Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Wie funktionieren Auftragskonfigurationen
Sie verwenden die Rollout- und Abbruchkonfigurationen, wenn Sie einen Auftrag bereitstellen, und die Timeout- und Wiederholungskonfigurationen für die Auftragsausführung. In den folgenden Abschnitten finden Sie weitere Informationen zur Funktionsweise dieser Konfigurationen.
Themen
Konfigurationen für Auftrags-Rollout, Planung und Abbruch
Mithilfe der Konfigurationen für Auftrags-Rollout, Planung und Abbruch können Sie festlegen, wie viele Geräte das Auftragsdokument erhalten, einen Auftrags-Rollout planen und die Kriterien für das Abbrechen eines Auftrags festlegen.
Sie können angeben, wie schnell die Ziele über eine ausstehende Auftragsausführung benachrichtigt werden. Sie können auch ein gestaffeltes Rollout erstellen, um Updates, Neustarts und andere Vorgänge zu verwalten. Um festzulegen, wie Ihre Ziele benachrichtigt werden, verwenden Sie die Auftrags-Rollout-Raten.
Auftragsrolloutraten
Sie können eine Rollout-Konfiguration erstellen, indem Sie entweder eine konstante Rollout-Rate oder eine exponentielle Rollout-Rate verwenden. Verwenden Sie eine konstante Rollout-Rate, um die maximale Anzahl von Auftragszielen festzulegen, die pro Minute informiert werden sollen.
AWS IoT Jobs können mit exponentiellen Rollout-Raten bereitgestellt werden, wenn verschiedene Kriterien und Schwellenwerte erfüllt werden. Wenn die Anzahl der fehlgeschlagenen Aufträge einer Reihe von Kriterien entspricht, die Sie angeben, können Sie den Auftrags-Rollout abbrechen. Sie legen die Kriterien für die Auftrags-Rollout-Rate fest, wenn Sie mithilfe des JobExecutionsRolloutConfig-Objekts einen Auftrag erstellen. Sie legen auch die Kriterien für den Auftragsabbruch bei der Auftragserstellung fest, indem Sie das AbortConfig-Objekt verwenden.
Das folgende Beispiel zeigt, wie die Rollout-Raten funktionieren. Beispielsweise würde ein Auftrags-Rollout mit einer Basisrate von 50 pro Minute, einem Inkrementfaktor von 2 und einer Anzahl von jeweils 1.000 Geräten, die benachrichtigt und erfolgreich waren, wie folgt funktionieren: Der Auftrag beginnt mit einer Geschwindigkeit von 50 Auftragsausführungen pro Minute und wird mit dieser Geschwindigkeit fortgesetzt, bis entweder 1.000 Objekte Benachrichtigungen zur Auftragsausführung erhalten haben oder 1.000 erfolgreiche Auftragsausführungen stattgefunden haben.
Die folgende Tabelle zeigt, wie der Rollout über die ersten vier Inkremente verläuft.
|
Rolloutrate pro Minute |
50 |
100 |
200 |
400 |
|
Anzahl der benachrichtigten Geräte oder der erfolgreichen Auftragsausführungen, um einer erhöhten Rate gerecht zu werden |
1.000 |
2.000 |
3,000 |
4.000 |
Anmerkung
Wenn Sie Ihr maximales Limit von 500 Aufträgen (isConcurrent = True) erreicht haben, behalten alle aktiven Aufträge den Status IN-PROGRESS und führen keine neuen Auftragsausführungen durch, bis die Anzahl der gleichzeitigen Aufträge 499 oder weniger beträgt (isConcurrent = False). Dies gilt für Snapshots und kontinuierliche Aufträge.
Falls isConcurrent = True, führt der Auftrag derzeit Auftragsausführungen auf allen Geräten Ihrer Zielgruppe durch. Falls isConcurrent = False, hat der Auftrag den Rollout aller Auftragsausführungen auf allen Geräten in Ihrer Zielgruppe abgeschlossen. Der Status wird aktualisiert, sobald alle Geräte in Ihrer Zielgruppe einen Terminal-Zustand erreicht haben, oder wenn Sie eine Konfiguration für den Auftragsabbruch ausgewählt haben, einen bestimmten Schwellenwert für Ihre Zielgruppe erreicht haben. Der Status auf Auftragsebene isConcurrent = False gibt für isConcurrent = True und beide IN_PROGRESS an.
Weitere Informationen zu den Limits für aktive und gleichzeitige Aufträge finden Sie unter Limits für aktive und gleichzeitige Aufträge.
