Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Debugging von anspruchsvolle Phasen und Straggler-Aufgaben
Mit dem AWS Glue-Aufgabenprofiling können Sie anspruchsvolle Phasen und Straggler-Aufgaben in Ihren ETL-Aufträgen (Extrahieren, Transformieren und Laden) identifizieren. Eine Straggler-Aufgabe dauert viel länger als der Rest der Aufgaben in einer Phase eines AWS Glue-Auftrags. Dies bewirkt, dass die Phase länger dauert, was auch die gesamte Ausführungszeit des Auftrags verzögert.
Zusammenführung von kleinen Eingabedateien zu größeren Ausgabedateien
Eine Straggler-Aufgabe kann auftreten, wenn eine uneinheitliche Verteilung der Arbeit auf die verschiedenen Aufgaben gibt, oder wenn eine Datenverzerrung dazu führt, dass eine Aufgabe mehr Daten verarbeiten muss.
Sie können den folgenden Code profilieren (ein gemeinsames Muster in Apache Spark), um eine große Anzahl von kleinen Dateien zu größeren Ausgabedateien zusammenzuführen. In diesem Beispiel besteht das Eingabe-Dataset aus 32 GB mit Gzip komprimierten JSON-Dateien. Das Ausgabe-Dataset umfasst ca. 190 GB nicht komprimierte JSON-Dateien.
