Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Apache Spark Plugin
Amazon EMR hat integriert EMR RecordServer , um eine differenzierte Zugriffskontrolle für Spark bereitzustellen. SQL EMR's RecordServer ist ein privilegierter Prozess, der auf allen Knoten eines Apache Ranger-fähigen Clusters ausgeführt wird. Wenn ein Spark-Treiber oder -Executor eine SQL Spark-Anweisung ausführt, durchlaufen alle Metadaten und Datenanfragen den. RecordServer Weitere Informationen EMR RecordServer dazu finden Sie auf der EMRAmazon-Komponenten Seite.
Themen
Unterstützte Features
| SQLAuskunft/Aktion des Rangers | STATUS | Unterstützte Version EMR |
|---|---|---|
|
SELECT |
Unterstützt |
Ab 5.32 |
|
SHOW DATABASES |
Unterstützt |
Ab 5.32 |
|
SHOW COLUMNS |
Unterstützt |
Ab 5.32 |
|
SHOW TABLES |
Unterstützt |
Ab 5.32 |
|
SHOW TABLE PROPERTIES |
Unterstützt |
Ab 5.32 |
|
DESCRIBE TABLE |
Unterstützt |
Ab 5.32 |
|
INSERT OVERWRITE |
Unterstützt |
Ab 5.34 und 6.4 |
| INSERT INTO | Unterstützt | Ab 5.34 und 6.4 |
|
ALTER TABLE |
Unterstützt |
Ab 6.4 |
|
CREATE TABLE |
Unterstützt |
Ab 5.35 und 6.7 |
|
CREATE DATABASE |
Unterstützt |
Ab 5.35 und 6.7 |
|
DROP TABLE |
Unterstützt |
Ab 5.35 und 6.7 |
|
DROP DATABASE |
Unterstützt |
Ab 5.35 und 6.7 |
|
DROP VIEW |
Unterstützt |
Ab 5.35 und 6.7 |
|
CREATE VIEW |
Nicht unterstützt |
Die folgenden Funktionen werden bei der Verwendung von Spark unterstütztSQL:
-
Eine detaillierte Zugriffskontrolle für Tabellen im Hive-Metastore und Richtlinien können auf Datenbank-, Tabellen- und Spaltenebene erstellt werden.
-
Die Richtlinien von Apache Ranger können Richtlinien für die Gewährung und die Ablehnung von Benutzern und Gruppen beinhalten.
-
Prüfereignisse werden an CloudWatch Logs übermittelt.
Stellen Sie die Servicedefinition erneut bereit, um Anweisungen INSERTALTER, oder DDL zu verwenden
Anmerkung
Ab Amazon EMR 6.4 können Sie Spark SQL mit den Anweisungen: INSERT INTO INSERTOVERWRITE, oder verwenden ALTERTABLE. Ab Amazon EMR 6.7 können Sie Spark verwenden, SQL um Datenbanken und Tabellen zu erstellen oder zu löschen. Wenn Sie bereits über eine Installation auf dem Apache Ranger-Server mit bereitgestellten Apache Spark-Servicedefinitionen verfügen, verwenden Sie den folgenden Code, um die Servicedefinitionen erneut bereitzustellen.
# Get existing Spark service definition id calling Ranger REST API and JSON processor curl --silent -f -u<admin_user_login>:<password_for_ranger_admin_user>\ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -k 'https://*<RANGER SERVER ADDRESS>*:6182/service/public/v2/api/servicedef/name/amazon-emr-spark' | jq .id # Download the latest Service definition wget https://s3.amazonaws.com/elasticmapreduce/ranger/service-definitions/version-2.0/ranger-servicedef-amazon-emr-spark.json # Update the service definition using the Ranger REST API curl -u<admin_user_login>:<password_for_ranger_admin_user>-X PUT -d @ranger-servicedef-amazon-emr-spark.json \ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -k 'https://*<RANGER SERVER ADDRESS>*:6182/service/public/v2/api/servicedef/<Spark service definition id from step 1>'
Installation der Servicedefinition
Für die Installation EMR der Apache Spark-Servicedefinition muss der Ranger Admin-Server eingerichtet werden. Siehe Richten Sie den Ranger-Admin-Server ein.
