Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Tutorial: Erste Schritte mit Amazon EMR
Gehen Sie durch einen Workflow, um schnell einen Amazon EMR-Cluster einzurichten und eine Spark-Anwendung auszuführen.
Einrichtung Ihres Amazon EMR-Clusters
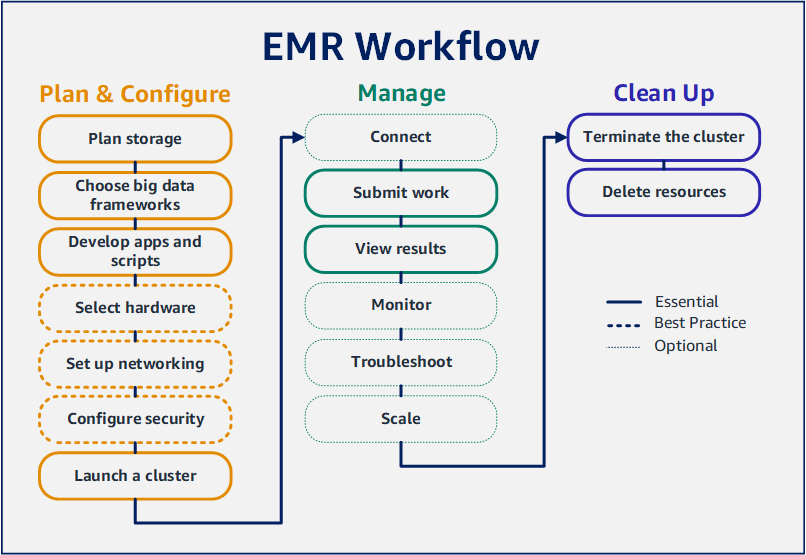
Mit Amazon EMR können Sie in nur wenigen Minuten einen Cluster einrichten, um Daten mit Big-Data-Frameworks zu verarbeiten und zu analysieren. Dieses Tutorial zeigt Ihnen, wie Sie einen Beispielcluster mit Spark starten und wie Sie ein einfaches PySpark Skript ausführen, das in einem Amazon S3 S3-Bucket gespeichert ist. Es behandelt wichtige Amazon-EMR-Aufgaben in drei Workflow-Hauptkategorien: Planen und Konfigurieren, Verwalten und Aufräumen.
Während Sie das Tutorial durcharbeiten, finden Sie Links zu detaillierteren Themen und im Nächste Schritte Abschnitt Ideen für weitere Schritte. Bei weiteren Fragen oder Problemen können Sie sich an das Amazon-EMR-Team wenden, indem Sie einen Beitrag im Diskussionsforum
Voraussetzungen
-
Stellen Sie vor dem Starten eines Amazon-EMR-Clusters sicher, dass Sie die Aufgaben unter Bevor Sie Amazon EMR einrichten ausführen.
Cost (Kosten)
-
Der erstellte Beispiel-Cluster wird in einer Live-Umgebung ausgeführt. Für den Cluster fallen nur minimale Gebühren an. Stellen Sie sicher, dass Sie die Bereinigungsaufgaben im letzten Schritt dieses Tutorials ausführen, um zusätzliche Kosten zu vermeiden. Gebühren fallen pro Sekunde gemäß den Amazon-EMR-Preisen an. Die Gebühren variieren auch je nach Region. Weitere Informationen finden Sie unter Amazon-EMR-Preise
. -
Für kleine Dateien, die Sie in Amazon S3 speichern, können geringe Gebühren anfallen. Einige oder alle Gebühren für Amazon S3 können erlassen werden, wenn Sie sich innerhalb der Nutzungsgrenzen des AWS kostenlosen Kontingents befinden. Weitere Informationen finden Sie unter Amazon-S3-Preise
und AWS kostenloses Kontingent .
Schritt 1: Datenressourcen konfigurieren und einen Amazon EMR-Cluster starten
Speicher für Amazon EMR vorbereiten
Wenn Sie Amazon EMR verwenden, können Sie aus einer Vielzahl von Dateisystemen wählen, um Eingabedaten, Ausgabedaten und Protokolldateien zu speichern. In diesem Tutorial verwenden Sie EMRFS zum Speichern von Daten in einem S3-Bucket. EMRFS ist eine Implementierung des Hadoop-Dateisystems, mit der Sie reguläre Dateien in Amazon S3 lesen und schreiben können. Weitere Informationen finden Sie unter Arbeiten mit Speicher- und Dateisystemen mit Amazon EMR.