Auftrags-Rollout-Raten für kontinuierliche Aufträge mit dynamischen Objektgruppen
Wenn Sie einen kontinuierlichen Job verwenden, um Fernoperationen in Ihrer Flotte einzuführen, führt AWS IoT Jobs die Ausführung von Jobs für Geräte in Ihrer Zielgruppe durch. Bei neuen Geräten, die der dynamischen Objektgruppe hinzugefügt werden, werden diese Auftragsausführungen auch nach der Erstellung des Auftrags weiterhin auf diesen Geräten ausgeführt.
Mit der Rollout-Konfiguration können die Rollout-Raten nur für Geräte gesteuert werden, die der Gruppe hinzugefügt werden, bis der Auftrag erstellt wird. Nachdem ein Auftrag erstellt wurde, werden die Auftragsausführungen für alle neuen Geräte nahezu in Echtzeit erstellt, sobald die Geräte der Zielgruppe beitreten.
Sie können einen kontinuierlichen Auftrag oder einen Snapshot-Auftrag bis zu einem Jahr im Voraus planen und dabei eine vorher festgelegte Startzeit, Endzeit und ein Endverhalten angeben, was mit jeder Auftragsausführung nach Erreichen der Endzeit geschehen soll. Darüber hinaus können Sie ein optionales wiederkehrendes Wartungsfenster mit flexibler Häufigkeit, Startzeit und Dauer für fortlaufende Aufträge einrichten, um ein Auftragsdokument auf allen Geräten innerhalb der Zielgruppe bereitzustellen.
Konfigurationen für die Auftragsplanung
Startzeit
Die Startzeit eines geplanten Auftrags ist das zukünftige Datum und die Uhrzeit, zu der der Auftrag mit der Bereitstellung des Auftragsdokuments auf allen Geräten in der Zielgruppe beginnt. Die Startzeit für einen geplanten Auftrag gilt für fortlaufende Aufträge und Snapshot-Aufträge. Wenn ein geplanter Auftrag zum ersten Mal erstellt wird, behält er den Status SCHEDULED. Sobald das von Ihnen gewählte startTime erreicht ist, wird es aktualisiert auf IN_PROGRESS und der Rollout des Auftragsdokuments wird gestartet. Der Zeitraum zwischen dem ursprünglichen Datum und der Uhrzeit, zu der Sie den geplanten Auftrag erstellt haben, startTime darf nicht länger als ein Jahr sein.
Weitere Informationen zur Syntax startTime bei der Verwendung eines API-Befehls oder des AWS CLI finden Sie unter Timestamp.
Bei einem Auftrag mit der optionalen Planungskonfiguration, der während eines wiederkehrenden Wartungsfensters an einem Ort mit Sommerzeit ausgeführt wird, ändert sich die Uhrzeit um eine Stunde, wenn von Sommerzeit auf Normalzeit und von Normalzeit auf Sommerzeit umgestellt wird.
Anmerkung
Die in der angezeigte Zeitzone AWS Management Console ist Ihre aktuelle Systemzeitzone. Diese Zeitzonen werden jedoch im System in UTC umgerechnet.
Endzeit
Die Endzeit eines geplanten Auftrags ist das zukünftige Datum und die Uhrzeit, zu der der Auftrag das Rollout des Auftragsdokuments an alle verbleibenden Geräte in der Zielgruppe beendet. Die Endzeit für einen geplanten Auftrag gilt für fortlaufende Aufträge und Snapshot-Aufträge. Wenn ein geplanter Auftrag beim ausgewählten endTime eintrifft und alle Auftragsausführungen einen Terminal-Zustand erreicht haben, wird sein Status von IN_PROGRESS auf COMPLETED aktualisiert. Der Zeitraum zwischen dem ursprünglichen Datum und der Uhrzeit, zu der Sie den geplanten Auftrag erstellt haben, endTime darf nicht länger als ein Jahr sein. Die Mindestdauer zwischen startTime und endTime beträgt 30 Minuten. Wiederholungsversuche bei der Auftragsausführung werden durchgeführt, bis der Auftrag den endTime erreicht, dann bestimmt der endBehavior, wie weiter vorzugehen ist.
Weitere Informationen zur Syntax endTime bei der Verwendung eines API-Befehls oder des AWS CLI finden Sie unter Timestamp.
Bei einem Auftrag mit der optionalen Planungskonfiguration, der während eines wiederkehrenden Wartungsfensters an einem Ort mit Sommerzeit ausgeführt wird, ändert sich die Uhrzeit um eine Stunde, wenn von Sommerzeit auf Normalzeit und von Normalzeit auf Sommerzeit umgestellt wird.
Anmerkung
Die in der angezeigte Zeitzone AWS Management Console ist Ihre aktuelle Systemzeitzone. Diese Zeitzonen werden jedoch im System in UTC umgerechnet.
Verhalten beenden
Das Endverhalten eines geplanten Auftrags bestimmt, was mit dem Auftrag und allen noch nicht abgeschlossenen Auftragsausführungen passiert, wenn der Auftrag den ausgewählten endTime erreicht.
