Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Was ist Amazon OpenSearch Serverless?
Amazon OpenSearch Serverless ist eine serverlose On-Demand-Option für Amazon OpenSearch Service, die die betriebliche Komplexität der Bereitstellung, Konfiguration und Optimierung von Clustern überflüssig macht. OpenSearch Es ist ideal für Unternehmen, die es vorziehen, ihre Cluster nicht selbst zu verwalten, oder die nicht über die speziellen Ressourcen und das Fachwissen verfügen, um umfangreiche Bereitstellungen zu betreiben. Mit OpenSearch Serverless können Sie große Datenmengen durchsuchen und analysieren, ohne die zugrunde liegende Infrastruktur verwalten zu müssen.
Eine OpenSearch serverlose Sammlung ist eine Gruppe von OpenSearch Indizes, die zusammenarbeiten, um eine bestimmte Arbeitslast oder einen bestimmten Anwendungsfall zu unterstützen. Sammlungen vereinfachen den Betrieb im Vergleich zu selbstverwalteten OpenSearch Clustern, die eine manuelle Bereitstellung erfordern.
Sammlungen verwenden denselben verteilten und hochverfügbaren Speicher mit hoher Kapazität wie bereitgestellte OpenSearch Dienstdomänen, reduzieren jedoch die Komplexität weiter, da die manuelle Konfiguration und Optimierung entfällt. Daten innerhalb einer Sammlung werden bei der Übertragung verschlüsselt. OpenSearch Serverless unterstützt auch OpenSearch Dashboards und bietet so eine Schnittstelle für die Datenanalyse.
OpenSearch Serverless ist mit Open Source kompatibel. OpenSearch Wenn neue Versionen veröffentlicht werden, aktualisiert OpenSearch Serverless die Sammlungen automatisch, um neue Funktionen, Bugfixes und Leistungsverbesserungen zu integrieren.
OpenSearch Serverless unterstützt dieselben Ingest- und Abfrage-API-Operationen wie die OpenSearch Open-Source-Suite, sodass Sie Ihre vorhandenen Clients und Anwendungen weiterhin verwenden können. Ihre Clients müssen mit OpenSearch 3.x kompatibel sein, um mit Serverless arbeiten zu können. OpenSearch Weitere Informationen finden Sie unter Daten in Amazon OpenSearch Serverless-Sammlungen aufnehmen.
Themen
Anwendungsfälle für Serverless OpenSearch
OpenSearch Serverless unterstützt zwei Hauptanwendungsfälle:
-
Protokollanalyse – Das Segment Protokollanalyse befasst sich mit der Analyse großer Mengen an halbstrukturierten, maschinell generierten Zeitreihendaten, um Einblicke in das Betriebs- und Benutzerverhalten zu erhalten.
-
Full-text Suche — Das Segment der Volltextsuche unterstützt Anwendungen in Ihren internen Netzwerken (Content-Management-Systeme, Rechtsdokumente) und Internetanwendungen wie die Inhaltssuche auf E-Commerce-Websites.
Wenn Sie eine Sammlung erstellen, wählen Sie einen dieser Anwendungsfälle aus. Weitere Informationen finden Sie unter Auswahl eines Sammlungstyps.
Funktionsweise
Herkömmliche OpenSearch Cluster verfügen über einen einzigen Satz von Instances, die sowohl Indizierungs- als auch Suchvorgänge ausführen, und der Indexspeicher ist eng mit der Rechenkapazität verknüpft. Im Gegensatz dazu verwendet OpenSearch Serverless eine cloudnative Architektur, die die Indexierungskomponenten (Ingest) von den Such- (Abfrage-) Komponenten trennt, wobei Amazon S3 der primäre Datenspeicher für Indizes ist.
Diese entkoppelte Architektur ermöglicht es Ihnen, Such- und Indizierungsfunktionen unabhängig voneinander und unabhängig von den indizierten Daten in S3 zu skalieren. Die Architektur bietet auch eine Isolierung für Aufnahme- und Abfragevorgänge, so dass sie ohne Ressourcenkonflikte gleichzeitig ausgeführt werden können.