Der profilierte Code sieht wie folgt aus:
datasource0 = spark.read.format("json").load("s3://input_path") df = datasource0.coalesce(1) df.write.format("json").save(output_path)
Visualisieren der profilierten Metriken auf der AWS Glue-Konsole
Sie können Ihren Auftrags profilieren, um vier verschiedene Metrik-Gruppen zu überprüfen:
-
ETL-Datenbewegung
-
Datenmischung über Executors hinweg
-
Auftragsausführung
-
Arbeitsspeicherprofil
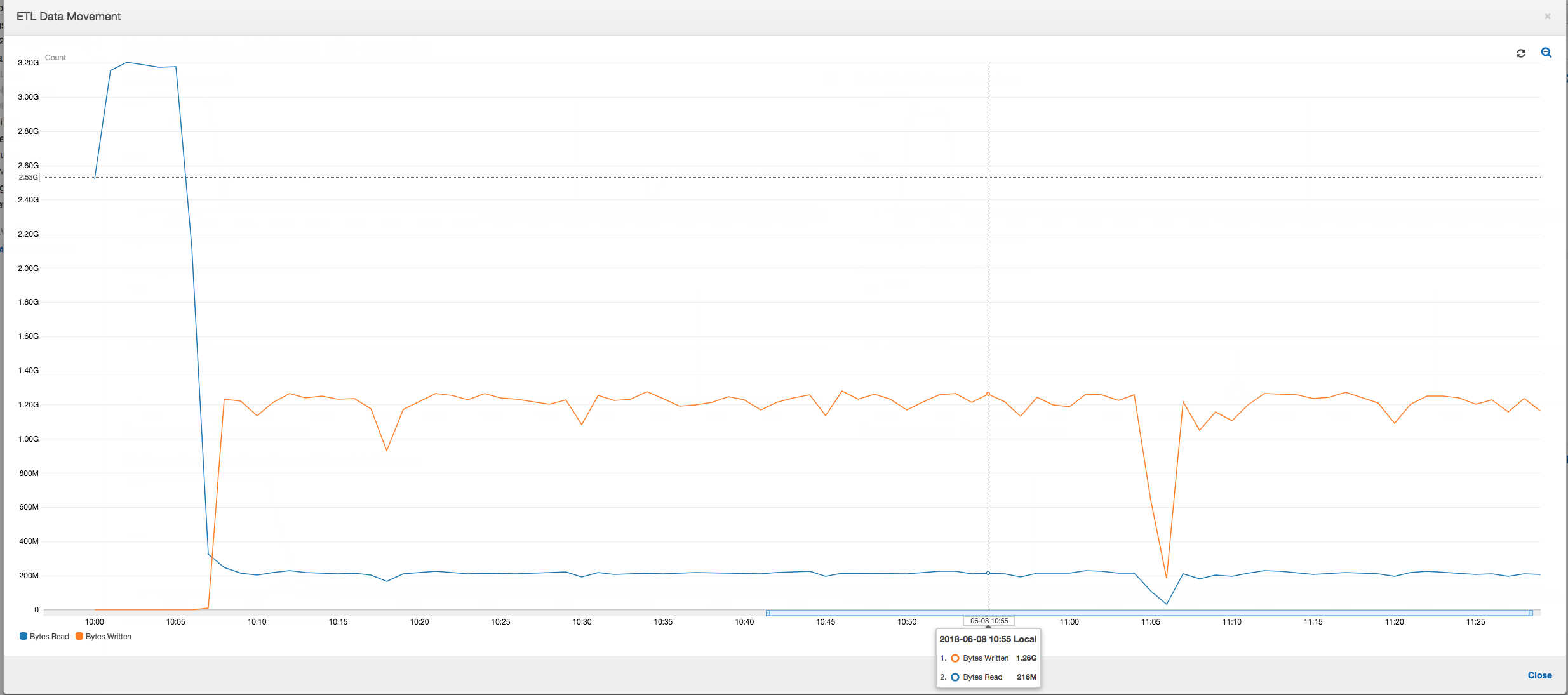
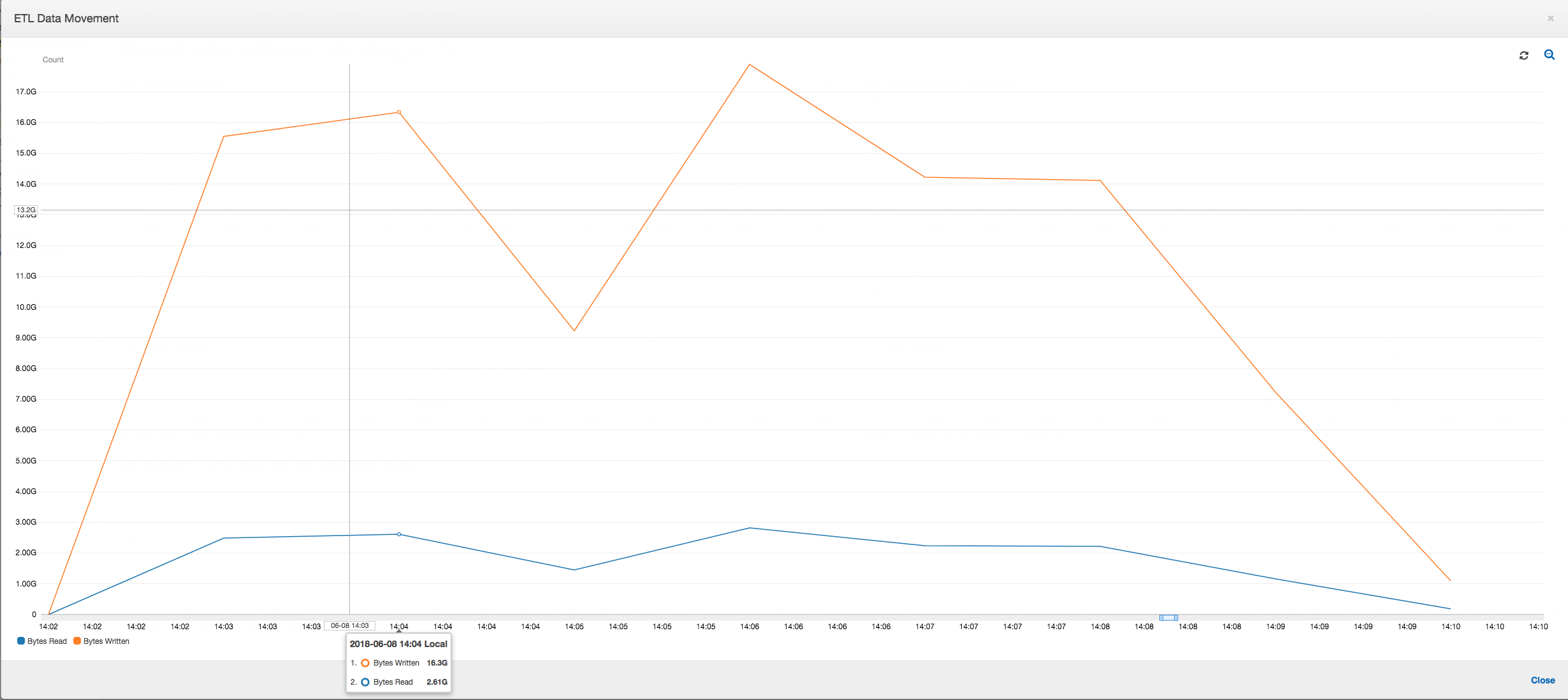
ETL-Datenbewegung: Im Profil ETL Data Movement (ETL-Datenbewegung) werden die Bytes von allen Executors in der ersten Phase, die innerhalb der ersten sechs Minuten abgeschlossen wird, relativ schnell gelesen. Die gesamte Auftragsausführung dauert jedoch etwa eine Stunde, vor allem durch die Schreibvorgänge für die Daten.
