Nach reiflicher Überlegung haben wir uns entschieden, Amazon Kinesis Data Analytics für SQL-Anwendungen einzustellen:
1. Ab dem 1. September 2025 werden wir keine Bugfixes für Amazon Kinesis Data Analytics for SQL-Anwendungen bereitstellen, da wir aufgrund der bevorstehenden Einstellung nur eingeschränkten Support dafür haben werden.
2. Ab dem 15. Oktober 2025 können Sie keine neuen Kinesis Data Analytics for SQL-Anwendungen mehr erstellen.
3. Wir werden Ihre Anwendungen ab dem 27. Januar 2026 löschen. Sie können Ihre Amazon Kinesis Data Analytics for SQL-Anwendungen nicht starten oder betreiben. Ab diesem Zeitpunkt ist kein Support mehr für Amazon Kinesis Data Analytics for SQL verfügbar. Weitere Informationen finden Sie unter Einstellung von Amazon Kinesis Data Analytics für SQL-Anwendungen.
Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Beispiel: Versetztes Fenster
Wenn eine fensterorientierte Abfrage separate Fenster für jeden eindeutigen Partitionsschlüssel verarbeitet und damit beginnt, wenn Daten mit übereinstimmendem Schlüssel ankommen, wird das Fenster als versetztes Fenster bezeichnet. Details hierzu finden Sie unter Versetzte Fenster. Dieses Amazon-Kinesis-Data-Analytics-Beispiel verwendet die Spalten EVENT_TIME und TICKER, um versetzte Fenster zu erstellen. Der Quell-Stream enthält Gruppen von sechs Datensätzen mit identischen EVENT_TIME- und TICKER-Werten, die innerhalb eines einminütigen Zeitraums ankommen, aber nicht denselben Minutenwert (z. B. 18:41:xx) aufweisen müssen.
In diesem Beispiel schreiben Sie die folgenden Datensätze zu den folgenden Zeiten in einen Kinesis-Datenstrom. Das Skript schreibt die Zeiten nicht in den Stream. Allerdings wird der Zeitpunkt, zu dem der Datensatz von der Anwendung übernommen wird, in das ROWTIME-Feld geschrieben:
{"EVENT_TIME": "2018-08-01T20:17:20.797945", "TICKER": "AMZN"} 20:17:30 {"EVENT_TIME": "2018-08-01T20:17:20.797945", "TICKER": "AMZN"} 20:17:40 {"EVENT_TIME": "2018-08-01T20:17:20.797945", "TICKER": "AMZN"} 20:17:50 {"EVENT_TIME": "2018-08-01T20:17:20.797945", "TICKER": "AMZN"} 20:18:00 {"EVENT_TIME": "2018-08-01T20:17:20.797945", "TICKER": "AMZN"} 20:18:10 {"EVENT_TIME": "2018-08-01T20:17:20.797945", "TICKER": "AMZN"} 20:18:21 {"EVENT_TIME": "2018-08-01T20:18:21.043084", "TICKER": "INTC"} 20:18:31 {"EVENT_TIME": "2018-08-01T20:18:21.043084", "TICKER": "INTC"} 20:18:41 {"EVENT_TIME": "2018-08-01T20:18:21.043084", "TICKER": "INTC"} 20:18:51 {"EVENT_TIME": "2018-08-01T20:18:21.043084", "TICKER": "INTC"} 20:19:01 {"EVENT_TIME": "2018-08-01T20:18:21.043084", "TICKER": "INTC"} 20:19:11 {"EVENT_TIME": "2018-08-01T20:18:21.043084", "TICKER": "INTC"} 20:19:21 ...
Anschließend erstellen Sie eine Kinesis Data Analytics Analytics-Anwendung in der AWS Management Console, mit dem Kinesis-Datenstream als Streaming-Quelle. Der Erkennungsvorgang liest Beispieldatensätze aus der Streaming-Quelle und leitet wie nachstehend veranschaulicht ein In-Application-Schema mit zwei Spalten (EVENT_TIME und TICKER) ab.
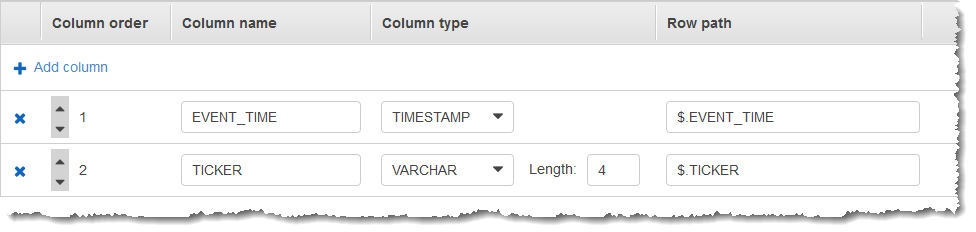
Sie verwenden den Anwendungscode mit der Funktion COUNT, um eine fensterbasierte Aggregation der Daten zu erstellen. Danach fügen Sie die resultierenden Daten wie im folgenden Screenshot dargestellt in einen anderen In-Application-Stream ein:
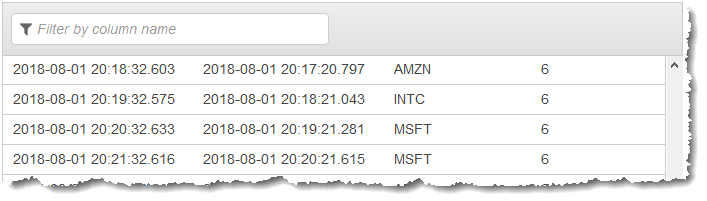
Im folgenden Verfahren erstellen Sie eine Kinesis Data Analytics-Anwendung, die Werte im Eingabe-Stream in einem versetzten Fenster basierend auf EVENT_TIME und TICKER aggregiert.
