Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Ereignis-Sourcing-Muster
Absicht
In ereignisgesteuerten Architekturen speichert das Ereignis-Sourcing-Muster die Ereignisse, die zu einer Statusänderung führen, in einem Datenspeicher. Dies hilft dabei, eine vollständige Historie von Statusänderungen zu erfassen und zu verwalten, und fördert die Überprüfbarkeit, Rückverfolgbarkeit und die Fähigkeit, vergangene Zustände zu analysieren.
Motivation
Mehrere Microservices können zusammenarbeiten, um Anfragen zu bearbeiten, und sie kommunizieren über Ereignisse. Diese Ereignisse können zu einer Änderung des Zustands (der Daten) führen. Das Speichern von Ereignisobjekten in der Reihenfolge ihres Auftretens liefert wertvolle Informationen über den aktuellen Zustand der Dateneinheit und zusätzliche Informationen darüber, wie sie zu diesem Zustand gekommen ist.
Anwendbarkeit
Verwenden Sie das Ereignis-Sourcing-Muster, wenn:
-
Für die Nachverfolgung ein unveränderlicher Verlauf der Ereignisse, die in einer Anwendung auftreten, erforderlich ist.
-
Polyglotte Datenprojektionen aus einer Single Source of Truth (SSOT) benötigt werden.
-
Point-in Eine Zeitrekonstruktion des Anwendungsstatus ist erforderlich.
-
Long-term Die Speicherung des Anwendungsstatus ist nicht erforderlich, aber Sie sollten ihn bei Bedarf rekonstruieren.
-
Workloads unterschiedliche Lese- und Schreibvolumen haben. Sie haben beispielsweise schreibintensive Workloads, für die keine Echtzeitverarbeitung erforderlich ist.
-
Change Data Capture (CDC) erforderlich ist, um die Anwendungsleistung und andere Metriken zu analysieren.
-
Audit-Daten für alle Ereignisse, die in einem System auftreten, für Berichts- und Compliance-Zwecke erforderlich sind.
-
Sie Was-wäre-wenn-Szenarien ableiten möchten, indem Sie während des Wiedergabeprozesses Ereignisse ändern (einfügen, aktualisieren oder löschen), um den möglichen Endzustand zu bestimmen.
Fehler und Überlegungen
-
Optimistic Concurrency Control: Dieses Muster speichert jedes Ereignis, das eine Statusänderung im System verursacht. Mehrere Benutzer oder Services können versuchen, dieselben Daten gleichzeitig zu aktualisieren, was zu Ereigniskonflikten führen kann. Diese Konflikte treten auf, wenn widersprüchliche Ereignisse gleichzeitig erzeugt und angewendet werden, was zu einem endgültigen Datenstatus führt, der nicht der Realität entspricht. Um dieses Problem zu beheben, können Sie Strategien zum Erkennen und Auflösen von Ereigniskonflikten implementieren. Sie können beispielsweise ein Schema für Optimistic Concurrency Control implementieren, indem Sie eine Versionsverwaltung hinzufügen oder Ereignisse mit Zeitstempeln versehen, um die Reihenfolge der Aktualisierungen zu verfolgen.
-
Komplexität: Die Implementierung von Event Sourcing erfordert ein Umdenken von traditionellen CRUD-Operationen hin zu ereignisgesteuertem Denken. Der Wiedergabeprozess, mit dem der ursprüngliche Zustand des Systems wiederhergestellt wird, kann komplex sein, um die Idempotenz der Daten zu gewährleisten. Auch die Speicherung von Ereignissen, Backups und Snapshots kann die Komplexität erhöhen.
-
Ereigniskonsistenz: Die aus den Ereignissen abgeleiteten Datenprojektionen sind aufgrund der Latenz bei der Aktualisierung der Daten durch das Muster Command Query Responsibility Segregation (CQRS, Segmentierung der Zuständigkeiten bei Befehlsabfragen) oder materialisierte Ansicht konsistent hinsichtlich der Ereignissen. Wenn Verbraucher Daten aus einem Ereignisspeicher verarbeiten und Publisher neue Daten senden, kann es sein, dass die Datenprojektion oder das Anwendungsobjekt nicht den aktuellen Zustand wiedergibt.
