“ verknüpft.
Die Zeitleistenspalte zeigt ein Liniendiagramm für die Metrik. Der schattierte Bereich zeigt das Zeitintervall, in dem DevOps Guru for RDS das Ergebnis als schwerwiegend eingestuft hat.
Analyse und Empfehlungen
Während die kausale Anomalie das Gesamtproblem beschreibt, beschreibt eine kontextuelle Anomalie ein bestimmtes Ergebnis, das untersucht werden muss. Jedes Ergebnis entspricht einer Reihe verwandter Kennzahlen.
Im folgenden Beispiel eines Abschnitts mit Analysen und Empfehlungen wurden zwei Ergebnisse für die Anomalie mit hoher Datenbanklast festgestellt.
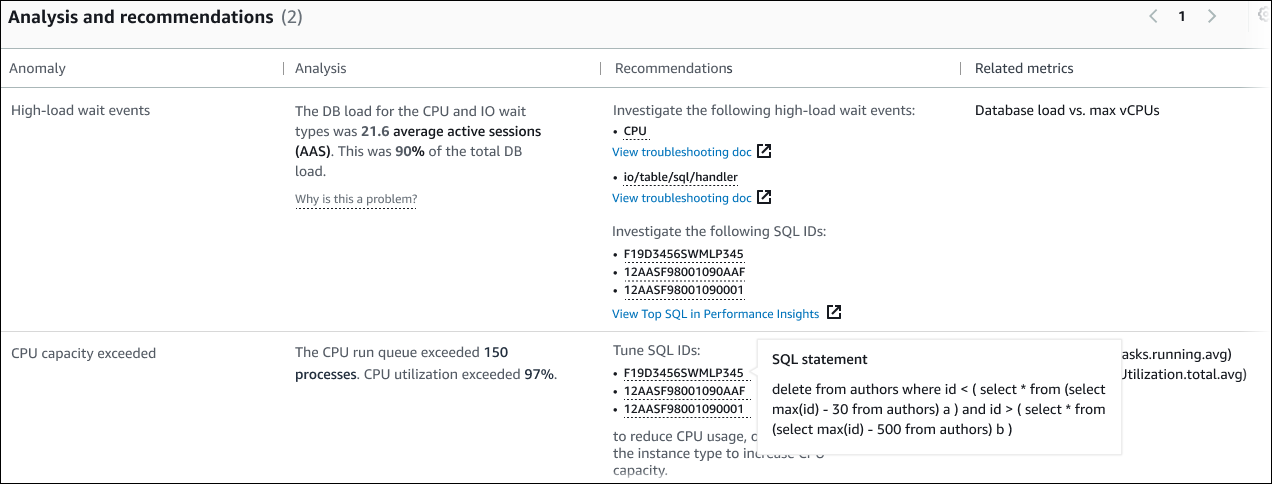
Diese Tabelle hat die folgenden Spalten:
-
Anomalie — Eine allgemeine Beschreibung dieser kontextuellen Anomalie. In diesem Beispiel handelt es sich bei der ersten Anomalie um Warteereignisse bei hoher Auslastung und bei der zweiten um eine Überschreitung der CPU-Kapazität.
-
Analyse — Eine detaillierte Erklärung der Anomalie.
Bei der ersten Anomalie tragen drei Wartearten zu 90% der DB-Auslastung bei. Bei der zweiten Anomalie überstieg die CPU-Ausführungswarteschlange 150, was bedeutet, dass zu einem bestimmten Zeitpunkt mehr als 150 Sitzungen auf CPU-Zeit warteten. Die CPU-Auslastung lag bei über 97%, was bedeutet, dass die CPU während der Dauer des Problems zu 97% ausgelastet war. Somit war die CPU fast ununterbrochen ausgelastet, während durchschnittlich 150 Sitzungen darauf warteten, auf der CPU ausgeführt zu werden.
-
Empfehlungen — Die vorgeschlagene Benutzerreaktion auf die Anomalie.
Bei der ersten Anomalie empfiehlt DevOps Guru for RDS, dass Sie die Warteereignisse
cpuuntersuchen und.io/table/sql/handlerInformationen dazu, wie Sie Ihre Datenbankleistung auf der Grundlage dieser Ereignisse optimieren können, finden Sie unter cpu und io/table/sql/handlerim Amazon Aurora Aurora-Benutzerhandbuch.Bei der zweiten Anomalie empfiehlt DevOps Guru for RDS, dass Sie den CPU-Verbrauch reduzieren, indem Sie drei SQL-Anweisungen optimieren. Sie können den Mauszeiger über die Links bewegen, um den SQL-Text zu sehen.
-
Verwandte Metriken — Metriken, die Ihnen spezifische Messwerte für die Anomalie liefern. Weitere Informationen zu diesen Metriken finden Sie unter Metrik-Referenz für Amazon Aurora im Amazon Aurora Aurora-Benutzerhandbuch oder Metrik-Referenz für Amazon RDS im Amazon RDS-Benutzerhandbuch.
Bei der ersten Anomalie empfiehlt DevOps Guru for RDS, die Datenbanklast mit der maximalen CPU-Auslastung für Ihre Instance zu vergleichen. Bei der zweiten Anomalie wird empfohlen, sich die CPU-Ausführungswarteschlange, die CPU-Auslastung und die SQL-Ausführungsrate anzusehen.