Um einen Bucket zu erstellen, befolgen Sie die Anweisungen unter Wie wird ein S3 Bucket erstellt? im Konsolen-Benutzerhandbuch zu Amazon Simple Storage Service. Erstellen Sie den Bucket in derselben AWS Region, in der Sie Ihren Amazon EMR-Cluster starten möchten. Zum Beispiel USA West (Oregon) us-west-2.
Für Buckets und Ordner, die Sie mit Amazon EMR verwenden, gelten die folgenden Einschränkungen:
-
Namen können Kleinbuchstaben, Zahlen, Bindestriche (-) und Punkte (.) enthalten.
-
Namen dürfen nicht mit Zahlen enden.
-
Bucket-Namen müssen in allen AWS-Konten eindeutig sein.
-
Ein Ausgabeordner muss leer sein.
Bereiten Sie eine Anwendung mit Eingabedaten für Amazon EMR vor
Die gängigste Methode zur Vorbereitung eines Antrags für Amazon EMR besteht darin, den Antrag und seine Eingabedaten in Amazon S3 hochzuladen. Wenn Sie dann Arbeit an Ihren Cluster senden, geben Sie die Amazon-S3-Speicherorte für Ihr Skript und Ihre Daten an.
In diesem Schritt laden Sie ein PySpark Beispielskript in Ihren Amazon S3 S3-Bucket hoch. Wir haben ein PySpark Skript zur Verfügung gestellt, das Sie verwenden können. Das Skript verarbeitet Inspektionsdaten von Lebensmittelbetrieben und gibt eine Ergebnisdatei in Ihrem S3-Bucket zurück. In der Ergebnisdatei sind die zehn Einrichtungen mit den meisten Verstößen vom Typ „Rot“ aufgeführt.
Sie laden auch Beispieleingabedaten in Amazon S3 hoch, damit das PySpark Skript sie verarbeiten kann. Bei den Eingabedaten handelt es sich um eine modifizierte Version der Inspektionsergebnisse des Gesundheitsministeriums in King County, Washington, von 2006 bis 2020. Weitere Informationen finden Sie unter King County Open Data: Daten zur Inspektion von Lebensmittelbetrieben
name,inspection_result,inspection_closed_business,violation_type,violation_points 100 LB CLAM,Unsatisfactory,FALSE,BLUE,5 100 PERCENT NUTRICION,Unsatisfactory,FALSE,BLUE,5 7-ELEVEN #2361-39423A,Complete,FALSE,,0
Um das PySpark Beispielskript für EMR vorzubereiten
-
Kopieren Sie den Beispielcode unten mit einem Editor Ihrer Wahl in eine neue Datei.
import argparse from pyspark.sql import SparkSession def calculate_red_violations(data_source, output_uri): """ Processes sample food establishment inspection data and queries the data to find the top 10 establishments with the most Red violations from 2006 to 2020. :param data_source: The URI of your food establishment data CSV, such as 's3://amzn-s3-demo-bucket/food-establishment-data.csv'. :param output_uri: The URI where output is written, such as 's3://amzn-s3-demo-bucket/restaurant_violation_results'. """ with SparkSession.builder.appName("Calculate Red Health Violations").getOrCreate() as spark: # Load the restaurant violation CSV data if data_source is not None: restaurants_df = spark.read.option("header", "true").csv(data_source) # Create an in-memory DataFrame to query restaurants_df.createOrReplaceTempView("restaurant_violations") # Create a DataFrame of the top 10 restaurants with the most Red violations top_red_violation_restaurants = spark.sql("""SELECT name, count(*) AS total_red_violations FROM restaurant_violations WHERE violation_type = 'RED' GROUP BY name ORDER BY total_red_violations DESC LIMIT 10""") # Write the results to the specified output URI top_red_violation_restaurants.write.option("header", "true").mode("overwrite").csv(output_uri) if __name__ == "__main__": parser = argparse.ArgumentParser() parser.add_argument( '--data_source', help="The URI for you CSV restaurant data, like an S3 bucket location.") parser.add_argument( '--output_uri', help="The URI where output is saved, like an S3 bucket location.") args = parser.parse_args() calculate_red_violations(args.data_source, args.output_uri) -
Speichern Sie die Datei als
health_violations.py. -
Laden Sie Ihre
health_violations.pyin Amazon S3 in den Bucket hoch, den Sie als Voraussetzung für dieses Tutorial erstellt haben. Anweisungen finden Sie unter Hochladen eines Objekts in Ihren Bucket im Handbuch „Erste Schritte“ für Amazon Simple Storage Service.