Themen
Schritt 1: Erstellen eines Kinesis-Datenstroms
Erstellen Sie einen Amazon-Kinesis-Datenstrom und füllen Sie die Datensätze wie folgt aus:
Melden Sie sich bei der an AWS Management Console und öffnen Sie die Kinesis-Konsole unter https://console.aws.amazon.com/kinesis
. -
Klicken Sie im Navigationsbereich auf Data Streams (Daten-Streams).
-
Klicken Sie auf Create Kinesis stream (Kinesis-Stream erstellen) und erstellen Sie dann einen Stream mit einer Shard. Weitere Informationen finden Sie unter Einen Stream erstellen im Amazon-Kinesis-Data-Streams-Entwicklerhandbuch.
-
Um Datensätze in einer Produktionsumgebung in einen Kinesis-Daten-Stream zu schreiben, empfiehlt sich die Verwendung der Kinesis Producer Library oder der API der Kinesis-Daten-Streams. Der Einfachheit halber werden in diesem Beispiel mit dem Python-Skript Datensätze generiert. Führen Sie den Code aus, um die Beispiel-Ticker-Datensätze zu füllen. Dieser einfache Code schreibt während einer Minute kontinuierlich eine Gruppe von sechs Datensätzen mit derselben zufälligen
EVENT_TIMEund demselben Tickersymbol in den Stream. Führen Sie das Skript weiter aus, damit Sie das Anwendungsschema später erstellen können.import datetime import json import random import time import boto3 STREAM_NAME = "ExampleInputStream" def get_data(): event_time = datetime.datetime.utcnow() - datetime.timedelta(seconds=10) return { "EVENT_TIME": event_time.isoformat(), "TICKER": random.choice(["AAPL", "AMZN", "MSFT", "INTC", "TBV"]), } def generate(stream_name, kinesis_client): while True: data = get_data() # Send six records, ten seconds apart, with the same event time and ticker for _ in range(6): print(data) kinesis_client.put_record( StreamName=stream_name, Data=json.dumps(data), PartitionKey="partitionkey", ) time.sleep(10) if __name__ == "__main__": generate(STREAM_NAME, boto3.client("kinesis"))
Schritt 2: Erstellen Sie die Amazon-Kinesis-Data-Analytics-Anwendung
Erstellen Sie wie folgt eine Kinesis Data Analytics-Anwendung:
-
Klicken Sie auf Create application (Anwendung erstellen), geben Sie einen Anwendungsnamen ein und klicken Sie erneut auf Create application (Anwendung erstellen).
-
Wählen Sie auf der Detailseite der Anwendung Connect streaming data (Streaming-Daten verbinden), um eine Verbindung mit der Quelle herzustellen.
-
Gehen Sie auf der Seite Connect to source (Mit Quelle verbinden) wie folgt vor:
-
Wählen Sie den Stream aus, den Sie im vorherigen Abschnitt erstellt haben.
-
Klicken Sie auf Discover schema (Schema erkennen). Warten Sie, bis die Konsole das abgeleitete Schema und die Beispieldatensätze anzeigt, die zum Ableiten des Schemas für den erstellten In-Application-Stream verwendet werden. Das abgeleitete Schema verfügt über zwei Spalten.
-
Klicken Sie auf Edit schema (Schema bearbeiten). Ändern Sie den Wert für Column type (Spaltentyp) der Spalte EVENT_TIME in
TIMESTAMP. -
Wählen Sie Save schema and update stream samples (Schema speichern und Stream-Beispiel aktualiseren). Nachdem die Konsole das Schema gespeichert hat, klicken Sie auf Exit (Beenden).
-
Wählen Sie Save and continue aus.
-
-
Klicken Sie auf der Detailseite der Anwendung auf Go to SQL editor (Gehe zu SQL-Editor). Um die Anwendung zu starten, wählen Sie im angezeigten Dialogfeld Yes, start application (Ja, Anwendung starten) aus.
-
Schreiben Sie im SQL-Editor den Anwendungscode und überprüfen Sie die Ergebnisse wie folgt:
-
Kopieren Sie den folgenden Anwendungscode und fügen Sie diesen in den Editor ein.
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" ( event_time TIMESTAMP, ticker_symbol VARCHAR(4), ticker_count INTEGER); CREATE OR REPLACE PUMP "STREAM_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM" SELECT STREAM EVENT_TIME, TICKER, COUNT(TICKER) AS ticker_count FROM "SOURCE_SQL_STREAM_001" WINDOWED BY STAGGER ( PARTITION BY TICKER, EVENT_TIME RANGE INTERVAL '1' MINUTE); -
Klicken Sie auf Save and run SQL (SQL speichern und ausführen).
Auf der Registerkarte Real-time analytics (Echtzeitanalyse) können Sie alle In-Application-Streams sehen, die von der Anwendung erstellt wurden, und die Daten überprüfen.
-
