Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Verwenden Sie Caching, um den Datenbankbedarf zu reduzieren
-Übersicht
Sie können Caching als effektive Strategie verwenden, um die Kosten für Ihre .NET-Anwendungen zu senken. Viele Anwendungen verwenden Backend-Datenbanken wie SQL Server, wenn Anwendungen häufig auf Daten zugreifen müssen. Die Kosten für die Wartung dieser Back-End-Dienste zur Deckung der Nachfrage können hoch sein. Sie können jedoch eine effektive Caching-Strategie verwenden, um die Belastung der Backend-Datenbanken zu reduzieren, indem Sie die Anforderungen an Größe und Skalierung reduzieren. Dies kann Ihnen helfen, die Kosten zu senken und die Leistung Ihrer Anwendungen zu verbessern.
Caching ist eine nützliche Technik, um Kosten im Zusammenhang mit leseintensiven Workloads zu sparen, die teurere Ressourcen wie SQL Server beanspruchen. Es ist wichtig, dass Sie die richtige Technik für Ihre Arbeitslast verwenden. Lokales Caching ist beispielsweise nicht skalierbar und erfordert, dass Sie für jede Instanz einer Anwendung einen lokalen Cache verwalten. Sie sollten die Auswirkungen auf die Leistung im Vergleich zu den potenziellen Kosten abwägen, sodass die niedrigeren Kosten der zugrunde liegenden Datenquelle alle zusätzlichen Kosten im Zusammenhang mit dem Caching-Mechanismus ausgleichen.
Auswirkung auf die Kosten
SQL Server verlangt, dass Sie bei der Dimensionierung Ihrer Datenbank Leseanforderungen berücksichtigen. Dies könnte sich auf die Kosten auswirken, da Sie möglicherweise Read Replicas einführen müssen, um der Last gerecht zu werden. Wenn Sie Read Replicas verwenden, sollten Sie sich darüber im Klaren sein, dass diese nur in der SQL Server Enterprise Edition verfügbar sind. Für diese Edition ist eine teurere Lizenz als die SQL Server Standard Edition erforderlich.
Das folgende Diagramm soll Ihnen helfen, die Effektivität des Cachings zu verstehen. Es zeigt Amazon RDS for SQL Server mit vier db.m4.2xlarge-Knoten, auf denen die SQL Server Enterprise Edition ausgeführt wird. Es wird in einer Multi-AZ Konfiguration mit einer Read Replica bereitgestellt. Exklusiver Leseverkehr (z. B. SELECT-Abfragen) wird an die Read Replicas weitergeleitet. Im Vergleich dazu verwendet Amazon DynamoDB einen DynamoDB Accelerator (DAX) -Cluster (R4.2xlarge) mit zwei Knoten.
Das folgende Diagramm zeigt die Ergebnisse, wenn keine dedizierten Read Replicas mehr benötigt werden, die hohen Leseverkehr verarbeiten.
