Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Tutorial: Visualisieren von Kundendienstanrufen mit OpenSearch Service und Dashboards OpenSearch
Dieses Kapitel enthält eine vollständige Schritt-für-Schritt-Anleitung für folgendes Szenario: In einem Unternehmen geht eine bestimmte Anzahl an Anrufen beim Kundensupport ein. Diese sollen analysiert werden. Wie lauteten die Themen der einzelnen Anrufe? Wie viele Gespräche waren positiv? Wie viele Gespräche waren negativ? Wie können Vorgesetzte nach den Transkripten der Anrufe suchen oder diese überprüfen?
Zu einem manuellen Workflow könnte das Anhören von Aufzeichnungen, das Notieren des Themas des Anrufs und die Feststellung, ob die Interaktion mit dem Kunden positiv war, gehören.
Dieser Prozess wäre aber sehr arbeitsaufwendig. Wenn man von einer durchschnittlichen Anrufdauer von 10 Minuten ausgeht, können Mitarbeiter 48 Anrufe pro Tag entgegennehmen. Ohne menschliche Voreingenommenheit wären die Daten, die generiert werden würden, sehr zuverlässig, die Menge der Daten aber minimal: Sie würden nur Aufschluss über das Thema des Anrufs und darüber geben, ob ein Kunde zufrieden war oder nicht. Weitere Daten, beispielsweise ein vollständiges Transkript, würde enorm viel Zeit in Anspruch nehmen.
Mit Amazon S3
Sie können diese exemplarische Vorgehensweise zwar unverändert verwenden, sie soll jedoch Ideen zur Anreicherung Ihrer JSON-Dokumente anregen, bevor Sie sie in Service indizieren. OpenSearch
Geschätzte Kosten
Im Allgemeinen sollte die Durchführung der Schritte in dieser Anleitung weniger als 2 USD kosten. Es werden folgende Ressourcen verwendet:
-
S3-Bucket mit weniger als 100 MB übertragenen und gespeicherten Daten
Weitere Informationen finden Sie unter Amazon S3 – Preise
. -
OpenSearch Service-Domain mit einer
t2.mediumInstanz und 10 GiB EBS-Speicher für mehrere StundenWeitere Informationen finden Sie unter Amazon OpenSearch Service Pricing
. -
Mehrere Aufrufe von Amazon Transcribe
Weitere Informationen finden Sie unter Amazon Transcribe – Preise
. -
Mehrere natürliche Sprachverarbeitungsaufrufe an Amazon Comprehend
Weitere Informationen finden Sie unter Amazon Comprehend – Preise
.
Themen
Schritt 1: Konfigurieren der Voraussetzungen
Zum Fortfahren benötigen Sie die folgenden Ressourcen.
| Voraussetzung | Description |
|---|---|
| Amazon-S3-Bucket | Weitere Informationen erhalten Sie unter Erstellen eines Buckets im Benutzerhandbuch für Amazon Simple Storage Service. |
| OpenSearch Service-Domain | Das Ziel für die Daten. Weitere Informationen finden Sie unter OpenSearch Dienstdomänen erstellen. |
Wenn Sie noch nicht über diese Ressourcen verfügen, können Sie diese mit den folgenden AWS CLI -Befehlen erstellen:
aws s3 mb s3://my-transcribe-test --region us-west-2
aws opensearch create-domain --domain-name my-transcribe-test --engine-version OpenSearch_1.0 --cluster-config InstanceType=t2.medium.search,InstanceCount=1 --ebs-options EBSEnabled=true,VolumeType=standard,VolumeSize=10 --access-policies '{"Version": "2012-10-17","Statement":[{"Effect":"Allow","Principal":{"AWS":"arn:aws:iam::123456789012:root"},"Action":"es:*","Resource":"arn:aws:es:us-west-2:123456789012:domain/my-transcribe-test/*"}]}' --region us-west-2
Anmerkung
Diese Befehle verwenden die us-west-2-Region. Sie können jedoch jede Region nutzen, die von Amazon Comprehend unterstützt wird. Weitere Informationen finden Sie in unter Allgemeine AWS-Referenz.