Wenn Sie Daten in eine Sammlung schreiben, verteilt OpenSearch Serverless sie an die Recheneinheiten für die Indexierung. Die indizierenden Recheneinheiten nehmen die eingehenden Daten auf und verschieben die Indizes zu S3. Wenn Sie eine Suche nach den Sammlungsdaten durchführen, leitet OpenSearch Serverless Anfragen an die Recheneinheiten für die Suche weiter, die die abgefragten Daten enthalten. Die Recheneinheiten für die Suche laden die indizierten Daten direkt von S3 herunter (wenn sie nicht bereits lokal zwischengespeichert sind), führen Suchvorgänge aus und führen Aggregationen durch.
Das folgende Image veranschaulicht diese entkoppelte Architektur:
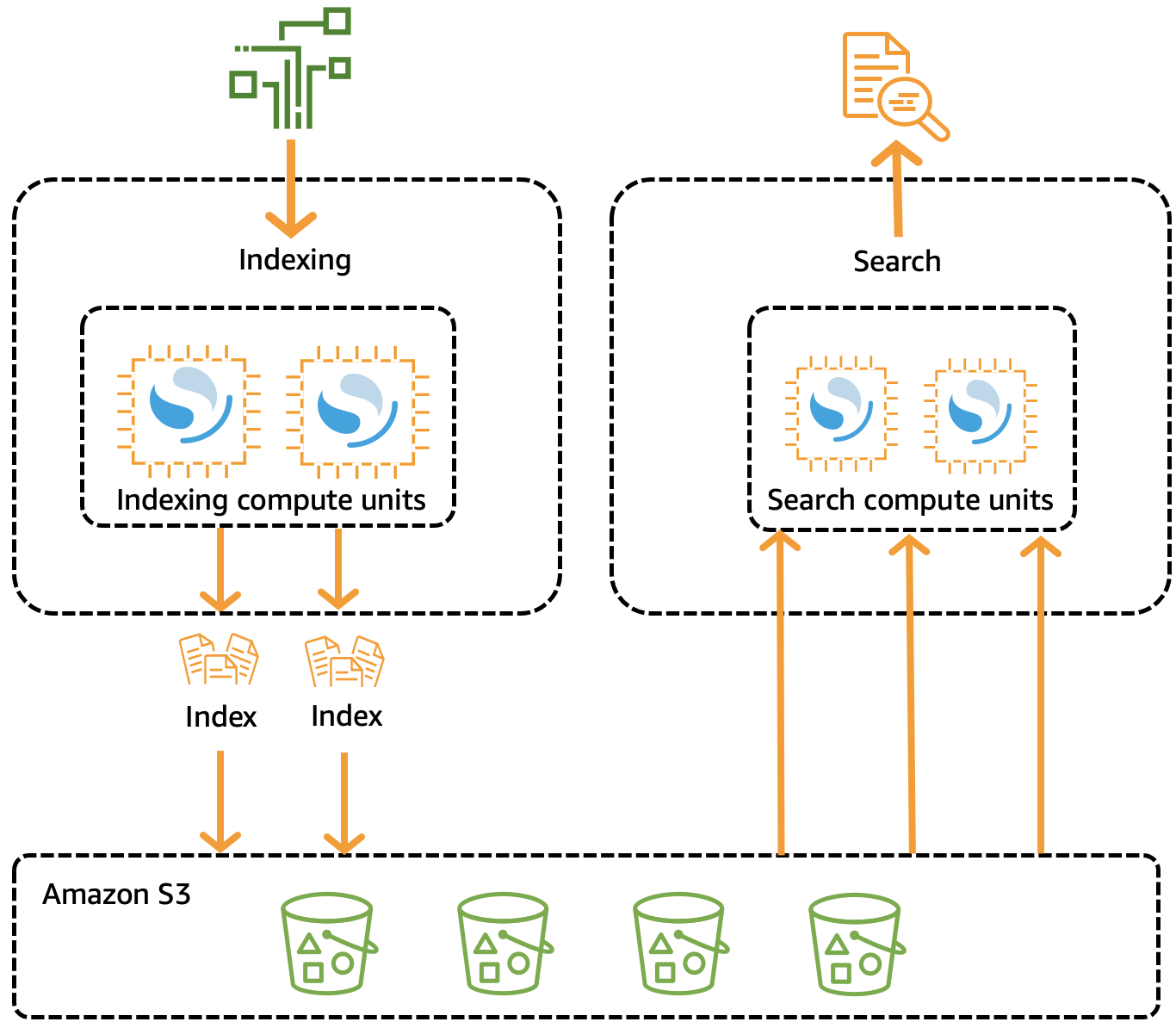
OpenSearch Serverlose Rechenkapazität für Datenaufnahme, Suche und Abfrage wird in OpenSearch Recheneinheiten (OCUs) gemessen. Jede OCU ist eine Kombination aus 6 GB Speicher und entsprechender virtueller CPU (vCPU) und erstellt eine Daten-Pipeline zu Amazon S3.