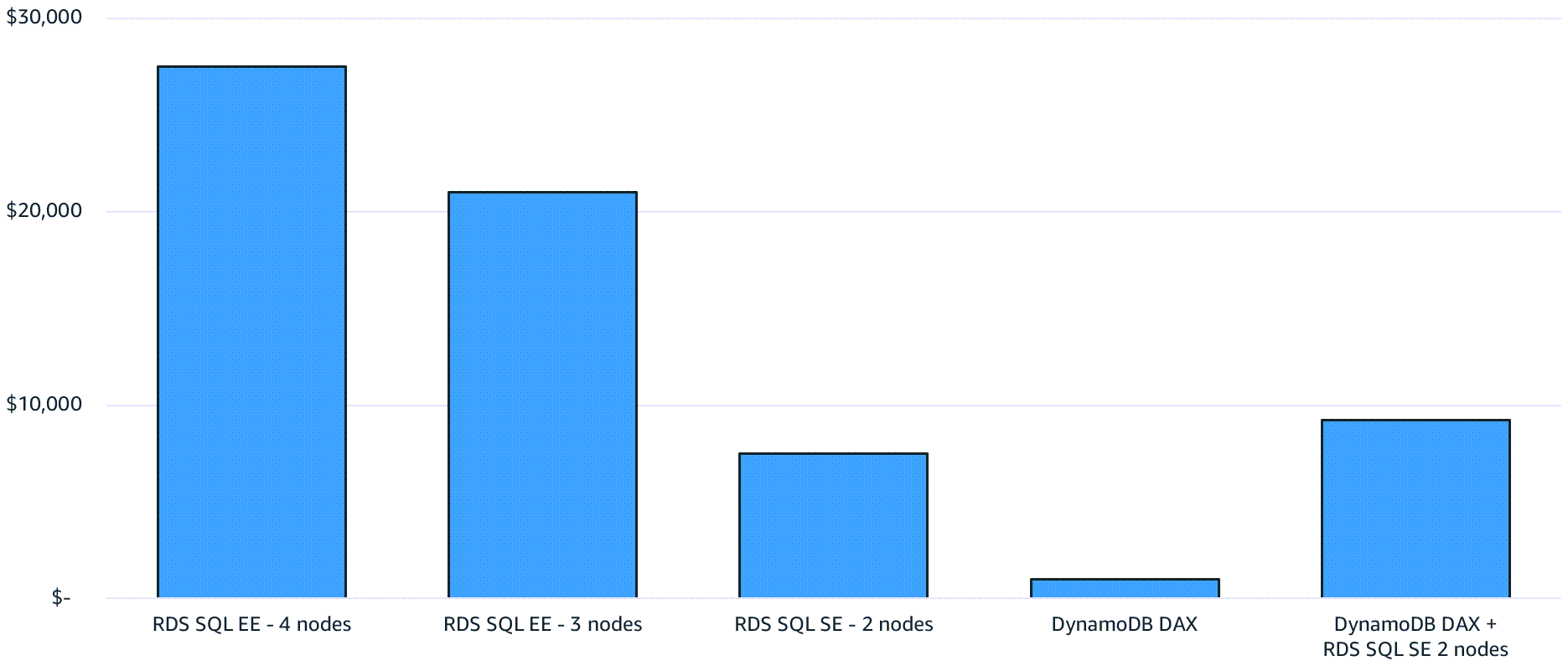
Sie können erhebliche Kosteneinsparungen erzielen, indem Sie lokales Caching ohne Read Replicas verwenden oder DAX Seite an Seite mit SQL Server auf Amazon RDS als Caching-Ebene einführen. Diese Ebene entlastet SQL Server und reduziert die Größe des SQL-Servers, der für den Betrieb der Datenbank erforderlich ist.
Empfehlungen zur Kostenoptimierung
Lokales Caching
Lokales Caching ist eine der am häufigsten verwendeten Methoden zum Zwischenspeichern von Inhalten für Anwendungen, die sowohl in lokalen Umgebungen als auch in der Cloud gehostet werden. Das liegt daran, dass es relativ einfach und intuitiv zu implementieren ist. Beim lokalen Caching werden Inhalte aus einer Datenbank oder einer anderen Quelle entnommen und entweder lokal im Arbeitsspeicher oder auf der Festplatte zwischengespeichert, um schneller darauf zugreifen zu können. Dieser Ansatz ist zwar einfach zu implementieren, für einige Anwendungsfälle jedoch nicht ideal. Dies schließt beispielsweise Anwendungsfälle ein, in denen der Caching-Inhalt über einen längeren Zeitraum erhalten bleiben muss, z. B. die Beibehaltung des Anwendungs- oder Benutzerstatus. Ein weiterer Anwendungsfall ist, wenn auf zwischengespeicherte Inhalte von anderen Anwendungsinstanzen aus zugegriffen werden muss.
