Wir aktualisieren den Amazon Machine Learning Learning-Service nicht mehr und akzeptieren auch keine neuen Nutzer mehr dafür. Diese Dokumentation ist für bestehende Benutzer verfügbar, wir aktualisieren sie jedoch nicht mehr. Weitere Informationen finden Sie unter Was ist Amazon Machine Learning.
Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Regressionsmodell-Einblicke
Interpretieren der Voraussagen
Die Ausgabe eines ML-Regressionsmodells ist ein numerischer Wert für die Modellvoraussage des Ziels. Wenn Sie beispielsweise Wohnungspreise voraussagen, kann die Voraussage des Modells ein Wert wie 254 013 sein.
Anmerkung
Der Ergebnisbereich der Voraussagen muss nicht mit dem Bereich des Ziels in den Schulungsdaten übereinstimmen. Nehmen wir beispielsweise an, dass Sie Wohnungspreise voraussagen und das Ziel in den Schulungsdaten Werte zwischen 0 und 450 000 hatte. Das vorausgesagte Ziel muss nicht in diesem Bereich liegen. Es kann jeden beliebigen positiven Wert (über 450 000) oder negativen Wert (kleiner als 0) haben. Es ist wichtig, einen Plan für die Handhabung von Voraussagewerten außerhalb des akzeptablen Bereichs für Ihre Anwendung zu haben.
Messung der ML-Modellgenauigkeit
Für Regressionsaufgaben verwendet Amazon ML die RMSE-Metrik (Root Mean Square Error, mittlerer quadratischer Vorhersagefehler) nach Branchenstandard. Es handelt sich um ein Maß für die Abweichung zwischen dem vorausgesagten numerischen Ziel und der tatsächlichen numerischen Antwort (Referenzdaten). Je kleiner der RMSE-Wert ist, umso höher ist die Voraussagegenauigkeit des Modells. Ein Modell mit absolut richtigen Voraussagen hat einen RMSE von 0. Das folgende Beispiel zeigt Evaluierungsdaten mit n Datensätzen:

Basis-RMSE
Amazon ML bietet eine Basis-Metrik für Regressionsmodelle. Dabei handelt es sich um den RMSE für ein hypothetisches Regressionsmodell, das immer den Durchschnitt des Ziel als Antwort voraussagt. Wenn Sie beispielsweise das Alter eines Hauskäufer voraussagen und das Durchschnittsalter für die Beobachtungen in Ihren Schulungsdaten 35 ist, sagt das Basismodell immer 35 als Antwort voraus. Sie können Ihr ML-Modell dann mit diesem Basismodell vergleichen, um zu ermitteln, ob Ihr ML-Modell besser ist als ein ML-Modell, das diese konstante Antwort vorhersagt.
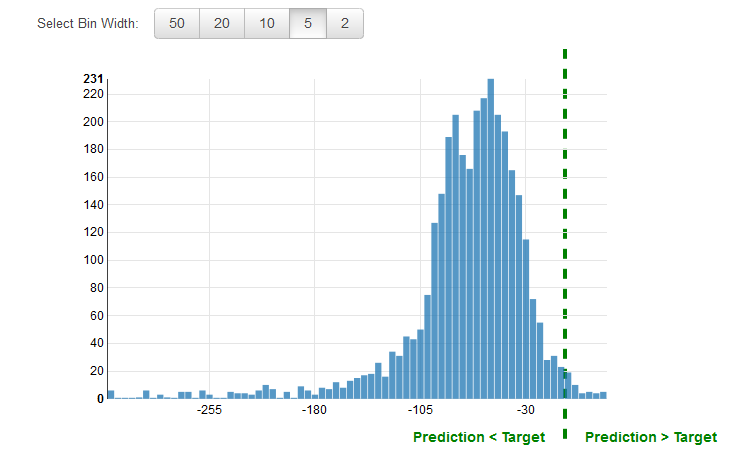
Verwenden der Performance-Visualisierung
Es ist eine gängige Vorgehensweise, den Rest bei Regressionsproblemen zu überprüfen. Ein Rest für eine Beobachtung in der Evaluierungsdaten ist der Unterschied zwischen dem wahren Ziel und dem vorausgesagten Ziel. Reste stellen den Teil des Ziels dar, den das Modell nicht voraussagen konnte. Ein positiver Rest deutet darauf hin, dass das Modell das Ziel unterschätzt (das tatsächliche Ziel ist größer als das vorausgesagte Ziel). Ein negativer Rest deutet auf eine Überbewertung hin (das tatsächliche Ziel ist kleiner als das vorausgesagte Ziel). Das Histogramm der Reste für die Evaluierungsdaten deutet bei glockenförmiger Anordnung und Zentrierung auf Null darauf hin, dass das Modell willkürliche Fehler macht und keinen spezifischen Zielwertbereich systematisch über- oder unterschätzt. Wenn die Reste keine Glockenform mit Zentrierung auf Null bilden, gibt es eine gewisse Struktur bei den Voraussagefehlern des Modells. Das Hinzufügen von weiteren Variablen kann es dem Modell ermöglichen, Muster zu erfassen, die vom aktuellen Modell nicht erfasst werden. Die folgende Abbildung zeigt Reste, die nicht um Null zentriert sind.