Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Wartungsfenster für AWS Glue Streaming
AWS Glue führt regelmäßig Wartungsaktivitäten durch. Während dieser Wartungsfenster müssen AWS Glue Sie Ihre Streaming-Jobs neu starten. Sie können steuern, wann die Jobs neu gestartet werden, indem Sie Wartungsfenster angeben. In diesem Abschnitt erläutern wir, wo Sie das Wartungsfenster einrichten können und welche Verhaltensweisen Sie dabei berücksichtigen sollten.
Themen
Ein Wartungsfenster einrichten
Sie können ein Wartungsfenster mit AWS Glue Studio oder APIs einrichten.
Ein Wartungsfenster in AWS Glue Studio einrichten
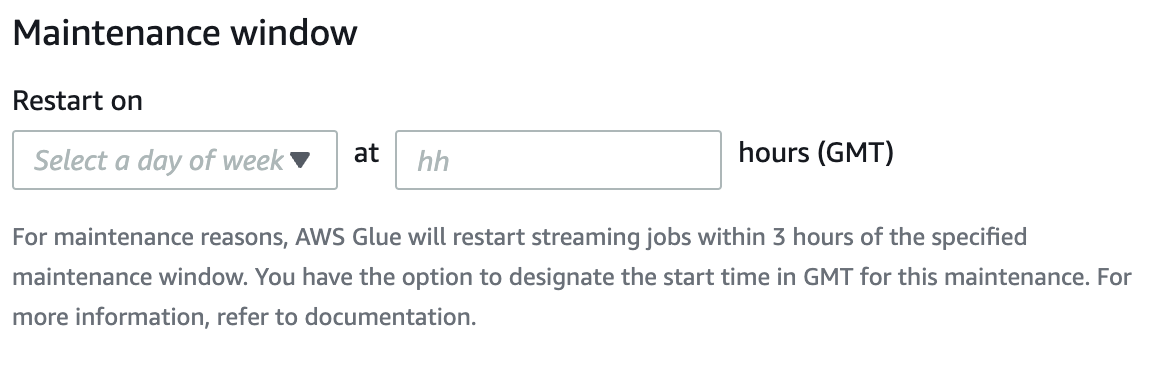
Sie können auf der Seite mit den Jobdetails Ihres AWS Glue Streaming-Jobs ein Wartungsfenster angeben. Sie können den Tag und die Uhrzeit in GMT angeben. AWS Glue wird Ihren Job innerhalb des angegebenen Zeitfensters neu starten.
Ein Wartungsfenster in der API einrichten
Sie können das Wartungsfenster alternativ in der Create Job API einrichten. Hier ist ein Beispiel für die Konfiguration eines Wartungsfensters über die API.
aws glue create-job —name jobName —role roleArnForTheJob —command Name=gluestreaming,ScriptLocation=s3-path-to-the-script --maintenance-window="Sun:10"
Ein Beispielbefehl lautet wie folgt:
aws glue create-job —name testMaintenance —role arn:aws:iam::012345678901:role/Glue_DefaultRole —command Name=gluestreaming,ScriptLocation=s3://glue-example-test/example.py —maintenance-window="Sun:10
Verhalten des Wartungsfensters
AWS Glue durchläuft eine Reihe von Schritten, um zu entscheiden, wann ein Job neu gestartet werden soll:
Wenn ein neuer Streaming-Job initiiert wird, wird AWS Glue zunächst geprüft, ob mit der Jobausführung ein Timeout verbunden ist. Ein Timeout ermöglicht es Ihnen, die Endzeit des Jobs zu konfigurieren. Wenn das Timeout weniger als 7 Tage beträgt, wird der Job nicht neu gestartet.
Wenn das Timeout länger als 7 Tage ist, wird AWS Glue geprüft, ob das Wartungsfenster für den Job konfiguriert ist. Ist dies der Fall, wird dieses Fenster ausgewählt und das Fenster wird der Auftragsausführung zugewiesen. AWS Glue startet den Job innerhalb von 3 Stunden nach Ablauf des angegebenen Wartungsfensters neu. Wenn Sie beispielsweise das Wartungsfenster für Montag um 10:00 Uhr GMT einrichten, werden Ihre Jobs zwischen 10:00 Uhr GMT und 13:00 Uhr GMT neu gestartet.
