Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Aktivieren des Identitätswechsels zur Überwachung von Spark-Benutzer- und -Aufgabenaktivitäten
EMRNotebooks ermöglicht es Ihnen, den Benutzerwechsel auf einem Spark-Cluster zu konfigurieren. Mit dieser Funktion können Sie die Auftragsaktivität nachverfolgen, die innerhalb des Notebook-Editors initiiert wurde. Darüber hinaus verfügt EMR Notebooks über ein integriertes Jupyter Notebook-Widget, mit dem Sie die Spark-Jobdetails zusammen mit der Abfrageausgabe im Notebook-Editor anzeigen können. Das Widget ist standardmäßig verfügbar und erfordert keine spezielle Konfiguration. Um die Verlaufsserver anzeigen zu können, muss Ihr Client jedoch so konfiguriert sein, dass er EMR Amazon-Webschnittstellen anzeigt, die auf dem primären Knoten gehostet werden.
Anmerkung
EMRNotebooks sind in der Konsole als EMR Studio-Workspaces verfügbar. Mit der Schaltfläche „Arbeitsbereich erstellen“ in der Konsole können Sie neue Notizbücher erstellen. Um auf Workspaces zuzugreifen oder diese zu erstellen, benötigen EMR Notebook-Benutzer zusätzliche IAM Rollenberechtigungen. Weitere Informationen finden Sie unter Amazon EMR Notebooks sind Amazon EMR Studio-Workspaces in der Konsole und EMRAmazon-Konsole.
Einrichten der Spark-Benutzerkennung
Standardmäßig stammen Spark-Aufträge, die Benutzer mit dem Notebook-Editor übermitteln, scheinbar aus einer unbestimmten livy-Benutzeridentität. Sie können eine Benutzerkennung für den Cluster konfigurieren, damit diese Aufträge stattdessen mit der Benutzeridentität verknüpft werden, die den Code ausgeführt hat. HDFSBenutzerverzeichnisse auf dem primären Knoten werden für jede Benutzeridentität erstellt, die Code im Notizbuch ausführt. Beispiel: Wenn der Benutzer NbUser1 Code aus dem Notebook-Editor ausführt, können Sie eine Verbindung mit dem Primärknoten herstellen und sehen, dass hadoop fs -ls /user das Verzeichnis /user/user_NbUser1 zeigt.
Sie können diese Funktion aktivieren, indem Sie Eigenschaften in den Konfigurationsklassifizierungen core-site und livy-conf festlegen. Diese Funktion ist standardmäßig nicht verfügbar, wenn Sie Amazon einen Cluster zusammen mit einem Notizbuch EMR erstellen lassen. Weitere Informationen zur Verwendung von Konfigurationsklassifizierungen zur Anpassung von Anwendungen finden Sie unter Konfiguration von Anwendungen im Amazon EMR Release Guide.
Verwenden Sie die folgenden Konfigurationsklassifizierungen und Werte, um die Benutzeridentität für Notebooks zu aktivieren: EMR
[ { "Classification": "core-site", "Properties": { "hadoop.proxyuser.livy.groups": "*", "hadoop.proxyuser.livy.hosts": "*" } }, { "Classification": "livy-conf", "Properties": { "livy.impersonation.enabled": "true" } } ]
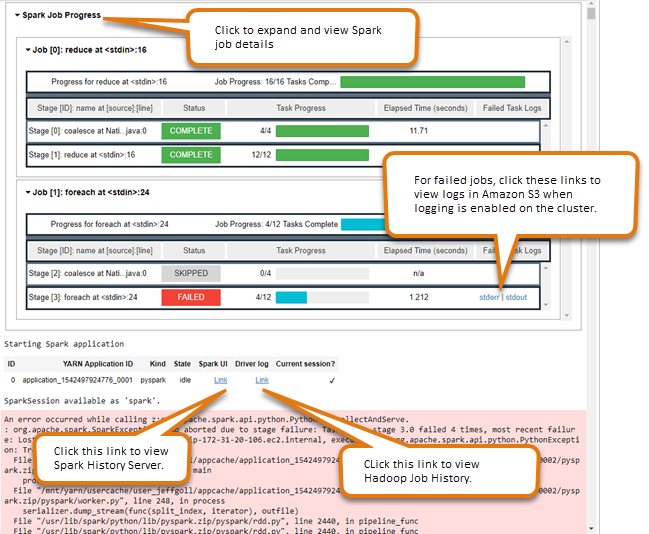
Verwenden des Spark-Widgets für die Auftragsüberwachung
Wenn Sie im Notebook-Editor Code ausführen, der Spark-Jobs auf dem EMR Cluster ausführt, enthält die Ausgabe ein Jupyter Notebook-Widget für die Spark-Jobüberwachung. Das Widget stellt Auftragsdetails, nützliche Links zur Spark-Verlaufsserverseite und zur Hadoop-Auftragsverlaufsseite sowie praktische Links zu Auftragsprotokollen in Amazon S3 für alle fehlgeschlagenen Aufträge bereit.
Um die Seiten des History-Servers auf dem primären Clusterknoten anzuzeigen, müssen Sie entsprechend einen SSH Client und einen Proxy einrichten. Weitere Informationen finden Sie unter Auf EMR Amazon-Clustern gehostete Weboberflächen anzeigen. Um Protokolle in Amazon S3 anzuzeigen, muss die Cluster-Protokollierung aktiviert sein. Dies ist die Standardeinstellung für neue Cluster. Weitere Informationen finden Sie unter In Amazon S3 archivierte Protokolldateien anzeigen.
Nachstehend finden Sie ein Beispiel für die Spark-Auftragsüberwachung.