Im Folgenden sind die Endverhaltensweisen aufgeführt, aus denen Sie bei der Erstellung des Auftrags oder der Auftragsvorlage wählen können:
-
STOP_ROLLOUT-
STOP_ROLLOUTstoppt den Rollout des Auftragsdokuments auf allen verbleibenden Geräten in der Zielgruppe für den Auftrag. Darüber hinaus werden alleQUEUED- undIN_PROGRESS-Aufträge so lange ausgeführt, bis sie den Terminal-Zustand erreicht haben. Dies ist das standardmäßige Endverhalten, sofern Sie nichtCANCELoderFORCE_CANCELauswählen.
-
-
CANCEL-
CANCELstoppt den Rollout des Auftragsdokuments auf allen verbleibenden Geräten in der Zielgruppe für den Auftrag. Darüber hinaus werden alleQUEUEDAuftragsausführungen abgebrochen, während alleIN_PROGRESSAuftragsausführungen fortgesetzt werden, bis sie einen Terminal-Zustand erreichen.
-
-
FORCE_CANCEL-
FORCE_CANCELstoppt den Rollout des Auftragsdokuments auf allen verbleibenden Geräten in der Zielgruppe für den Auftrag. Darüber hinaus werden alleQUEUED- undIN_PROGRESS-Auftragsausführungen storniert.
-
Anmerkung
Um eine auszuwählenendbehavior, müssen Sie eine auswählen endtime
Max. Dauer
Die Höchstdauer eines geplanten Auftrags muss unabhängig von startTime und endTime unter zwei Jahren liegen.
In der folgenden Tabelle sind die häufigsten Dauerszenarien für einen geplanten Auftrag aufgeführt:
| Beispielnummer für einen geplanten Auftrag | startTime | endTime | Max. Dauer |
|---|---|---|---|
|
1 |
Unmittelbar nach der ersten Auftragserstellung. |
Ein Jahr nach der ersten Auftragserstellung. |
Ein Jahr |
|
2 |
Ein Monat nach der ersten Schaffung von Arbeitsplätzen. |
13 Monate nach der ersten Schaffung von Arbeitsplätzen. |
Ein Jahr |
|
3 |
Ein Jahr nach der ersten Auftragserstellung. |
Zwei Jahre nach der ersten Auftragserstellung. |
Ein Jahr |
|
4 |
Unmittelbar nach der ersten Auftragserstellung. |
Zwei Jahre nach der ersten Auftragserstellung. |
Zwei Jahre |
Wiederkehrendes Wartungsfenster
Das Wartungsfenster ist eine optionale Konfiguration innerhalb der Planungskonfiguration der APIs AWS Management Console und SchedulingConfig innerhalb der CreateJobTemplate APIs CreateJob und. Sie können ein wiederkehrendes Wartungsfenster mit einer festgelegten Startzeit, Dauer und Häufigkeit (täglich, wöchentlich oder monatlich) einrichten. Wartungsfenster gelten nur für fortlaufende Aufträge. Die maximale Dauer eines wiederkehrenden Wartungsfensters beträgt 23 Stunden und 50 Minuten.
Das folgende Diagramm zeigt den Status der Aufträge für verschiedene geplante Auftragsszenarien mit einem optionalen Wartungsfenster:
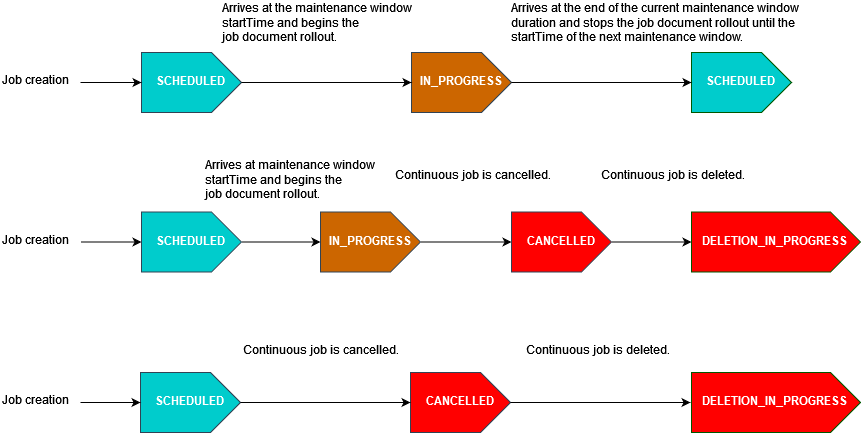
Weitere Informationen zu Auftragsstatus finden Sie unter Aufträge und Status der Auftragsausführung.
Anmerkung
Wenn ein Auftrag endTime während eines Wartungsfensters am eingeht, wird er von IN_PROGRESS bis COMPLETED aktualisiert. Darüber hinaus folgen alle verbleibenden Auftragsausführungen dem endBehavior für den Auftrag.
