Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Leistung von Amazon FSx for Lustre
Dieses Kapitel enthält Themen zur Leistung von Amazon FSx for Lustre, einschließlich einiger wichtiger Tipps und Empfehlungen zur Maximierung der Leistung Ihres Dateisystems.
Themen
-Übersicht
Amazon FSx for Lustre basiert auf dem Lustre beliebten Hochleistungsdateisystem und bietet Scale-Out-Leistung, die linear mit der Größe eines Dateisystems zunimmt. LustreDateisysteme lassen sich horizontal auf mehrere Dateiserver und Festplatten skalieren. Durch diese Skalierung erhält jeder Client direkten Zugriff auf die auf den einzelnen Festplatten gespeicherten Daten, wodurch viele der in herkömmlichen Dateisystemen vorhandenen Engpässe beseitigt werden. Amazon FSx for Lustre baut auf der Lustre skalierbaren Architektur auf, um ein hohes Leistungsniveau bei einer großen Anzahl von Kunden zu unterstützen.
So funktionieren FSx for Lustre-Dateisysteme
Jedes FSx for Lustre-Dateisystem besteht aus den Dateiservern, mit denen die Clients kommunizieren, und einem Satz von Festplatten, die an jeden Dateiserver angeschlossen sind und Ihre Daten speichern. Jeder Dateiserver verwendet einen schnellen In-Memory-Cache, um die Leistung für die am häufigsten aufgerufenen Daten zu verbessern. Je nach Speicherklasse kann Ihr Dateiserver mit einem optionalen SSD-Lesecache ausgestattet werden. Wenn ein Client auf Daten zugreift, die im In-Memory- oder SSD-Cache gespeichert sind, muss der Dateiserver sie nicht von der Festplatte lesen, was die Latenz reduziert und den Gesamtdurchsatz erhöht, den Sie steuern können. Das folgende Diagramm zeigt die Pfade eines Schreibvorgangs, eines Lesevorgangs, der von der Festplatte aus ausgeführt wird, und eines Lesevorgangs, der über den Arbeitsspeicher oder den SSD-Cache ausgeführt wird.
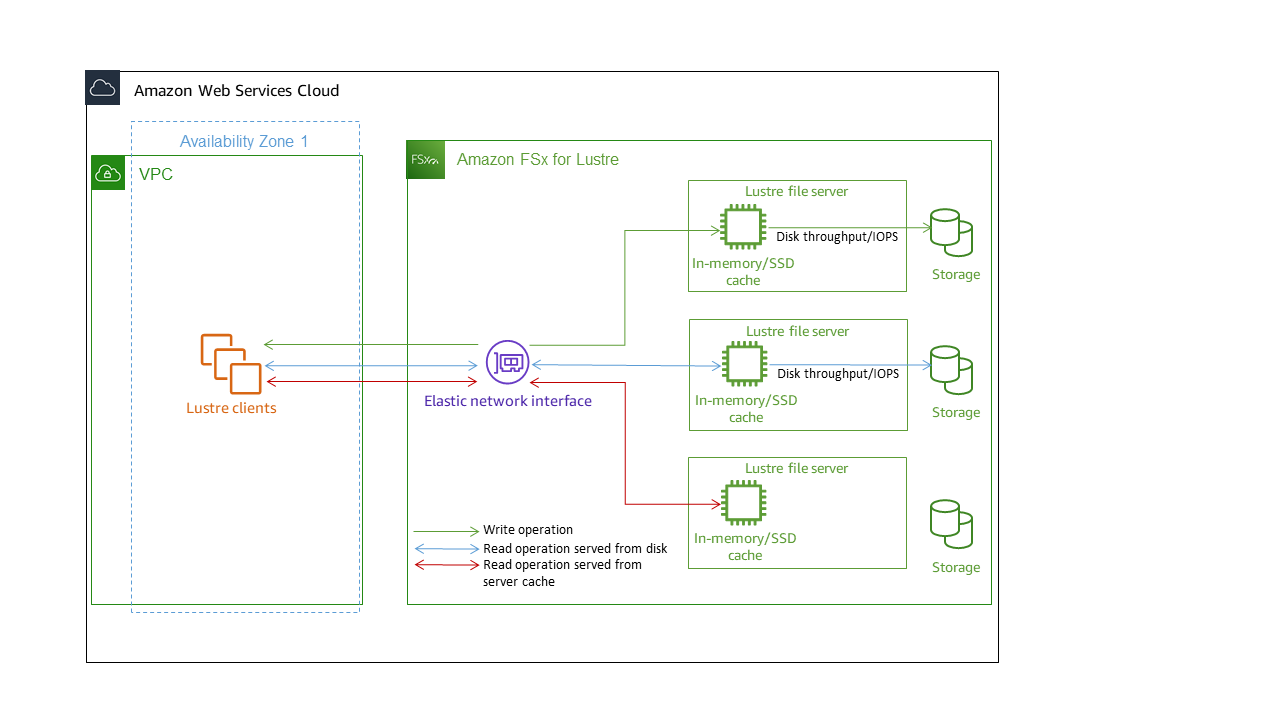
Wenn Sie Daten lesen, die im Arbeitsspeicher- oder SSD-Cache des Dateiservers gespeichert sind, wird die Leistung des Dateisystems durch den Netzwerkdurchsatz bestimmt. Wenn Sie Daten in Ihr Dateisystem schreiben oder wenn Sie Daten lesen, die nicht im In-Memory-Cache gespeichert sind, wird die Leistung des Dateisystems durch den jeweils niedrigeren Wert des Netzwerkdurchsatzes und des Festplattendurchsatzes bestimmt.