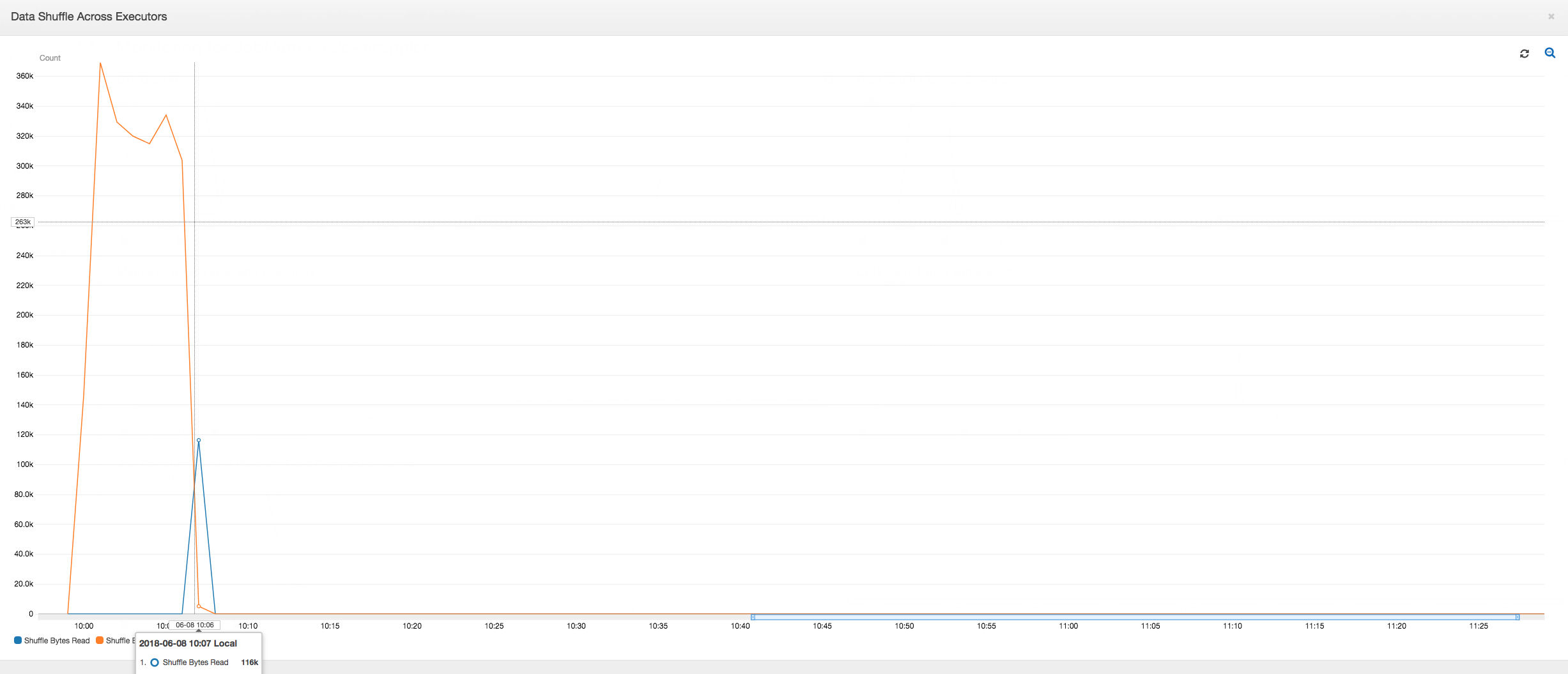
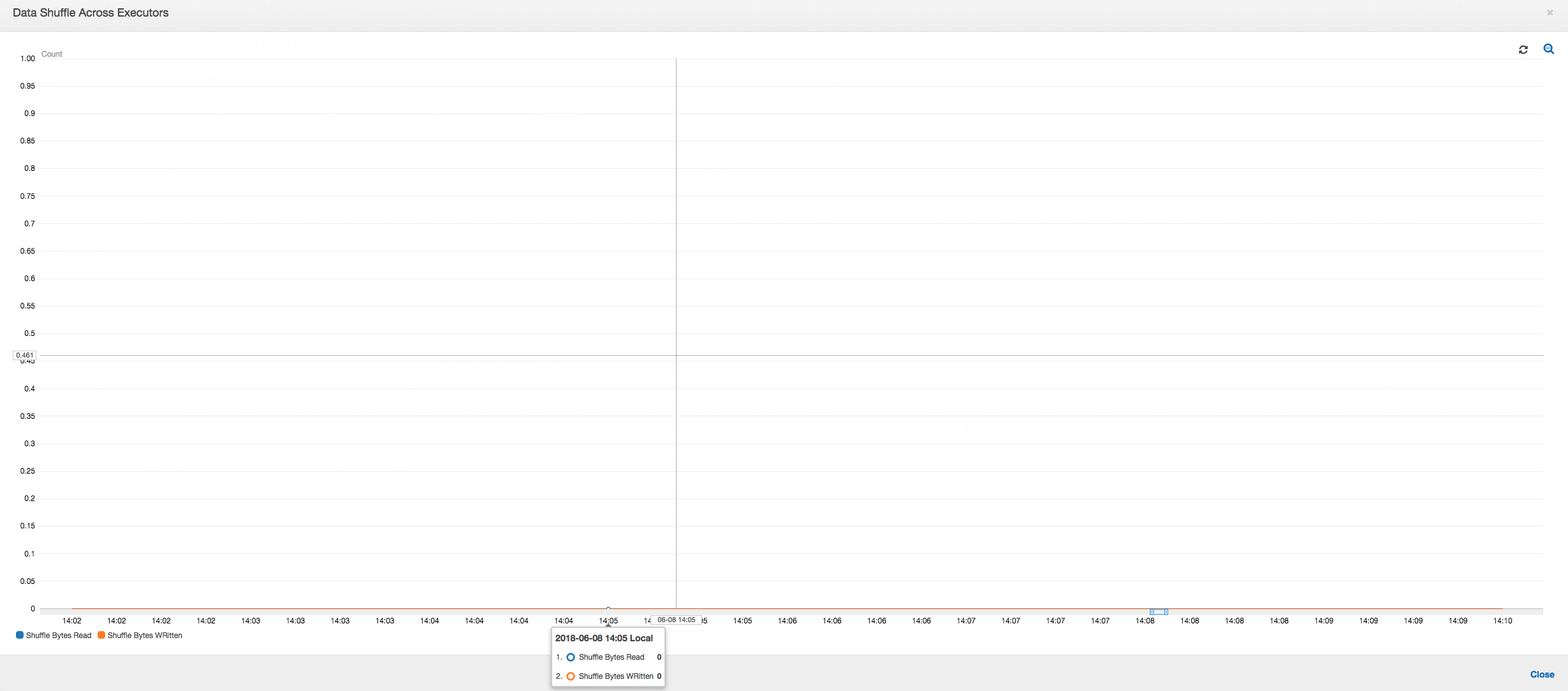
Datenmischung über Executors hinweg: Die Anzahl der gelesenen und geschriebenen Bytes während des Mischens zeigt auch eine hohe Zahl, bevor Phase 2 endet, wie durch die Metriken Job Execution (Auftragsausführung) und Data Shuffle (Datenmischung) gezeigt. Nachdem die Daten aus allen Executors gemischt wurden, werden die Lese- und Schreiboperationen nur noch von Executor Nummer 3 ausgeführt.