-
Abfragen: Das Abrufen von aktuellen oder aggregierten Daten aus Ereignisprotokollen kann im Vergleich zu herkömmlichen Datenbanken aufwändiger und langsamer sein, insbesondere bei komplexen Abfragen und Berichtsaufgaben. Um dieses Problem zu beheben, wird Ereignis-Sourcing häufig mit dem CQRS-Muster implementiert.
-
Größe und Kosten des Ereignisspeichers: Die Größe des Ereignisspeichers kann exponentiell ansteigen, da die Ereignisse kontinuierlich aufbewahrt werden, insbesondere in Systemen mit hohem Ereignisdurchsatz oder langen Aufbewahrungszeiten. Daher müssen Sie die Ereignisdaten regelmäßig auf kostengünstigem Speicher archivieren, um zu verhindern, dass der Ereignisspeicher zu groß wird.
-
Skalierbarkeit des Ereignisspeichers: Der Ereignisspeicher muss große Mengen an Schreib- und Lesevorgängen effizient verarbeiten. Das Skalieren eines Ereignisspeichers kann eine Herausforderung sein. Daher ist es wichtig, über einen Datenspeicher zu verfügen, der Shards und Partitionen bereitstellt.
-
Effizienz und Optimierung: Wählen oder entwerfen Sie einen Ereignisspeicher, der sowohl Schreib- als auch Lesevorgänge effizient verarbeitet. Der Ereignisspeicher sollte für das erwartete Ereignisvolumen und die Abfragemuster für die Anwendung optimiert werden. Durch die Implementierung von Indizierungs- und Abfragemechanismen kann der Abruf von Ereignissen bei der Rekonstruktion des Anwendungsstatus beschleunigt werden. Sie können auch die Verwendung spezialisierter Datenbanken oder Bibliotheken für Ereignisspeicher in Betracht ziehen, die Features zur Abfrageoptimierung bieten.
-
Snapshots: Sie müssen die Ereignisprotokolle in regelmäßigen Abständen mit zeitbasierter Aktivierung sichern. Die Wiedergabe der Ereignisse auf dem letzten bekannten erfolgreichen Backup der Daten sollte zu einer zeitpunktgenauen Wiederherstellung des Anwendungsstatus führen. Das Recovery Point Objective (RPO) ist die maximal zulässige Zeitspanne seit dem letzten Datenwiederherstellungspunkt. RPO bestimmt, was als akzeptabler Datenverlust zwischen dem letzten Wiederherstellungspunkt und der Serviceunterbrechung angesehen wird. Die Häufigkeit der täglichen Snapshots des Daten- und Ereignisspeichers sollte auf dem RPO für die Anwendung basieren.
-
Zeitabhängigkeit: Die Ereignisse werden in der Reihenfolge gespeichert, in der sie auftreten. Daher ist die Netzwerkzuverlässigkeit ein wichtiger Faktor, den Sie bei der Implementierung dieses Musters berücksichtigen sollten. Latenzprobleme können zu einem fehlerhaften Systemstatus führen. Verwenden Sie First-in, First-out (FIFO)-Warteschlangen mit maximal einmaliger Zustellung, um die Ereignisse in den Ereignisspeicher zu übertragen.
-
Ereignis-Wiedergabeleistung: Die Wiedergabe einer großen Anzahl von Ereignissen zur Rekonstruktion des aktuellen Anwendungsstatus kann zeitaufwändig sein. Es sind Optimierungsmaßnahmen erforderlich, um die Leistung zu verbessern, insbesondere bei der Wiedergabe von Ereignissen aus archivierten Daten.
-
Externe Systemaktualisierungen: Anwendungen, die das Event-Sourcing-Muster verwenden, aktualisieren möglicherweise Datenspeicher in externen Systemen und erfassen diese Aktualisierungen möglicherweise als Ereignisobjekte. Bei der Wiedergabe von Ereignissen kann dies zu einem Problem werden, wenn das externe System keine Aktualisierung erwartet. In solchen Fällen können Sie Feature-Flags verwenden, um externe Systemaktualisierungen zu steuern.
