Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Redshift-Verbindungen
Sie können AWS Glue for Spark verwenden, um aus Tabellen in Amazon Redshift Redshift-Datenbanken zu lesen und in Tabellen zu schreiben. Bei der Verbindung zu Amazon Redshift-Datenbanken verschiebt AWS Glue Daten mithilfe von Amazon Redshift SQL COPY und UNLOAD Befehlen über Amazon S3, um einen maximalen Durchsatz zu erzielen. In AWS Glue 4.0 und höher können Sie die Amazon Redshift Redshift-Integration für Apache Spark verwenden, um mit Amazon Redshift Redshift-spezifischen Optimierungen und Funktionen zu lesen und zu schreiben, die über diejenigen hinausgehen, die bei Verbindungen über frühere Versionen verfügbar sind.
Erfahren Sie, wie AWS Glue es für Amazon Redshift Redshift-Benutzer einfacher denn je macht, für die serverlose Datenintegration zu AWS Glue zu migrieren und. ETL
Konfigurieren von Redshift-Verbindungen
Um Amazon Redshift Redshift-Cluster in AWS Glue verwenden zu können, benötigen Sie einige Voraussetzungen:
-
Ein Amazon-S3-Verzeichnis zur temporären Speicherung beim Lesen und Schreiben in die Datenbank.
-
Ein Amazon, das VPC die Kommunikation zwischen Ihrem Amazon Redshift Redshift-Cluster, Ihrem AWS Glue-Job und Ihrem Amazon S3 S3-Verzeichnis ermöglicht.
-
Entsprechende IAM Berechtigungen für den AWS Glue-Job und den Amazon Redshift Redshift-Cluster.
Rollen konfigurieren IAM
Einrichten der Rolle für den Amazon-Redshift-Cluster
Ihr Amazon Redshift Redshift-Cluster muss in der Lage sein, in Amazon S3 zu lesen und in Amazon S3 zu schreiben, um in AWS Glue-Jobs integriert zu werden. Um dies zu ermöglichen, können Sie IAM Rollen mit dem Amazon Redshift Redshift-Cluster verknüpfen, zu dem Sie eine Verbindung herstellen möchten. Ihre Rolle sollte über eine Richtlinie verfügen, die das Lesen und Schreiben in Ihrem temporären Amazon-S3-Verzeichnis ermöglicht. Ihre Rolle sollte über eine Vertrauensbeziehung verfügen, die den redshift.amazonaws.com.rproxy.goskope.com-Service zu AssumeRole ermöglicht.
So ordnen Sie Amazon Redshift eine IAM Rolle zu
Voraussetzungen: Ein Amazon-S3-Bucket oder -Verzeichnis, der für die temporäre Speicherung von Dateien verwendet wird.
-
Identifizieren Sie, welche Amazon-S3-Berechtigungen Ihr Amazon-Redshift-Cluster benötigt. Beim Verschieben von Daten zu und von einem Amazon Redshift-Cluster führt AWS Glue zu Problemen COPY und UNLOAD Aussagen gegen Amazon Redshift. Wenn Ihr Job eine Tabelle in Amazon Redshift ändert, gibt AWS Glue auch CREATE LIBRARY Kontoauszüge aus. Informationen zu bestimmten Amazon S3 S3-Berechtigungen, die Amazon Redshift zur Ausführung dieser Anweisungen benötigt, finden Sie in der Amazon Redshift-Dokumentation: Amazon Redshift: Zugriffsberechtigungen für andere Ressourcen. AWS
Erstellen Sie in der IAM Konsole eine IAM Richtlinie mit den erforderlichen Berechtigungen. Weitere Informationen zum Erstellen einer Richtlinie: IAMRichtlinien erstellen.
Erstellen Sie in der IAM Konsole eine Rollen- und Vertrauensbeziehung, sodass Amazon Redshift die Rolle übernehmen kann. Folgen Sie den Anweisungen in der IAM Dokumentation, um eine Rolle für einen AWS Service (Konsole) zu erstellen
Wenn Sie aufgefordert werden, einen AWS Service-Anwendungsfall auszuwählen, wählen Sie „Redshift — Customizable“.
Wenn Sie aufgefordert werden, eine Richtlinie anzufügen, wählen Sie die zuvor definierte Richtlinie aus.
Anmerkung
Weitere Informationen zur Konfiguration von Rollen für Amazon Redshift finden Sie in der Amazon Redshift-Dokumentation unter Autorisieren von Amazon Redshift, in Ihrem Namen auf andere AWS Services zuzugreifen.