Weitere Informationen über den Netzwerkdurchsatz, den Festplattendurchsatz und die IOPS-Eigenschaften von SSD- und HDD-Speicherklassen finden Sie unter Leistungsmerkmale der SSD- und HDD-Speicherklassen und. Intelligent-Tiering Leistungsmerkmale der Speicherklasse
Leistung der Metadaten des Dateisystems
I/O-Operationen pro Sekunde (IOPS) für Dateisystem-Metadaten bestimmen die Anzahl der Dateien und Verzeichnisse, die Sie pro Sekunde erstellen, auflisten, lesen und löschen können.
Persistent 2-Dateisysteme ermöglichen es Ihnen, Metadaten-IOPS unabhängig von der Speicherkapazität bereitzustellen und bieten einen besseren Einblick in die Anzahl und Art der Metadaten-IOPS-Client-Instances, die in Ihrem Dateisystem ausgeführt werden. Bei SSD-Dateisystemen werden Metadaten-IOPS automatisch auf der Grundlage der von Ihnen bereitgestellten Speicherkapazität bereitgestellt. Der automatische Modus wird auf Intelligent-Tiering Dateisystemen nicht unterstützt.
Bei FSx for Lustre Persistent 2-Dateisystemen bestimmen die Anzahl der von Ihnen bereitgestellten Metadaten-IOPS und die Art des Metadatenvorgangs die Rate der Metadatenoperationen, die Ihr Dateisystem unterstützen kann. Die Ebene der von Ihnen bereitgestellten Metadaten-IOPS bestimmt die Anzahl der IOPS, die für die Metadaten-Festplatten Ihres Dateisystems bereitgestellt werden.
| Art des Vorgangs | Vorgänge, die Sie pro Sekunde für jede bereitgestellte Metadaten-IOPS ausführen können |
|---|---|
|
Datei erstellen, öffnen und schließen |
2 |
|
Datei löschen |
1 |
|
Verzeichnis erstellen, umbenennen |
0.1 |
|
Verzeichnis löschen |
0.2 |
Für SSD-Dateisysteme können Sie festlegen, dass Metadaten-IOPS im automatischen Modus bereitgestellt werden soll. Im automatischen Modus stellt Amazon FSx automatisch Metadaten-IOPS basierend auf der Speicherkapazität Ihres Dateisystems gemäß der folgenden Tabelle bereit:
| Speicherkapazität des Dateisystems | Inklusive Metadaten-IOPS im automatischen Modus |
|---|---|
|
1200 GiB |
1500 |
|
2400 GiB |
3000 |
|
4800—9600 GiB |
6 000 |
|
12000—456,00 GiB |
12000 |
|
≥48000 GiB |
12000 IOPS pro 24000 GiB |
Im User-provisioned Modus können Sie optional die Anzahl der bereitzustellenden Metadaten-IOPS angeben. Gültige Werte sind:
Für SSD-Dateisysteme sind die Werte
1500,,3000600012000, und Vielfaches von12000bis zu einem Maximum von gültig.192000Für Intelligent-Tiering Dateisysteme sind die Werte
6000und12000gültig.