Schritt 2: Kopieren des Beispiel-Codes
-
Kopieren Sie den folgenden Python-3-Beispiel-Code in eine neue Datei namens
call-center.py:import boto3 import datetime import json import requests from requests_aws4auth import AWS4Auth import time import urllib.request # Variables to update audio_file_name = '' # For example, 000001.mp3 bucket_name = '' # For example, my-transcribe-test domain = '' # For example, https://search-my-transcribe-test-12345.us-west-2.es.amazonaws.com index = 'support-calls' type = '_doc' region = 'us-west-2' # Upload audio file to S3. s3_client = boto3.client('s3') audio_file = open(audio_file_name, 'rb') print('Uploading ' + audio_file_name + '...') response = s3_client.put_object( Body=audio_file, Bucket=bucket_name, Key=audio_file_name ) # # Build the URL to the audio file on S3. # # Only for the us-east-1 region. # mp3_uri = 'https://' + bucket_name + '.s3.amazonaws.com/' + audio_file_name # Get the necessary details and build the URL to the audio file on S3. # For all other regions. response = s3_client.get_bucket_location( Bucket=bucket_name ) bucket_region = response['LocationConstraint'] mp3_uri = 'https://' + bucket_name + '.s3-' + bucket_region + '.amazonaws.com/' + audio_file_name # Start transcription job. transcribe_client = boto3.client('transcribe') print('Starting transcription job...') response = transcribe_client.start_transcription_job( TranscriptionJobName=audio_file_name, LanguageCode='en-US', MediaFormat='mp3', Media={ 'MediaFileUri': mp3_uri }, Settings={ 'ShowSpeakerLabels': True, 'MaxSpeakerLabels': 2 # assumes two people on a phone call } ) # Wait for the transcription job to finish. print('Waiting for job to complete...') while True: response = transcribe_client.get_transcription_job(TranscriptionJobName=audio_file_name) if response['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break else: print('Still waiting...') time.sleep(10) transcript_uri = response['TranscriptionJob']['Transcript']['TranscriptFileUri'] # Open the JSON file, read it, and get the transcript. response = urllib.request.urlopen(transcript_uri) raw_json = response.read() loaded_json = json.loads(raw_json) transcript = loaded_json['results']['transcripts'][0]['transcript'] # Send transcript to Comprehend for key phrases and sentiment. comprehend_client = boto3.client('comprehend') # If necessary, trim the transcript. # If the transcript is more than 5 KB, the Comprehend calls fail. if len(transcript) > 5000: trimmed_transcript = transcript[:5000] else: trimmed_transcript = transcript print('Detecting key phrases...') response = comprehend_client.detect_key_phrases( Text=trimmed_transcript, LanguageCode='en' ) keywords = [] for keyword in response['KeyPhrases']: keywords.append(keyword['Text']) print('Detecting sentiment...') response = comprehend_client.detect_sentiment( Text=trimmed_transcript, LanguageCode='en' ) sentiment = response['Sentiment'] # Build the Amazon OpenSearch Service URL. id = audio_file_name.strip('.mp3') url = domain + '/' + index + '/' + type + '/' + id # Create the JSON document. json_document = {'transcript': transcript, 'keywords': keywords, 'sentiment': sentiment, 'timestamp': datetime.datetime.now().isoformat()} # Provide all details necessary to sign the indexing request. credentials = boto3.Session().get_credentials() awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, 'opensearchservice', session_token=credentials.token) headers = {"Content-Type": "application/json"} # Index the document. print('Indexing document...') response = requests.put(url, auth=awsauth, json=json_document, headers=headers) print(response) print(response.json()) -
Aktualisieren Sie die ersten sechs Variablen.
-
Installieren Sie die erforderlichen Pakete mit den folgenden Befehlen:
pip install boto3 pip install requests pip install requests_aws4auth -
Platzieren Sie Ihre MP3-Datei im selben Verzeichnis wie
call-center.pyund führen Sie das Skript aus. Hier ein Beispiel für eine Ausgabe:$ python call-center.py Uploading 000001.mp3... Starting transcription job... Waiting for job to complete... Still waiting... Still waiting... Still waiting... Still waiting... Still waiting... Still waiting... Still waiting... Detecting key phrases... Detecting sentiment... Indexing document... <Response [201]> {u'_type': u'call', u'_seq_no': 0, u'_shards': {u'successful': 1, u'failed': 0, u'total': 2}, u'_index': u'support-calls4', u'_version': 1, u'_primary_term': 1, u'result': u'created', u'_id': u'000001'}
call-center.py führt eine Reihe von Operationen durch:
-
Das Skript lädt eine Audio-Datei (in diesem Fall eine MP3, Amazon Transcribe unterstützt aber viele Formate) in Ihren S3-Bucket hoch.