Cron-Ausdrücke
Bei geplanten Aufträgen, bei denen das Auftragsdokument während eines Wartungsfensters mit einer benutzerdefinierten Häufigkeit ausgeführt wird, wird die benutzerdefinierte Häufigkeit mithilfe eines Cron-Ausdrucks eingegeben. Ein Cron-Ausdruck verfügt über sechs Pflichtfelder, die durch Leerzeichen voneinander getrennt sind.
Syntax
cron(fields)
| Feld | Werte | Platzhalter |
|---|---|---|
|
Minuten |
0-59 |
, - * / |
|
Stunden |
0-23 |
, - * / |
|
D ay-of-month |
1-31 |
, - * ? / L W |
|
Monat |
1-12 oder JAN-DEC |
, - * / |
|
D ay-of-week |
1-7 oder SUN-SAT |
, - * ? / L # |
|
Jahr |
1970-2199 |
, - * / |
Platzhalter
-
Das Platzhalterzeichen , (Komma) schließt zusätzliche Werte ein. Im Feld "Monat" steht JAN, FEB, MAR für Januar, Februar und März.
-
Das Platzhalterzeichen - (Bindestrich) gibt einen Bereich an. Im Feld "Tag" steht 1-15 für die Tage 1 bis 15 des angegebenen Monats.
-
Das Platzhalterzeichen * (Sternchen) steht für alle Werte im Feld. Im Feld für die Stundenangaben steht * für alle Stunden. Sie können * nicht sowohl in den ay-of-week Feldern D als ay-of-month auch in D verwenden. Wenn Sie es in einem der Felder eingeben, müssen Sie im anderen Feld ein ? verwenden.
-
Das Platzhalterzeichen / (Schrägstrich) steht für schrittweise Steigerungen. Im Feld "Minuten" können Sie 1/10 eingeben, um einen Bereich von je 10 Minuten beginnend mit der ersten Minute der Stunde anzugeben (z. B. die 11., 21. und 31. Minute usw.).
-
Das Platzhalterzeichen ? (Fragezeichen) steht für einen Wert. In das ay-of-month D-Feld könnten Sie 7 eingeben, und wenn es Ihnen egal wäre, welcher Wochentag der 7. ist, könnten Sie eingeben? im ay-of-week D-Feld.
-
Der Platzhalter L in den ay-of-week Feldern D ay-of-month oder D gibt den letzten Tag des Monats oder der Woche an.
-
Der
WPlatzhalter im ay-of-month D-Feld gibt einen Wochentag an.3WGibt im ay-of-month Feld D den Wochentag an, der dem dritten Tag des Monats am nächsten liegt. -
Der Platzhalter # im ay-of-week Feld D gibt eine bestimmte Instanz des angegebenen Wochentags innerhalb eines Monats an. Beispiel: 3#2 steht für den zweiten Dienstag des Monats: Die 3 bezieht sich auf Dienstag, da dies der dritte Tag jeder Woche ist, und die 2 bezieht sich auf den zweiten Tag dieses Typs innerhalb des Monats.
Anmerkung
Wenn Sie das Zeichen '#' verwenden, können Sie nur einen Ausdruck in dem day-of-week Feld definieren. Beispiel,
"3#1,6#3"ist ungültig, da es als zwei Ausdrücke interpretiert wird.
Einschränkungen
-
Sie können die ay-of-week Felder D ay-of-month und D nicht in demselben Cron-Ausdruck angeben. Wenn Sie einen Wert (oder einen *) in einem der Felder angeben, müssen Sie in dem anderen Feld ein ? eingeben.
Beispiele
Wenn Sie einen Cron-Ausdruck für ein wiederkehrendes Wartungsfenster verwenden, können Sie sich auf die folgenden Beispiele für startTime beziehen.
