Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Konfigurationsoptionen für benutzerdefinierte Datenbezeichner
Mithilfe von benutzerdefinierten Datenbezeichnern können Sie benutzerdefinierte Kriterien für die Erkennung sensibler Daten in Amazon Simple Storage Service (Amazon S3) -Objekten definieren. Sie können die verwalteten Datenkennungen, die Amazon Macie bereitstellt, ergänzen und sensible Daten erkennen, die die speziellen Szenarien, das geistige Eigentum oder die firmeneigenen Daten Ihres Unternehmens widerspiegeln.
Jeder benutzerdefinierte Datenbezeichner gibt Erkennungskriterien und optional Schweregradeinstellungen für Ergebnisse an, die anhand der Kennung ermittelt werden. Die Erkennungskriterien spezifizieren einen regulären Ausdruck, der ein Textmuster definiert, dem in einem S3-Objekt entsprochen werden soll. Die Kriterien können auch Zeichenfolgen und eine Näherungsregel angeben, mit denen die Ergebnisse verfeinert werden. Die Schweregradeinstellungen geben an, welcher Schweregrad den Ergebnissen zugewiesen werden soll. Der Schweregrad kann auf der Anzahl der Textvorkommen basieren, die den Erkennungskriterien des Bezeichners entsprechen.
Erkennungskriterien
Wenn Sie einen benutzerdefinierten Datenbezeichner erstellen, geben Sie einen regulären Ausdruck (Regex) an, der ein passendes Textmuster definiert. Sie können auch Zeichenfolgen wie Wörter und Ausdrücke sowie eine Näherungsregel angeben, um die Ergebnisse zu verfeinern. Bei den Zeichenfolgen kann es sich um: Schlüsselwörter, also Wörter oder Ausdrücke, die in der Nähe von Text stehen müssen, der dem regulären Ausdruck entspricht, oder um Wörter ignorieren, bei denen es sich um Wörter oder Ausdrücke handelt, die aus den Ergebnissen ausgeschlossen werden sollen.
Für die Regex unterstützt Amazon Macie eine Teilmenge der Mustersyntax, die von der Bibliothek Perl Compatible Regular Expressions
-
Rückverweise
-
Gruppen erfassen
-
Bedingungsmuster
-
Eingebetteter Code
-
Globale Musterflags, wie
/i/m, und/x -
Rekursive Muster
-
Positive und negative Look-Behind- und Look-Ahead-Assertionen mit einer Breite von Null, wie,, und
?=?!?<=?<!
Der reguläre Ausdruck kann bis zu 512 Zeichen enthalten.
Beachten Sie die folgenden Tipps und Empfehlungen, um ein effektives Regex-Muster für einen benutzerdefinierten Datenbezeichner zu erstellen:
-
Verwenden Sie Anker (
^oder$) nur, wenn Sie erwarten, dass das Muster am Anfang oder Ende einer Datei erscheint, nicht am Anfang oder Ende einer Zeile. -
Aus Leistungsgründen begrenzt Macie die Größe begrenzter Wiederholungsgruppen. Kompiliert beispielsweise
\d{100,1000}nicht in Macie. Um sich dieser Funktionalität anzunähern, können Sie eine Wiederholung mit offenem Ende verwenden, wie z.\d{100,} -
Um bei Teilen eines Musters die Groß- und Kleinschreibung nicht zu berücksichtigen, können Sie das
(?i)Konstrukt anstelle des/iFlags verwenden. -
Es ist nicht erforderlich, Präfixe oder Alternativen manuell zu optimieren. Wenn Sie beispielsweise
/hello|hi|hey/zu wechseln,/h(?:ello|i|ey)/wird die Leistung nicht verbessert. -
Aus Leistungsgründen begrenzt Macie die Anzahl wiederholter Platzhalter. Kompiliert beispielsweise
a*b*a*nicht in Macie.
Zum Schutz vor falsch formatierten oder lang andauernden Ausdrücken testet Macie automatisch Regex-Muster anhand einer Sammlung von Beispieltext, wenn Sie einen benutzerdefinierten Datenbezeichner erstellen. Wenn es ein Problem mit der Regex gibt, gibt Macie einen Fehler zurück, der das Problem beschreibt.
Zusätzlich zur Regex können Sie optional Zeichenfolgen und eine Näherungsregel angeben, um die Ergebnisse zu verfeinern.