-
Externe Systemabfragen: Wenn externe Systemaufrufe auf das Datum und die Uhrzeit des Aufrufs reagieren, können die empfangenen Daten in internen Datenspeichern gespeichert werden, um sie bei Wiedergaben zu verwenden.
-
Ereignis-Versionsverwaltung: Mit der Weiterentwicklung der Anwendung kann sich die Struktur der Ereignisse (Schema) ändern. Es ist notwendig, eine Versionsverwaltungsstrategie für Ereignisse zu implementieren, um die Rückwärts- und Vorwärtskompatibilität sicherzustellen. Dies kann die Aufnahme eines Versionsfeldes in die Ereignisnutzlast und die angemessene Behandlung verschiedener Ereignisversionen während der Wiedergabe beinhalten.
Implementierung
High-level Architektur
Befehle und Ereignisse
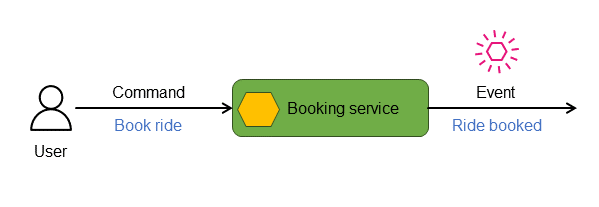
In verteilten, ereignisgesteuerten Microservice-Anwendungen stellen Befehle die Anweisungen oder Anfragen dar, die an einen Service gesendet werden, in der Regel mit der Absicht, eine Änderung seines Zustands einzuleiten. Der Service verarbeitet diese Befehle und bewertet die Gültigkeit und Anwendbarkeit des Befehls auf seinen aktuellen Status. Wenn der Befehl erfolgreich ausgeführt wird, reagiert der Service, indem er ein Ereignis ausgibt, das die ergriffene Aktion und die entsprechenden Statusinformationen angibt. In der folgenden Abbildung reagiert der Buchungsservice beispielsweise auf den Befehl „Fahrt buchen“, indem er das Ereignis „Fahrt gebucht“ ausgibt.
Ereignis-Speicher
Ereignisse werden in einem unveränderlichen und chronologisch geordneten Append-Only-Repository oder -Datenspeicher, dem sogenannten Ereignis-Speicher, protokolliert. Jede Statusänderung wird als individuelles Ereignisobjekt behandelt. Ein Entitätsobjekt oder ein Datenspeicher mit bekanntem Anfangszustand, seinem aktuellen Zustand und einer beliebigen zeitpunktbezogenen Ansicht kann rekonstruiert werden, indem die Ereignisse in der Reihenfolge ihres Auftretens wiedergegeben werden.
Der Ereignis-Speicher dient als historische Aufzeichnung aller Aktionen und Statusänderungen und dient als wertvolle Single Source of Truth. Sie können den Ereignis-Speicher verwenden, um den endgültigen, aktuellen Status des Systems abzuleiten, indem Sie die Ereignisse über einen Wiedergabeprozessor weiterleiten, der diese Ereignisse anwendet, um eine genaue Darstellung des aktuellen Systemstatus zu erstellen. Sie können den Ereignis-Speicher auch verwenden, um den Status zu einem bestimmten Zeitpunkt darzustellen, indem Sie die Ereignisse über einen Wiedergabeprozessor wiedergeben. Im Ereignis-Sourcing-Muster wird der aktuelle Status möglicherweise nicht vollständig durch das jüngste Ereignisobjekt repräsentiert. Sie können den aktuellen Status auf drei Arten ableiten:
-
Durch die Aggregation verwandter Ereignisse. Die zugehörigen Ereignisobjekte werden kombiniert, um den aktuellen Status für die Abfrage zu generieren. Dieser Ansatz wird häufig in Verbindung mit dem CQRS-Muster verwendet, bei dem die Ereignisse kombiniert und in den schreibgeschützten Datenspeicher geschrieben werden.