Um die Probeneingabedaten für EMR vorzubereiten
-
Laden Sie die ZIP-Datei food_establishment_data.zip herunter.
-
Entpacken und speichern Sie
food_establishment_data.zipalsfood_establishment_data.csvauf Ihrem Computer. -
Laden Sie die CSV-Datei in den S3-Bucket hoch, den Sie für dieses Tutorial erstellt haben. Anweisungen finden Sie unter Hochladen eines Objekts in Ihren Bucket im Handbuch „Erste Schritte“ für Amazon Simple Storage Service.
Weitere Informationen zum Einrichten von Daten für EMR finden Sie unter Eingabedaten für die Verarbeitung mit Amazon EMR vorbereiten.
Starten eines Amazon-EMR-Clusters
Nachdem Sie einen Speicherort und Ihre Anwendung vorbereitet haben, können Sie einen Amazon-EMR-Beispielcluster starten. In diesem Schritt starten Sie einen Apache-Spark-Cluster mit der neuesten Amazon-EMR-Version.
Schritt 2: Arbeiten an Ihren Amazon EMR-Cluster einreichen
Arbeit einreichen und Ergebnisse ansehen
Nachdem Sie einen Cluster gestartet haben, können Sie Arbeiten an den laufenden Cluster senden, um Daten zu verarbeiten und zu analysieren. In einem Schritt reichen Sie Arbeiten an einen Amazon-EMR-Cluster ein. Ein Schritt ist eine Arbeitseinheit, die aus einer oder mehreren Aktionen besteht. Sie könnten beispielsweise einen Schritt zur Berechnung von Werten oder zur Übertragung und Verarbeitung von Daten einreichen. Sie können Schritte beim Erstellen eines Clusters oder an einen laufenden Cluster senden. In diesem Teil des Tutorials übermitteln Sie health_violations.py als Schritt an Ihren laufenden Cluster. Weitere Informationen zu Schritten finden Sie unter Arbeit an einen Amazon EMR-Cluster einreichen.
Weitere Informationen zum Schrittlebenszyklus finden Sie unter Ausführen von Schritten zur Verarbeitung von Daten.
Ergebnisse anzeigen
Nachdem ein Schritt erfolgreich ausgeführt wurde, können Sie seine Ausgabeergebnisse in Ihrem Amazon-S3-Ausgabeordner anzeigen.
Um die Ergebnisse von anzusehen health_violations.py
Öffnen Sie die Amazon S3 S3-Konsole unter https://console.aws.amazon.com/s3/
. -
Wählen Sie den Bucket-Namen und dann den Ausgabeordner aus, den Sie beim Absenden des Schritts angegeben haben. Zum Beispiel,
amzn-s3-demo-bucketund dannmyOutputFolder. -
Stellen Sie sicher, dass die folgenden Elemente in Ihrem Ausgabeordner angezeigt werden:
-
Ein kleines Objekt namens
_SUCCESS. -
Eine CSV-Datei, die mit dem Präfix
part-beginnt, die Ihre Ergebnisse enthält.
-
-
Wählen Sie das Objekt mit Ihren Ergebnissen aus und klicken Sie dann auf Herunterladen, um die Ergebnisse in Ihrem lokalen Dateisystem zu speichern.
-
Öffnen Sie die Ergebnisse in Ihrem Editor Ihrer Wahl. In der Ausgabedatei sind die zehn Lebensmittelbetriebe mit den meisten roten Verstößen aufgeführt. Die Ausgabedatei zeigt auch die Gesamtzahl der roten Verstöße für jeden Betrieb.
Es folgt ein Beispiel für ein
health_violations.py-Ergebnis.name, total_red_violations SUBWAY, 322 T-MOBILE PARK, 315 WHOLE FOODS MARKET, 299 PCC COMMUNITY MARKETS, 251 TACO TIME, 240 MCDONALD'S, 177 THAI GINGER, 153 SAFEWAY INC #1508, 143 TAQUERIA EL RINCONSITO, 134 HIMITSU TERIYAKI, 128
Weitere Informationen zur Amazon-EMR-Clusterausgabe finden Sie unter Einen Speicherort für die Amazon EMR-Clusterausgabe konfigurieren.