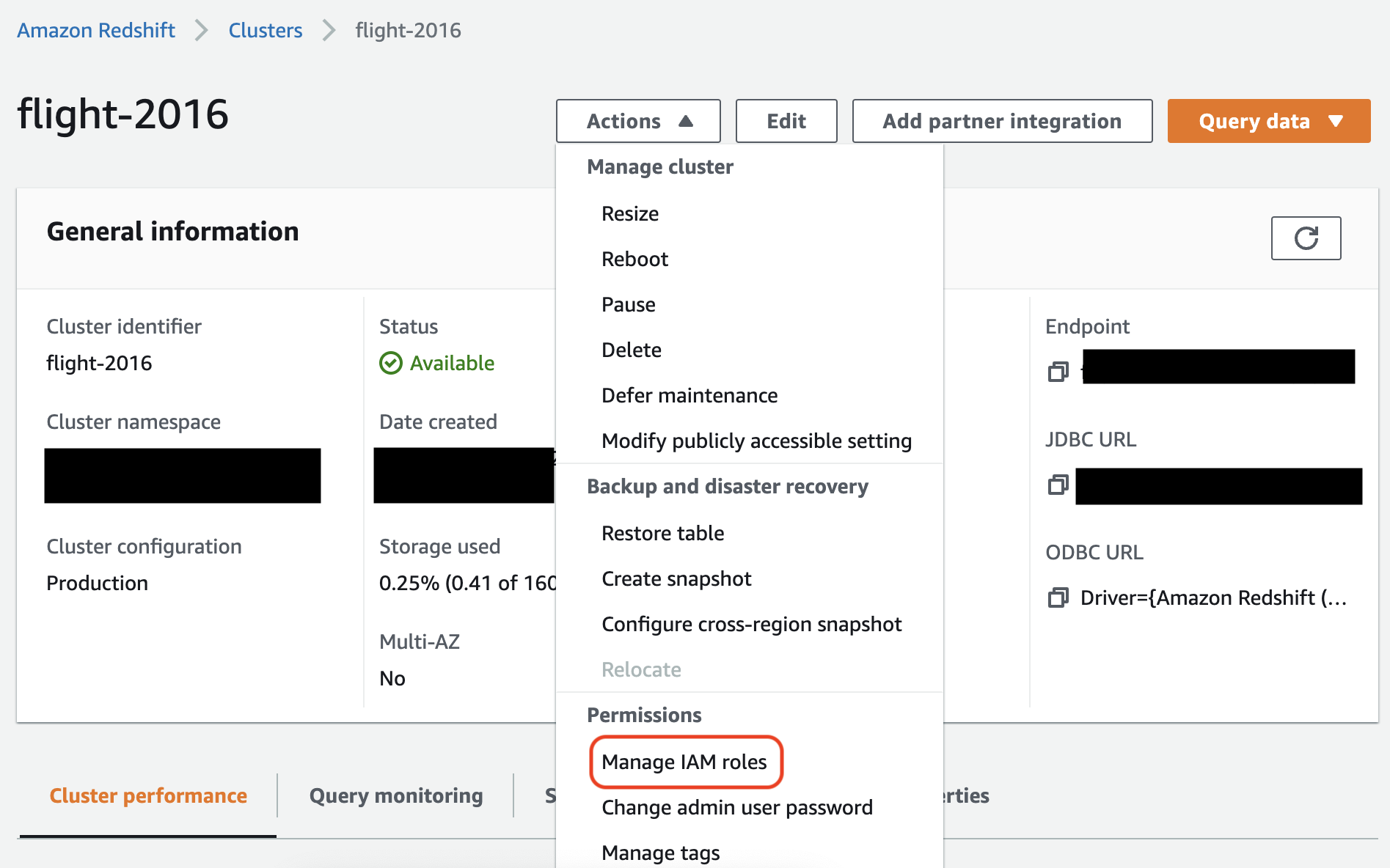
Ordnen Sie in der Amazon-Redshift-Konsole die Rolle Ihrem Amazon-Redshift-Cluster zu. Folgen Sie den Anweisungen in der Amazon-Redshift-Dokumentation.
Wählen Sie die hervorgehobene Option in der Amazon-Redshift-Konsole aus, um diese Einstellung zu konfigurieren:
Anmerkung
Standardmäßig übergeben AWS Glue-Jobs temporäre Amazon Redshift Redshift-Anmeldeinformationen, die mit der Rolle erstellt wurden, die Sie für die Ausführung des Jobs angegeben haben. Wir raten von der Verwendung dieser Anmeldeinformationen ab. Aus Sicherheitsgründen verfallen diese Zugangsdaten nach einer Stunde.