| Minuten | Stunden | Tag des Monats | Monat | Wochentag | Jahr | Bedeutung |
|---|---|---|---|---|---|---|
| 0 | 10 | * | * | ? | * |
Ausführung jeden Tag um 10:00 Uhr (UTC) |
| 15 | 12 | * | * | ? | * |
Ausführung jeden Tag um 12:15 Uhr (UTC) |
| 0 | 18 | ? | * | MO-FR | * |
Ausführung jeden Montag bis Freitag um 18:00 Uhr (UTC) |
| 0 | 8 | 1 | * | ? | * |
Ausführung jeden 1. Tag des Monats um 08:00 Uhr (UTC) |
Logik für die Dauer des wiederkehrenden Wartungsfensters
Wenn ein Auftrags-Rollout während eines Wartungsfensters das Ende des aktuellen Wartungsfensters erreicht, werden die folgenden Aktionen ausgeführt:
-
Der Auftrag beendet alle Rollouts des Auftragsdokuments auf allen verbleibenden Geräten in Ihrer Zielgruppe. Es wird mit dem
startTimedes nächsten Wartungsfensters fortgesetzt. -
Alle Auftragsausführungen mit dem Status
QUEUEDbleibenQUEUEDbis zumstartTimedes nächsten Wartungsfenster. Im nächsten Fenster können sie zu demIN_PROGRESSwechseln, zu dem das Gerät bereit ist, mit der Ausführung der im Auftragsdokument angegebenen Aktionen zu beginnen. -
Alle Auftragsausführungen mit dem Status
IN_PROGRESSsetzen die Ausführung der im Auftragsdokument angegebenen Aktionen fort, bis sie den Terminal-Zustand erreichen. Alle Wiederholungsversuche, wie unterJobExecutionsRetryConfigbeschrieben, finden mit demstartTimedes nächsten Wartungsfensters statt.
Verwenden Sie diese Konfiguration, um Kriterien für das Abbrechen eines Auftrags zu erstellen, wenn ein bestimmter Prozentsatz von Geräten diese Kriterien erfüllt. Mit dieser Konfiguration können Sie beispielsweise einen Auftrag in den folgenden Fällen stornieren:
-
Wenn ein bestimmter Prozentsatz von Geräten keine Benachrichtigungen zur Auftragsausführung erhält, z. B. wenn Ihr Gerät für ein Over-The-Air (OTA)-Update nicht kompatibel ist. In diesem Fall kann Ihr Gerät einen
REJECTED-Status melden. -
Wenn ein bestimmter Prozentsatz von Geräten Fehler bei der Auftragsausführung meldet, z. B. wenn Ihr Gerät beim Versuch, das Auftragsdokument von einer Amazon S3-URL herunterzuladen, auf eine Verbindungsunterbrechung stößt. In solchen Fällen muss Ihr Gerät so programmiert sein, dass es den
FAILURE-Status an AWS IoT meldet. -
Wenn ein
TIMED_OUT-Status gemeldet wird, weil die Auftragsausführung nach dem Start der Auftragsausführung für einen bestimmten Prozentsatz von Geräten ein Timeout überschreitet. -
Wenn mehrere Wiederholungsversuche fehlgeschlagen sind. Wenn Sie eine Wiederholungskonfiguration hinzufügen, können für jeden erneuten Versuch zusätzliche Kosten für Ihr AWS-Konto anfallen. In solchen Fällen kann das Abbrechen des Auftrags die Ausführung von Aufträgen in der Warteschlange abbrechen und Wiederholungsversuche für diese Ausführungen verhindern. Weitere Informationen zur Wiederholungskonfiguration und deren Verwendung zusammen mit der Abbruchkonfiguration finden Sie unter Timeout bei der Auftragsausführung und Wiederholungskonfigurationen.
Sie können mithilfe der AWS IoT Konsole oder der Jobs-API eine Abbruchbedingung für einen AWS IoT Job einrichten.
Timeout bei der Auftragsausführung und Wiederholungskonfigurationen
Verwenden Sie die Timeout-Konfiguration für die Auftragsausführung, um Ihnen eine Auftragsbenachrichtigungen zu senden, wenn eine Auftragsausführung länger als die festgelegte Dauer andauert. Verwenden Sie die Konfiguration für die Wiederholung der Auftragsausführung, um die Ausführung erneut zu versuchen, wenn der Auftrag fehlschlägt oder das Timeout überschritten wird.
Verwenden Sie die Konfiguration für die Zeitüberschreitung bei der Auftragsausführung, um Sie zu benachrichtigen, wenn ein Auftrag für einen unerwartet langen Zeitraum im Status IN_PROGRESS stecken bleibt. Wenn der Auftrag IN_PROGRESS ist, können Sie den Fortschritt Ihrer Auftragsausführung überwachen.
Timer für Auftrags-Timeouts
Es gibt zwei Arten von Timern: Timer für „In Bearbeitung“ und Timer für „Schritt“.
Fortschrittstimer
Wenn Sie einen Auftrag oder eine Auftragsvorlage erstellen, können Sie einen Wert für den Timer in Bearbeitung angeben, der zwischen 1 Minute und 7 Tagen liegt. Sie können den Wert dieses Timers bis zum Start der Auftragsausführung aktualisieren. Nachdem Ihr Timer gestartet wurde, kann er nicht mehr aktualisiert werden, und der Timerwert gilt für alle Auftragsausführungen für den Auftrag. Immer wenn eine Auftragsausführung länger als dieses Intervall im IN_PROGRESS Status verbleibt, schlägt die Auftragsausführung fehl und wechselt in den TIMED_OUT Terminalstatus. AWS IoT veröffentlicht auch eine MQTT-Benachrichtigung.
