Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Verwaltung der Speicherkapazität
Amazon FSx for NetApp ONTAP bietet eine Reihe von speicherbezogenen Funktionen, mit denen Sie die Speicherkapazität in Ihrem Dateisystem verwalten können.
Themen
FSx für ONTAP Speicherstufen
Speicherstufen sind die physischen Speichermedien für ein Amazon FSx for NetApp ONTAP-Dateisystem. FSx for ONTAP bietet die folgenden Speicherstufen:
SSD-Stufe — Der vom Benutzer bereitgestellte, leistungsstarke Solid-State-Drive-Speicher (SSD), der speziell für den aktiven Teil Ihres Datensatzes entwickelt wurde.
Kapazitätspool-Tier — Vollständig elastischer Speicher, der automatisch auf Petabyte skaliert wird und kostenoptimiert für Ihre Daten ist, auf die Sie selten zugreifen.
Ein FSx for ONTAP-Volume ist eine virtuelle Ressource, die, ähnlich wie Ordner, keine Speicherkapazität verbraucht. Die Daten, die Sie speichern — und die physischen Speicherplatz beanspruchen — befinden sich in Volumes. Wenn Sie ein Volume erstellen, geben Sie dessen Größe an, die Sie nach der Erstellung ändern können. FSx for ONTAP-Volumes sind Thin Provisioning, und der Dateisystemspeicher wird nicht im Voraus reserviert. Stattdessen werden SSD- und Kapazitätspoolspeicher nach Bedarf dynamisch zugewiesen. Eine Tiering-Richtlinie, die Sie auf Volume-Ebene konfigurieren, bestimmt, ob und wann Daten, die auf der SSD-Stufe gespeichert sind, in die Kapazitätspoolebene übergehen.
Das folgende Diagramm zeigt ein Beispiel für Daten, die auf mehreren FSx for ONTAP-Volumes in einem Dateisystem angeordnet sind.
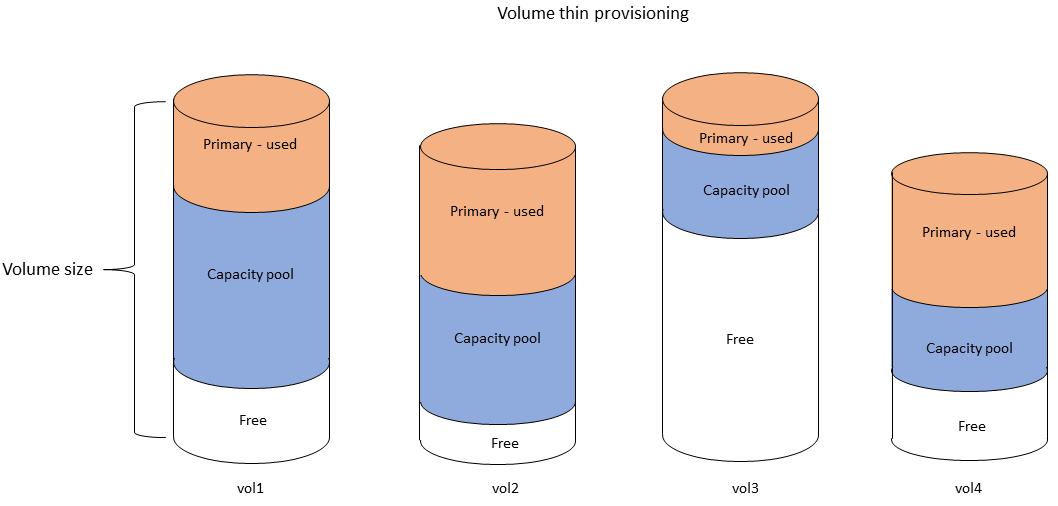
Das folgende Diagramm zeigt, wie die physische Speicherkapazität des Dateisystems durch die Daten in den vier Volumes im vorherigen Diagramm verbraucht wird.