Das folgende Diagramm zeigt einen hochverfügbaren SQL Server-Cluster mit vier Knoten und zwei Read Replicas.
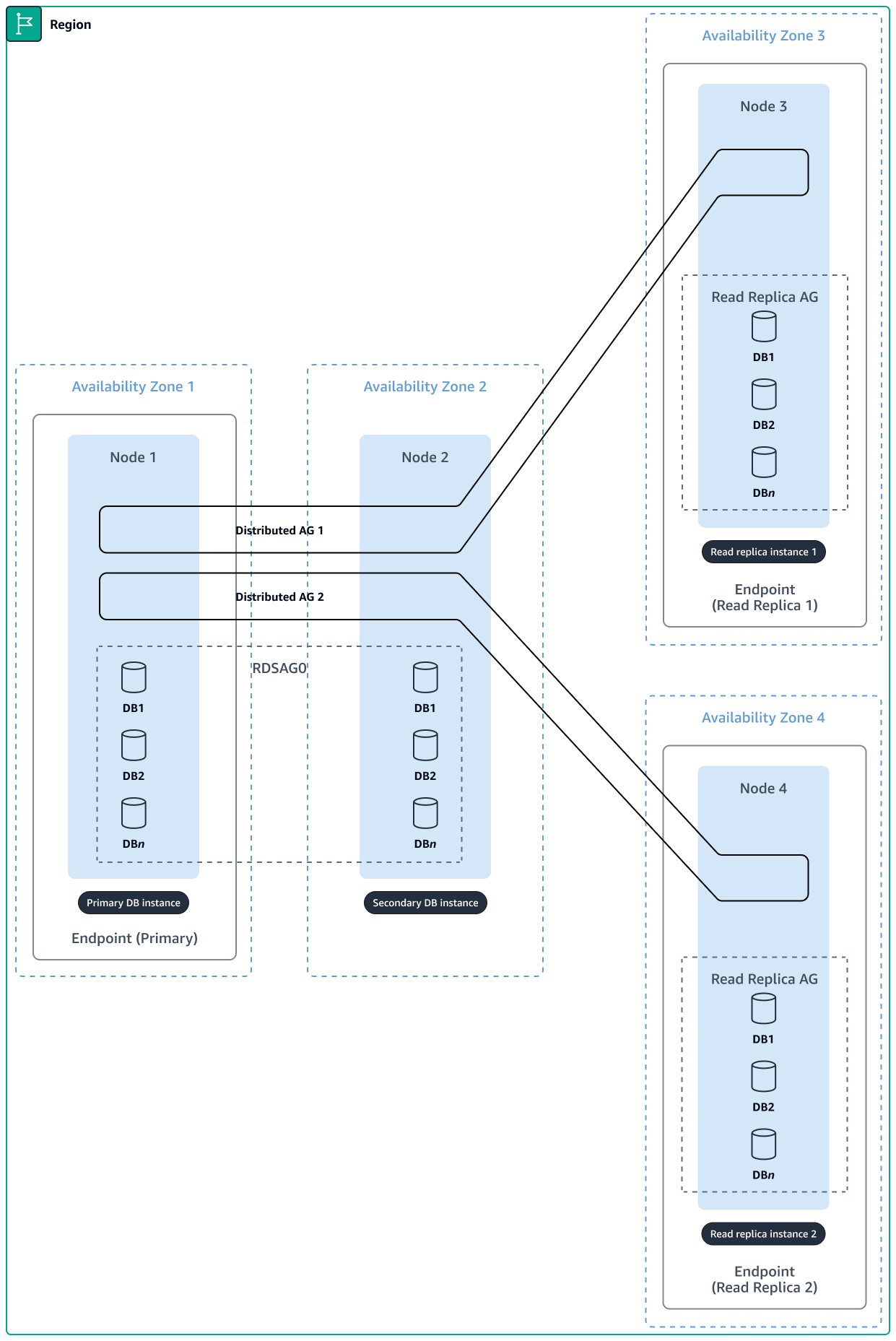
Bei lokalem Caching müssen Sie möglicherweise einen Lastenausgleich für den Datenverkehr auf mehrere EC2-Instances durchführen. Jede Instanz muss ihren eigenen lokalen Cache verwalten. Wenn der Cache Statusinformationen speichert, müssen regelmäßige Commits an die Datenbank vorgenommen werden, und Benutzer müssen möglicherweise für jede weitere Anfrage an dieselbe Instanz weitergeleitet werden (Sticky Session). Dies stellt bei der Skalierung von Anwendungen eine Herausforderung dar, da einige Instanzen überlastet sein könnten, während andere aufgrund der ungleichmäßigen Verteilung des Datenverkehrs nicht ausgelastet sind.