-
Es sendet die URL der Audio-Datei an Amazon Transcribe und wartet, bis der Transkriptionsauftrag abgeschlossen ist.
Die Zeit bis zum Abschließen des Transkriptionsauftrags hängt von der Länge der Audiodatei ab. Gehen Sie aber von Minuten und nicht Sekunden aus.
Tipp
Zur Verbesserung der Qualität der Transkription können Sie ein benutzerdefiniertes Vokabular für Amazon Transcribe konfigurieren.
-
Nach Abschluss des Transkriptionsauftrag extrahiert das Skript das Transkript, kürzt es auf 5.000 Zeichen und sendet es zwecks Schlüsselwort- und Stimmungsanalyse an Amazon Comprehend.
-
Schließlich fügt das Skript einem JSON-Dokument das vollständige Protokoll, die Schlüsselwörter, die Stimmung und den aktuellen Zeitstempel hinzu und indexiert es in Service. OpenSearch
Tipp
LibriVox
(Optional) Schritt 3: Indizieren von Beispieldaten
Wenn Sie keine Aufrufaufzeichnungen zur Hand haben – und wer hat das schon? – können Sie die Beispieldokumente in der Datei sample-calls.zip indizieren, die mit dem vergleichbar sind, was call-center.py produziert.
-
Erstellen Sie eine Datei namens
bulk-helper.py:import boto3 from opensearchpy import OpenSearch, RequestsHttpConnection import json from requests_aws4auth import AWS4Auth host = '' # For example, my-test-domain.us-west-2.es.amazonaws.com region = '' # For example, us-west-2 service = 'es' bulk_file = open('sample-calls.bulk', 'r').read() credentials = boto3.Session().get_credentials() awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token) search = OpenSearch( hosts = [{'host': host, 'port': 443}], http_auth = awsauth, use_ssl = True, verify_certs = True, connection_class = RequestsHttpConnection ) response = search.bulk(bulk_file) print(json.dumps(response, indent=2, sort_keys=True)) -
Aktualisieren Sie die ersten zwei Variablen für
hostundregion. -
Installieren Sie das erforderlich Paket mit folgendem Befehl:
pip install opensearch-py -
Laden Sie die Datei sample-calls.zip herunter und entpacken Sie sie.
-
Speichern Sie
sample-calls.bulkin demselben Verzeichnis wiebulk-helper.pyund führen Sie das Helferobjekt aus. Hier ein Beispiel für eine Ausgabe:$ python bulk-helper.py { "errors": false, "items": [ { "index": { "_id": "1", "_index": "support-calls", "_primary_term": 1, "_seq_no": 42, "_shards": { "failed": 0, "successful": 1, "total": 2 }, "_type": "_doc", "_version": 9, "result": "updated", "status": 200 } },...], "took": 27 }
Schritt 4: Analysieren und Visualisieren Sie Ihre Daten
Da Sie nun einige Daten in OpenSearch Service haben, können Sie sie mithilfe von OpenSearch Dashboards visualisieren.
-
Navigieren Sie zu
https://search-.domain.region.es.amazonaws.com/_dashboards -
Bevor Sie OpenSearch Dashboards verwenden können, benötigen Sie ein Indexmuster. Dashboards verwendet Index-Muster, um ihre Analyse auf einen oder mehrere Indizes einzugrenzen. Um den
support-calls-Index abzugleichen, dencall-center.pyerstellt hat, gehen Sie zu Stack Management, Index Patterns, und definieren Sie ein Indexmuster vonsupport*, und wählen Sie dann Nächster Schritt. -
Wählen Sie für Time Filter field name (Feldname für Zeitfilter) die Option timestamp (Zeitstempel) aus.
-
Sie können nun mit dem Generieren von Visualisierungen beginnen. Wählen Sie Visualize (Visualisieren) aus und fügen Sie eine neue Visualisierung hinzu.