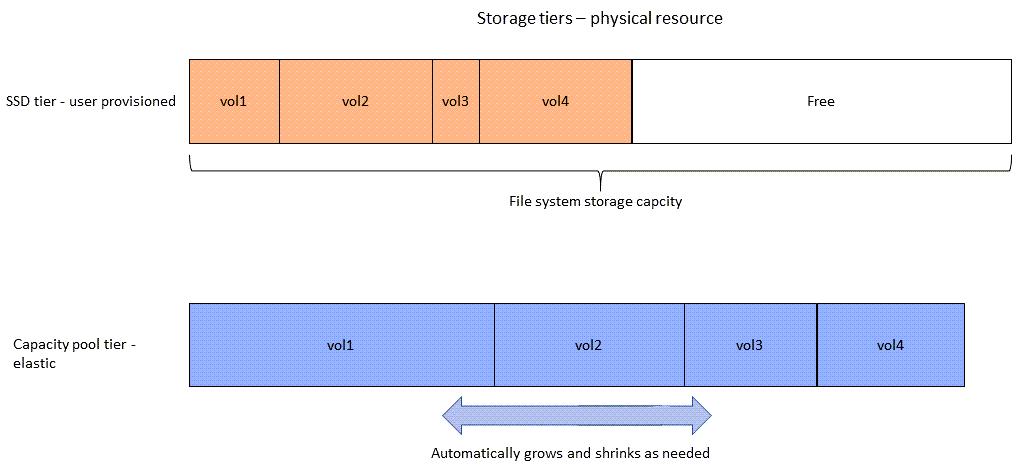
Sie können Ihre Speicherkosten senken, indem Sie die Tiering-Richtlinie wählen, die den Anforderungen für jedes Volume in Ihrem Dateisystem am besten entspricht. Weitere Informationen finden Sie unter Tiering von Volumendaten.
Auswahl der richtigen Menge an SSD-Speicher für das Dateisystem
Bei der Auswahl der SSD-Speicherkapazität für Ihr FSx for ONTAP-Dateisystem müssen Sie die folgenden Punkte berücksichtigen, die sich auf die Menge des für die Speicherung Ihrer Daten verfügbaren SSD-Speichers auswirken:
Speicherkapazität, die für den Overhead der NetApp ONTAP-Software reserviert ist.
Datei-Metadaten
Kürzlich geschriebene Daten
Dateien, die Sie auf SSD-Speicher speichern möchten, unabhängig davon, ob es sich um Daten handelt, deren Kühlzeit noch nicht erreicht wurde, oder um Daten, die Sie kürzlich gelesen haben und die wieder auf die SSD abgerufen wurden.
Wie wird SSD-Speicher verwendet
Der SSD-Speicher Ihres Dateisystems wird für eine Kombination aus NetApp ONTAP-Software (Overhead), Dateimetadaten und Ihren Daten verwendet.
NetApp Mehraufwand für die ONTAP-Software
Wie bei anderen NetApp ONTAP-Dateisystemen sind bis zu 16% der SSD-Speicherkapazität eines Dateisystems für ONTAP-Overhead reserviert, was bedeutet, dass sie nicht zum Speichern Ihrer Dateien verfügbar sind. Der ONTAP-Overhead wird wie folgt zugewiesen:
11% sind für NetApp ONTAP-Software reserviert. Für Dateisysteme mit über 30 Tebibyte (TiB) SSD-Speicherkapazität sind 6% reserviert.
5% sind für aggregierte Snapshots reserviert, die zur Synchronisation von Daten zwischen den beiden Dateiservern eines Dateisystems erforderlich sind.
Datei-Metadaten
Dateimetadaten belegen in der Regel 3-7% der Speicherkapazität, die von den Dateien belegt wird. Dieser Prozentsatz hängt von der durchschnittlichen Dateigröße (eine geringere durchschnittliche Dateigröße erfordert mehr Metadaten) und der Höhe der Einsparungen bei der Speichereffizienz Ihrer Dateien ab. Beachten Sie, dass Dateimetadaten nicht von Einsparungen bei der Speichereffizienz profitieren. Sie können die folgenden Richtlinien verwenden, um abzuschätzen, wie viel SSD-Speicher für Metadaten in Ihrem Dateisystem verwendet wird.
| Durchschnittliche Dateigröße | Größe der Metadaten als Prozentsatz der Dateidaten |
|---|---|
|
4 KB |
7% |
|
8 KB |
3,5% |
|
32 KB oder mehr |
1-3% |
Bei der Bemessung der SSD-Speicherkapazität, die Sie für die Metadaten von Dateien benötigen, die Sie auf der Kapazitätspoolebene speichern möchten, empfehlen wir, ein konservatives Verhältnis von 1 GiB SSD-Speicher pro 10 GiB an Daten zu verwenden, die Sie auf der Kapazitätspoolebene speichern möchten.