Schritt-Timer
Sie können auch einen Schritt-Timer festlegen, der nur für die Auftragsausführung gilt, die Sie aktualisieren möchten. Dieser Timer hat keine Auswirklungen auf den Timer, der gerade bearbeitet wird. Jedes Mal, wenn Sie eine Auftragsausführung aktualisieren, können Sie einen neuen Wert für den Schritt-Timer festlegen. Sie können auch einen neuen Schritt-Timer erstellen, wenn Sie die nächste ausstehende Auftragsausführung für ein Objekt starten. Falls die Auftragsausführung länger als das Schritt-Timer-Intervall im Status IN_PROGRESS bleibt, schlägt sie fehl und wechselt in den terminalen Status TIMED_OUT.
Anmerkung
Sie können den Timer für die Bearbeitung festlegen, indem Sie die AWS IoT Konsole oder die AWS IoT Jobs-API verwenden. Verwenden Sie die API, um den Schritt-Timer anzugeben.
So funktionieren Timer für Auftrags-Timeouts
Nachfolgend sehen Sie, wie die Zeitüberschreitungen während eines 20-minütigen Zeitlimits und die Schrittzeitüberschreitungen miteinander interagieren.
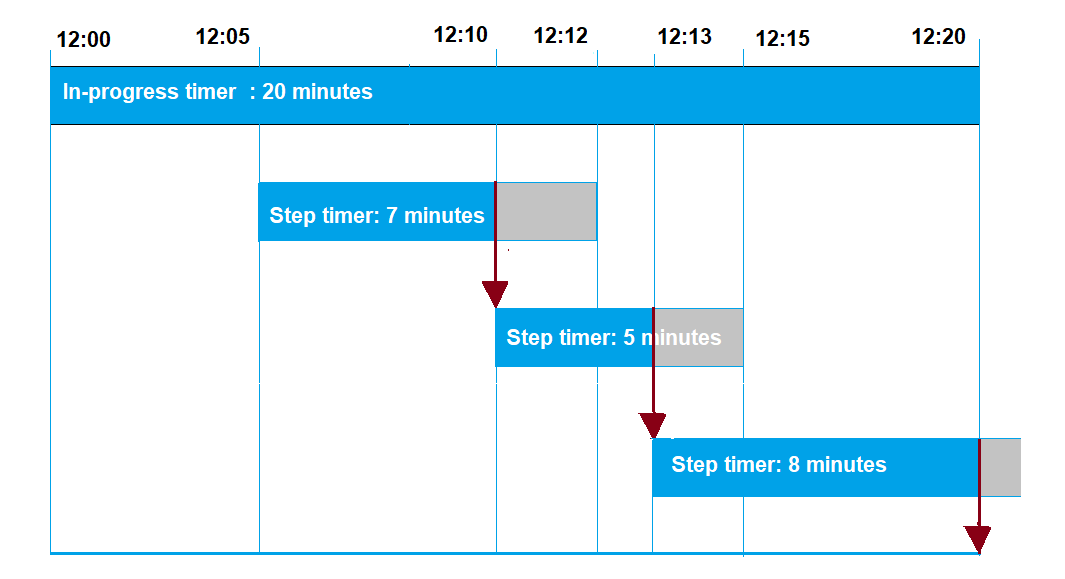
Im Folgenden werden die einzelnen Schritte erläutert:
-
12:00
Beim Erstellen eines Auftrags wird ein neuer Auftrag erstellt und ein Timer für die Dauer von 20 Minuten in Bearbeitung gestartet. Der Timer für die Bearbeitung beginnt zu laufen und die Auftragsausführung wechselt in den Status
IN_PROGRESS. -
12:05
Ein neuer Schritt-Timer mit einem Wert von 7 Minuten wird erstellt. Die Auftragsausführung läuft jetzt um 12:12 Uhr ab.
-
12:10
Ein neuer Schritt-Timer mit einem Wert von 5 Minuten wird erstellt. Wenn ein neuer Schritt-Timer erstellt wird, wird der vorherige Step-Timer verworfen und die Auftragsausführung läuft nun um 12:15 Uhr ab.
-
12:13
Ein neuer Schritt-Timer mit einem Wert von 9 Minuten wird erstellt. Der vorherige Schritt-Timer wird verworfen und die Auftragsausführung läuft jetzt um 12:20 Uhr ab, da der Timer für die Bearbeitung des laufenden Timers um 12:20 Uhr abläuft. Der Schritt-Timer kann die absolute Grenze des laufenden Timers nicht überschreiten.