Wenn das Wartungsfenster nicht konfiguriert ist, wird die Neustartzeit AWS Glue automatisch auf 7 Tage nach der Initiierung der Auftragsausführung festgelegt. Wenn Sie Ihren Job beispielsweise am 01.07.2024 12:00 Uhr GMT initiiert haben und keine Wartungsfenster angegeben haben, wird Ihr Job so eingestellt, dass er am 08.07.2024 um 12:00 Uhr GMT neu gestartet wird.
Anmerkung
Wenn Sie bereits Streaming-Jobs ausführen, wirkt sich diese Änderung ab dem 1. Juli 2024 auf Sie aus. Sie haben bis zum 30. Juni Zeit, Ihre Wartungsfenster zu konfigurieren. Nach dem 1. Juli werden alle Streaming-Jobs, die Sie starten, gemäß dieser Dokumentation neu gestartet. Wenn Sie zusätzliche Unterstützung benötigen, können Sie sich an den AWS Support wenden.
Manchmal kann der Job AWS Glue möglicherweise nicht neu gestartet werden, insbesondere wenn der laufende Mikrobatch nicht verarbeitet wird. In diesen Fällen wird der Job nicht unterbrochen. In diesen Fällen AWS Glue wird der Job nach 14 Tagen neu gestartet. In diesem Fall wird das Wartungsfenster nicht eingehalten.
Überwachung von Job
Sie können die Jobs auf der AWS Glue Studio-Monitoring-Seite überwachen.
Um den voraussichtlichen Zeitpunkt des nächsten Neustarts von Streaming-Jobs zu sehen, zeigen Sie die Spalte in der Tabelle Auftragsausführungen auf der Seite Überwachung an.
Klicken Sie oben rechts in der Tabelle auf das Zahnradsymbol.

Scrollen Sie nach unten und aktivieren Sie die Spalte Erwartete Neustartzeit. Es sind sowohl UTC- als auch Lokalzeitoptionen verfügbar.
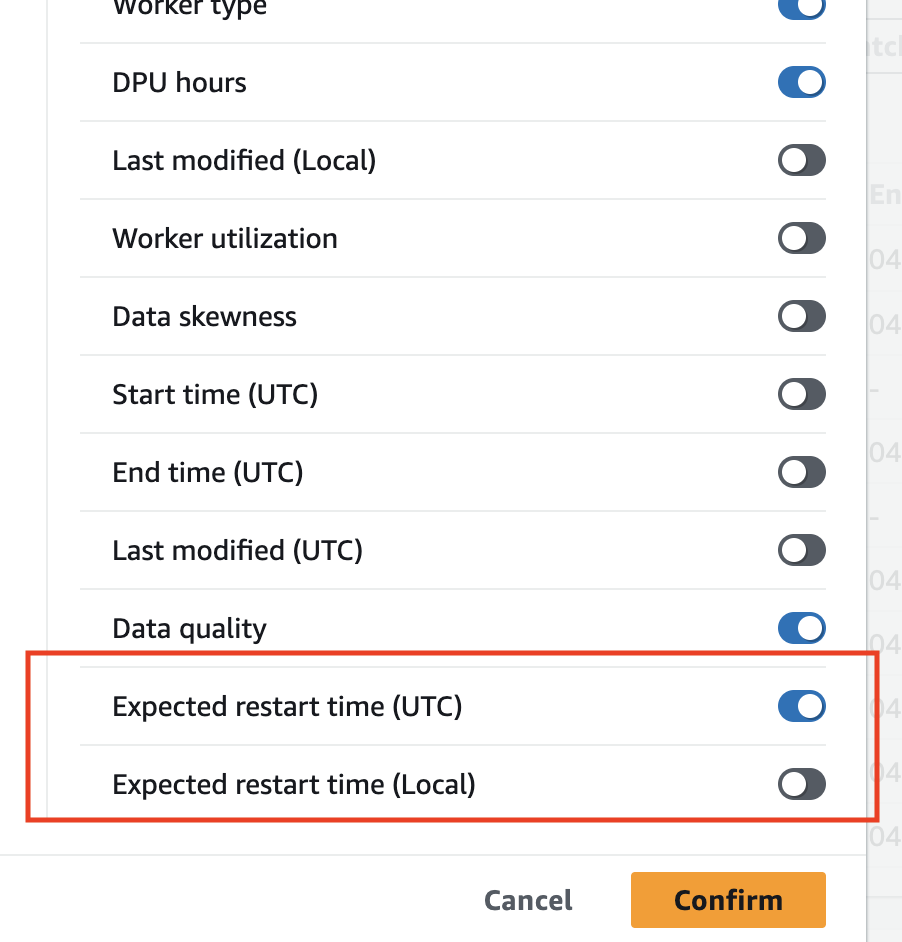
Anschließend können Sie die Spalten in der Tabelle anzeigen.