OpenSearch Serverless stellt OCUs separat für die Suche und Indizierung bereit. OpenSearch Serverless fügt nur bei Bedarf zusätzliche OCUs für Suche und Aufnahme hinzu, um die Sammlungen entsprechend den von Ihnen angegebenen Kapazitätsgrenzen zu unterstützen. Die Kapazität wird mit sinkender Computernutzung wieder herunterskaliert.
Informationen darüber, wie Ihnen diese OCUs in Rechnung gestellt werden, finden Sie unter Amazon OpenSearch Service-Preise
Auswahl eines Sammlungstyps
OpenSearch Serverless unterstützt drei primäre Erfassungstypen:
Zeitreihen — Das Segment der Protokollanalysen, das große Mengen halbstrukturierter, maschinengenerierter Daten in Echtzeit analysiert und so Einblicke in Betrieb, Sicherheit, Benutzerverhalten und Unternehmensleistung bietet.
Anmerkung
Zeitreihen-Sammlungen sind nur für Classic-Sammlungen verfügbar. NextGenSammlungen unterstützen derzeit nur die Such- und Vektor-Suchtypen.
Suche — eine Full-text Suche, die Anwendungen innerhalb interner Netzwerke ermöglicht, wie z. B. Content-Management-Systeme und Ablagen für juristische Dokumente, sowie Internetanwendungen wie E-Commerce-Sitesuche und Inhaltssuche.
Vektorsuche — Die semantische Suche nach Vektor-Einbettungen vereinfacht die Verwaltung von Vektordaten und ermöglicht durch maschinelles Lernen (ML) erweiterte Sucherlebnisse. Es unterstützt generative KI-Anwendungen wie Chatbots, persönliche Assistenten und Betrugserkennung.
Sie wählen einen Sammlungstyp aus, wenn Sie zum ersten Mal eine Sammlung erstellen:
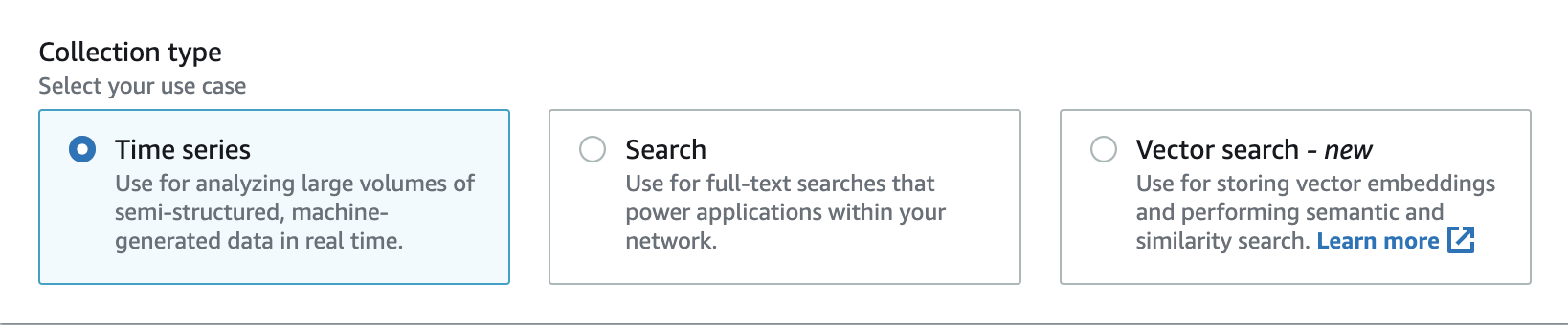
Der ausgewählte Sammlungstyp hängt von der Art der Daten ab, die Sie in die Sammlung aufnehmen möchten, und davon, wie Sie diese abfragen möchten. Sie können den Sammlungstyp nach dem Erstellen nicht mehr ändern.