Gehen Sie wie folgt vor, um die Apache-Spark-Servicedefinition zu installieren:
Schritt 1: SSH In den Apache Ranger Admin-Server
Beispielsweise:
ssh ec2-user@ip-xxx-xxx-xxx-xxx.ec2.internal
Schritt 2: Die Servicedefinition und das Apache-Ranger-Admin-Server-Plugin herunterladen
Laden Sie die Servicedefinition in einem temporären Verzeichnis herunter. Diese Servicedefinition wird von Ranger-2.x-Versionen unterstützt.
mkdir /tmp/emr-spark-plugin/ cd /tmp/emr-spark-plugin/ wget https://s3.amazonaws.com/elasticmapreduce/ranger/service-definitions/version-2.0/ranger-spark-plugin-2.x.jar wget https://s3.amazonaws.com/elasticmapreduce/ranger/service-definitions/version-2.0/ranger-servicedef-amazon-emr-spark.json
Schritt 3: Installieren Sie das Apache Spark-Plugin für Amazon EMR
export RANGER_HOME=.. # Replace this Ranger Admin's home directory eg /usr/lib/ranger/ranger-2.0.0-admin mkdir $RANGER_HOME/ews/webapp/WEB-INF/classes/ranger-plugins/amazon-emr-spark mv ranger-spark-plugin-2.x.jar $RANGER_HOME/ews/webapp/WEB-INF/classes/ranger-plugins/amazon-emr-spark
Schritt 4: Registrieren Sie die Apache Spark-Servicedefinition für Amazon EMR
curl -u *<admin users login>*:*_<_**_password_ **_for_** _ranger admin user_**_>_* -X POST -d @ranger-servicedef-amazon-emr-spark.json \ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -k 'https://*<RANGER SERVER ADDRESS>*:6182/service/public/v2/api/servicedef'
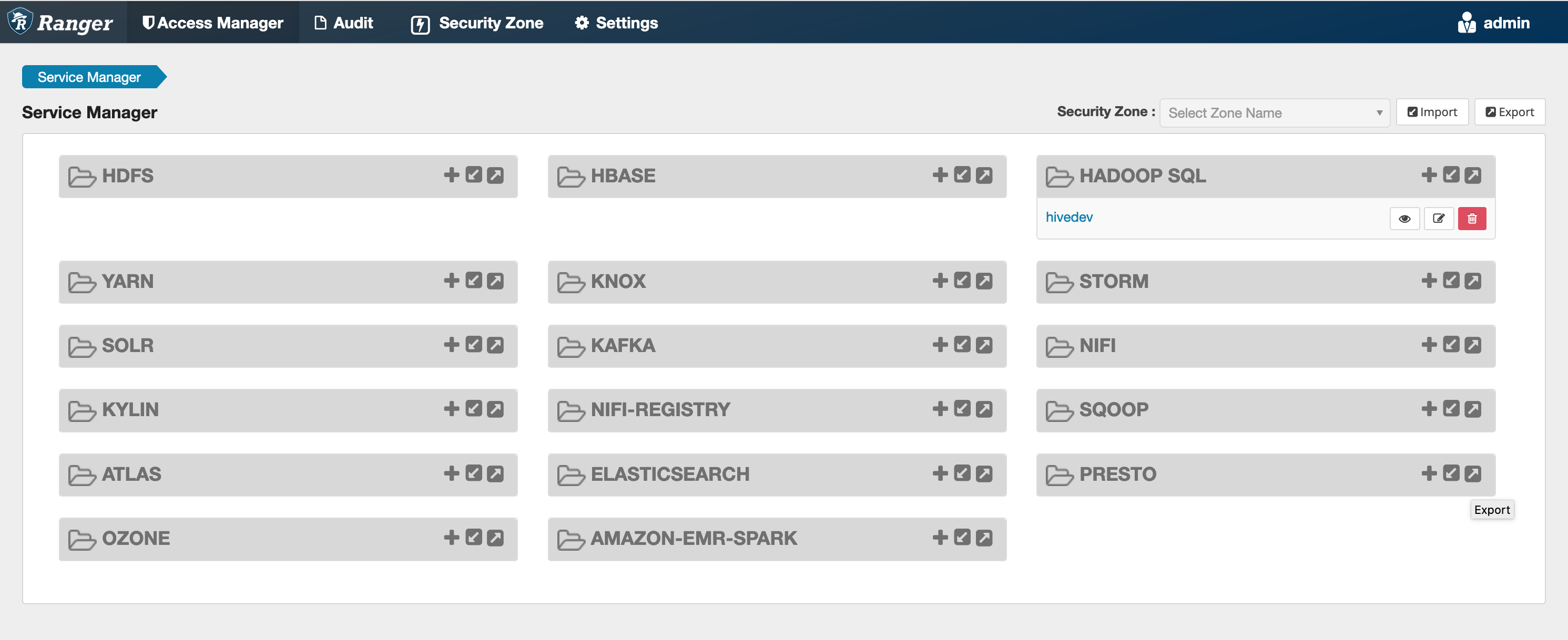
Wenn dieser Befehl erfolgreich ausgeführt wird, sehen Sie in Ihrer Ranger-Admin-Benutzeroberfläche einen neuen Dienst namens "AMAZON- EMR - SPARK „, wie in der folgenden Abbildung gezeigt (Ranger-Version 2.0 wird gezeigt).
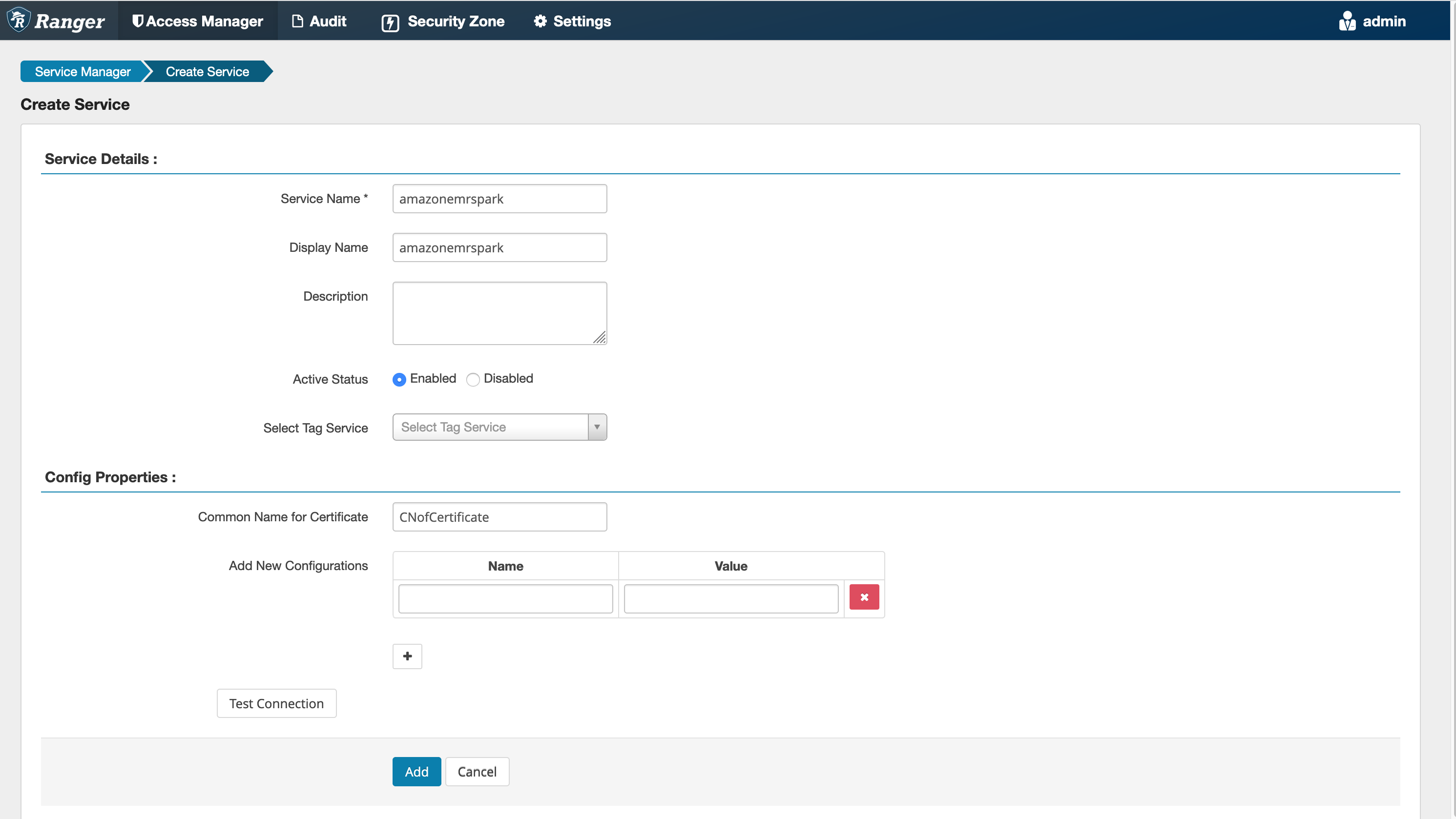