-
Wählen Sie das Kreisdiagramm und das
support*-Index-Muster aus. -
Die Standardvisualisierung ist eine eher grundlegende. Eine detaillierte Visualisierung erhalten Sie, wenn Sie Split Slices (Slices aufteilen) auswählen.
Wählen Sie unter Aggregation den Eintrag Terms (Bedingungen) aus. Wählen Sie für Field (Feld) sentiment.keyword aus. Klicken Sie dann auf Apply changes (Änderungen übernehmen) und Save (Speichern).
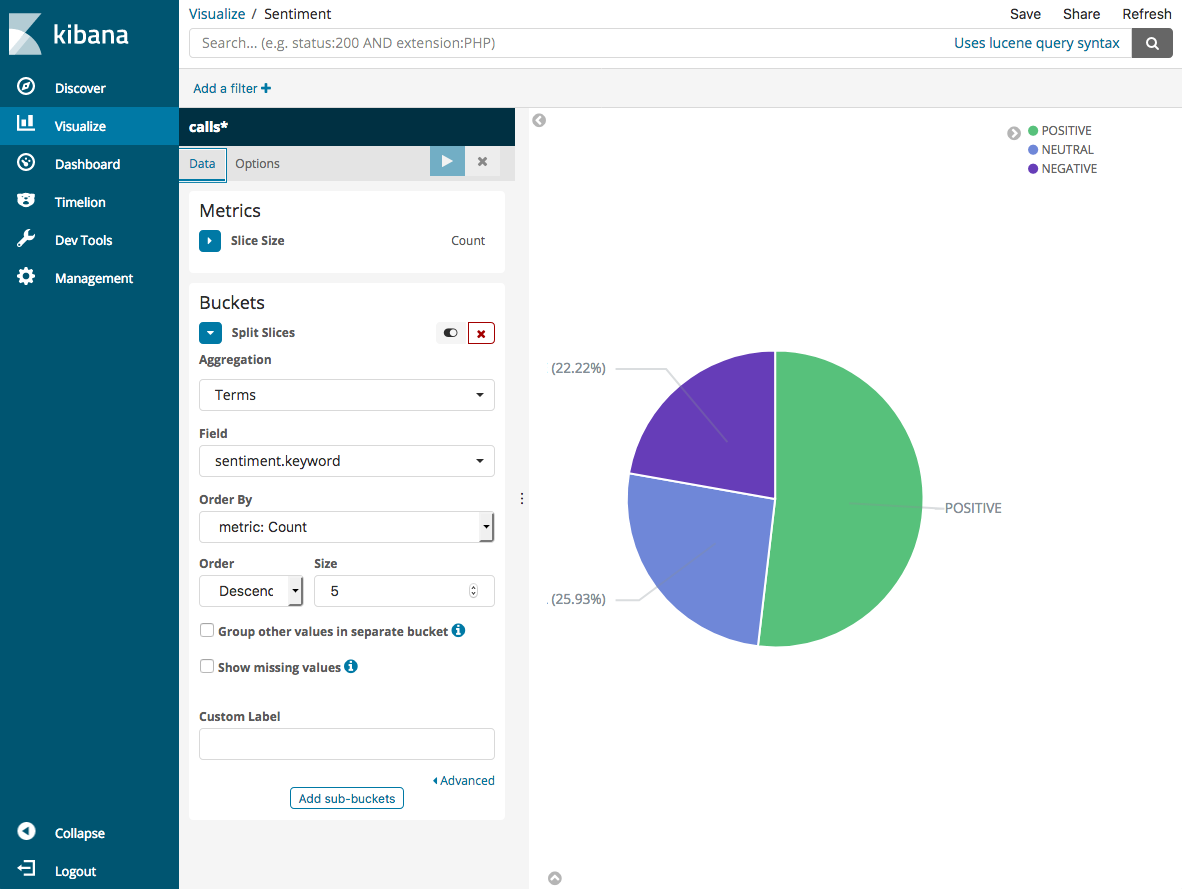
-
Kehren Sie zur Seite Visualize (Visualisieren) zurück und fügen Sie eine weitere Visualisierung hinzu. Wählen Sie dieses Mal das horizontale Balkendiagramm aus.
