Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Debuggen von Anwendungen und Aufträgen mit EMR Studio
Mit Amazon EMR Studio können Sie Datenanwendungsschnittstellen starten, um Anwendungen und Auftragsausführungen im Browser zu analysieren.
Sie können die persistenten Benutzeroberflächen außerhalb des Clusters für Amazon EMR, die auf EC2-Clustern ausgeführt werden, auch von der Amazon-EMR-Konsole aus starten. Weitere Informationen finden Sie unter Persistente Anwendungsbenutzeroberflächen in Amazon EMR anzeigen.
Abhängig von Ihren Browsereinstellungen müssen Sie möglicherweise Popups aktivieren, damit die Benutzeroberfläche einer Anwendung geöffnet werden kann.
Informationen zum Konfigurieren und Verwenden der Anwendungsschnittstellen finden Sie unter YARN Timeline Server, Überwachung und Instrumentierung oder Tez-UI-Übersicht.
Debuggen von Amazon EMR, das in Amazon-EC2-Aufträgen ausgeführt wird
- Workspace UI
-
Starten Sie eine Cluster-Benutzeroberfläche aus einer Notebook-Datei
Wenn Sie die Amazon-EMR-Release-Versionen 5.33.0 und höher verwenden, können Sie die Spark-Webbenutzeroberfläche (die Spark-Benutzeroberfläche oder den Spark History Server) von einem Notebook in Ihrem Workspace aus starten.
On-cluster Benutzeroberflächen funktionieren mit den Kernel PySpark, Spark oder SparkR. Die maximale sichtbare Dateigröße für Spark-Event- oder Container-Logs beträgt 10 MB. Wenn Ihre Protokolldateien 10 MB überschreiten, empfehlen wir Ihnen, zum Debuggen von Jobs den persistenten Spark History Server anstelle der Cluster-internen Spark-Benutzeroberfläche zu verwenden.
Damit EMR Studio Benutzeroberflächen für Cluster-Anwendungen von einem Workspace aus starten kann, muss ein Cluster in der Lage sein, mit dem Amazon API Gateway zu kommunizieren. Sie müssen den EMR-Cluster so konfigurieren, dass ausgehender Netzwerkverkehr zu Amazon API Gateway zugelassen wird, und sicherstellen, dass Amazon API Gateway vom Cluster aus erreichbar ist.
Die Spark-Benutzeroberfläche greift auf Container-Logs zu, indem sie Hostnamen auflöst. Wenn Sie einen benutzerdefinierten Domainnamen verwenden, müssen Sie sicherstellen, dass die Hostnamen Ihrer Clusterknoten von Amazon DNS oder dem von Ihnen angegebenen DNS-Server aufgelöst werden können. Stellen Sie dazu die Dynamic Host Configuration Protocol (DHCP)-Optionen für die Amazon Virtual Private Cloud (VPC) ein, die Ihrem Cluster zugeordnet ist. Weitere Informationen zu DHCP-Optionen finden Sie unter DHCP-Optionssätze im Amazon-Virtual-Private-Cloud-Benutzerhandbuch.
-
Öffnen Sie in Ihrem EMR Studio den Workspace, den Sie verwenden möchten, und stellen Sie sicher, dass er mit einem Amazon-EMR-Cluster verbunden ist, der auf EC2 ausgeführt wird. Detaillierte Anweisungen finden Sie unter Einen Computer an einen EMR Studio Workspace anhängen.
-
Öffnen Sie eine Notebook-Datei und verwenden Sie den PySpark, Spark- oder SparkR-Kernel. Um einen Kernel auszuwählen, wählen Sie den Kernel-Namen oben rechts in der Notebook-Symbolleiste, um das Dialogfeld Kernel auswählen zu öffnen. Der Name erscheint als Kein Kernel! wenn kein Kernel ausgewählt wurde.
-
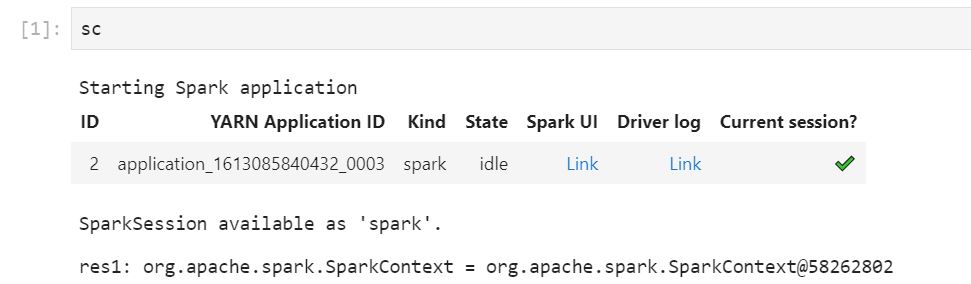
Führen Sie Ihren Notebook-Code aus. Folgendes wird als Ausgabe im Notebook angezeigt, wenn Sie den Spark-Kontext starten. Es kann einige Sekunden dauern, bis es angezeigt wird. Wenn Sie den Spark-Kontext gestartet haben, können Sie den %%info-Befehl ausführen, um jederzeit auf einen Link zur Spark-Benutzeroberfläche zuzugreifen.
Wenn die Spark-UI-Links nicht funktionieren oder nach einigen Sekunden nicht angezeigt werden, erstellen Sie eine neue Notebook-Zelle und führen Sie den %%info-Befehl aus, um die Links neu zu generieren.
-
Um die Spark-Benutzeroberfläche zu starten, wählen Sie Link unter Spark-Benutzeroberfläche. Wenn Ihre Spark-Anwendung ausgeführt wird, wird die Spark-Benutzeroberfläche in einer neuen Registerkarte geöffnet. Wenn die Anwendung abgeschlossen ist, wird stattdessen der Spark History Server geöffnet.