Sie können lokales Caching für .NET-Anwendungen verwenden, entweder im Arbeitsspeicher oder unter Verwendung von lokalem Speicher. Zu diesem Zweck können Sie Funktionen hinzufügen, um Objekte entweder auf der Festplatte zu speichern und sie bei Bedarf abzurufen oder Daten aus der Datenbank abzufragen und im Speicher zu speichern. Um beispielsweise lokales Zwischenspeichern im Arbeitsspeicher und beim lokalen Speichern von Daten von einem SQL Server in C# durchzuführen, können Sie eine Kombination aus Bibliotheken und verwenden. MemoryCache LiteDB MemoryCachebietet In-Memory-Caching und LiteDB ist gleichzeitig eine eingebettete, festplattenbasierte NoSQL-Datenbank, die schnell und leicht ist.
Verwenden Sie die .NET-Bibliothek, um In-Memory-Caching durchzuführen. System.Runtime.MemoryCache Das folgende Codebeispiel zeigt, wie die System.Runtime.Caching.MemoryCache Klasse verwendet wird, um Daten im Speicher zwischenzuspeichern. Diese Klasse bietet eine Möglichkeit, Daten vorübergehend im Speicher der Anwendung zu speichern. Dies kann dazu beitragen, die Leistung einer Anwendung zu verbessern, da weniger Daten aus einer teureren Ressource wie einer Datenbank oder einer API abgerufen werden müssen.
So funktioniert der Code:
-
Eine private statische Instanz von
MemoryCachenamed_memoryCachewird erstellt. Der Cache erhält einen Namen (dataCache), um ihn zu identifizieren. Anschließend speichert und ruft der Cache die Daten ab. -
Die
GetDataMethode ist eine generische Methode, die zwei Argumente benötigt: einenstringSchlüssel und einen aufgerufenenFunc<T>Delegaten.getDataDer Schlüssel wird verwendet, um die zwischengespeicherten Daten zu identifizieren, während dergetDataDelegat die Datenabruflogik darstellt, die ausgeführt wird, wenn die Daten nicht im Cache vorhanden sind. -
Die Methode überprüft anhand der Methode zunächst, ob die Daten im Cache vorhanden sind.
_memoryCache.Contains(key)Wenn sich die Daten im Cache befinden, ruft die Methode die Daten mithilfe von T ab_memoryCache.Get(key)und wandelt sie in den erwarteten Typ um. -
Wenn sich die Daten nicht im Cache befinden, ruft die Methode den
getDataDelegaten auf, um die Daten abzurufen. Anschließend fügt sie die Daten dem Cache hinzu, indem sie_memoryCache.Add(key, data, DateTimeOffset.Now.AddMinutes(10))Dieser Aufruf gibt an, dass der Cacheeintrag nach 10 Minuten ablaufen soll. Zu diesem Zeitpunkt werden die Daten automatisch aus dem Cache entfernt. -
Die
ClearCacheMethode verwendet einenstringSchlüssel als Argument und entfernt die mit diesem Schlüssel verknüpften Daten mithilfe von_memoryCache.Remove(key).