Die Sammlungstypen weisen die folgenden bemerkenswerten Unterschiede auf:
-
Bei Sammlungen mit Such - und Vektorsuche werden alle Daten im Hot-Storage gespeichert, um schnelle Antwortzeiten bei Abfragen zu gewährleisten. Zeitreihen-Sammlungen verwenden eine Kombination aus Hot- und Warm-Speicher, wobei die aktuellsten Daten im Hot-Speicher aufbewahrt werden, um die Reaktionszeiten bei Abfragen für Daten mit häufigerem Zugriff zu optimieren.
-
Bei Zeitreihen-Sammlungen können Sie weder anhand einer benutzerdefinierten Dokument-ID indexieren noch anhand von Upsert-Anfragen aktualisieren. Dieser Vorgang ist Suchanwendungsfällen vorbehalten. Stattdessen können Sie die Aktualisierung anhand der Dokument-ID vornehmen. Weitere Informationen finden Sie unter Unterstützte OpenSearch API-Operationen und Berechtigungen.
-
Für Such - und Zeitreihensammlungen können Sie keine Indizes vom Typ k-NN verwenden.
Unterstützt AWS-Regionen
OpenSearch Serverless ist nur in einer Teilmenge verfügbar, in der der OpenSearch Service verfügbar AWS-Regionen ist. Eine Liste der unterstützten Regionen finden Sie unter Amazon OpenSearch Service-Endpunkte und Kontingente in der Allgemeine AWS-Referenz.
Einschränkungen
OpenSearch Serverless hat die folgenden Einschränkungen:
-
Einige OpenSearch API-Operationen werden nicht unterstützt. Siehe Unterstützte OpenSearch API-Operationen und Berechtigungen.
-
Einige OpenSearch Plugins werden nicht unterstützt. Siehe Unterstützte OpenSearch Plug-ins.
-
Derzeit gibt es keine Möglichkeit, Ihre Daten automatisch von einer verwalteten OpenSearch Dienstdomäne zu einer serverlosen Sammlung zu migrieren. Sie müssen Ihre Daten von einer Domain zu einer Sammlung neu indizieren.
-
Cross-account Der Zugriff auf Sammlungen wird nicht unterstützt. Sie können Sammlungen von anderen Konten nicht in Ihre Verschlüsselungs- oder Datenzugriffsrichtlinien aufnehmen.
-
Benutzerdefinierte OpenSearch Plugins werden nicht unterstützt.
-
Automatisierte Snapshots werden für OpenSearch serverlose Sammlungen unterstützt. Manuelle Snapshots werden nicht unterstützt. Weitere Informationen finden Sie unter Sammlungen mithilfe von Schnappschüssen sichern.
-
Cross-Region Suche und Replikation werden nicht unterstützt.
-
Die Anzahl der Serverless-Ressourcen, die Sie in einem einzigen Konto und einer Region haben können, ist begrenzt. Siehe OpenSearch Serverlose Kontingente.
-
Das Aktualisierungsintervall für Indizes in Such- und Zeitreihensammlungen beträgt ungefähr 10 Sekunden.
-
Die Anzahl der Shards, die Anzahl der Intervalle und das Aktualisierungsintervall können nicht geändert werden und werden von Serverless verwaltet. OpenSearch Die Sharding-Strategie basiert auf der Art der Erfassung und dem Datenverkehr. Beispielsweise skaliert eine Zeitreihen-Sammlung primäre Shards auf der Grundlage von Engpässen im Schreibdatenverkehr.