- Schlüsselwörter
-
Dabei handelt es sich um spezifische Zeichenfolgen, die sich in der Nähe von Text befinden müssen, der dem Regex-Muster entspricht. Die Anforderungen an die Nähe variieren je nach Speicherformat oder Dateityp eines S3-Objekts:
-
Strukturierte Spaltendaten — Macie fügt ein Ergebnis hinzu, wenn der Text dem Regex-Muster entspricht und ein Schlüsselwort im Namen des Felds oder der Spalte enthalten ist, in dem der Text gespeichert ist, oder wenn dem Text ein Schlüsselwort im selben Feld oder Zellenwert vorangestellt ist und sich innerhalb der maximalen Übereinstimmungsdistanz befindet. Dies ist bei Microsoft Excel-Arbeitsmappen, CSV-Dateien und TSV-Dateien der Fall.
-
Strukturierte datensatzbasierte Daten — Macie fügt ein Ergebnis hinzu, wenn der Text dem Regex-Muster entspricht und sich der Text innerhalb der maximalen Übereinstimmungsdistanz eines Schlüsselworts befindet. Das Schlüsselwort kann im Namen eines Elements im Pfad zu dem Feld oder Array enthalten sein, in dem der Text gespeichert ist, oder es kann demselben Wert in dem Feld oder der Matrix, in dem der Text gespeichert ist, vorangehen und Teil desselben Werts sein. Dies ist bei Apache Avro-Objektcontainern, Apache Parquet-Dateien, JSON-Dateien und JSON Lines-Dateien der Fall.
-
Unstrukturierte Daten — Macie fügt ein Ergebnis hinzu, wenn der Text dem Regex-Muster entspricht und dem Text ein Schlüsselwort vorangestellt ist und sich innerhalb der maximalen Übereinstimmungsdistanz befindet. Dies ist bei Dateien im Adobe Portable Document Format, Microsoft Word-Dokumenten, E-Mail-Nachrichten und nicht binären Textdateien mit Ausnahme von CSV-, JSON-, JSON Lines- und TSV-Dateien der Fall. Dies schließt alle strukturierten Daten wie Tabellen in diesen Dateitypen ein.
Sie können bis zu 50 Schlüsselwörter angeben. Jedes Schlüsselwort kann 3—90 UTF-8-Zeichen enthalten. Bei Schlüsselwörtern muss die Groß- und Kleinschreibung nicht beachtet werden.
-
- Maximaler Übereinstimmungsabstand
-
Dies ist eine zeichenbasierte Näherungsregel für Keywords. Macie verwendet diese Einstellung, um zu bestimmen, ob ein Schlüsselwort vor einem Text steht, der dem Regex-Muster entspricht. Die Einstellung definiert die maximale Anzahl von Zeichen, die zwischen dem Ende eines vollständigen Schlüsselworts und dem Ende des Textes, der dem Regex-Muster entspricht, existieren können. Macie fügt ein Ergebnis ein, wenn der Text:
-
Entspricht dem Regex-Muster,
-
Tritt nach mindestens einem vollständigen Schlüsselwort auf und
-
Tritt innerhalb der angegebenen Entfernung zum Schlüsselwort auf.
Andernfalls schließt Macie den Text aus den Ergebnissen aus.
Sie können einen Abstand von 1—300 Zeichen angeben. Der Standardabstand beträgt 50 Zeichen. Um optimale Ergebnisse zu erzielen, sollte dieser Abstand größer sein als die Mindestanzahl von Textzeichen, für die die Regex entworfen wurde. Wenn nur ein Teil des Textes innerhalb der maximalen Trefferdistanz eines Schlüsselworts liegt, nimmt Macie ihn nicht in die Ergebnisse auf.
-
- Ignoriere Wörter
-
Dies sind spezifische Zeichenfolgen, die aus den Ergebnissen ausgeschlossen werden sollen. Wenn Text dem Regex-Muster entspricht, aber ein Ignorierwort enthält, nimmt Macie es nicht in die Ergebnisse auf.
Sie können bis zu 10 Ignorierwörter angeben. Jedes Ignorierwort kann 4—90 UTF-8-Zeichen enthalten. Die zu ignorierenden Wörter unterscheiden zwischen Groß- und Kleinschreibung.
Anmerkung
Bevor Sie einen benutzerdefinierten Datenbezeichner erstellen, empfehlen wir dringend, die zugehörigen Erkennungskriterien anhand von Beispieldaten zu testen und zu verfeinern. Da benutzerdefinierte Datenbezeichner bei Aufträgen zur Erkennung vertraulicher Daten verwendet werden, können Sie eine benutzerdefinierte Daten-ID nicht mehr ändern, nachdem Sie sie erstellt haben. Auf diese Weise können Sie sicherstellen, dass Sie über einen unveränderlichen Verlauf der Ergebnisse sensibler Daten und der Ergebnisse der von Ihnen durchgeführten Datenschutzprüfungen oder -untersuchungen verfügen.