Richten Sie die Rolle für den AWS Glue-Job ein
Der AWS Glue-Job benötigt eine Rolle für den Zugriff auf den Amazon S3 S3-Bucket. Sie benötigen keine IAM Berechtigungen für den Amazon Redshift Redshift-Cluster. Ihr Zugriff wird durch die Konnektivität in Amazon VPC und Ihre Datenbankanmeldedaten gesteuert.
Amazon einrichten VPC
So richten Sie den Zugriff für Amazon-Redshift-Datenspeicher ein
Melden Sie sich bei der an AWS Management Console und öffnen Sie die Amazon Redshift Redshift-Konsole unter https://console.aws.amazon.com/redshiftv2/
. -
Wählen Sie im linken Navigationsbereich die Option Cluster aus.
-
Wählen Sie den Clusternamen, von dem aus Sie zugreifen möchten AWS Glue.
-
Wählen Sie im Abschnitt Clustereigenschaften unter Sicherheitsgruppen eine Sicherheitsgruppe aus, die zugelassen werden soll VPC AWS Glue zu verwenden. Notieren Sie sich den Namen der Sicherheitsgruppe, die Sie gewählt haben, um später darauf zurückgreifen zu können. Wenn Sie die Sicherheitsgruppe auswählen, wird die Liste der Sicherheitsgruppen der EC2 Amazon-Konsole geöffnet.
-
Wählen Sie die Sicherheitsgruppe aus, die geändert werden soll, und navigieren Sie zur Registerkarte Eingehend.
-
Fügen Sie eine Regel hinzu, die sich selbst referenziert, um Folgendes zuzulassen AWS Glue Komponenten für die Kommunikation. Insbesondere fügen Sie hinzu oder bestätigen Sie, dass eine Regel des Typs
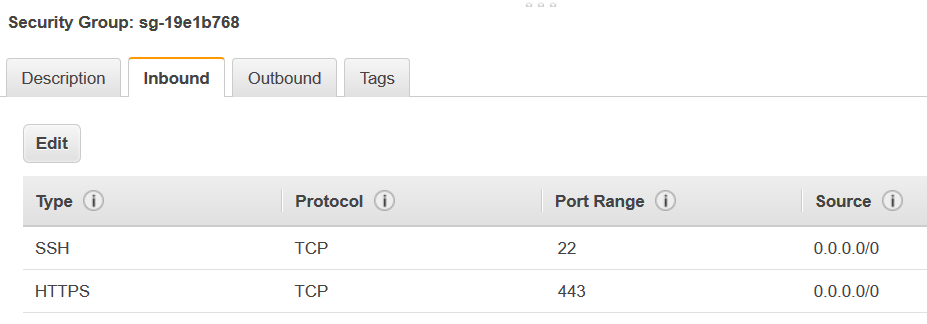
All TCPvorhanden ist, das ProtokollTCPlautet, der Port-Bereich alle Ports umfasst und deren Quelle über denselben Sicherheitsgruppennamen verfügt wie die Gruppen-ID.Die eingehende Regel sollte wie folgt aussehen:
Typ Protocol (Protokoll) Port-Bereich Quelle Alle TCP
TCP
0–65535
database-security-group
Beispielsweise:
-
Fügen Sie ebenfalls eine Regel für ausgehenden Datenverkehr hinzu. Erlauben Sie entweder ausgehenden Datenverkehr für alle Ports, beispielsweise:
Typ Protocol (Protokoll) Port-Bereich Bestimmungsort Gesamter Datenverkehr
ALL
ALL
0.0.0.0/0
Oder erstellen Sie eine selbstreferenzierende Regel, wobei der Typ
All TCPist, das ProtokollTCPlautet, der Port-Bereich alle Ports umfasst und deren Ziel über denselben Sicherheitsgruppennamen wie die Gruppen-ID verfügt. Wenn Sie einen Amazon S3 VPC S3-Endpunkt verwenden, fügen Sie auch eine HTTPS Regel für den Amazon S3 S3-Zugriff hinzu. Dass3-prefix-list-idist in der Sicherheitsgruppenregel erforderlich, um Datenverkehr vom VPC zum Amazon S3 VPC S3-Endpunkt zuzulassen.Beispielsweise:
Typ Protocol (Protokoll) Port-Bereich Bestimmungsort Alle TCP
TCP
0–65535
security-groupHTTPS
TCP
443
s3-prefix-list-id
AWS Glue einrichten
Sie müssen eine AWS Glue Data Catalog-Verbindung erstellen, die VPC Amazon-Verbindungsinformationen bereitstellt.
