Wir aktualisieren den Amazon Machine Learning Learning-Service nicht mehr und akzeptieren auch keine neuen Nutzer mehr dafür. Diese Dokumentation ist für bestehende Benutzer verfügbar, wir aktualisieren sie jedoch nicht mehr. Weitere Informationen finden Sie unter Was ist Amazon Machine Learning.
Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Dateneinblicke
Amazon ML berechnet deskriptive Statistiken zu Ihren Eingabedaten, anhand derer Sie Ihre Daten verstehen können.
Beschreibende Statistiken
Amazon ML berechnet die folgenden beschreibenden Statistiken für verschiedene Attributtypen:
Numerischer Wert:
-
Verteilungshistogramme
-
Anzahl ungültiger Werte
-
Minimale, mittlere, durchschnittliche und maximale Werte
Binär und kategorisch:
-
Anzahl (eindeutige Werte pro Kategorie)
-
Wertverteilungshistogramm
-
Häufigste Werte
-
Anzahl eindeutiger Werte
-
Prozentsatz des tatsächlichen Werts (nur binär)
-
Bedeutendste Wörter
-
Häufigste Wörter
Text:
-
Name des Attributs
-
Korrelation zum Ziel (wenn ein Ziel festgelegt ist)
-
Wörter gesamt
-
Eindeutige Wörter
-
Umfang der Anzahl der Wörter in einer Zeile
-
Umfang der Wortlängen
-
Bedeutendste Wörter
Zugreifen auf Data Insights über die Amazon ML-Konsole
In der Amazon ML-Konsole können Sie den Namen oder die ID einer beliebigen Datenquelle auswählen, um deren Data Insights-Seite anzuzeigen. Auf dieser Seite finden Sie Metriken und Visualisierungen, mit deren Hilfe Sie mehr über die Eingabedaten in Verbindung mit der Datenquelle erfahren, einschließlich der folgenden Informationen:
-
Datenzusammenfassung
-
Zielverteilungen
-
Fehlende Werte
-
Ungültige Werte
-
Zusammenfassende Statistik der Variablen nach Datentyp
-
Verteilung der Variablen nach Datentyp
In den folgenden Abschnitten werden die Metriken und Visualisierungen im Detail beschrieben.
Datenzusammenfassung
Der zusammenfassende Datenbericht einer Datenquelle enthält zusammenfassende Informationen, einschließlich der Datenquellen-ID, Name, wo sie abgeschlossen wurde, aktueller Status, Zielattribut, Eingabedateninformationen (S3-Bucket-Speicherort, Datenformat, Anzahl der verarbeiteten Datensätze und Anzahl der fehlerhaften Datensätze während der Verarbeitung) sowie die Anzahl der Variablen nach Datentyp.
Zielverteilungen
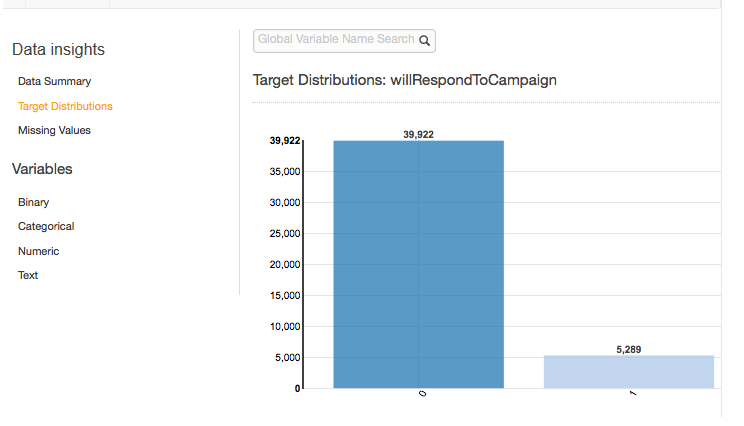
Der Zielverteilungsbericht zeigt die Verteilung von Zielattributen der Datenquelle. Im folgenden Beispiel gibt es 39.922 Beobachtungen, bei denen das Zielattribut „will RespondToCampaign target“ gleich 0 ist. Dies ist die Anzahl der Kunden, die nicht auf die E-Mail-Kampagne reagiert haben. Es gibt 5.289 Beobachtungen, bei denen Will gleich 1 ist. RespondToCampaign Dies ist die Anzahl der Kunden, die auf die E-Mail-Kampagne reagiert haben.
Fehlende Werte
Der Bericht über fehlende Werte listet die Attribute in den Eingabedaten auf, für die Werte fehlen. Nur Attribute mit numerischen Datentypen können fehlende Werte haben. Da fehlende Werte sich auf die Qualität der Schulung eines ML-Modells auswirken können, empfehlen wir, dass fehlende Werte angegeben werden, falls möglich.