-
Durch das Verwenden der materialisierten Ansicht. Sie können Event Sourcing mit dem Materialisierte-Ansicht-Muster verwenden, um die Ereignisdaten zu berechnen oder zusammenzufassen und den aktuellen Status der zugehörigen Daten zu ermitteln.
-
Durch die Wiedergabe von Ereignissen. Ereignisobjekte können wiedergegeben werden, um Aktionen zur Generierung des aktuellen Status auszuführen.
Das folgende Diagramm zeigt, wie das Ereignis Ride booked in einem Ereignisspeicher gespeichert wird.
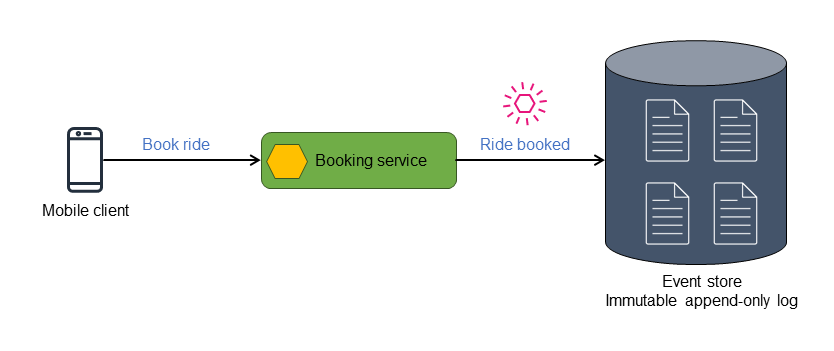
Der Ereignisspeicher veröffentlicht die Ereignisse, die er speichert, und die Ereignisse können gefiltert und für nachfolgende Aktionen an den entsprechenden Prozessor weitergeleitet werden. Ereignisse können beispielsweise an einen Anzeigeprozessor weitergeleitet werden, der den Status zusammenfasst und eine materialisierte Ansicht anzeigt. Die Ereignisse werden in das Datenformat des Zieldatenspeichers umgewandelt. Diese Architektur kann erweitert werden, um verschiedene Arten von Datenspeichern abzuleiten, was zu einer polyglotten Persistenz der Daten führt.
Das folgende Diagramm beschreibt die Ereignisse in einer Anwendung zur Buchung von Fahrten. Alle Ereignisse, die innerhalb der Anwendung auftreten, werden im Ereignisspeicher gespeichert. Gespeicherte Ereignisse werden dann gefiltert und an verschiedene Verbraucher weitergeleitet.
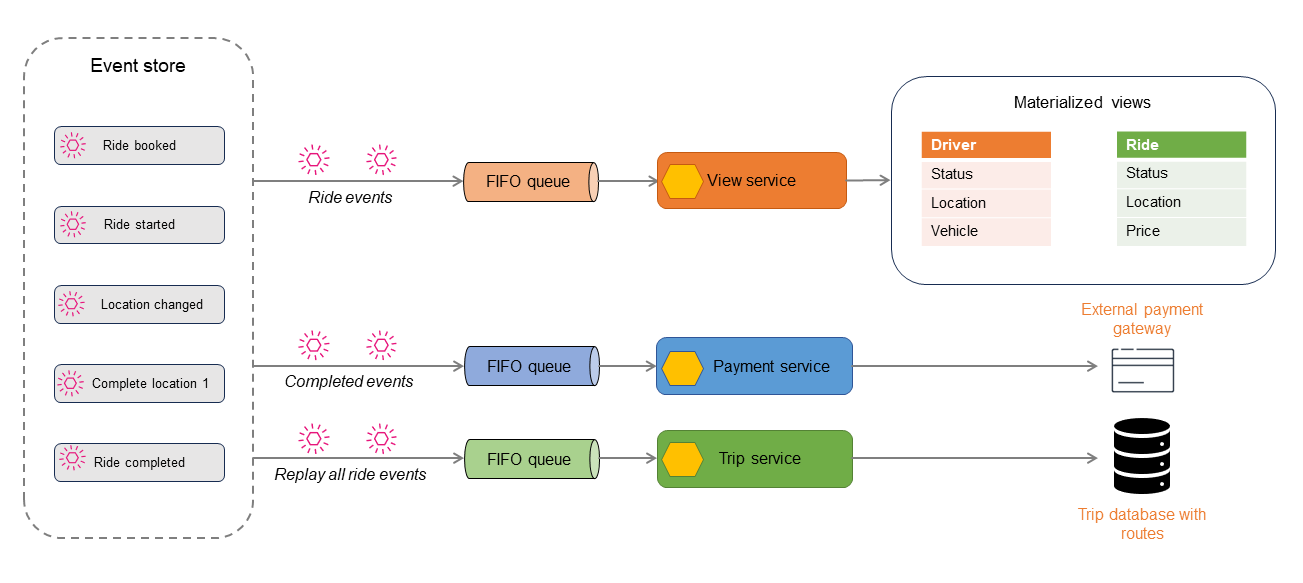
Die Fahrt-Ereignisse können verwendet werden, um schreibgeschützte Datenspeicher mithilfe der CQRS- oder Materialisierte-Ansicht-Muster zu generieren. Sie können den aktuellen Status der Fahrt, des Fahrers oder der Buchung erfahren, indem Sie die Lesespeicher abfragen. Einige Ereignisse, wie z. B. Location changed oder Ride completed, werden an einen anderen Verbraucher zur Zahlungsabwicklung veröffentlicht. Wenn die Fahrt beendet ist, werden alle Ereignisse der Fahrt wiedergegeben, um einen Verlauf der Fahrt für Prüf- oder Berichtszwecke zu erstellen.