So konfigurieren Sie die Amazon Redshift VPC Amazon-Konnektivität zu AWS Glue in der Konsole
-
Erstellen Sie eine Data-Catalog-Verbindung, indem Sie die Schritte in AWS Glue Verbindung hinzufügen ausführen. Nachdem Sie die Verbindung hergestellt haben, behalten Sie den Verbindungsnamen für den nächsten Schritt bei.
connectionNameWählen Sie bei der Auswahl eines Verbindungstyps die Option Amazon Redshift aus.
Wählen Sie bei der Auswahl eines Redshift-Clusters Ihren Cluster nach Namen aus.
Stellen Sie Standardverbindungsinformationen für einen Amazon-Redshift-Benutzer in Ihrem Cluster bereit.
Ihre VPC Amazon-Einstellungen werden automatisch konfiguriert.
Anmerkung
Sie müssen Ihren Amazon manuell angeben
PhysicalConnectionRequirements, VPC wenn Sie eine Amazon Redshift Redshift-Verbindung über den AWS SDK herstellen. -
Stellen
connectionNameSie in Ihrer AWS Glue-Job-Konfiguration eine zusätzliche Netzwerkverbindung bereit.
Beispiel: Lesen aus Amazon-Redshift-Tabellen
Sie können aus Amazon-Redshift-Clustern und Serverless-Amazon-Redshift-Umgebungen lesen.
Voraussetzungen: Eine Amazon-Redshift-Tabelle, aus der Sie gerne lesen möchten. Folgen Sie den Schritten im vorherigen Abschnitt. Konfigurieren von Redshift-Verbindungen Danach sollten Sie Amazon S3 URI für ein temporäres Verzeichnis temp-s3-dir und eine IAM Rolle,rs-role-name, (im Kontorole-account-id) haben.
Beispiel: Schreiben in Amazon-Redshift-Tabellen
Sie können in Amazon-Redshift-Cluster und Serverless-Amazon-Redshift-Umgebungen schreiben.
Voraussetzungen: Ein Amazon Redshift Redshift-Cluster und folgen Sie den Schritten im vorherigen Abschnitt. Konfigurieren von Redshift-Verbindungen Danach sollten Sie Amazon S3 URI für ein temporäres Verzeichnis temp-s3-dir und eine IAM Rolle,rs-role-name, (im Kontorole-account-id) haben. Sie benötigen außerdem einen DynamicFrame, dessen Inhalt Sie in die Datenbank schreiben möchten.
Referenz zur Amazon-Redshift-Verbindungsoption
Die grundlegenden Verbindungsoptionen, die für alle AWS JDBC Glue-Verbindungen verwendet werden, um Informationen wie einzurichtenurl, user und password sind für alle JDBC Typen konsistent. Weitere Hinweise zu JDBC Standardparametern finden Sie unterJDBCReferenz zu den Verbindungsoptionen.
Der Amazon-Redshift-Verbindungstyp erfordert einige zusätzliche Verbindungsoptionen:
-
"redshiftTmpDir": (Erforderlich) Der Amazon-S3-Pfad, in dem temporäre Daten beim Kopieren aus der Datenbank bereitgestellt werden können. -
"aws_iam_role": (Optional) ARN für eine IAM Rolle. Der AWS Glue-Job leitet diese Rolle an den Amazon Redshift Redshift-Cluster weiter, um den Cluster-Berechtigungen zu erteilen, die für die Ausführung der Anweisungen aus dem Job erforderlich sind.
Zusätzliche Verbindungsoptionen in AWS Glue 4.0+ verfügbar
Sie können Optionen für den neuen Amazon Redshift Redshift-Connector auch über die AWS Glue-Verbindungsoptionen übergeben. Eine vollständige Liste der unterstützten Connector-Optionen finden Sie im Abschnitt SQLSpark-Parameter unter Amazon Redshift Redshift-Integration für Apache Spark.