Wenn Sie Amazon EMR verwenden, möchten Sie möglicherweise eine Verbindung zu einem laufenden Cluster herstellen, um Protokolldateien zu lesen, den Cluster zu debuggen oder CLI-Tools wie die Spark-Shell zu verwenden. Mit Amazon EMR können Sie mithilfe des Secure Shell (SSH)-Protokolls eine Verbindung zu einem Cluster herstellen. In diesem Abschnitt erfahren Sie, wie Sie SSH konfigurieren, eine Verbindung zu Ihrem Cluster herstellen und Protokolldateien für Spark anzeigen. Weitere Informationen zum Herstellen einer Verbindung mit einem Cluster finden Sie unter Authentifizieren von Amazon-EMR-Cluster-Knoten.
Autorisieren von SSH-Verbindungen zu Ihrem Cluster
Bevor Sie eine Verbindung zu Ihrem Cluster herstellen, müssen Sie Ihre Cluster-Sicherheitsgruppen ändern, um eingehende SSH-Verbindungen zu autorisieren. Amazon-EC2-Sicherheitsgruppen fungieren als virtuelle Firewalls für Ihre Instances zur Steuerung des ein- und ausgehenden Datenverkehrs zu Ihrem Cluster. Als Sie Ihren Cluster für dieses Tutorial erstellt haben, hat Amazon EMR in Ihrem Namen die folgenden Sicherheitsgruppen erstellt:
- ElasticMapReduce-master
-
Die standardmäßige verwaltete Amazon-EMR-Sicherheitsgruppe, die mit dem Primärknoten verknüpft ist. In einem Amazon-EMR-Cluster ist der Primärknoten eine Amazon-EC2-Instance, die den Cluster verwaltet.
- ElasticMapReduce-slave
-
Die Standardsicherheitsgruppe, die Core- und Aufgabenknoten zugeordnet ist.
Connect zu Ihrem Cluster her, indem SieAWS CLI
Unabhängig von Ihrem Betriebssystem können Sie mit dem AWS CLI eine SSH-Verbindung zu Ihrem Cluster herstellen.
Um eine Verbindung zu Ihrem Cluster herzustellen und Protokolldateien anzuzeigen, verwenden SieAWS CLI
-
Stellen Sie mit dem folgenden Befehl eine SSH-Verbindung zu Ihrem Cluster her.
<mykeypair.key>Ersetzen Sie durch den vollständigen Pfad und Dateinamen Ihrer Schlüsselpaardatei. Beispiel,C:\Users\<username>\.ssh\mykeypair.pem.aws emr ssh --cluster-id<j-2AL4XXXXXX5T9>--key-pair-file<~/mykeypair.key> -
Navigieren Sie zu
/mnt/var/log/spark, um auf die Spark-Protokolle auf dem Hauptknoten Ihres Clusters zuzugreifen. Sehen Sie sich dann die Dateien an diesem Speicherort an. Eine Liste zusätzlicher Protokolldateien auf dem Hauptknoten finden Sie unter Protokolldateien auf dem Primärknoten anzeigen.cd /mnt/var/log/spark ls
Amazon EMR on EC2 ist auch ein unterstützter Berechnungstyp für Amazon SageMaker AI Unified Studio. Informationen zur Verwendung und Verwaltung von EMR auf EC2-Ressourcen in Unified Studio finden Sie unter Amazon EMR auf EC2 verwalten. Amazon SageMaker AI
Schritt 3: Ihre Amazon-EMR-Ressourcen bereinigen
So beenden Sie Ihren Cluster
Nachdem Sie Arbeiten an Ihren Cluster übermittelt und die Ergebnisse Ihrer PySpark Bewerbung eingesehen haben, können Sie den Cluster beenden. Durch das Beenden eines Clusters werden alle mit dem Cluster verbundenen Amazon-EMR-Gebühren und Amazon-EC2-Instances gestoppt.
Wenn Sie einen Cluster kündigen, speichert Amazon EMR Metadaten über den Cluster zwei Monate lang kostenlos. Archivierte Metadaten helfen Ihnen dabei, den Cluster für einen neuen Auftrag zu klonen oder die Cluster-Konfiguration zu Referenzzwecken wiederaufzugreifen. Zu den Metadaten gehören keine Daten, die der Cluster in S3 schreibt, oder Daten, die in HDFS auf dem Cluster gespeichert sind.