Das Ereignis-Sourcing-Muster wird häufig in Anwendungen verwendet, die eine zeitpunktbezogene Wiederherstellung erfordern, und auch dann, wenn die Daten mithilfe einer Single Source of Truth in verschiedenen Formaten projiziert werden müssen. Beide Vorgänge erfordern einen Wiedergabeprozess, um die Ereignisse auszuführen und den erforderlichen Endzustand abzuleiten. Der Wiedergabeprozessor könnte auch einen bekannten Startpunkt benötigen – idealerweise nicht beim Start der Anwendung, denn das würde keinen effizienten Prozess darstellen. Wir empfehlen Ihnen, regelmäßig Snapshots des Systemstatus zu erstellen und eine kleinere Anzahl von Ereignissen anzuwenden, um einen aktuellen Status zu erhalten.
Implementierung mithilfe von AWS-Services
In der folgenden Architektur wird Amazon Kinesis Data Streams als Ereignisspeicher verwendet. Dieser Service erfasst und verwaltet Anwendungsänderungen als Ereignisse und bietet eine Daten-Streaming-Lösung mit hohem Durchsatz und in Echtzeit. Um das Event Sourcing Pattern auf AWS zu implementieren, können Sie je nach den Anforderungen Ihrer Anwendung auch Services wie Amazon EventBridge und Amazon Managed Streaming for Apache Kafka (Amazon MSK) verwenden.
Um die Haltbarkeit zu erhöhen und Prüfungen zu ermöglichen, können Sie die von Kinesis Data Streams erfassten Ereignisse in Amazon Simple Storage Service (Amazon S3) archivieren. Dieser duale Speicheransatz hilft, historische Ereignisdaten für zukünftige Analysen und Compliance-Zwecke sicher beizubehalten.