Zur Vereinfachung möchten wir Sie hier noch einmal auf bestimmte neue Optionen hinweisen:
| Name | Erforderlich | Standard | Beschreibung |
|---|---|---|---|
| autopushdown |
Nein | TRUE | Wendet Prädikat- und Abfrage-Pushdown an, indem die logischen Spark-Betriebspläne erfasst und analysiert werden. SQL Die Operationen werden in eine SQL Abfrage übersetzt und dann in Amazon Redshift ausgeführt, um die Leistung zu verbessern. |
| autopushdown.s3_result_cache |
Nein | FALSE | Zwischenspeichert die SQL Abfrage, um Daten für die Amazon S3 S3-Pfadzuordnung im Speicher zu entladen, sodass dieselbe Abfrage nicht erneut in derselben Spark-Sitzung ausgeführt werden muss. Wird nur unterstützt wenn |
| unload_s3_format |
Nein | PARQUET | PARQUET- Entlädt die Abfrageergebnisse im Parquet-Format. TEXT- Entlädt die Abfrageergebnisse im durch Leerzeichen getrennten Textformat. |
| sse_kms_key |
Nein | N/A | Der KMS Schlüssel AWS SSE -, der für die Verschlüsselung während des |
| extracopyoptions |
Nein | N/A | Eine Liste zusätzlicher Optionen, die beim Laden von Daten an den Amazon Redshift Beachten Sie, dass nur Optionen verwendet werden können, die am Ende des Befehls sinnvoll sind, da diese Optionen an das Ende des |
| csvnullstring (experimentell) |
Nein | NULL | Der String-Wert, der bei Verwendung von für Nullen geschrieben werden soll. CSV |
Diese neuen Parameter können auf folgende Weise verwendet werden.
Neue Optionen zur Leistungsverbesserung
Der neue Konnektor bietet einige neue Optionen zur Leistungsverbesserung:
-
autopushdown: Standardmäßig aktiviert. -
autopushdown.s3_result_cache: Standardmäßig deaktiviert. -
unload_s3_format: StandardmäßigPARQUET.
Informationen zur Verwendung dieser Optionen finden Sie unter Amazon-Redshift-Integration für Apache Spark. Es wird empfohlen, das
autopushdown.s3_result_cache nicht einzuschalten, wenn Sie Lese- und Schreibvorgänge miteinander kombinieren, da die zwischengespeicherten Ergebnisse möglicherweise veraltete Informationen enthalten. Die Option unload_s3_format ist standardmäßig auf PARQUET für den UNLOAD-Befehl festgelegt, um die Leistung zu verbessern und die Speicherkosten zu reduzieren. Um das Standardverhalten des UNLOAD-Befehls zu verwenden, setzen Sie die Option auf TEXT zurück.
Neue Verschlüsselungsoption für das Lesen
Standardmäßig sind das die Daten im temporären Ordner AWS Glue verwendet, wenn Daten aus der Amazon Redshift Redshift-Tabelle gelesen werden, werden sie mit SSE-S3 Verschlüsselung verschlüsselt. Um Ihre Daten mit vom Kunden verwalteten Schlüsseln von AWS Key Management Service (AWS KMS) zu verschlüsseln, können Sie festlegen, ("sse_kms_key"
→ kmsKey) woher ksmKey die Schlüssel-ID stammt AWS KMS, und nicht die alte Einstellungsoption in ("extraunloadoptions" →
s"ENCRYPTED KMS_KEY_ID '$kmsKey'") AWS Glue Version 3.0.
datasource0 = glueContext.create_dynamic_frame.from_catalog( database = "database-name", table_name = "table-name", redshift_tmp_dir = args["TempDir"], additional_options = {"sse_kms_key":"<KMS_KEY_ID>"}, transformation_ctx = "datasource0" )
IAMSupport-basiert JDBC URL
Der neue Connector unterstützt eine IAM basierte Verbindung, JDBC URL sodass Sie weder einen Benutzer/ein Passwort noch ein Geheimnis eingeben müssen. Bei einem IAM based JDBC URL verwendet der Connector die Job-Runtime-Rolle für den Zugriff auf die Amazon Redshift Redshift-Datenquelle.
Schritt 1: Fügen Sie Ihrer mindestens erforderlichen Richtlinie die folgende Richtlinie bei AWS Glue Rolle zur Laufzeit des Jobs.