-
Wählen Sie Split Series (Serie aufteilen) aus.
Wählen Sie unter Aggregation den Eintrag Terms (Bedingungen) aus. Wählen Sie für Field (Feld) keywords.keyword aus und ändern Sie Size (Größe) in 20. Klicken Sie dann auf Apply changes (Änderungen übernehmen) und Save (Speichern).
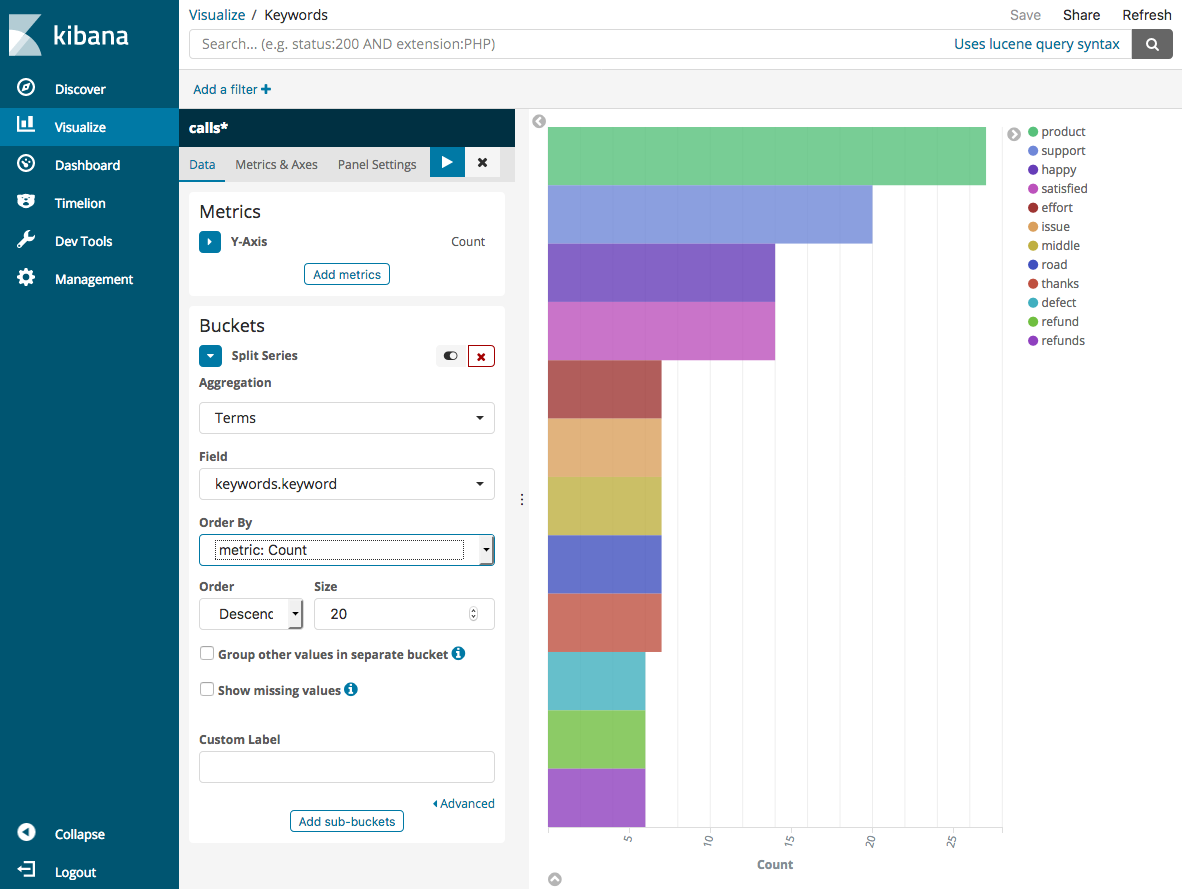
-
Kehren Sie zur Seite Visualize (Visualisieren) zurück und fügen Sie eine letzte Visualisierung, ein vertikales Balkendiagramm, hinzu.
-
Wählen Sie Split Series (Serie aufteilen) aus. Wählen Sie für Aggregation (Aggregation) Date Histogram (Datumshistogramm) aus. Wählen Sie für Field (Feld) timestamp aus und ändern Sie das Interval (Intervall) in Daily (Täglich).