Informationen zur Konfiguration von Metadaten-IOPS finden Sie unterVerwaltung der Metadaten-Performance. Beachten Sie, dass Sie für Metadaten-IOPS zahlen, die über der Standardanzahl an Metadaten-IOPS für Ihr Dateisystem bereitgestellt werden.
Durchsatz für einzelne Client-Instanzen
Wenn Sie ein Dateisystem mit einer Durchsatzkapazität von über 10 Gbit/s erstellen, empfehlen wir, den Elastic Fabric Adapter (EFA) zu aktivieren, um den Durchsatz pro Client-Instance zu optimieren. Um den Durchsatz pro Client-Instance weiter zu optimieren, unterstützen EFA-enabled Dateisysteme auch GPUDirect Storage für EFA-enabled GPU-based NVIDIA-Client-Instances und ENA Express für ENA-Client-Instances. Express-enabled
Der Durchsatz, den Sie einer einzelnen Client-Instance zuweisen können, hängt von der Wahl des Dateisystemtyps und der Netzwerkschnittstelle auf Ihrer Client-Instance ab.
| Typ des Dateisystems | Netzwerkschnittstelle der Client-Instanz | Maximaler Durchsatz pro Client, Gbit/s |
|---|---|---|
|
Nicht EFA-enabled |
Beliebig |
100 Gbit/s* |
|
EFA-enabled |
ENA |
100 Gbit/s* |
|
EFA-enabled |
ENA Express |
100 Gbit/s |
|
EFA-enabled |
EFA |
700 Gbit/s |
|
EFA-enabled |
EFA mit GDS |
1200 Gbit/s |
Anmerkung
* Der Datenverkehr zwischen einer einzelnen Client-Instanz und einem einzelnen FSx for Lustre-Objektspeicherserver ist auf 5 Gbit/s begrenzt. Die Anzahl der Object Storage-Server, die Ihrem FSx IP-Adressen für Dateisysteme for Lustre-Dateisystem zugrunde liegen, finden Sie unter.
Speicherlayout des Dateisystems
Alle Lustre darin enthaltenen Dateidaten werden auf Speichervolumes gespeichert, die als Object Storage Targets (OSTs) bezeichnet werden. Alle Dateimetadaten (einschließlich Dateinamen, Zeitstempel, Berechtigungen und mehr) werden auf Speichervolumes gespeichert, die als Metadatenziele (MDTs) bezeichnet werden. Amazon FSx for Lustre-Dateisysteme bestehen aus einem oder mehreren MDTs und mehreren OSTs. Amazon FSx for Lustre verteilt Ihre Dateidaten auf die OSTs, aus denen Ihr Dateisystem besteht, um die Speicherkapazität mit dem Durchsatz und der IOPS-Auslastung in Einklang zu bringen.
Um die Speichernutzung der MDT- und OSTs zu überprüfen, aus denen Ihr Dateisystem besteht, führen Sie den folgenden Befehl von einem Client aus, auf dem das Dateisystem gemountet ist.
lfs df -hmount/path
Die Ausgabe dieses Befehls sieht wie folgt aus:
Beispiel
UUID bytes Used Available Use% Mounted onmountname-MDT0000_UUID 68.7G 5.4M 68.7G 0% /fsx[MDT:0]mountname-OST0000_UUID 1.1T 4.5M 1.1T 0% /fsx[OST:0]mountname-OST0001_UUID 1.1T 4.5M 1.1T 0% /fsx[OST:1] filesystem_summary: 2.2T 9.0M 2.2T 0% /fsx
Daten in Ihrem Dateisystem entfernen
Mit File-Striping können Sie die Durchsatzleistung Ihres Dateisystems optimieren. Amazon FSx for Lustre verteilt Dateien automatisch auf alle OSTs, um sicherzustellen, dass Daten von allen Speicherservern bereitgestellt werden. Sie können dasselbe Konzept auf Dateiebene anwenden, indem Sie konfigurieren, wie Dateien auf mehrere OSTs verteilt werden.