Schritt 5: Erstellen Sie eine Instanz der AMAZON - EMR - SPARK -Anwendung
Servicename (falls angezeigt): Der Servicename, der verwendet wird. Der vorgeschlagene Wert ist amazonemrspark. Notieren Sie sich diesen Dienstnamen, da er bei der Erstellung einer EMR Sicherheitskonfiguration benötigt wird.
Anzeigename: Der Name, der für diese Instance angezeigt werden soll. Der vorgeschlagene Wert ist amazonemrspark.
Allgemeiner Name für das Zertifikat: Das CN-Feld innerhalb des Zertifikats, das verwendet wird, um von einem Client-Plugin aus eine Verbindung zum Admin-Server herzustellen. Dieser Wert muss mit dem CN-Feld in Ihrem TLS Zertifikat übereinstimmen, das für das Plugin erstellt wurde.
Anmerkung
Das TLS Zertifikat für dieses Plugin sollte im Trust Store auf dem Ranger Admin-Server registriert worden sein. Weitere Details finden Sie unter TLSZertifikate.
SQLSpark-Richtlinien erstellen
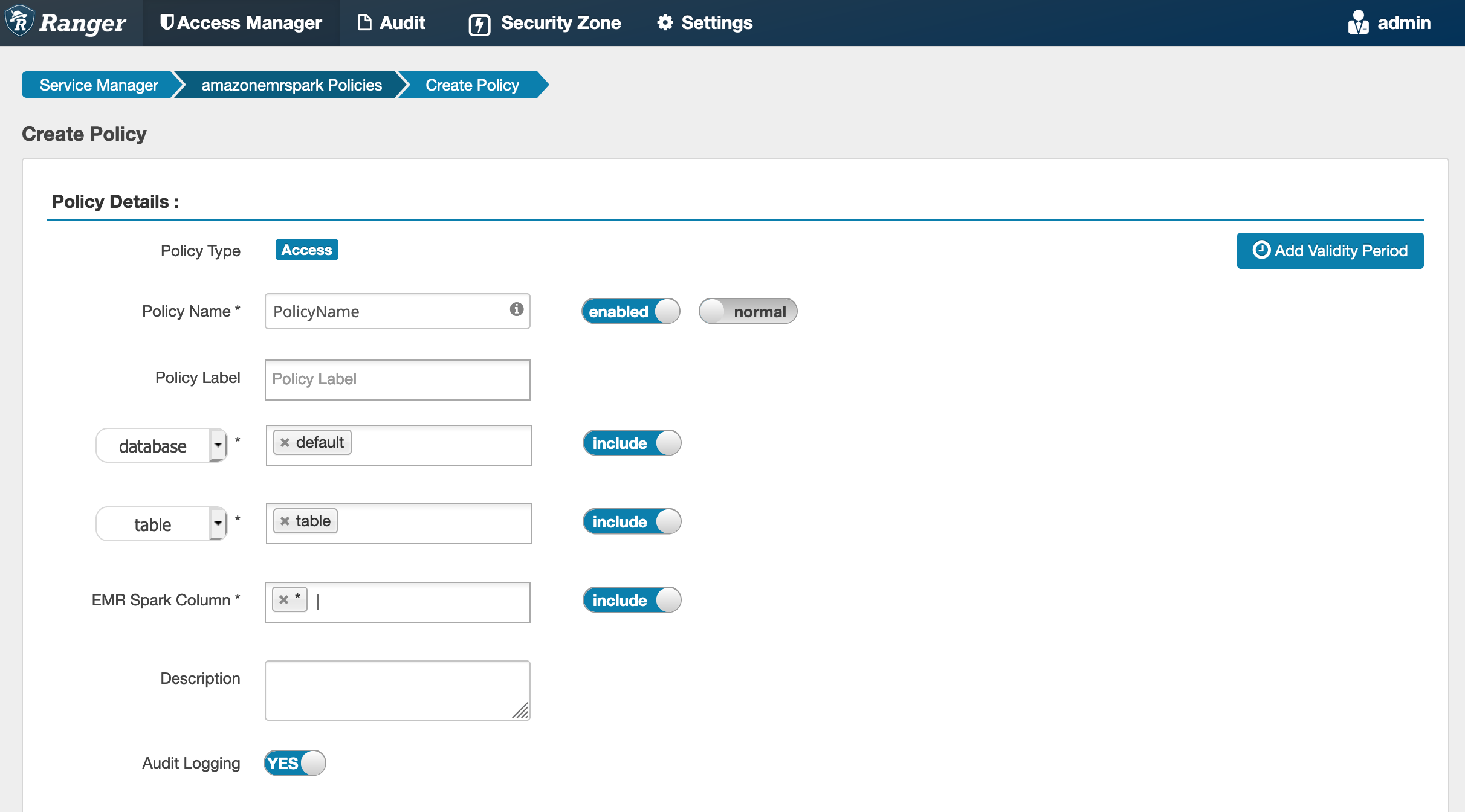
Beim Erstellen einer neuen Richtlinie müssen folgende Felder ausgefüllt werden:
Richtlinienname: Der Name dieser Richtlinie.
Richtlinienbezeichnung: Eine Bezeichnung, die Sie dieser Richtlinie hinzufügen können.
Datenbank: Die Datenbank, für die diese Richtlinie gilt. Der Platzhalter „*“ steht für alle Tabellen.
Tabelle: Die Tabellen, für die diese Richtlinie gilt. Der Platzhalter „*“ steht für alle Tabellen.
EMRSpark-Spalte: Die Spalten, für die diese Richtlinie gilt. Der Platzhalter „*“ steht für alle Spalten.
Beschreibung: Eine Beschreibung dieser Richtlinie.
Um die Benutzer und Gruppen anzugeben, geben Sie die Benutzer und Gruppen unten ein, um Berechtigungen zu erteilen. Sie können auch Ausnahmen für die Bedingungen Zulassen und Verweigern angeben.
