Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Gehen Sie wie folgt vor, um einen Crawler für Amazon S3 S3-Ereignisbenachrichtigungen für ein Amazon S3 S3-Ziel einzurichten, indem Sie die Option AWS Management Console oder AWS CLI verwenden.
-
Melden Sie sich bei der an AWS Management Console und öffnen Sie die GuardDuty Konsole unter https://console.aws.amazon.com/guardduty/
. -
Legen Sie Ihre Crawler-Eigenschaften fest. Weitere Informationen finden Sie unter Einstellung der Crawler-Konfigurationsoptionen auf der AWS Glue Konsole.
-
Im Abschnitt Datenquellenkonfiguration werden Sie gefragt, ob Ihre Daten bereits zugeordnet sind AWS Glue Tabellen?
Standardmäßig ist Not yet (Noch nicht) ausgewählt. Belassen Sie dies als Standard, da Sie eine Amazon S3 S3-Datenquelle verwenden und die Daten noch nicht zugeordnet sind AWS Glue Tabellen.
-
Wählen Sie im Abschnitt Data sources (Datenquellen) Add a data source (Datenquelle hinzufügen) aus.
-
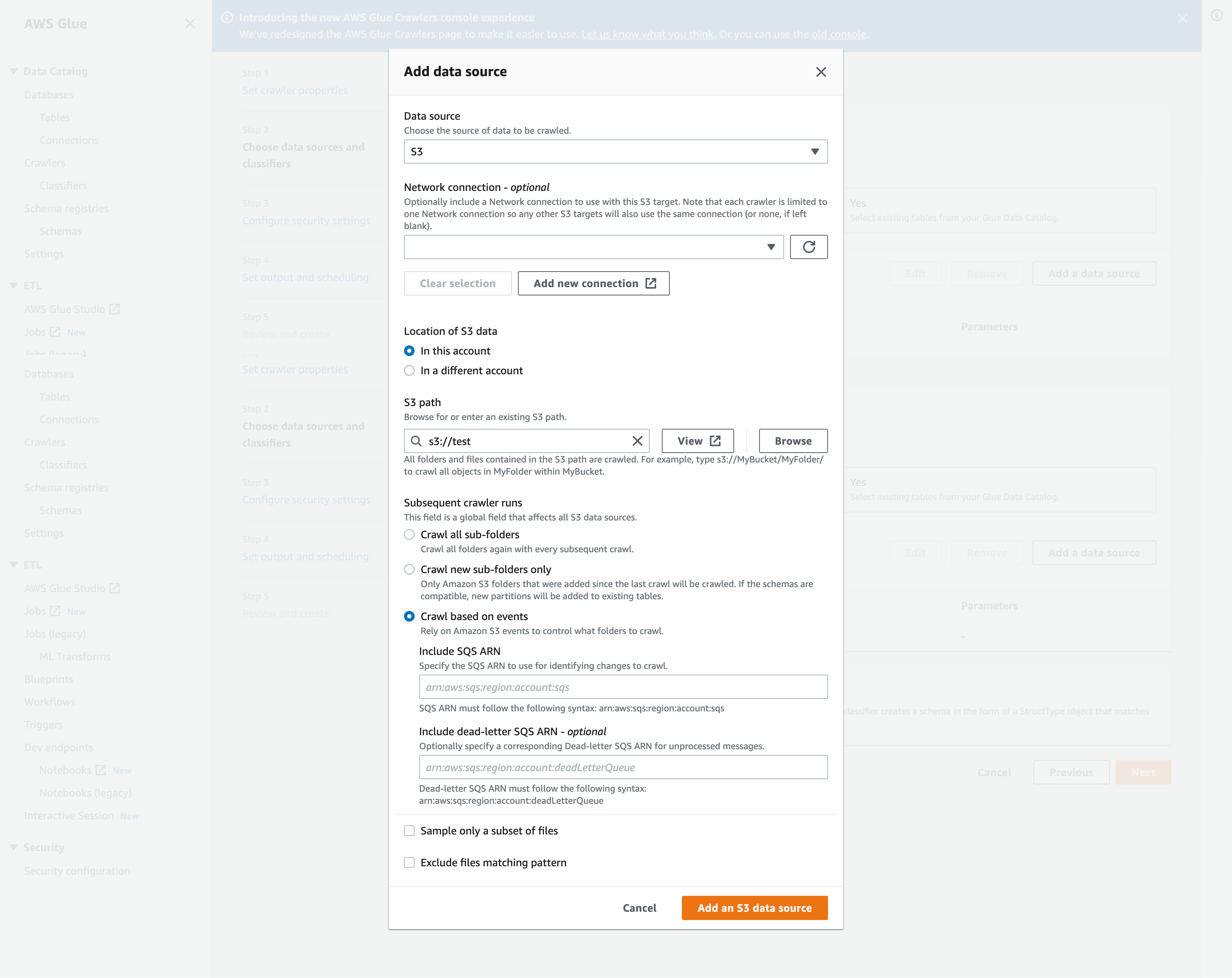
Konfigurieren Sie im Modal Add a data source (Datenquelle hinzufügen) die Amazon-S3-Datenquelle:
-
Data source (Datenquelle): Standardmäßig ist Amazon S3 ausgewählt.
-
Network connection (Netzwerkverbindung) (Optional): Wählen Sie Add new connection (Neue Verbindung hinzufügen).
-
Location of Amazon S3 data (Speicherort der Amazon-S3-Daten): Standardmäßig ist In this account (In diesem Konto) ausgewählt.
-
Amazon S3 path (Amazon-S3-Pfad): Geben Sie den Amazon-S3-Pfad an, wo Ordner und Dateien gecrawlt werden.
-
Subsequent crawler runs (Nachfolgende Crawler-Ausführungen): Wählen Sie Crawl based on events (Crawling basierend auf Ereignissen) aus, um Amazon-S3-Ereignisbenachrichtigungen für Ihren Crawler zu verwenden.
-
Einschließen SQS ARN: Geben Sie die Datenspeicherparameter einschließlich des gültigen a an SQSARN. (Beispiel:
arn:aws:sqs:region:account:sqs). -
Toten Brief einschließen SQS ARN (optional): Geben Sie einen gültigen Amazon-Leerbrief an. SQS ARN (Beispiel:
arn:aws:sqs:region:account:deadLetterQueue). -
Wählen Sie Add an Amazon S3 data source (Amazon-S3-Datenquelle hinzufügen) aus.
-
