Wir aktualisieren den Amazon Machine Learning Learning-Service nicht mehr und akzeptieren keine neuen Benutzer mehr dafür. Diese Dokumentation ist für bestehende Benutzer verfügbar, wir aktualisieren sie jedoch nicht mehr. Weitere Informationen finden Sie unterWas Amazon Machine Learning.
Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Binäre Klassifizierung
Die tatsächliche Ausgabe von vielen binären Klassifizierungsalgorithmen ist eine Voraussagepunktzahl. Die Punktzahl gibt die Sicherheit des Systems an, dass die angegebene Beobachtung der positiven Klasse angehört. Sie können die Punktzahl interpretieren, indem Sie einen Klassifizierungsschwellenwert oder Grenzwert festlegen und die Punktzahl damit vergleichen, um zu entscheiden, ob die Beobachtung als positiv oder negativ klassifiziert wird. Alle Beobachtungen mit Punkteständen höher als der Schwellenwert werden als positive Klasse vorausgesagt, undPunktestände unter dem Schwellenwert werden als negative Klasse vorausgesagt.
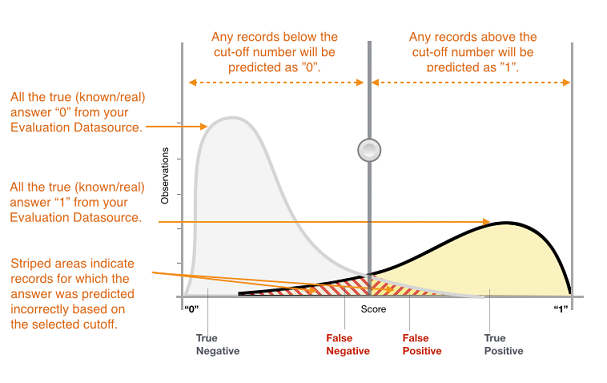
Abbildung 1: Verteilung der Punkte für ein binäres Klassifikationsmodell
Die Voraussagen werden nun basierend auf der tatsächlichen bekannten Antwort und der vorausgesagten Antwort in vier Gruppen unterteilt: richtige positive Voraussagen (echte Positive), richtige negative Voraussagen (echte Negative), falsche positive Voraussagen (falsche Positive) und falsche negative Voraussagen (falsche Negative).
Richtigkeitsmetriken für die binäre Klassifizierung quantifizieren zwei Arten von richtigen Voraussagen und zwei Arten von Fehlern. Typische Metriken sind Richtigkeit (ACC), Präzision, Wiedererkennung, Falschpositivrate, F1-measure. Jede Metrik misst einen anderen Aspekt des Voraussagemodells. Die Richtigkeit (ACC) misst den Anteil der richtigen Voraussagen. Genauigkeit misst den Anteil der tatsächlichen Positiva unter den Beispielen, die als positiv vorausgesagt wurden. Wiedererkennung misst, wie viele tatsächliche Positive als positiv vorausgesagt wurden. F1-measure ist das harmonische Mittel von Genauigkeit und Wiedererkennung.
AUC ist eine andere Art der Metrik. Sie misst die Fähigkeit des Modells, eine höhere Bewertung für positive Beispiele im Vergleich zu negativen Beispielen vorherzusagen. Da die AUC unabhängig vom ausgewählten Schwellenwert ist, bekommen Sie ein Gefühl für die Voraussageleistung Ihres Modells aus der AUC-Metrik, ohne einen Schwellenwert auszuwählen.
Abhängig von Ihrem Unternehmensproblem benötigen Sie vielleicht eher ein Modell, das für eine bestimmte Teilmenge dieser Metriken gut funktioniert. Zwei Unternehmensanwendungen können beispielsweise sehr unterschiedliche Anforderungen an ihre ML-Modelle haben:
Eine Anwendung muss vielleicht sehr sicher sein, dass die positiven Voraussagen tatsächlich positiv sind (hohe Präzision) und kann es verkraften, dass einige positive Beispiele falsch als negativ klassifiziert werden (moderate Wiedererkennung).
Eine andere Anwendung soll so viele positive Beispiele wie möglich korrekt voraussagen (hohe Wiedererkennung) und nimmt es in Kauf, dass einige negative Beispiele falsch als positiv klassifiziert werden (moderate Genauigkeit).
In Amazon ML erhalten Beobachtungen eine vorausgesagte Punktzahl im Bereich [0,1]. Der Schwellenwert für die Entscheidung für die Klassifizierung von Beispielen als 0 oder 1 ist standardmäßig auf 0,5 festgelegt. Mit Amazon ML können Sie die Auswirkungen der Auswahl von unterschiedlichen Schwellenwerten prüfen und einen geeigneten Schwellenwert wählen, das Ihren geschäftlichen Anforderungen entspricht.