Wenn beim ML-Modelltraining das Zielattribut fehlt, lehnt Amazon ML den entsprechenden Datensatz ab. Wenn das Zielattribut im Datensatz vorhanden ist, aber ein Wert für ein anderes numerisches Attribut fehlt, übersieht Amazon ML den fehlenden Wert. In diesem Fall erstellt Amazon ML ein Ersatzattribut und setzt es auf 1, um anzuzeigen, dass dieses Attribut fehlt. Auf diese Weise kann Amazon ML Muster aus dem Auftreten fehlender Werte lernen.
Ungültige Werte
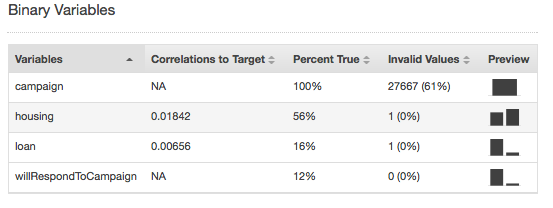
Ungültige Werte können nur bei numerischen und binären Datentypen auftreten. Sie können ungültige Werte suchen, indem Sie die zusammenfassenden Statistiken von Variablen in den Datentypberichten anzeigen. In den folgenden Beispielen gibt es nur einen ungültigen Wert im numerischen Attribut "Duration" und zwei ungültige Werte im binären Datentyp (einer im Attribut "Housing" und einer im Attribut "Loan").

Variable-Target Korrelation
Nachdem Sie eine Datenquelle erstellt haben, kann Amazon ML die Datenquelle auswerten und die Korrelation oder Auswirkung zwischen Variablen und dem Ziel identifizieren. Beispielsweise ist es möglich, dass der Preis eines Produkts signifikante Auswirkungen darauf hat, ob es ein Bestseller wird, während die Abmessungen des Produkts wahrscheinlich wenig Vorhersagekraft haben.
Eine bewährte Methode ist es, so viele Variablen wie möglich in die Schulungsdaten einzuschließen. Das Datenrauschen durch viele Variablen mit wenig Vorhersagekraft kann jedoch die Qualität und die Richtigkeit Ihres ML-Modells negativ beeinflussen.
Sie können die prädiktive Leistung Ihres Modells verbessern, indem Sie Variablen mit wenig Auswirkungen während der Modellschulung entfernen. Sie können in einem Rezept definieren, welche Variablen dem maschinellen Lernprozess zur Verfügung gestellt werden. Dabei handelt es sich um einen Transformationsmechanismus von Amazon ML. Weitere Informationen zu Rezepten finden Sie unter Data Transformation for Machine Learning.
Zusammenfassende Statistik der Attribute nach Datentyp
Im Bericht zu Dateneinblicken können Sie zusammenfassende Attributstatistiken nach den folgenden Datentypen anzeigen:
-
Binär
-
Kategorisch
-
Numerischer Wert
-
Text
Zusammenfassende Statistiken für binären Datentypen zeigen alle binären Attribute. Die Spalte Correlations to target zeigt die zwischen der Zielspalte und der Attributspalte gemeinsam genutzten Informationen. Die Spalte Percent true zeigt den Prozentsatz der Beobachtungen mit dem Wert "1" an. In der Spalte Invalid values wird die Anzahl der ungültigen Werte und der Prozentsatz der ungültigen Werte für jedes Attribut angezeigt. In der Spalte Preview finden Sie einen Link zu einer grafischen Verteilung für jedes Attribut.
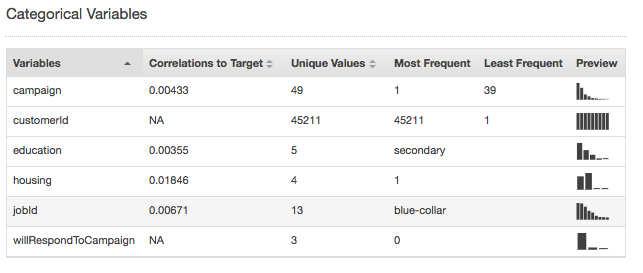
Zusammenfassende Statistiken für den kategorischen Datentyp zeigen aller kategorischen Attribute mit der Anzahl eindeutiger Werte, häufigster Wert und seltenster Wert. In der Spalte Preview finden Sie einen Link zu einer grafischen Verteilung für jedes Attribut.
Zusammenfassende Statistiken für den numerischen Datentyp zeigen alle numerischen Attributen mit der Anzahl fehlender Werte, ungültiger Werte, Wertebereich, durchschnittlicher und mittlerer Wert. In der Spalte Preview finden Sie einen Link zu einer grafischen Verteilung für jedes Attribut.
