Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Migrieren Sie Hadoop-Daten mithilfe WANdisco LiveData von Migrator zu Amazon S3
Erstellt von Tony Velcich
Quelle: Lokaler Hadoop-Cluster | Ziel: Amazon S3 | R-Typ: Rehost |
Umgebung: Produktion | Technologien: DataLakes; Große Datenmengen; Hybrid-Cloud; Migration | Arbeitslast: Alle anderen Workloads |
AWSDienste: Amazon S3 |
Übersicht
Dieses Muster beschreibt den Prozess für die Migration von Apache Hadoop-Daten von einem Hadoop Distributed File System (HDFS) zu Amazon Simple Storage Service (Amazon S3). Es verwendet WANdisco LiveData Migrator, um den Datenmigrationsprozess zu automatisieren.
Voraussetzungen und Einschränkungen
Voraussetzungen
Hadoop-Cluster-Edge-Knoten, auf dem LiveData Migrator installiert wird. Der Knoten sollte die folgenden Anforderungen erfüllen:
Mindestspezifikation: 4CPUs, 16 GBRAM, 100 GB Speicher.
Netzwerk mit mindestens 2 Gbit/s.
Port 8081, auf den auf Ihrem Edge-Knoten zugegriffen werden kann, um auf die WANdisco Benutzeroberfläche zuzugreifen.
Java 1.8 64-Bit.
Auf dem Edge-Knoten installierte Hadoop-Clientbibliotheken.
Möglichkeit, sich als HDFSSuperuser
zu authentifizieren (z. B. „hdfs“). Wenn Kerberos auf Ihrem Hadoop-Cluster aktiviert ist, muss auf dem Edge-Knoten ein gültiger Keytab verfügbar sein, der einen geeigneten Principal für den HDFS Superuser enthält.
Eine Liste der unterstützten Betriebssysteme finden Sie in den Versionshinweisen
.
Ein aktives AWS Konto mit Zugriff auf einen S3-Bucket.
Ein AWS Direct Connect-Link, der zwischen Ihrem lokalen Hadoop-Cluster (insbesondere dem Edge-Knoten) und hergestellt wird. AWS
Produktversionen
LiveData Migrator 1.8.6
WANdiscoBenutzeroberfläche (OneUI) 5.8.0
Architektur
Quelltechnologie-Stack
Lokaler Hadoop-Cluster
Zieltechnologie-Stack
Amazon S3
Architektur
Das folgende Diagramm zeigt die Architektur der LiveData Migrator-Lösung.
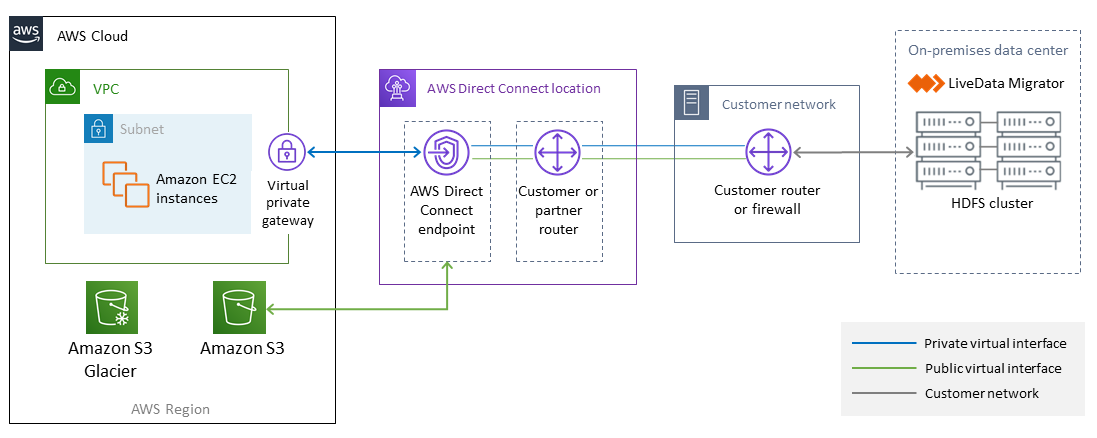
Der Workflow besteht aus vier Hauptkomponenten für die Datenmigration von lokalen Systemen HDFS zu Amazon S3.