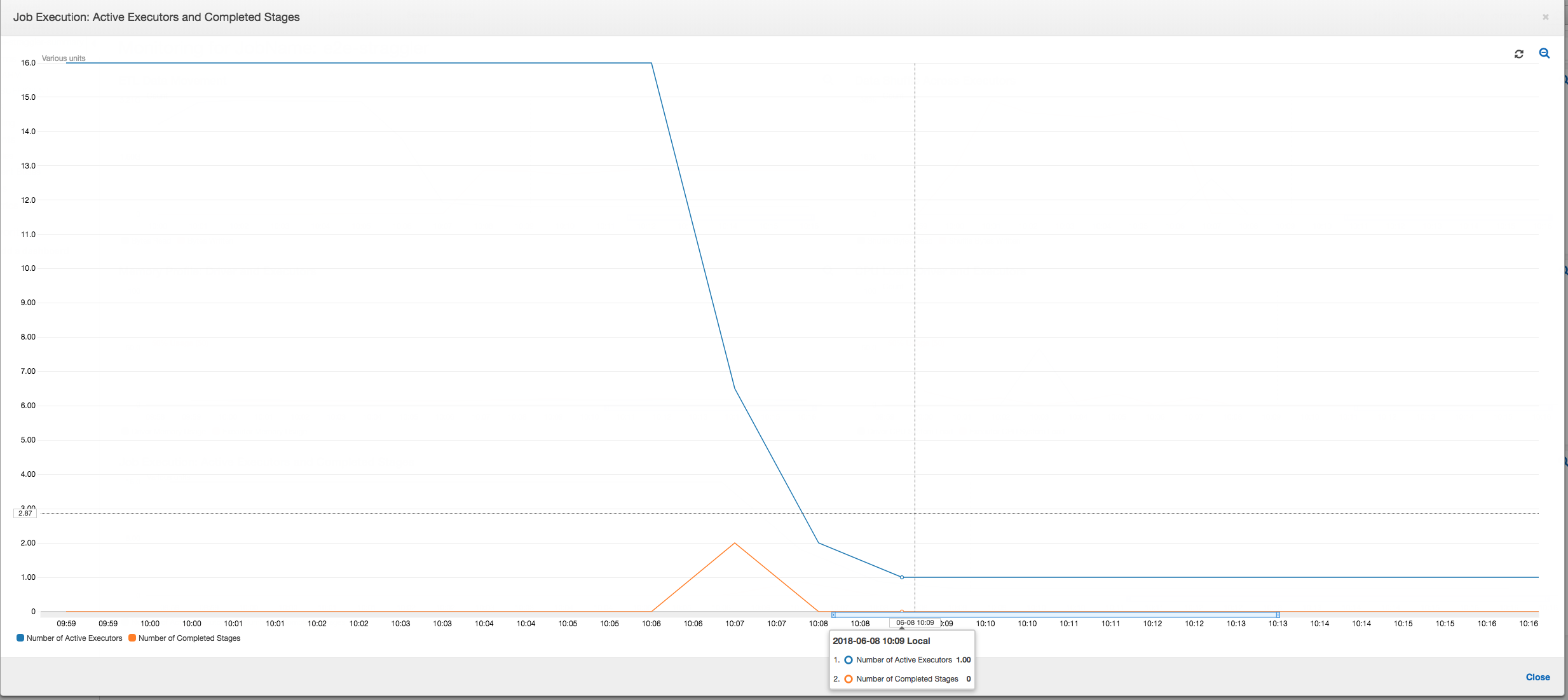
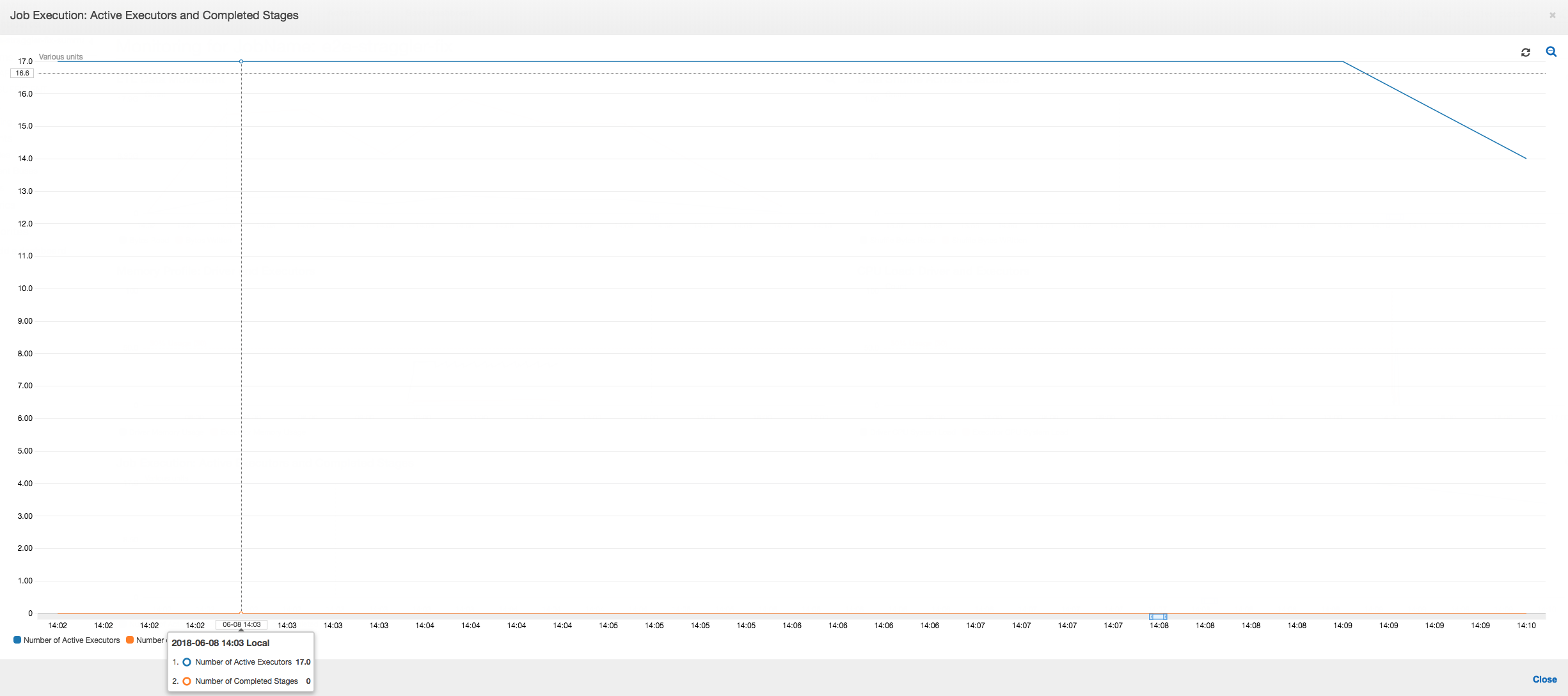
Auftragsausführung: Wie im folgenden Graphen gezeigt, sind alle anderen Executors im Leerlauf und werden schließlich zum Zeitpunkt 10:09 aufgegeben. Zu diesem Zeitpunkt verringert sich die Gesamtanzahl der Executors auf nur einen. Dies zeigt deutlich, dass der Executor Nummer 3 aus der Straggler-Aufgabe besteht, die die längste Ausführungszeit benötigt und zum größten Teil zur Auftragsausführungszeit beiträgt.