Anmerkung
Mit der Amazon-EMR-Konsole können Sie nach dem Beenden des Clusters keinen Cluster aus der Listenansicht löschen. Ein beendeter Cluster verschwindet von der Konsole, wenn Amazon EMR seine Metadaten löscht.
Löschen von S3-Ressourcen
Um zusätzliche Gebühren zu vermeiden, sollten Sie Ihren Amazon-S3-Bucket löschen. Durch das Löschen des Buckets werden alle Amazon-S3-Ressourcen für dieses Tutorial entfernt. Ihr Bucket sollte Folgendes enthalten:
-
Das PySpark Skript
-
Der Eingabedatensatz
-
Ihr Ordner mit den Ausgabeergebnissen
-
Ihr Ordner für Protokolldateien
Möglicherweise müssen Sie zusätzliche Schritte unternehmen, um gespeicherte Dateien zu löschen, wenn Sie PySpark das Skript oder die Ausgabe an einem anderen Ort gespeichert haben.
Anmerkung
Ihr Cluster muss beendet werden, bevor Sie Ihren Bucket löschen können. Andernfalls dürfen Sie den Bucket möglicherweise nicht leeren.
Um Ihren Bucket zu löschen, befolgen Sie die Anweisungen unter Wie lösche ich einen S3-Bucket? im Benutzerhandbuch zu Amazon Simple Storage Service.
Nächste Schritte
Sie haben jetzt Ihren ersten Amazon-EMR-Cluster von Anfang bis Ende gestartet. Sie haben auch wichtige EMR-Aufgaben wie das Vorbereiten und Einreichen von Big-Data-Anwendungen, das Anzeigen von Ergebnissen und das Beenden eines Clusters erledigt.
Verwenden Sie die folgenden Themen, um mehr über zu erfahren, wie Sie Ihren Amazon-EMR-Workflow anpassen können.
Erkunden Sie Big-Data-Anwendungen für Amazon EMR
Entdecken und vergleichen Sie die Big-Data-Anwendungen, die Sie auf einem Cluster installieren können, im Amazon-EMR-Versionshandbuch. Der Versionshandbuch beschreibt jede EMR-Version und enthält Tipps zur Verwendung von Frameworks wie Spark und Hadoop auf Amazon EMR.
Planen Sie Cluster-Hardware, Netzwerke und Sicherheit
In diesem Tutorial haben Sie einen einfachen EMR-Cluster erstellt, ohne erweiterte Optionen zu konfigurieren. Mit den erweiterten Optionen können Sie Amazon-EC2-Instance-Typen, Cluster-Netzwerke und Cluster-Sicherheit angeben. Weitere Informationen zur Planung und Einführung eines Clusters, der Ihren Anforderungen entspricht, finden Sie unter Planung, Konfiguration und Start von Amazon EMR-Clustern und Sicherheit in Amazon EMR.
Verwalten von Clustern
Erfahren Sie mehr über die Arbeit mit laufenden Clustern unter Amazon EMR-Cluster verwalten. Um einen Cluster zu verwalten, können Sie eine Verbindung zum Cluster herstellen, Schritte debuggen und die Clusteraktivitäten und den Zustand verfolgen. Mit EMR-verwalteter Skalierung können Sie die Clusterressourcen auch an die Workload-Anforderungen anpassen.
Verwenden Sie eine andere Schnittstelle
Zusätzlich zur Amazon EMR-Konsole können Sie Amazon EMR mithilfe der AWS Command Line Interface Webservice-API oder eines der vielen unterstützten AWS SDKs verwalten. Weitere Informationen finden Sie unter Verwaltungsschnittstellen.
Sie können auch auf vielfältige Weise mit Anwendungen interagieren, die auf Amazon-EMR-Clustern installiert sind. Einige Anwendungen wie Apache Hadoop veröffentlichen Weboberflächen, die Sie sich ansehen können. Weitere Informationen finden Sie unter Anzeigen von auf Amazon-EMR-Clustern gehosteten Webschnittstellen.
Stöbern Sie im technischen Blog von EMR
Exemplarische Vorgehensweisen und ausführliche technische Diskussionen zu den neuen Amazon-EMR-Features finden Sie im AWS-Big-Data-Blog