LiveData Migrator
— Automatisiert die Migration von Daten von HDFS zu Amazon S3 und befindet sich auf einem Edge-Knoten des Hadoop-Clusters. HDFS
— Ein verteiltes Dateisystem, das Zugriff auf Anwendungsdaten mit hohem Durchsatz ermöglicht. Amazon S3
— Ein Objektspeicherservice, der Skalierbarkeit, Datenverfügbarkeit, Sicherheit und Leistung bietet. AWSDirect Connect — Ein Dienst, der eine dedizierte Netzwerkverbindung von Ihren lokalen Rechenzentren zu AWS herstellt.
Automatisierung und Skalierung
In der Regel erstellen Sie mehrere Migrationen, sodass Sie bestimmte Inhalte aus Ihrem Quelldateisystem nach Pfad oder Verzeichnis auswählen können. Sie können Daten auch in mehrere unabhängige Dateisysteme gleichzeitig migrieren, indem Sie mehrere Migrationsressourcen definieren.
Epen
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Melden Sie sich bei Ihrem AWS-Konto an. | Melden Sie sich bei der AWS Management Console an und öffnen Sie die Amazon S3 S3-Konsole unter https://console.aws.amazon.com/s3/. | AWSErfahrung |
Erstellen Sie einen S3-Bucket. | Wenn Sie noch keinen vorhandenen S3-Bucket haben, den Sie als Zielspeicher verwenden können, wählen Sie in der Amazon S3 S3-Konsole die Option „Bucket erstellen“ und geben Sie einen Bucket-Namen, eine AWS Region und Bucket-Einstellungen für den Block Public Access an. AWSund WANdisco empfehlen Ihnen, die Optionen zum Blockieren des öffentlichen Zugriffs für den S3-Bucket zu aktivieren und die Richtlinien für den Bucket-Zugriff und die Benutzerberechtigungen so einzurichten, dass sie den Anforderungen Ihrer Organisation entsprechen. Ein AWS Beispiel finden Sie unter https://docs.aws.amazon.com/AmazonS3/ example-walkthroughs-managing-access latest/dev/ -example1.html. | AWSErfahrung |
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Laden Sie das LiveData Migrator-Installationsprogramm herunter. | Laden Sie das LiveData Migrator-Installationsprogramm herunter und laden Sie es auf den Hadoop Edge-Knoten hoch. Sie können eine kostenlose Testversion von LiveData Migrator unter /aws.amazon.com/marketplace/pp/B07B8 herunterladen. https://www2.wandisco.com/ldm-trial. You can also obtain access to LiveData Migrator from AWS Marketplace, at https:/ SZND9 | Hadoop-Administrator, Besitzer der Anwendung |
Installieren Sie LiveData Migrator. | Verwenden Sie das heruntergeladene Installationsprogramm und installieren Sie LiveData Migrator als HDFS Superuser auf einem Edge-Knoten in Ihrem Hadoop-Cluster. Die Installationsbefehle finden Sie im Abschnitt „Zusätzliche Informationen“. | Hadoop-Administrator, Besitzer der Anwendung |
Überprüfen Sie den Status von LiveData Migrator und anderen Diensten. | Überprüfen Sie den Status von LiveData Migrator, Hive Migrator und WANdisco UI mithilfe der Befehle im Abschnitt „Zusätzliche Informationen“. | Hadoop-Administrator, Anwendungsbesitzer |
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Registrieren Sie Ihr LiveData Migrator-Konto. | Melden Sie sich über einen Webbrowser auf Port 8081 (auf dem Hadoop-Edge-Knoten) bei der WANdisco Benutzeroberfläche an und geben Sie Ihre Daten für die Registrierung ein. Wenn Sie LiveData Migrator beispielsweise auf einem Host namens myldmhost.example.com ausführen, wäre das: http://myldmhost.example.com:8081 URL | Besitzer der Anwendung |
Konfigurieren Sie Ihren HDFS Quellspeicher. | Geben Sie die für Ihren HDFS Quellspeicher erforderlichen Konfigurationsdetails an. Dazu gehören der Wert „fs.defaultFS“ und ein benutzerdefinierter Speichername. Wenn Kerberos aktiviert ist, geben Sie den Principal- und den Keytab-Speicherort an, den Migrator verwenden soll. LiveData Wenn NameNode HA auf dem Cluster aktiviert ist, geben Sie einen Pfad zu den Dateien core-site.xml und hdfs-site.xml auf dem Edge-Knoten an. | Hadoop-Administrator, Besitzer der Anwendung |