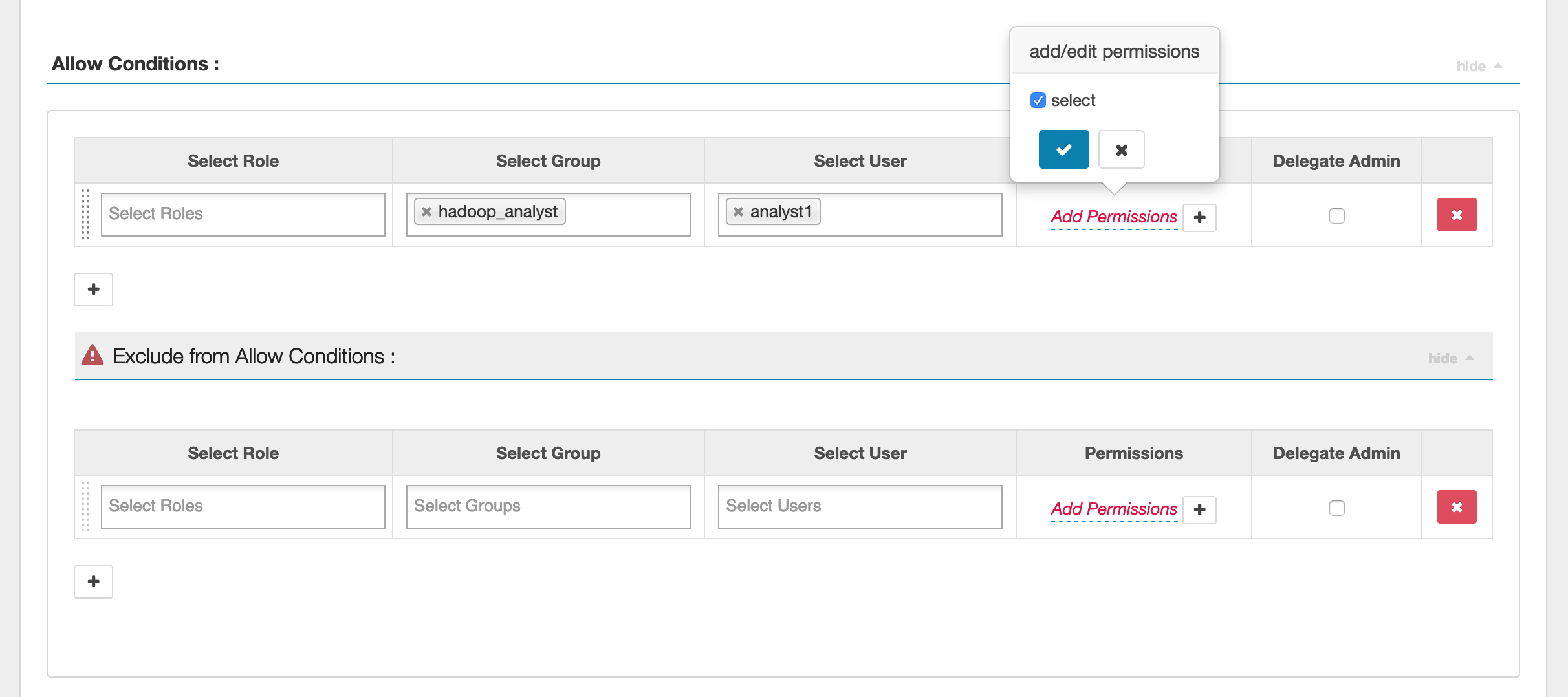
Nachdem Sie die Bedingungen für das Zulassen und Verweigern angegeben haben, klicken Sie auf Speichern.
Überlegungen
Jeder Knoten innerhalb des EMR Clusters muss in der Lage sein, eine Verbindung zum Hauptknoten auf Port 9083 herzustellen.
Einschränkungen
Die folgenden Einschränkungen gelten derzeit für das Apache-Spark-Plugin:
-
Der Record Server stellt immer eine Verbindung zur HMS Ausführung auf einem EMR Amazon-Cluster her. Konfigurieren HMS Sie bei Bedarf die Verbindung zum Remote-Modus. Sie sollten keine Konfigurationswerte in die Apache-Spark-Konfigurationsdatei Hive-site.xml einfügen.
-
Tabellen, die mit Spark-Datenquellen auf CSV oder Avro erstellt wurden, können mit nicht gelesen werden. EMR RecordServer Verwenden Sie Hive, um Daten zu erstellen und zu schreiben, und lesen Sie sie mit Record.
-
Delta Lake- und Hudi-Tabellen werden nicht unterstützt.
-
Benutzer müssen Zugriff auf die Standarddatenbank haben. Dies ist eine Voraussetzung für Apache Spark.
-
Der Ranger-Admin-Server unterstützt die automatische Vervollständigung nicht.
-
Das SQL Spark-Plugin für Amazon unterstützt EMR keine Zeilenfilter oder Datenmaskierung.
-
Bei der Verwendung ALTER TABLE mit Spark SQL muss ein Partitionsspeicherort das untergeordnete Verzeichnis einer Tabellenposition sein. Das Einfügen von Daten in eine Partition, deren Partitionsspeicherort sich von der Tabellenposition unterscheidet, wird nicht unterstützt.