Dateidaten, die auf Ihrer SSD-Stufe gespeichert sind
Zusätzlich zu Ihrem aktiven Datensatz und allen Dateimetadaten werden alle in Ihr Dateisystem geschriebenen Daten zunächst auf die SSD-Ebene geschrieben, bevor sie auf den Kapazitätspoolspeicher abgestuft werden. Dies gilt unabhängig von der Tiering-Richtlinie des Volumes, mit der Ausnahme, dass Daten direkt in den Kapazitätspool-Speicher geschrieben werden, wenn sie SnapMirror auf einem Volume verwendet werden, für das die Tiering-Richtlinie „Alle Daten“ konfiguriert ist.
Zufällige Lesevorgänge aus der Kapazitätspoolebene werden in der SSD-Stufe zwischengespeichert, sofern die SSD-Stufe zu weniger als 90% ausgelastet ist. Weitere Informationen finden Sie unter Tiering von Volumendaten.
Empfohlene SSD-Kapazitätsauslastung
Wir empfehlen, dass Sie Ihre SSD-Speicherebene kontinuierlich nicht über 80% auslasten. Für Dateisysteme der zweiten Generation empfehlen wir außerdem, die Auslastung der Aggregate Ihres Dateisystems nicht kontinuierlich zu überschreiten. Diese Empfehlungen entsprechen der Empfehlung für NetApp ONTAP. Da die SSD-Stufe Ihres Dateisystems auch für das Staging von Schreibvorgängen und für zufällige Lesevorgänge auf der Ebene des Kapazitätspools verwendet wird, können plötzliche Änderungen der Zugriffsmuster schnell zu einer erhöhten Auslastung Ihrer SSD-Stufe führen.
Bei einer SSD-Auslastung von 90% werden die aus der Kapazitätspoolebene gelesenen Daten nicht mehr auf der SSD-Ebene zwischengespeichert, sodass die verbleibende SSD-Kapazität für alle neuen Daten, die in das Dateisystem geschrieben werden, erhalten bleibt. Dies führt dazu, dass wiederholte Lesevorgänge derselben Daten aus der Kapazitätspoolebene aus dem Kapazitätspoolspeicher gelesen werden, anstatt zwischengespeichert und aus der SSD-Ebene gelesen zu werden, was sich auf die Durchsatzkapazität Ihres Dateisystems auswirken kann.
Alle Tiering-Funktionen werden beendet, wenn die SSD-Stufe zu 98% oder mehr ausgelastet ist. Weitere Informationen finden Sie unter Schwellenwerte für die Staffelung.
Speichereffizienz
NetApp ONTAPbietet Funktionen zur Speichereffizienz auf Blockebene auf Volume-Ebene, darunter Komprimierung, Verdichtung und Deduplizierung. Mit diesen Funktionen können Sie bis zu 65% an Speicherkapazität für allgemeine Dateifreigaben einsparen, ohne dass die Leistung darunter leidet. Sie können die Speichereffizienz auf Volumenbasis aktivieren. Diese Funktionen reduzieren die Menge an Speicherkapazität, die Ihre Daten verbrauchen, sodass Sie weniger Speicherplatz auf SSD, Kapazitätspool und Backup-Speicher verbrauchen können. Sie können die Komprimierung und Deduplizierung auf jedem Volume für Daten im SSD-Speicher aktivieren. Die durch Komprimierung und Deduplizierung im SSD-Speicher erzielten Speichereinsparungen bleiben erhalten, wenn die Daten auf den Kapazitätspoolspeicher aufgeteilt werden. Die Speichereffizienz ist für Backup-Daten immer aktiviert, unabhängig von der Speichereffizienzkonfiguration Ihres Dateisystems.