-
Wählen Sie Metrics & Axes (Metriken & Achsen) aus und ändern Sie den Mode (Modus) in normal.
-
Klicken Sie auf Apply changes (Änderungen übernehmen) und Save (Speichern).
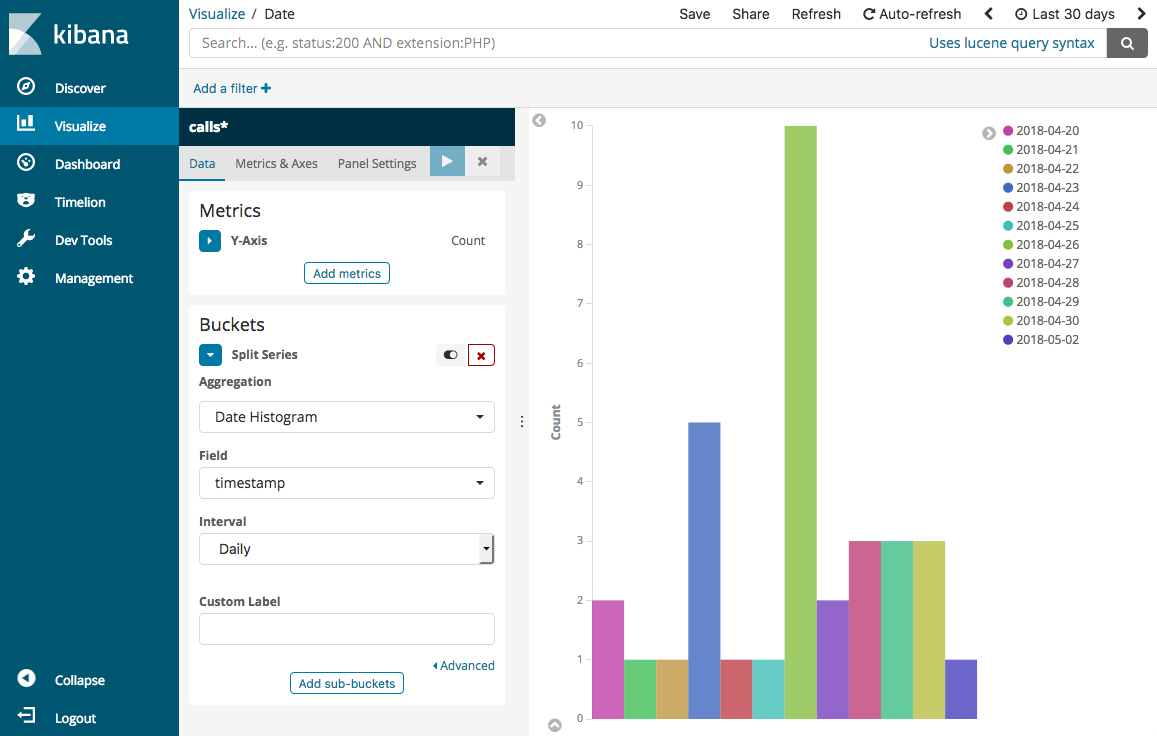
-
Nachdem Sie nun drei Visualisierungen haben, können Sie diese zu einer Dashboard-Visualisierung hinzufügen. Klicken Sie auf Dashboard, erstellen Sie ein Dashboard und fügen Sie Ihre Visualisierungen hinzu.