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": "redshift:GetClusterCredentials", "Resource": [ "arn:aws:redshift:<region>:<account>:dbgroup:<cluster name>/*", "arn:aws:redshift:*:<account>:dbuser:*/*", "arn:aws:redshift:<region>:<account>:dbname:<cluster name>/<database name>" ] }, { "Sid": "VisualEditor1", "Effect": "Allow", "Action": "redshift:DescribeClusters", "Resource": "*" } ] }
Schritt 2: Verwenden Sie IAM based JDBC URL wie folgt. Geben Sie eine neue Option DbUser mit dem Amazon-Redshift-Benutzernamen an, mit dem Sie eine Verbindung herstellen.
conn_options = { // IAM-based JDBC URL "url": "jdbc:redshift:iam://<cluster name>:<region>/<database name>", "dbtable": dbtable, "redshiftTmpDir": redshiftTmpDir, "aws_iam_role": aws_iam_role, "DbUser": "<Redshift User name>" // required for IAM-based JDBC URL } redshift_write = glueContext.write_dynamic_frame.from_options( frame=dyf, connection_type="redshift", connection_options=conn_options ) redshift_read = glueContext.create_dynamic_frame.from_options( connection_type="redshift", connection_options=conn_options )
Anmerkung
A unterstützt DynamicFrame derzeit nur ein IAM based JDBC URL mit a
DbUser im GlueContext.create_dynamic_frame.from_options Workflow.
Migration von AWS Glue Version 3.0 bis Version 4.0
In AWS Glue 4.0 haben ETL Jobs Zugriff auf einen neuen Amazon Redshift Spark-Konnektor und einen neuen JDBC Treiber mit unterschiedlichen Optionen und Konfigurationen. Der neue Amazon-Redshift-Konnektor und -Treiber sind auf Leistung ausgelegt und gewährleisten die Transaktionskonsistenz Ihrer Daten. Diese Produkte sind in der Amazon-Redshift-Dokumentation dokumentiert. Weitere Informationen finden Sie unter:
Einschränkung für Tabellen-/Spaltennamen und Kennungen
Für den neuen Amazon-Redshift-Spark-Konnektor und -Treiber gelten strengere Anforderungen für den Redshift-Tabellennamen. Weitere Informationen finden Sie unter Namen und Kennungen zum Definieren des Namens Ihrer Amazon-Redshift-Tabelle. Der Workflow für Auftragslesezeichen funktioniert möglicherweise nicht mit einem Tabellennamen, der nicht mit den Regeln übereinstimmt, und mit bestimmten Zeichen, z. B. einem Leerzeichen.
Wenn Sie über veraltete Tabellen mit Namen verfügen, die nicht den Regeln für Namen und Kennungen entsprechen, und Probleme mit Lesezeichen sehen (Aufträge, die alte Amazon-Redshift-Tabellendaten neu verarbeiten), empfehlen wir Ihnen, Ihre Tabellennamen umzubenennen. Weitere Informationen finden Sie in den ALTERTABLEBeispielen.
Änderung des Standard-Tempformats in Dataframe
Das Tool AWS Glue Version 3.0 Der Spark-Connector ist CSV beim Schreiben tempformat in Amazon Redshift standardmäßig auf. Um konsistent zu sein, in AWS Glue Version 3.0, die
DynamicFrame immer noch standardmäßig verwendet wird. tempformat CSV Wenn Sie Spark Dataframe zuvor APIs direkt mit dem Amazon Redshift Spark-Konnektor verwendet haben, können Sie den Wert CSV in den DataframeReader Optionen/explizit tempformat auf setzen. Writer Andernfalls wird tempformat im neuen Spark-Konnektor standardmäßig auf AVRO festgelegt.
Verhaltensänderung: Ordnen Sie den Amazon Redshift Redshift-Datentyp REAL dem Spark-Datentyp zu, FLOAT anstatt DOUBLE
In AWS Glue Version 3.0, Amazon Redshift REAL wird in einen
DOUBLE Spark-Typ konvertiert. Der neue Amazon-Redshift-Spark-Konnektor hat das Verhalten so aktualisiert, dass der
REAL-Typ von Amazon Redshift in den FLOAT-Typ von Spark konvertiert wird und umgekehrt. Wenn Sie einen älteren Anwendungsfall haben, bei dem Sie den REAL-Typ von Amazon Redshift weiterhin einem DOUBLE-Typ von Spark zuordnen möchten, können Sie die folgende Problemumgehung verwenden:
-
Ordnen Sie für eine
DynamicFramedenFloat-Typ einemDouble-Typ mitDynamicFrame.ApplyMappingzu. Für eineDataframemüssen Siecastverwenden.
Codebeispiel:
dyf_cast = dyf.apply_mapping([('a', 'long', 'a', 'long'), ('b', 'float', 'b', 'double')])