Die folgende Tabelle zeigt Beispiele für typische Speichereinsparungen.
| Nur Komprimierung | Nur Deduplizierung | Komprimierung und Deduplizierung | |
|---|---|---|---|
| General-purpose Dateifreigaben | 50 % | 30 % | 65% |
| Virtuelle Server und Desktops | 55% | 70 % | 70 % |
| Datenbanken | 65-70% | 0% | 65-70% |
| Technische Daten | 55% | 30 % | 75 % |
| Geoseismische Daten | 40% | 3% | 40% |
Bei den meisten Workloads wirkt sich die Aktivierung von Komprimierung und Deduplizierung nicht negativ auf die Leistung des Dateisystems aus. Bei den meisten Workloads erhöht die Komprimierung die Gesamtleistung. Um schnelle Lese- und Schreibvorgänge aus dem RAM-Cache zu ermöglichen, verfügen FSx für ONTAP-Dateiserver über eine höhere Netzwerkbandbreite auf den Front-End-Netzwerkschnittstellenkarten (NICs) als zwischen den Dateiservern und Speicherplatten. Da die Datenkomprimierung die zwischen Dateiservern und Speicherplatten übertragene Datenmenge reduziert, werden Sie bei den meisten Workloads eine Erhöhung der Gesamtdurchsatzkapazität des Dateisystems feststellen, wenn Sie Datenkomprimierung verwenden. Erhöhungen der Durchsatzkapazität im Zusammenhang mit der Datenkomprimierung werden begrenzt, sobald Sie die Front-End-Netzwerkkarte Ihres Dateisystems voll ausgelastet haben.
Amazon FSx for NetApp ONTAP unterstützt auch andere ONTAP Funktionen, mit denen Sie Speicherplatz sparen, darunter Snapshots, Thin Provisioning und Volumes. FlexClone
Funktionen zur Speichereffizienz sind standardmäßig nicht aktiviert. Sie können sie wie folgt aktivieren:
Auf dem Root-Volume einer SVM, wenn Sie ein Dateisystem erstellen.
Wenn Sie ein neues Volume erstellen.
Wenn Sie ein vorhandenes Volume ändern.
Informationen zum Umfang der Speichereinsparungen in einem Dateisystem mit aktivierter Speichereffizienz finden Sie unterÜberwachung der Einsparungen bei der Speichereffizienz.
Berechnung der Einsparungen bei der Speichereffizienz
Sie können die CloudWatch Dateisystemmetriken LogicalDataStored und StorageUsed FSx for ONTAP verwenden, um Speichereinsparungen durch Komprimierung, Deduplizierung, Komprimierung, Snapshots und zu berechnen. FlexClones Diese Metriken haben eine einzige Dimension,. FileSystemId Weitere Informationen finden Sie unter Metriken für das Dateisystem.
Um die Einsparungen bei der Speichereffizienz in Byte zu berechnen, nehmen Sie den Durchschnitt von
StorageUsedüber einen bestimmten Zeitraum und subtrahieren Sie ihn vom Durchschnitt für denselbenLogicalDataStoredZeitraum.Um die Einsparungen bei der Speichereffizienz als Prozentsatz der gesamten logischen Datengröße zu berechnen, nehmen Sie den Wert
AveragevonStorageUsedüber einen bestimmten Zeitraum und subtrahieren ihn vom Wert von von imAveragegleichen Zeitraum.LogicalDataStoredDann dividieren Sie die Differenz durch den WertAveragevonLogicalDataStoredim gleichen Zeitraum.
Beispiel für die SSD-Größe
Angenommen, Sie möchten 100 TiB an Daten für eine Anwendung speichern, bei der auf 80% der Daten selten zugegriffen wird. In diesem Szenario werden 80% (80 TiB) Ihrer Daten automatisch auf die Ebene des Kapazitätspools aufgeteilt, und die restlichen 20% (20 TiB) verbleiben im SSD-Speicher. Basierend auf den typischen Einsparungen bei der Speichereffizienz von 65% für allgemeine Filesharing-Workloads entspricht das einer Datenmenge von 7 TiB. Um eine SSD-Nutzungsrate von 80% aufrechtzuerhalten, benötigen Sie 8,75 TiB SSD-Speicherkapazität für die 20 TiB an aktiv abgerufenen Daten. Die Menge an SSD-Speicher, die Sie bereitstellen, muss auch den Speicheraufwand der ONTAP-Software in Höhe von 16% berücksichtigen, wie aus der folgenden Berechnung hervorgeht.
ssdNeeded = ssdProvisioned * (1 - 0.16) 8.75 TiB / 0.84 = ssdProvisioned 10.42 TiB = ssdProvisioned
In diesem Beispiel müssen Sie also mindestens 10,42 TiB SSD-Speicher bereitstellen. Sie verwenden außerdem 28 TiB Kapazitätspoolspeicher für die verbleibenden 80 TiB an selten abgerufenen Daten.