using System; using System.Runtime.Caching; public class InMemoryCache { private static MemoryCache _memoryCache = new MemoryCache("dataCache"); public static T GetData<T>(string key, Func<T> getData) { if (_memoryCache.Contains(key)) { return (T)_memoryCache.Get(key); } T data = getData(); _memoryCache.Add(key, data, DateTimeOffset.Now.AddMinutes(10)); return data; } public static void ClearCache(string key) { _memoryCache.Remove(key); } }
Sie können den folgenden Code verwenden:
public class Program { public static void Main() { string cacheKey = "sample_data"; Func<string> getSampleData = () => { // Replace this with your data retrieval logic return "Sample data"; }; string data = InMemoryCache.GetData(cacheKey, getSampleData); Console.WriteLine("Data: " + data); } }
Das folgende Beispiel zeigt Ihnen, wie Sie LiteDBLocalStorageCache Klasse enthält die Hauptfunktionen für die Verwaltung des Caches.
using System; using LiteDB; public class LocalStorageCache { private static string _liteDbPath = @"Filename=LocalCache.db"; public static T GetData<T>(string key, Func<T> getData) { using (var db = new LiteDatabase(_liteDbPath)) { var collection = db.GetCollection<T>("cache"); var item = collection.FindOne(Query.EQ("_id", key)); if (item != null) { return item; } } T data = getData(); using (var db = new LiteDatabase(_liteDbPath)) { var collection = db.GetCollection<T>("cache"); collection.Upsert(new BsonValue(key), data); } return data; } public static void ClearCache(string key) { using (var db = new LiteDatabase(_liteDbPath)) { var collection = db.GetCollection("cache"); collection.Delete(key); } } } public class Program { public static void Main() { string cacheKey = "sample_data"; Func<string> getSampleData = () => { // Replace this with your data retrieval logic return "Sample data"; }; string data = LocalStorageCache.GetData(cacheKey, getSampleData); Console.WriteLine("Data: " + data); } }
Wenn Sie über einen statischen Cache oder statische Dateien verfügen, die sich nicht häufig ändern, können Sie diese Dateien auch im Objektspeicher von Amazon Simple Storage Service (Amazon S3) speichern. Die Anwendung kann die statische Cache-Datei beim Start abrufen, um sie lokal zu verwenden. Weitere Informationen zum Abrufen von Dateien aus Amazon S3 mithilfe von.NET finden Sie unter Objekte herunterladen in der Amazon S3 S3-Dokumentation.
Caching mit DAX
Sie können eine Caching-Ebene verwenden, die von allen Anwendungsinstanzen gemeinsam genutzt werden kann. DynamoDB Accelerator (DAX) ist ein vollständig verwalteter, hochverfügbarer In-Memory-Cache für DynamoDB, der die Leistung um das Zehnfache verbessern kann. Sie können DAX verwenden, um Kosten zu senken, indem Sie die Notwendigkeit reduzieren, Lesekapazitätseinheiten in DynamoDB-Tabellen übermäßig bereitzustellen. Dies ist besonders nützlich für Workloads, die viele Lesevorgänge erfordern und wiederholte Lesevorgänge für einzelne Schlüssel erfordern.
DynamoDB wird auf Anfrage oder mit bereitgestellter Kapazität berechnet, sodass die Anzahl der Lese- und Schreibvorgänge pro Monat zu den Kosten beiträgt. Wenn Sie umfangreiche Workloads gelesen haben, können DAX-Cluster helfen, die Kosten zu senken, indem sie die Anzahl der Lesevorgänge in Ihren DynamoDB-Tabellen reduzieren. Anweisungen zur Einrichtung von DAX finden Sie unter In-memory Beschleunigung mit DynamoDB Accelerator (DAX) in der DynamoDB-Dokumentation. Informationen zur Integration von.NET-Anwendungen finden Sie unter Integrieren von Amazon DynamoDB DAX in Ihre ASP.NET Anwendung auf
Weitere Ressourcen