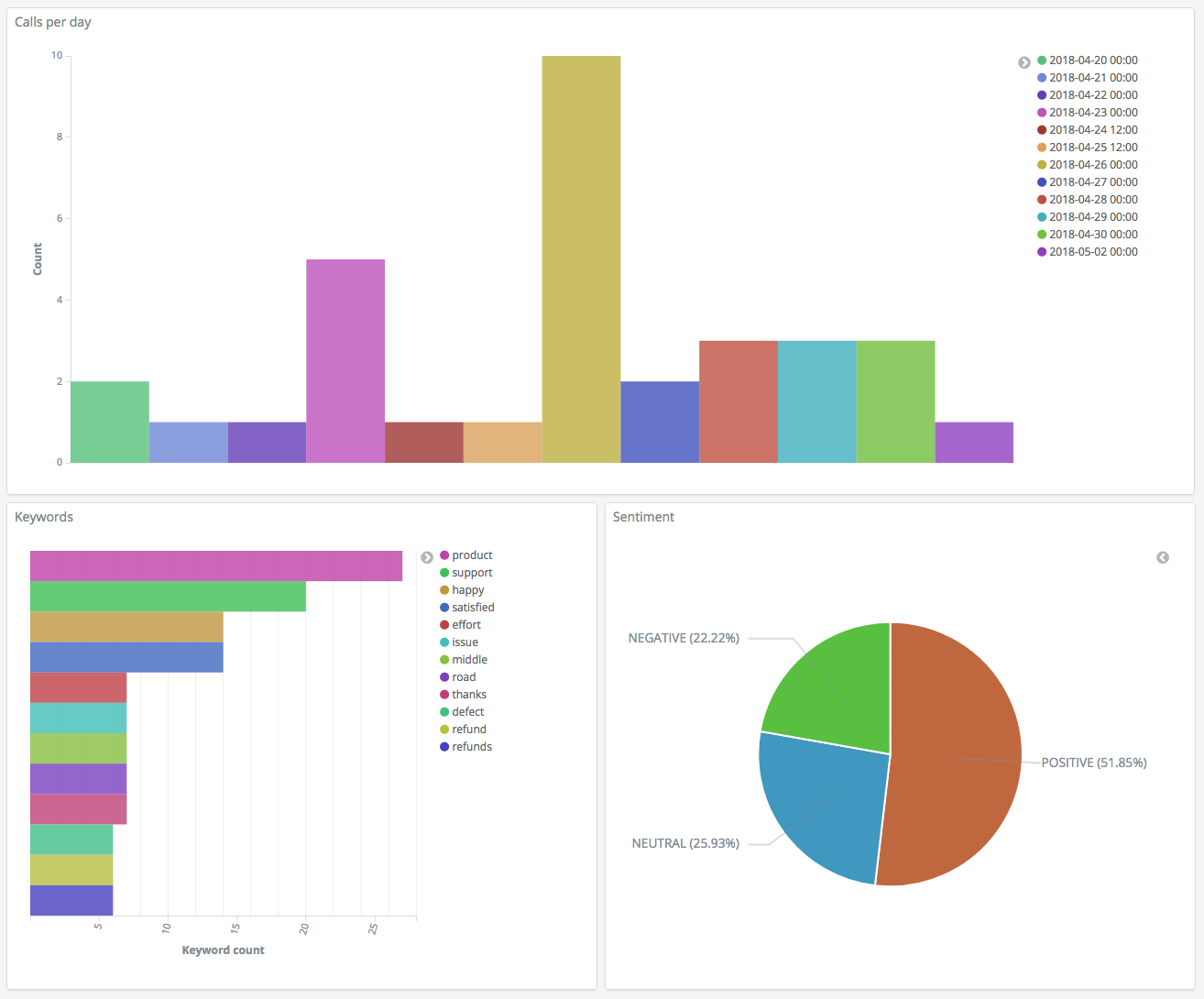
Schritt 5: Bereinigen Sie Ressourcen und nächste Schritte
Um unnötige Gebühren zu vermeiden, löschen Sie den S3-Bucket und die OpenSearch Service-Domain. Weitere Informationen finden Sie unter Löschen eines Buckets im Amazon Simple Storage Service-Benutzerhandbuch und Löschen einer OpenSearch Service-Domain in diesem Handbuch.
Transkripte erfordern weniger Speicherplatz als MP3-Dateien. Sie können die Einstellungen für Ihr MP3-Aufbewahrungsfenster ändern – beispielsweise können Sie die dreimonatige Aufbewahrungsdauer für Anrufaufzeichnungen auf einen Monat verkürzen – Transkripte jahrelang aufbewahren und immer noch Speicherkosten sparen.
Sie können den Transkriptionsprozess auch mithilfe von AWS Step Functions Lambda automatisieren, vor der Indizierung zusätzliche Metadaten hinzufügen oder komplexere Visualisierungen erstellen, die genau auf Ihren Anwendungsfall zugeschnitten sind.