Sie können die Wiederholungskonfiguration verwenden, um die Ausführung des Auftrags erneut zu versuchen, wenn bestimmte Kriterien erfüllt sind. Ein Wiederholungsversuch kann versucht werden, wenn bei einem Auftrag das Timeout überschritten wird oder wenn das Gerät ausfällt. Um die Ausführung aufgrund eines Timeout-Fehlers erneut zu versuchen, müssen Sie die Timeout-Konfiguration aktivieren.
Wie man Konfiguration wiederholen verwendet
Führen Sie die folgenden Schritte aus, um die Konfiguration zu wiederholen:
-
Bestimmen Sie, ob Sie die Wiederholungskonfiguration für
FAILED,TIMED_OUToder beide Fehlerkriterien verwenden möchten. Was denTIMED_OUT -
Prüfen Sie für den
FAILED-Status, ob Ihr Fehler bei der Auftragsausführung erneut versucht werden kann. Wenn ein erneuter Versuch möglich ist, programmieren Sie Ihr Gerät so, dass es einenFAILURE-Status an AWS IoT meldet. Im folgenden Abschnitt erfahren Sie mehr über wiederholbare und nicht wiederholbare Fehler. -
Geben Sie anhand der obigen Informationen die Anzahl der Wiederholungen an, die für jeden Fehlertyp verwendet werden sollen. Für ein einzelnes Gerät können Sie bis zu 10 Wiederholungsversuche für beide Fehlertypen zusammen angeben. Die Wiederholungsversuche werden automatisch beendet, wenn eine Ausführung erfolgreich ist oder wenn die angegebene Anzahl von Versuchen erreicht wird.
-
Fügen Sie eine Abbruchkonfiguration hinzu, um den Auftrag abzubrechen, wenn wiederholte Wiederholungsversuche fehlschlagen, um zu vermeiden, dass bei einer großen Anzahl von Wiederholungsversuchen zusätzliche Kosten anfallen.
Anmerkung
Wenn ein Auftrag das Ende eines wiederkehrenden Wartungsfensters erreicht, führen alle IN_PROGRESS-Auftragsausführungen weiterhin die im Auftragsdokument angegebenen Aktionen aus, bis sie den Terminal-Zustand erreichen. Wenn die Ausführung eines Auftrags außerhalb eines Wartungsfensters den Terminal-Zustand FAILED oder TIMED_OUT erreicht, wird im nächsten Fenster ein erneuter Versuch unternommen, wenn die Versuche nicht erschöpft sind. Beim startTime des Wartungsfensters wird eine neue Auftragsausführung erstellt, die in den Status QUEUED wechselt, bis das Gerät startbereit ist.
Versuchen Sie es erneut und brechen Sie die Konfiguration ab
Für jeden erneuten Versuch fallen zusätzliche Kosten für Sie an. AWS-Konto Um zu vermeiden, dass zusätzliche Gebühren aufgrund wiederholter Wiederholungsversuche anfallen, empfehlen wir, eine Abbruchkonfiguration hinzuzufügen. Weitere Informationen zu Preisen finden Sie unter AWS IoT Device Management
Preise
Es kann vorkommen, dass mehrere Wiederholungsversuche fehlschlagen, wenn bei einem hohen Prozentsatz Ihrer Geräte ein Timeout auftritt oder ein Fehler gemeldet wird. In diesem Fall können Sie die Abbruchkonfiguration verwenden, um den Auftrag abzubrechen und so zu vermeiden, dass Aufträge in der Warteschlange ausgeführt oder weitere Versuche wiederholt werden.
Anmerkung
Wenn die Abbruchkriterien für den Abbruch einer Auftragsausführung erfüllt sind, werden nur QUEUED-Auftragsausführungen abgebrochen. Wiederholungen in der Warteschlange für das Gerät werden nicht versucht. Aktuelle Auftragsausführungen, die einen IN_PROGRESS-Status haben, werden jedoch nicht abgebrochen.
Bevor Sie eine fehlgeschlagene Auftragsausführung erneut versuchen, empfehlen wir Ihnen außerdem, zu überprüfen, ob die fehlgeschlagene Auftragsausführung erneut versucht werden kann, wie im folgenden Abschnitt beschrieben.
Wiederholungsversuch bei Fehlerart FAILED
Um Wiederholungsversuche für den Fehlertyp FAILED zu versuchen, müssen Ihre Geräte so programmiert sein, dass sie den FAILURE.Status einer fehlgeschlagenen Auftragsausführung an AWS IoT melden. Legen Sie die Wiederholungskonfiguration mit den Kriterien fest, nach denen die FAILED Auftragsausführung wiederholt werden soll, und geben Sie die Anzahl der auszuführenden Wiederholungen an. Wenn AWS IoT Jobs den FAILURE Status erkennt, wird automatisch versucht, die Auftragsausführung für das Gerät erneut zu versuchen. Die Wiederholungsversuche werden fortgesetzt, bis die Auftragsausführung erfolgreich ist oder die maximale Anzahl von Wiederholungsversuchen erreicht ist.
