Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Verteilte Verfügbarkeitsgruppen
Eine verteilte Verfügbarkeitsgruppe umfasst zwei separate Verfügbarkeitsgruppen. Sie können sie sich als eine Verfügbarkeitsgruppe von Verfügbarkeitsgruppen vorstellen. Die zugrunde liegenden Verfügbarkeitsgruppen sind auf zwei verschiedenen WSFC-Clustern konfiguriert. Die Verfügbarkeitsgruppen, die Teil einer verteilten Verfügbarkeitsgruppe sind, müssen sich nicht denselben Standort teilen. Sie können physisch oder virtuell, lokal oder in der Public Cloud sein. Die Verfügbarkeitsgruppen in einer verteilten Verfügbarkeitsgruppe müssen nicht dieselbe Version von SQL Server ausführen. Die Ziel-DB-Instance kann eine neuere Version von SQL Server als die Quell-DB-Instance ausführen.
Eine verteilte Verfügbarkeitsgruppenarchitektur bietet Ihnen eine flexible Möglichkeit, eine unternehmenskritische SQL Server-Instanz oder Datenbank neu zu hosten. AWS Sie bietet eine Hybridlösung für das Lifting and Shifting (oder Lifting und Transformation) Ihrer kritischen SQL Server-Datenbanken. AWS
Die Verwendung einer Architektur für verteilte Verfügbarkeitsgruppen ist effizienter als die Erweiterung vorhandener lokaler WFSC-Cluster. AWSDaten werden nur vom lokalen Primärserver an eines der AWS Replikate (den Forwarder) übertragen. Der Forwarder ist dafür verantwortlich, Daten an andere sekundäre Read-Replicas zu senden. AWS
In der folgenden Abbildung wird der erste WSFC-Cluster (WSFC 1) lokal gehostet und verfügt über eine lokale Verfügbarkeitsgruppe (AG 1). Der zweite WSFC-Cluster (WSFC 2) wird auf gehostet AWS und verfügt über eine AWS Verfügbarkeitsgruppe (AG 2). Direct Connect
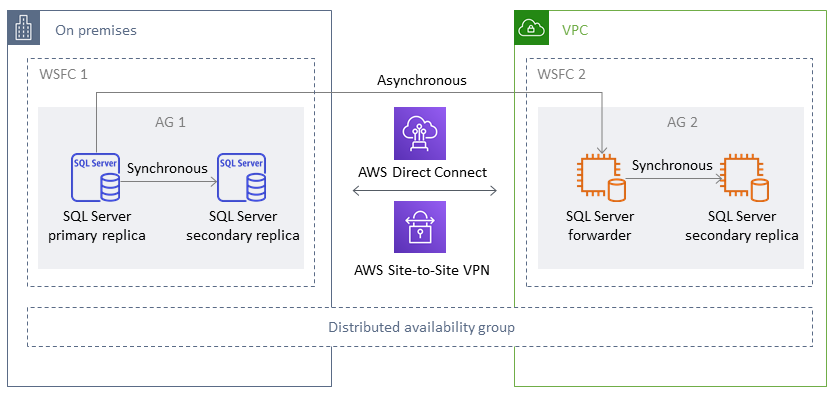
Anmerkung
Zu einem bestimmten Zeitpunkt gibt es nur eine Datenbank, die für Schreibvorgänge verfügbar ist. Sie können die verbleibenden sekundären Replikate für Lesevorgänge verwenden. Um Ihre Lese-Workloads zu skalieren, können Sie weitere Read Replicas in mehreren Availability Zones hinzufügen. AWS
Weitere Informationen zu verteilten Verfügbarkeitsgruppen finden Sie unter:
-
So erstellen Sie eine hybride Microsoft SQL Server-Lösung mithilfe verteilter Verfügbarkeitsgruppen
im AWS Datenbank-Blog -
Migrieren Sie SQL Server auf die AWS Verwendung verteilter Verfügbarkeitsgruppen auf der AWS Prescriptive Guidance-Website