Sie können Erkennungskriterien mithilfe der Amazon Macie Macie-Konsole oder der Amazon Macie Macie-API testen. Um die Kriterien mithilfe der Konsole zu testen, verwenden Sie die Optionen im Abschnitt Evaluieren, während Sie die benutzerdefinierte Daten-ID erstellen. Verwenden Sie den TestCustomDataIdentifierBetrieb der Amazon Macie Macie-API, um die Kriterien programmgesteuert zu testen. Wenn Sie den verwenden, führen Sie den test-custom-data-identifierBefehl aus AWS Command Line Interface, um die Kriterien zu testen.
Sehen Sie sich das folgende Video an, um zu zeigen, wie Stichwörter Ihnen helfen können, vertrauliche Daten zu finden und Fehlalarme zu vermeiden:
Einstellungen für den Schweregrad der Ergebnisse
Wenn Sie eine benutzerdefinierte Daten-ID erstellen, können Sie auch benutzerdefinierte Einstellungen für den Schweregrad der Ergebnisse angeben, die anhand der Kennung erkannt werden. Standardmäßig weist Amazon Macie allen Ergebnissen, die eine benutzerdefinierte Daten-ID liefert, den Schweregrad Mittel zu. Wenn ein S3-Objekt mindestens einmal Text enthält, der den Erkennungskriterien entspricht, weist Macie dem resultierenden Ergebnis automatisch den Schweregrad Mittel zu.
Mit benutzerdefinierten Schweregradeinstellungen geben Sie an, welcher Schweregrad auf der Grundlage der Anzahl von Textvorkommen zugewiesen werden soll, die den Erkennungskriterien entsprechen. Sie können Schwellenwerte für Vorkommen für bis zu drei Schweregrade definieren: Niedrig (am wenigsten schwerwiegend), Mittel und Hoch (am schwersten). Ein Schwellenwert für Vorkommnisse ist die Mindestanzahl von Übereinstimmungen, die in einem S3-Objekt vorhanden sein müssen, um ein Ergebnis mit dem angegebenen Schweregrad zu erhalten. Wenn Sie mehr als einen Schwellenwert angeben, müssen die Schwellenwerte nach Schweregrad in aufsteigender Reihenfolge angegeben werden, d. h. von Niedrig bis Hoch.
Die folgende Abbildung zeigt beispielsweise Schweregradeinstellungen, die drei Schwellenwerte angeben, einen für jeden Schweregrad, den Macie unterstützt.
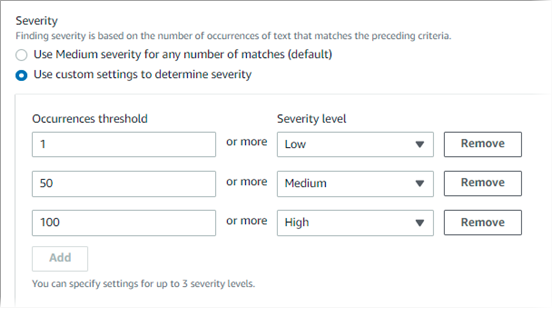
In der folgenden Tabelle wird der Schweregrad der Ergebnisse angegeben, die mit der benutzerdefinierten Daten-ID erzielt wurden.
| Schwellenwert für Vorkommen | Schweregrad | Ergebnis |
|---|---|---|
| 1 | Niedrig | Wenn ein S3-Objekt 1—49 Textvorkommen enthält, die den Erkennungskriterien entsprechen, ist der Schweregrad des resultierenden Ergebnisses Niedrig. |
| 50 | Mittel | Wenn ein S3-Objekt 50—99 Textstellen enthält, die den Erkennungskriterien entsprechen, lautet der Schweregrad des resultierenden Ergebnisses Mittel. |
| 100 | Hoch | Wenn ein S3-Objekt 100 oder mehr Textstellen enthält, die den Erkennungskriterien entsprechen, lautet der Schweregrad des resultierenden Ergebnisses Hoch. |
Sie können auch die Einstellungen für den Schweregrad verwenden, um anzugeben, ob überhaupt ein Befund erstellt werden soll. Wenn ein S3-Objekt weniger Vorkommen enthält als der Schwellenwert für das niedrigste Vorkommen, erstellt Macie keinen Befund.