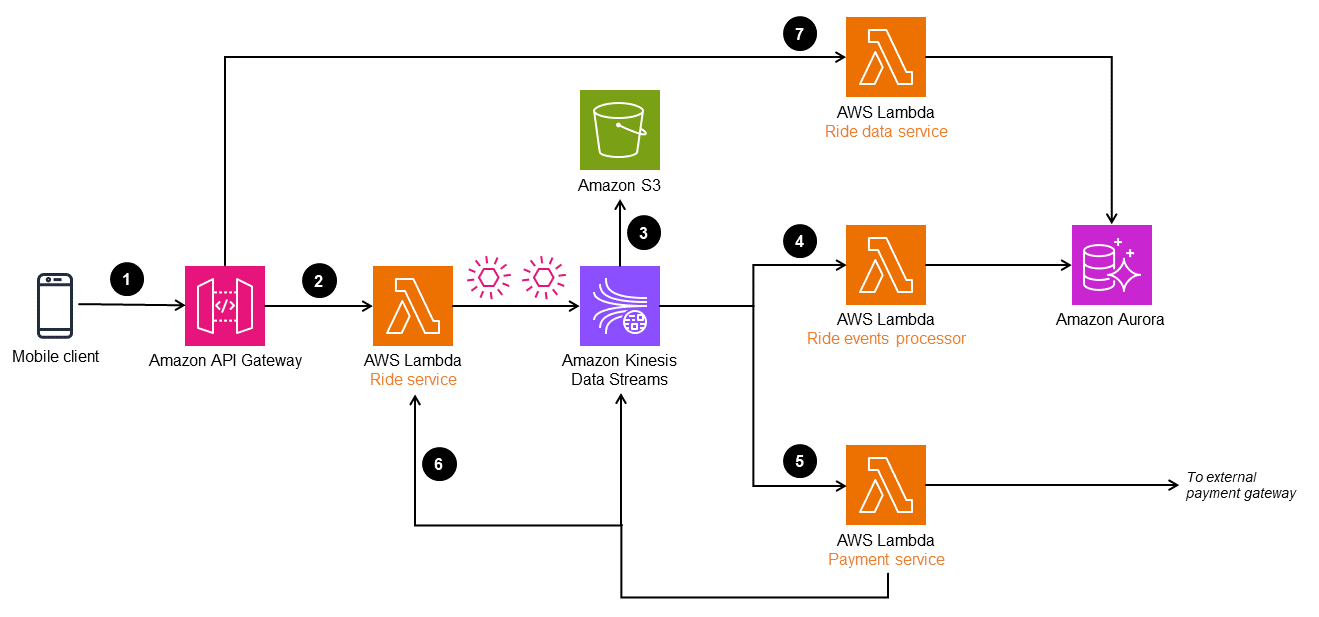
Der Workflow besteht aus folgenden Schritten:
-
Eine Fahrtbuchungsanfrage wird über einen mobilen Client an einen Amazon-API-Gateway-Endpunkt gestellt.
-
Der Fahrt-Microservice (
Ride service-Lambda-Funktion) empfängt die Anfrage, wandelt die Objekte um und veröffentlicht sie in Kinesis Data Streams. -
Die Ereignisdaten in Kinesis Data Streams werden zu Compliance- und Prüfungs-Zwecken in Amazon S3 gespeichert.
-
Die Ereignisse werden von der
Ride event processor-Lambda-Funktion umgewandelt und verarbeitet und in einer Amazon-Aurora-Datenbank gespeichert, um eine materialisierte Ansicht für die Fahrtdaten bereitzustellen. -
Die abgeschlossenen Fahrt-Ereignisse werden gefiltert und zur Zahlungsabwicklung an ein externes Zahlungs-Gateway gesendet. Wenn die Zahlung abgeschlossen ist, wird ein weiteres Ereignis an Kinesis Data Streams gesendet, um die Fahrt-Datenbank zu aktualisieren.
-
Wenn die Fahrt abgeschlossen ist, werden die Fahrt-Ereignisse an die
Ride service-Lambda-Funktion wiedergegeben, um Routen und den Verlauf der Fahrt zu erstellen. -
Fahrt-Informationen können über den
Ride data service, der aus der Aurora-Datenbank gelesen wird, abgerufen werden.
API Gateway kann auch ohne die Ride service-Lambda-Funktion das Ereignisobjekt direkt an Kinesis Data Streams senden. In einem komplexen System wie einem Taxidienst muss das Ereignisobjekt jedoch möglicherweise verarbeitet und angereichert werden, bevor es in den Datenstrom aufgenommen wird. Aus diesem Grund verfügt die Architektur über einen Ride service, der das Ereignis verarbeitet, bevor er es an Kinesis Data Streams sendet.
Blog-Referenzen