Der ursprüngliche Job hat den Status „ABGELAUFEN“ und die neue Auftragsinstanz den Status „LÄUFT“. Die neue Auftragsausführung, die neu gestartet wurde, hat eine Job-Run-ID als Verkettung aus der ID der ersten Auftragsausführung plus dem Präfix „restart_“, das die Anzahl der Neustarts darstellt. Wenn die ID der ersten Auftragsausführung beispielsweise lautetjr_1234, hat die neu gestartete Auftragsausführung die ID für den ersten Neustart. jr1234_restart_1 Der zweite Neustart ist jr1234_restart_2 für den zweiten Neustart und so weiter vorgesehen.
Ihr Wiederholungsversuch wird durch die Neustarts nicht beeinträchtigt. Wenn ein Lauf fehlschlägt und aufgrund eines automatischen Wiederholungsversuchs ein neuer Lauf gestartet wird, beginnt der Neustartzähler wieder bei 1. Schlägt ein Lauf beispielsweise bei fehljr_1234_attempt_3_restart_5, wird bei einem automatischen Wiederholungsversuch ein neuer Lauf mit der ID: gestartet, jr_id1_attempt_4 und wenn dieser Versuch nach 7 Tagen erneut gestartet wird, lautet die neue Lauf-ID. jr_id1_attempt_4_restart_1
Umgang mit Datenverlust
Bei Wartungsneustarts folgt AWS Glue Streaming einem Prozess, der die Datenintegrität und Konsistenz zwischen der vorherigen Auftragsausführung und der neu gestarteten Auftragsausführung sicherstellt. Beachten Sie, dass AWS Glue dies nicht die Datenintegrität und Konsistenz zwischen Auftragsneustarts garantiert. Wir empfehlen daher, Überlegungen zur Architektur zu beachten, um doppelte Daten innerhalb von Streaming-Aufträgen zu behandeln.
Erkennung von Wartungsneustartbedingungen: AWS Glue Streaming überwacht Bedingungen, die angeben, wann ein Wartungsneustart ausgelöst werden sollte, z. B. wenn nach 7 Tagen ein Wartungsfenster erreicht wird oder nach 14 Tagen ein harter Neustart erforderlich ist.
Aufrufen eines ordnungsgemäßen Abbruchs: Wenn die Bedingungen für den Neustart der Wartung erfüllt sind, leitet AWS Glue Streaming einen ordnungsgemäßen Beendungsprozess für den aktuell ausgeführten Job ein. Dieser Prozess umfasst die folgenden Schritte:
Stoppen der Aufnahme neuer Daten: Der Streaming-Job verwendet keine neuen Daten mehr aus den Eingabequellen (z. B. Kafka-Themen, Kinesis-Streams oder Dateien).
Verarbeitung ausstehender Daten: Der Job verarbeitet weiterhin alle Daten, die sich bereits in seinen internen Puffern oder Warteschlangen befinden.
Offsets und Checkpoints festschreiben: Der Job überträgt die neuesten Offsets oder Checkpoints an externe Systeme (z. B. Kafka, Kinesis oder Amazon S3), um sicherzustellen, dass der neu gestartete Job dort weitermachen kann, wo der vorherige Job aufgehört hat.
Job neu starten: Nachdem der Vorgang zur ordnungsgemäßen Beendigung abgeschlossen ist, startet Streaming den Job mit dem beibehaltenen Status und den Checkpoints neu. AWS Glue Der neu gestartete Job nimmt die Verarbeitung ab dem letzten festgeschriebenen Offset oder Checkpoint auf und stellt so sicher, dass keine Daten verloren gehen oder dupliziert werden.
Fortsetzung der Datenverarbeitung: Der neu gestartete Job setzt die Datenverarbeitung an dem Punkt fort, an dem der vorherige Job aufgehört hat. Er setzt die Aufnahme neuer Daten aus den Eingabequellen fort, beginnend mit dem letzten festgeschriebenen Offset oder Checkpoint, und verarbeitet die Daten gemäß der definierten ETL-Logik.