Zusammenfassende Statistiken für den Datentyp Text zeigen alle Textattribute, die Gesamtanzahl der Wörter in diesem Attribut, die Anzahl der eindeutigen Wörter in diesem Attribut, den Umfang von Wörtern in einem Attribut, den Umfang der Wortlängen und die bedeutendsten Wörter. In der Spalte Preview finden Sie einen Link zu einer grafischen Verteilung für jedes Attribut.
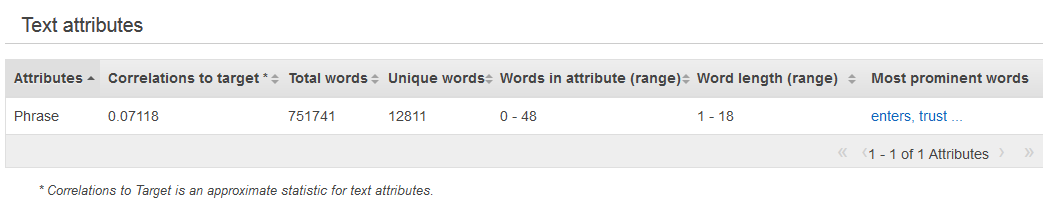
Das folgende Beispiel zeigt Statistiken für den Datentyp Text für eine Textvariable mit dem Namen "Review", mit vier Datensätzen.
1. The fox jumped over the fence. 2. This movie is intriguing. 3. 4. Fascinating movie.
Die Spalten für dieses Beispiel würden die folgenden Informationen anzeigen.
-
Die Spalte Attributes zeigt den Namen der Variablen an. In diesem Beispiel heißt die Spalte "Review".
-
Die Spalte Correlations to target existiert nur, wenn ein Ziel angegeben ist. Korrelationen messen die Menge an Informationen, die dieses Attribut über das Ziel bietet. Je höher die Korrelation, desto mehr erfahren Sie aus diesem Attribut über das Ziel. Korrelation wird in Form von gegenseitigen Informationen zwischen einer vereinfachten Darstellung des Textattributs und des Ziels gemessen.
-
Die Spalte Total words zeigt die Anzahl der Wörter, die durch Aufgliederung jeden Datensatzes in Token generiert werden, wobei Wörter durch Leerzeichen getrennt werden. In diesem Beispiel enthält die Spalte "12".
-
Die Spalte Unique words zeigt die Anzahl der eindeutigen Wörter für ein Attribut an. In diesem Beispiel enthält die Spalte "10".
-
Die Spalte Words in attribute (range) zeigt die Anzahl der Wörter in einer einzigen Zeile im Attribut an. In diesem Beispiel enthält die Spalte "0-6".
-
Die Spalte Word length (range) zeigt den Umfang an, wie viele Zeichen in den Wörtern enthalten sind. In diesem Beispiel enthält die Spalte "2-11".
-
Die Spalte Most prominent words zeigt eine Rangliste der Wörter, die im Attribut vorhanden sind. Wenn es ein Zielattribut gibt, werden Wörter anhand ihrer Korrelation zum Ziel sortiert. Das bedeutet, dass die Wörter mit der höchsten Korrelation zuerst aufgelistet werden. Wenn kein Ziel in den Daten vorhanden ist, werden die Wörter anhand ihres mittlerer Informationsgehalts in Rangfolge gebracht.
Erläuterungen zur Verteilung von kategorischen und binären Attributen
Durch Klicken auf den Link Preview für das kategorische oder binäre Attribut können Sie die Verteilung des Attributs sowie die Beispieldaten aus der Eingabedatei für jeden kategorischen Wert des Attributs anzeigen.
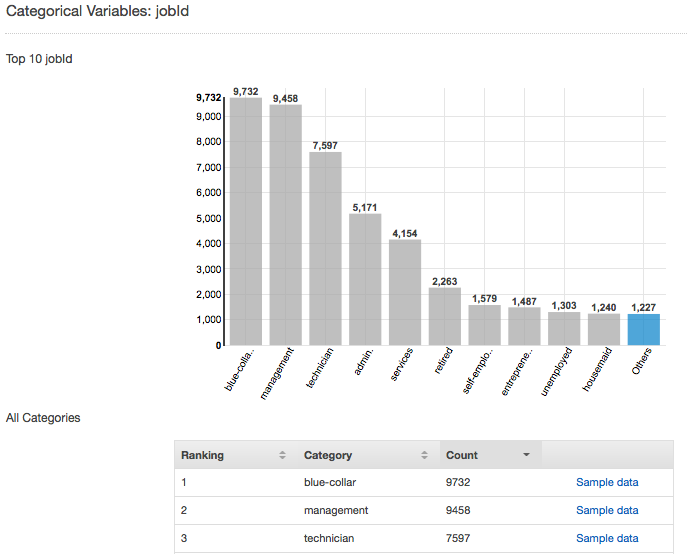
Die folgende Abbildung zeigt die Verteilung für das kategorische Attribut jobId. Die Verteilung zeigt die 10 häufigsten kategorischen Werte, alle anderen Werte sind als "other" gruppiert. Sie stuft jeden der 10 häufigsten kategorischen Werte nach der Anzahl der Beobachtungen in der Eingabedatei ein, die diesen Wert enthält, sowie einem Link zur Anzeige von Beispielbeobachtungen aus der Eingabedatendatei.