Striping bedeutet, dass Dateien in mehrere Blöcke aufgeteilt werden können, die dann auf verschiedenen OSTs gespeichert werden. Wenn eine Datei über mehrere OSTs verteilt wird, werden Lese- oder Schreibanforderungen an die Datei auf diese OSTs verteilt, wodurch der Gesamtdurchsatz oder die IOPS, die Ihre Anwendungen verarbeiten können, erhöht wird.
Im Folgenden sind die Standardlayouts für Amazon FSx for Lustre-Dateisysteme aufgeführt.
Für Dateisysteme, die vor dem 18. Dezember 2020 erstellt wurden, gibt das Standardlayout eine Stripe-Anzahl von 1 an. Das bedeutet, dass, sofern kein anderes Layout angegeben ist, jede Datei, die in Amazon FSx for Lustre mit Standard-Linux-Tools erstellt wurde, auf einer einzigen Festplatte gespeichert wird.
Für Dateisysteme, die nach dem 18. Dezember 2020 erstellt wurden, ist das Standardlayout ein progressives Dateilayout, bei dem Dateien mit einer Größe von weniger als 1 GiB in einem Stripe gespeichert werden und größeren Dateien eine Stripe-Anzahl von 5 zugewiesen wird.
Für Dateisysteme, die nach dem 25. August 2023 erstellt wurden, ist das Standardlayout ein progressives 4-Komponenten-Dateilayout, das unter erklärt wird. Progressive Datei-Layouts
Für alle Dateisysteme, unabhängig von ihrem Erstellungsdatum, verwenden aus Amazon S3 importierte Dateien nicht das Standardlayout, sondern das Layout im
ImportedFileChunkSizeDateisystemparameter. S3-imported Dateien, die größer als die sind,ImportedFileChunkSizewerden auf mehreren OSTs mit einer Stripe-Anzahl von(FileSize / ImportedFileChunksize) + 1gespeichert. Der Standardwert vonImportedFileChunkSizeist 1 GiB.
Sie können die Layoutkonfiguration einer Datei oder eines Verzeichnisses mit dem lfs getstripe Befehl anzeigen.
lfs getstripepath/to/filename
Dieser Befehl meldet die Anzahl der Stripes, die Stripe-Größe und den Stripe-Offset einer Datei. Die Streifenanzahl gibt an, über wie viele OSTs die Datei gestreift ist. Die Stripe-Größe gibt an, wie viele kontinuierliche Daten auf einem OST gespeichert sind. Der Stripe-Offset ist der Index der ersten OST-Datei, über die die Datei gestreift wird.
Ändern Sie Ihre Striping-Konfiguration
Die Layoutparameter einer Datei werden festgelegt, wenn die Datei zum ersten Mal erstellt wird. Verwenden Sie den lfs setstripe Befehl, um eine neue, leere Datei mit einem bestimmten Layout zu erstellen.
lfs setstripefilename--stripe-countnumber_of_OSTs
Der lfs setstripe Befehl wirkt sich nur auf das Layout einer neuen Datei aus. Verwenden Sie ihn, um das Layout einer Datei festzulegen, bevor Sie sie erstellen. Sie können auch ein Layout für ein Verzeichnis definieren. Sobald es für ein Verzeichnis festgelegt ist, wird dieses Layout auf jede neue Datei angewendet, die diesem Verzeichnis hinzugefügt wird, jedoch nicht auf vorhandene Dateien. Jedes neue Unterverzeichnis, das Sie erstellen, erbt auch das neue Layout, das dann auf alle neuen Dateien oder Verzeichnisse angewendet wird, die Sie in diesem Unterverzeichnis erstellen.
Verwenden Sie den Befehl, um das Layout einer vorhandenen Datei zu ändern. lfs migrate Mit diesem Befehl wird die Datei nach Bedarf kopiert, um ihren Inhalt entsprechend dem Layout zu verteilen, das Sie im Befehl angeben. Beispielsweise ändern Dateien, die angehängt oder vergrößert werden, die Anzahl der Stripes nicht. Sie müssen sie also migrieren, um das Dateilayout zu ändern. Sie können auch eine neue Datei erstellen, indem Sie mit dem lfs setstripe Befehl ihr Layout angeben, den Originalinhalt in die neue Datei kopieren und dann die neue Datei umbenennen, um die Originaldatei zu ersetzen.