Sie können jeden Wiederholungsversuch und den Auftrag, der auf diesen Geräten ausgeführt wird, verfolgen. Indem Sie den Ausführungsstatus verfolgen, können Sie nach der angegebenen Anzahl von Wiederholungsversuchen Ihr Gerät verwenden, um Fehler zu melden und einen weiteren Wiederholungsversuch einzuleiten.
Fehler, die wiederholt werden können und die nicht wiederholt werden können
Ihr Fehler bei der Auftragsausführung kann wiederholt oder nicht wiederholt werden. Für jeden Wiederholungsversuch können Gebühren für Ihr AWS-Konto anfallen. Um zu vermeiden, dass bei mehreren Wiederholungsversuchen zusätzliche Gebühren anfallen, sollten Sie zunächst prüfen, ob Ihr Fehler bei der Auftragsausführung erneut versucht werden kann. Ein Beispiel für einen erneuten Versuch ist ein Verbindungsfehler, der auf Ihrem Gerät auftritt, wenn versucht wird, das Auftragsdokument von einer Amazon S3-URL herunterzuladen. Wenn Ihr Fehler bei der Auftragsausführung erneut versucht werden kann, programmieren Sie Ihr Gerät so, dass es einen FAILURE-Status meldet, falls die Auftragsausführung fehlschlägt. Stellen Sie dann die Wiederholungskonfiguration so ein, dass FAILED-Ausführungen erneut versucht werden.
Wenn die Ausführung nicht erneut versucht werden kann, empfehlen wir, das Gerät so zu programmieren, dass es einen REJECTED-Status an AWS IoT meldet, um einen erneuten Versuch zu vermeiden und Ihrem Konto möglicherweise zusätzliche Gebühren aufzuerlegen. Ein Fehler, der nicht wiederholt werden kann, ist zum Beispiel, wenn Ihr Gerät keine Auftragsaktualisierung empfangen kann oder wenn bei der Ausführung eines Auftrags ein Speicherfehler auftritt. In diesen Fällen versucht AWS IoT Jobs die Auftragsausführung nicht erneut, da Jobs die Ausführung des Jobs nur dann wiederholt, wenn der Status oder erkannt wird. FAILED TIMED_OUT
Wenn Sie festgestellt haben, dass ein Fehler bei der Auftragsausführung erneut versucht werden kann, sollten Sie die Geräteprotokolle überprüfen, falls ein erneuter Versuch immer noch fehlschlägt.
Anmerkung
Wenn ein Auftrag mit der optionalen Planungskonfiguration seinen endTime erreicht, stoppt endBehavior die Auswahl die Bereitstellung des Auftragsdokuments auf allen verbleibenden Geräten in der Zielgruppe und bestimmt, wie mit den verbleibenden Auftragsausführungen fortgefahren werden soll. Die Versuche werden wiederholt, wenn sie über die Wiederholungskonfiguration ausgewählt wurden.
Wiederholungsversuch bei Fehlerart TIMEOUT
Wenn Sie bei der Erstellung eines Jobs das Timeout aktivieren, versucht AWS IoT Jobs, die Auftragsausführung für das Gerät erneut zu versuchen, wenn der Status von zu wechselt. IN_PROGRESS TIMED_OUT Diese Statusänderung kann auftreten, wenn für den Timer in Bearbeitung eine Zeitüberschreitung eintritt oder wenn ein von Ihnen festgelegter Schritt-Timer in IN_PROGRESS ist und dann das Zeitlimit überschritten wird. Die Wiederholungsversuche werden fortgesetzt, bis die Auftragsausführung erfolgreich ist oder bis die maximale Anzahl von Wiederholungsversuchen für diesen Fehlertyp erreicht ist.
Fortlaufende Aktualisierungen von Aufträgen und Mitgliedschaften in Objektgruppen
Bei kontinuierlichen Aufträgen mit dem Auftragsstatus IN_PROGRESS wird die Anzahl der Wiederholungsversuche auf Null zurückgesetzt, wenn die Gruppenmitgliedschaft eines Objekts aktualisiert wird. Nehmen wir beispielsweise an, Sie haben fünf Wiederholungsversuche angegeben und drei Wiederholungsversuche wurden bereits durchgeführt. Wenn ein Ding jetzt aus der Objektgruppe entfernt wird und dann wieder der Gruppe beitritt, z. B. bei dynamischen Objektgruppen, wird die Anzahl der Wiederholungsversuche auf Null zurückgesetzt. Sie können jetzt fünf Wiederholungsversuche für Ihre Objektgruppe durchführen, anstatt der beiden verbleibenden Versuche. Wenn ein Objekt aus der Objektgruppe entfernt wird, werden außerdem weitere Wiederholungsversuche abgebrochen.