Konfigurieren Sie Ihren Amazon S3 S3-Zielspeicher. | Fügen Sie Ihren Zielspeicher als Typ S3a hinzu. Geben Sie den benutzerdefinierten Speichernamen und den S3-Bucket-Namen an. Geben Sie „org.apache.hadoop.fs.s3a.S impleAWSCredentials Provider“ für die Option Credentials Provider ein und geben Sie die Zugriffs- und Geheimschlüssel für den S3-Bucket ein. AWS Zusätzliche S3a-Eigenschaften werden ebenfalls benötigt. Einzelheiten finden Sie im Abschnitt „S3a-Eigenschaften“ in der LiveData Migrator-Dokumentation unter https://docs.wandisco.com/live-data-migrator/ docs/command-reference/# 3a. filesystem-add-s | AWS, Besitzer der Anwendung |
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Fügen Sie Ausnahmen hinzu (falls erforderlich). | Wenn Sie bestimmte Datensätze von der Migration ausschließen möchten, fügen Sie Ausnahmen für den Quellspeicher hinzu. HDFS Diese Ausnahmen können auf der Dateigröße, den Dateinamen (basierend auf Regex-Mustern) und dem Änderungsdatum basieren. | Hadoop-Administrator, Besitzer der Anwendung |
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Erstellen und konfigurieren Sie die Migration. | Erstellen Sie eine Migration im Dashboard der WANdisco Benutzeroberfläche. Wählen Sie Ihre Quelle (HDFS) und Ihr Ziel (den S3-Bucket). Fügen Sie neue Ausnahmen hinzu, die Sie im vorherigen Schritt definiert haben. Wählen Sie entweder die Option „Überschreiben“ oder die Option „Überspringen, wenn die Größe übereinstimmt“. Erstellen Sie die Migration, wenn alle Felder vollständig sind. | Hadoop-Administrator, Besitzer der Anwendung |
Starten Sie die Migration. | Wählen Sie im Dashboard die Migration aus, die Sie erstellt haben. Klicken Sie hier, um die Migration zu starten. Sie können eine Migration auch automatisch starten, indem Sie bei der Erstellung der Migration die Option Autostart auswählen. | Besitzer der Anwendung |
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Legen Sie ein Netzwerkbandbreitenlimit zwischen Quelle und Ziel fest. | Wählen Sie in der Speicherliste auf dem Dashboard Ihren Quellspeicher aus und wählen Sie in der Gruppierungsliste „Bandbreitenverwaltung“ aus. Deaktivieren Sie die Option „Unbegrenzt“ und definieren Sie das maximale Bandbreitenlimit und die maximale Bandbreiteneinheit. Wählen Sie „Anwenden“. | Inhaber der Anwendung, Netzwerk |
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Zeigen Sie Migrationsinformationen über die WANdisco Benutzeroberfläche an. | Verwenden Sie die WANdisco Benutzeroberfläche, um Lizenz-, Bandbreiten-, Speicher- und Migrationsinformationen anzuzeigen. Die Benutzeroberfläche bietet auch ein Benachrichtigungssystem, sodass Sie Benachrichtigungen über Fehler, Warnungen oder wichtige Meilensteine Ihrer Nutzung erhalten können. | Hadoop-Administrator, Anwendungsbesitzer |
Migrationen beenden, fortsetzen und löschen. | Sie können verhindern, dass bei einer Migration Inhalte auf das Ziel übertragen werden, indem Sie sie in den STOPPED entsprechenden Status versetzen. Gestoppte Migrationen können wieder aufgenommen werden. Migrationen im STOPPED Bundesstaat können auch gelöscht werden. | Hadoop-Administrator, Besitzer der Anwendung |
Zugehörige Ressourcen
Zusätzliche Informationen
Installation von Migrator LiveData
Sie können LiveData Migrator mit den folgenden Befehlen installieren, vorausgesetzt, das Installationsprogramm befindet sich in Ihrem Arbeitsverzeichnis:
su – hdfs chmod +x livedata-migrator.sh && sudo ./livedata-migrator.sh
Überprüfen Sie den Status von LiveData Migrator und anderen Diensten nach der Installation
Verwenden Sie die folgenden Befehle, um den Status von LiveData Migrator, Hive Migrator und UI zu überprüfen: WANdisco
service livedata-migrator status service hivemigrator status service livedata-ui status