Nachdem Sie die Spark-Benutzeroberfläche gestartet haben, können Sie die URL im Browser ändern, um den YARN ResourceManager - oder den Yarn Timeline Server zu öffnen. Fügen Sie nach amazonaws.com einen der folgenden Pfade hinzu.
| Web-Benutzeroberfläche |
Pfad |
Beispiel für eine geänderte URL |
| GARN ResourceManager |
/rm |
https://j-examplebby5ij.emrappui-prod. eu-west-1.amazonaws.com /rm |
| Yarn-Timeline-Server |
/yts |
https://.emrappui-prod. j-examplebby5ij eu-west-1.amazonaws.com /yts |
| Spark History Server |
/shs |
https://.emrappui-prod. j-examplebby5ij eu-west-1.amazonaws.com /shs
|
- Studio UI
-
Starten Sie den persistenten YARN Timeline Server, Spark History Server oder Tez UI über die EMR-Studio-Benutzeroberfläche
-
Wählen Sie in Ihrem EMR Studio links auf der Seite Amazon EMR in EC2 aus, um die Liste der Cluster von Amazon EMR in EC2 zu öffnen.
-
Filtern Sie die Clusterliste nach Name, Status oder ID, indem Sie Werte in das Suchfeld eingeben. Sie können auch nach Erstellungszeitraum suchen.
-
Wählen Sie einen Cluster aus und klicken Sie dann auf Anwendungsbenutzeroberflächen starten, um eine Anwendungsbenutzeroberfläche auszuwählen. Die Anwendungsbenutzeroberfläche wird in einer neuen Browser-Registerkarte geöffnet. Es kann einige Zeit dauern, bis sie geladen wird.
Debuggen Sie EMR Studio, das auf EMR Serverless läuft
Ähnlich wie Amazon EMR, das auf Amazon EC2 läuft, können Sie die Workspace-Benutzeroberfläche verwenden, um Ihre EMR-Serverless-Anwendungen zu analysieren. Wenn Sie Amazon-EMR-Versionen 6.14.0 und höher verwenden, können Sie von der Workspace-Benutzeroberfläche aus die Spark-Webbenutzeroberfläche (die Spark-Benutzeroberfläche oder den Spark History Server) von einem Notebook in Ihrem Workspace aus starten. Der Einfachheit halber stellen wir auch einen Link zum Treiberprotokoll zur Verfügung, über den Sie schnell auf die Spark-Treiberprotokolle zugreifen können.
Debuggen Sie Amazon EMR in EKS-Auftragsausführungen mit dem Spark History Server
Wenn Sie eine Auftragsausführung an einen Amazon EMR in EKS-Cluster senden, können Sie über den Spark History Server auf die Protokolle für diese Auftragsausführung zugreifen. Der Spark History Server bietet Tools zur Überwachung von Spark-Anwendungen, z. B. eine Liste von Scheduler-Phasen und -aufgaben, eine Zusammenfassung der RDD-Größen und der Speichernutzung sowie Umgebungsinformationen. Sie können den Spark History Server für Amazon EMR in EKS-Auftragsläufe auf folgende Weise starten:
-
Wenn Sie einen Auftrag einreichen, der mit EMR Studio und einem von Amazon EMR auf EKS verwalteten Endpunkt ausgeführt wird, können Sie den Spark History Server von einer Notebook-Datei in Ihrem Workspace aus starten.
-
Wenn Sie einen Job einreichen, der mit dem AWS CLI oder AWS SDK für Amazon EMR auf EKS ausgeführt wird, können Sie den Spark History Server über die EMR Studio-Benutzeroberfläche starten.
Informationen zur Verwendung des Spark History Servers finden Sie unter Überwachung und Instrumentierung in der Apache-Spark-Dokumentation. Weitere Informationen zu Auftragsausführungen finden Sie unter Konzepte und Komponenten im Entwicklerhandbuch zu Amazon EMR in EKS.
So starten Sie den Spark History Server aus einer Notebook-Datei in Ihrem EMR Studio Workspace
-
Öffnen Sie einen Workspace, der mit einem Amazon EMR in EKS-Cluster verbunden ist.
-
Wählen Sie Ihre Notebook-Datei aus und öffnen Sie sie im Workspace.
-
Wählen Sie oben in der Notebook-Datei die Spark-Benutzeroberfläche, um den persistenten Spark-Geschichtsserver in einer neuen Registerkarte zu öffnen.
So starten Sie den Spark History Server über die EMR-Studio-Benutzeroberfläche
In der Jobliste in der EMR Studio-Benutzeroberfläche werden nur Jobausführungen angezeigt, die Sie mit dem AWS CLI oder AWS SDK für Amazon EMR auf EKS einreichen.
-
Wählen Sie in Ihrem EMR Studio links auf der Seite Amazon EMR in EKS aus.
-
Suchen Sie nach dem virtuellen Amazon EMR in EKS-Cluster, mit dem Sie Ihre Auftragsausführung eingereicht haben. Sie können die Liste der Cluster nach Status oder ID filtern, indem Sie Werte in das Suchfeld eingeben.
-
Wählen Sie den Cluster aus, um seine Detailseite zu öffnen. Auf der Detailseite werden Informationen über den Cluster wie ID, Namespace und Status angezeigt. Auf der Seite wird auch eine Liste aller Auftragsausführungen angezeigt, die an diesen Cluster übermittelt wurden.
-
Wählen Sie auf der Cluster-Detailseite einen Auftrag aus, der debuggt werden soll.
-
Wählen Sie oben rechts in der Auftragsliste die Option Spark History Server starten, um die Anwendungsoberfläche in einer neuen Browser-Registerkarte zu öffnen.