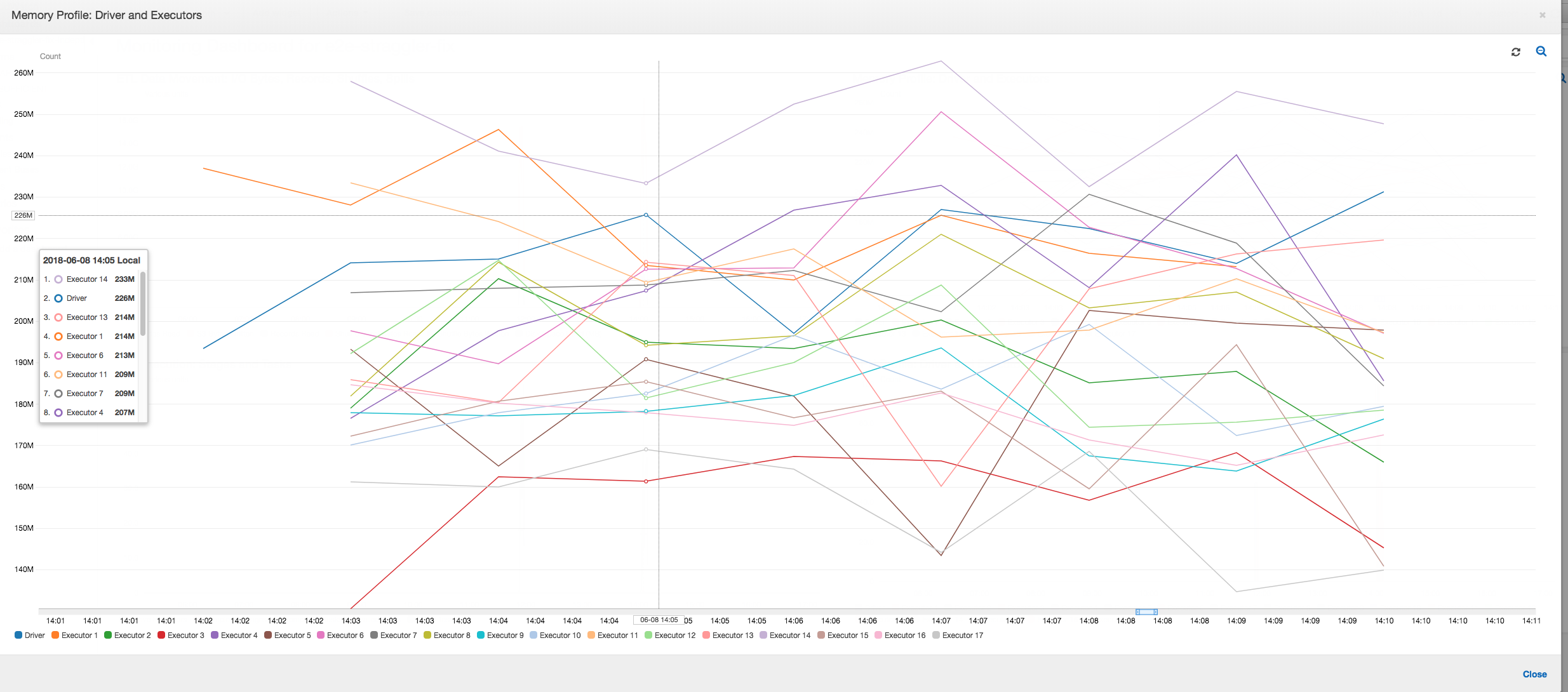
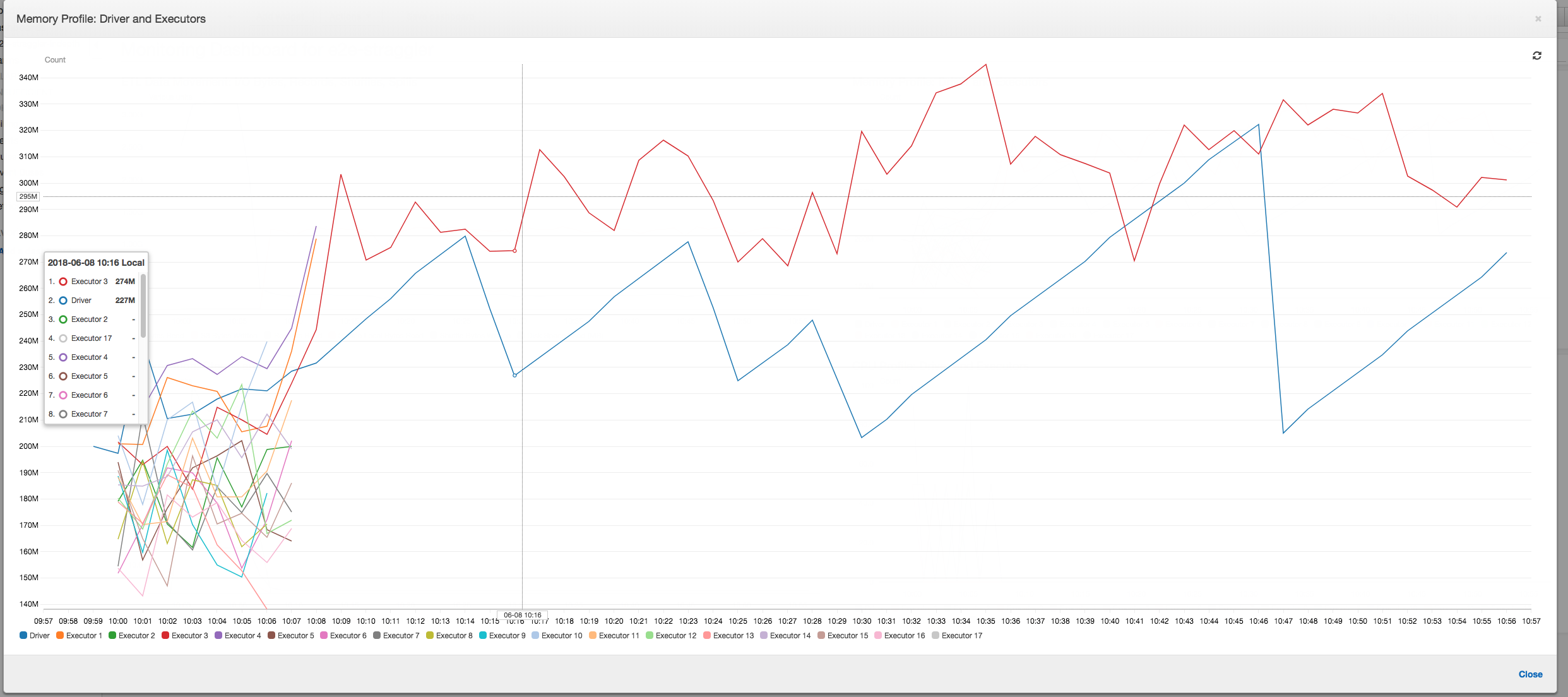
Speicherprofil: Nachdem den ersten beiden Phasen verbraucht nur noch Executor Nummer 3 aktiv Arbeitsspeicher zur Verarbeitung der Daten. Die restlichen Executors sind einfach im Leerlauf oder wurden kurz nach Abschluss der ersten beiden Phasen aufgegeben.
Beheben von Straggling-Executors unter Verwendung der Gruppierung
Mit der Gruppierungsfeature in AWS Glue können Sie Straggling-Executors vermeiden. Verwenden Sie die Gruppierung, um die Daten gleichmäßig auf alle Executors zu verteilen und Dateien zu größeren Dateien zusammenzufassen, indem Sie alle verfügbaren Executors auf dem Cluster verwenden. Weitere Informationen finden Sie unter Zusammenfassen von Eingabedateien in größeren Gruppen beim Lesen.
Um die ETL-Datenbewegungen des AWS Glue-Auftrags zu überprüfen, müssen Sie den folgenden Code mit aktivierter Gruppierung profilieren:
df = glueContext.create_dynamic_frame_from_options("s3", {'paths': ["s3://input_path"], "recurse":True, 'groupFiles': 'inPartition'}, format="json") datasink = glueContext.write_dynamic_frame.from_options(frame = df, connection_type = "s3", connection_options = {"path": output_path}, format = "json", transformation_ctx = "datasink4")