Es kann vorkommen, dass die Standard-Layoutkonfiguration nicht optimal für Ihre Arbeitslast ist. Beispielsweise kann in einem Dateisystem mit Dutzenden von OSTs und einer großen Anzahl von Dateien mit mehreren Gigabyte eine höhere Leistung erzielt werden, wenn die Dateien über mehr als den Standardwert für die Stripe-Anzahl von fünf OSTs verteilt werden. Das Erstellen großer Dateien mit einer niedrigen Stripe-Anzahl kann zu I/O Leistungsengpässen führen und auch dazu führen, dass OSTs voll werden. In diesem Fall können Sie ein Verzeichnis mit einer größeren Stripe-Anzahl für diese Dateien erstellen.
Die Einrichtung eines Streifenlayouts für große Dateien (insbesondere Dateien mit einer Größe von mehr als einem Gigabyte) ist aus folgenden Gründen wichtig:
Verbessert den Durchsatz, indem mehrere OSTs und die zugehörigen Server beim Lesen und Schreiben großer Dateien IOPS, Netzwerkbandbreite und CPU-Ressourcen bereitstellen können.
Reduziert die Wahrscheinlichkeit, dass ein kleiner Teil der OSTs zu Hotspots wird, die die allgemeine Workload-Leistung einschränken.
Verhindert, dass eine einzelne große Datei eine OST-Datei füllt, was möglicherweise zu Fehlern bei voller Festplatte führen kann.
Es gibt keine einzige optimale Layoutkonfiguration für alle Anwendungsfälle. Eine ausführliche Anleitung zu Datei-Layouts finden Sie in der Lustre.org Dokumentation unter Verwaltung des Dateilayouts (Striping) und des freien Speicherplatzes
Das gestreifte Layout ist am wichtigsten für große Dateien, insbesondere für Anwendungsfälle, in denen Dateien routinemäßig Hunderte von Megabyte oder mehr groß sind. Aus diesem Grund weist das Standardlayout für ein neues Dateisystem Dateien mit einer Größe von mehr als 1 GiB eine Streifenanzahl von fünf zu.
Die Anzahl der Stripes ist der Layoutparameter, den Sie für Systeme, die große Dateien unterstützen, anpassen sollten. Die Anzahl der Stripes gibt die Anzahl der OST-Volumes an, auf denen Teile einer Stripe-Datei gespeichert werden. LustreSchreibt beispielsweise bei einer Stripe-Anzahl von 2 und einer Stripe-Größe von 1 MiB abwechselnd 1-MB-Chunks einer Datei in jedes der beiden OSTs.
Die effektive Stripe-Anzahl ist der kleinere Wert aus der tatsächlichen Anzahl von OST-Volumes und dem von Ihnen angegebenen Wert für die Stripe-Anzahl. Sie können den speziellen Wert für die Stripe-Anzahl von verwenden,
-1um anzugeben, dass Stripes auf allen OST-Volumes platziert werden sollen.Die Festlegung einer großen Anzahl an Stripes für kleine Dateien ist nicht optimal, da für bestimmte Operationen ein Netzwerk-Roundtrip zu jedem OST-Objekt im Layout Lustre erforderlich ist, auch wenn die Datei zu klein ist, um Speicherplatz auf allen OST-Volumes zu belegen.
Sie können ein progressives Datei-Layout (PFL) einrichten, bei dem sich das Layout einer Datei mit der Größe ändern kann. Eine PFL-Konfiguration kann die Verwaltung eines Dateisystems mit einer Kombination aus großen und kleinen Dateien vereinfachen, ohne dass Sie für jede Datei explizit eine Konfiguration festlegen müssen. Weitere Informationen finden Sie unter Progressive Datei-Layouts.
Die Stripe-Größe beträgt standardmäßig 1 MiB. Das Einstellen eines Stripe-Offsets kann unter bestimmten Umständen nützlich sein, aber im Allgemeinen ist es am besten, ihn nicht anzugeben und die Standardeinstellung zu verwenden.