Erläuterungen zur Verteilung von numerischen Attributen
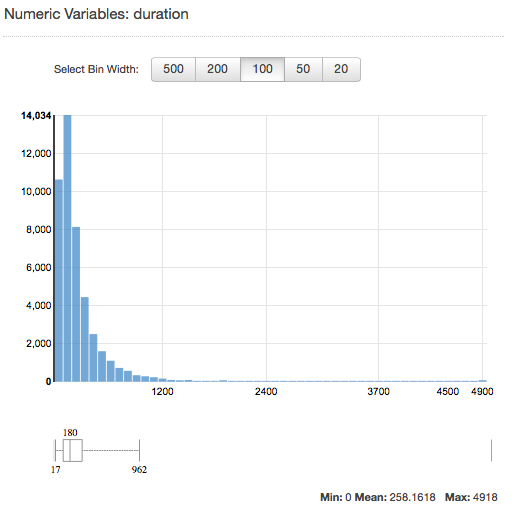
Um die Verteilung eines numerischen Attributs anzuzeigen, klicken Sie auf den Link Preview für das Attribut. Wenn Sie die Verteilung eines numerischen Attributs erstellen, können Sie Bin-Größen von 500, 200, 100, 50 oder 20 festlegen. Die größer die Bin-Größe, um so kleiner die Anzahl der Balkendiagramme, die angezeigt werden. Darüber hinaus wird die Auflösung der Verteilung für große Bin-Größen recht grob. Im Gegensatz dazu erhöht das Festlegen der Bucket-Größe auf 20 die Auflösung der angezeigten Verteilung.
Die minimalen, mittleren und maximalen Werte werden ebenfalls angezeigt (siehe Abbildung).
Erläuterungen zur Verteilung von Textattributen
Um die Verteilung eines Textattributs anzuzeigen, klicken Sie auf den Link Preview für das Attribut. Bei der Anzeige der Verteilung eines Textattributs sehen Sie die folgenden Informationen.
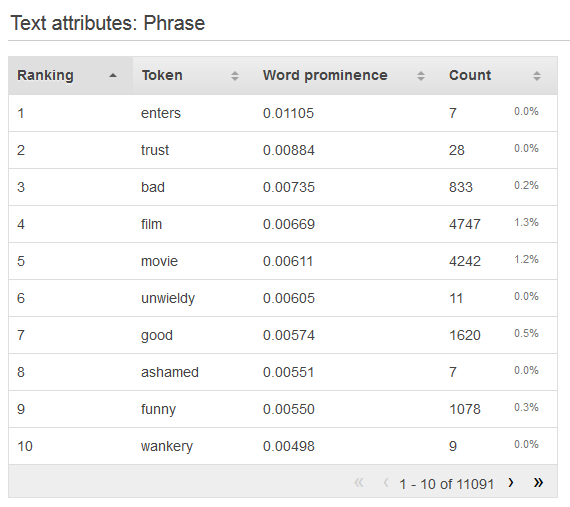
- Ranking
-
Texttoken werden anhand der Menge der übermittelten Informationen angeordnet, von am meisten informativen bis zu am wenigsten informativ.
- Token
-
Das Token zeigt das Wort aus dem Eingabetext, auf das sich die Statistikzeile bezieht.
- Wortbedeutung
-
Wenn es ein Zielattribut gibt, werden Wörter anhand ihrer Korrelation zum Ziel sortiert. Das bedeutet, dass die Wörter mit der höchsten Korrelation zuerst aufgelistet werden. Wenn kein Ziel in den Daten vorhanden ist, werden die Wörter anhand ihrer Entropie in Rangfolge gebracht, d. h. die Menge an Informationen, die sie kommunizieren können.
- Anzahl
-
Die Anzahl zeigt die Anzahl der Eingabedatensätze, in denen das Token vorhanden ist.
- Prozentsatz
-
Der Prozentsatz zeigt den prozentualen Anteil der Eingabedatenzeilen, in denen das Token vorhanden ist.