ETL-Datenbewegung: Die Datenschreibvorgänge werden nun parallel zu den Datenlesevorgängen während der gesamten Ausführungszeit des Auftrags gestreamt. Dies bewirkt, dass der Auftrag innerhalb von acht Minuten abgeschlossen wird, viel schneller als zuvor.
Datenmischung über Executors hinweg: Da die Eingabedateien während des Lesens über die Gruppierungsfeature zusammengeführt werden, gibt es nach dem Lesen der Daten keine kostspielige Datenmischung.
Auftragsausführung: Die Auftragsausführungsmetriken zeigen, dass die Gesamtanzahl der aktiven Executors, die ausgeführt werden und Daten verarbeiten, relativ konstant bleibt. Es gibt keine einzelnen Straggler in dem Auftrag. Alle Executors sind aktiv und werden nicht aufgegeben, bis zum der Auftrag abgeschlossen ist. Da es keine zwischenzeitliche Datenmischung zwischen den Executors gibt, gibt es nur eine einzige Phase in dem Auftrag.
Speicherprofil: Die Metriken zeigen die aktive Speicherbelegung für alle Executors – dies bestätigt, dass Aktivitäten auf allen Executors vorliegen. Da die Daten parallel gestreamt und ausgegeben werden, ist der gesamte Speicherbedarf aller Executors etwa gleich groß und liegt weit unter der sicheren Schwelle für alle Executors.