Progressive Datei-Layouts
Sie können eine PFL-Konfiguration (Progressive File Layout) für ein Verzeichnis angeben, um vor dem Auffüllen verschiedene Stripe-Konfigurationen für kleine und große Dateien festzulegen. Sie können beispielsweise eine PFL für das Verzeichnis der obersten Ebene festlegen, bevor Daten in ein neues Dateisystem geschrieben werden.
Um eine PFL-Konfiguration anzugeben, verwenden Sie den lfs setstripe Befehl mit -E Optionen, um Layoutkomponenten für Dateien unterschiedlicher Größe anzugeben, z. B. den folgenden Befehl:
lfs setstripe -E 100M -c 1 -E 10G -c 8 -E 100G -c 16 -E -1 -c 32/mountname/directory
Mit diesem Befehl werden vier Layoutkomponenten festgelegt:
Die erste Komponente (
-E 100M -c 1) gibt einen Wert für die Anzahl der Stripes von 1 für Dateien mit einer Größe von bis zu 100 MiB an.Die zweite Komponente (
-E 10G -c 8) gibt eine Stripe-Anzahl von 8 für Dateien mit einer Größe von bis zu 10 GiB an.Die dritte Komponente (
-E 100G -c 16) gibt eine Stripe-Anzahl von 16 für Dateien mit einer Größe von bis zu 100 GiB an.Die vierte Komponente (
-E -1 -c 32) gibt eine Stripe-Anzahl von 32 für Dateien mit mehr als 100 GiB an.
Wichtig
Durch das Anhängen von Daten an eine Datei, die mit einem PFL-Layout erstellt wurde, werden alle Layoutkomponenten aufgefüllt. Wenn Sie beispielsweise mit dem oben gezeigten 4-Komponenten-Befehl eine 1 MiB-Datei erstellen und dann Daten am Ende der Datei hinzufügen, wird das Layout der Datei auf eine Stripe-Anzahl von -1 erweitert, was alle OSTs im System bedeutet. Das bedeutet nicht, dass Daten in jedes OST geschrieben werden, aber ein Vorgang wie das Lesen der Dateilänge sendet parallel zu jedem OST eine Anfrage, was das Dateisystem erheblich belastet.
Achten Sie daher darauf, die Anzahl der Stripes für Dateien mit kleiner oder mittlerer Länge zu begrenzen, an die anschließend Daten angehängt werden können. Da Protokolldateien normalerweise wachsen, wenn neue Datensätze angehängt werden, weist Amazon FSx for Lustre jeder im Anfügemodus erstellten Datei eine Standard-Stripe-Anzahl von 1 zu, unabhängig von der im übergeordneten Verzeichnis angegebenen Standard-Stripe-Konfiguration.
Die Standard-PFL-Konfiguration auf Amazon FSx for Lustre-Dateisystemen, die nach dem 25. August 2023 erstellt wurden, wird mit diesem Befehl festgelegt:
lfs setstripe -E 100M -c 1 -E 10G -c 8 -E 100G -c 16 -E -1 -c 32/mountname
Kunden mit Workloads, die häufig gleichzeitig auf mittlere und große Dateien zugreifen, werden wahrscheinlich von einem Layout mit mehr Stripes bei kleineren Größen und Striping über alle OSTs für die größten Dateien profitieren, wie im Beispiel-Layout mit vier Komponenten dargestellt.
Überwachung von Leistung und Nutzung
Jede Minute sendet Amazon FSx for Lustre Nutzungsmetriken für jede Festplatte (MDT und OST) an Amazon. CloudWatch
Um aggregierte Details zur Dateisystemnutzung anzuzeigen, können Sie sich die Summenstatistik jeder Metrik ansehen. Die Summe der DataReadBytes Statistik gibt beispielsweise den gesamten Lesedurchsatz an, der von allen OSTs in einem Dateisystem gemessen wurde. In ähnlicher Weise gibt die Summe der FreeDataStorageCapacity Statistik die gesamte verfügbare Speicherkapazität für Dateidaten im Dateisystem an.
Weitere Informationen zur Überwachung der Leistung Ihres Dateisystems finden Sie unterÜberwachung von Amazon FSx for Lustre-Dateisystemen.
