Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Übersicht über das -Framework
Der Rahmen für die Resilienzanalyse wurde entwickelt, indem die gewünschten Resilienzeigenschaften einer Arbeitslast ermittelt wurden. Bei den gewünschten Eigenschaften handelt es sich um die Dinge, die für das System gelten sollen. Resilienz wird in der Regel an der Verfügbarkeit gemessen. Daher sind fünf Eigenschaften die Merkmale eines hochverfügbaren verteilten Systems: Redundanz, ausreichende Kapazität, rechtzeitige Ausgabe, korrekte Ausgabe und Fehlerisolierung. Diese Eigenschaften sind in der folgenden Abbildung dargestellt.
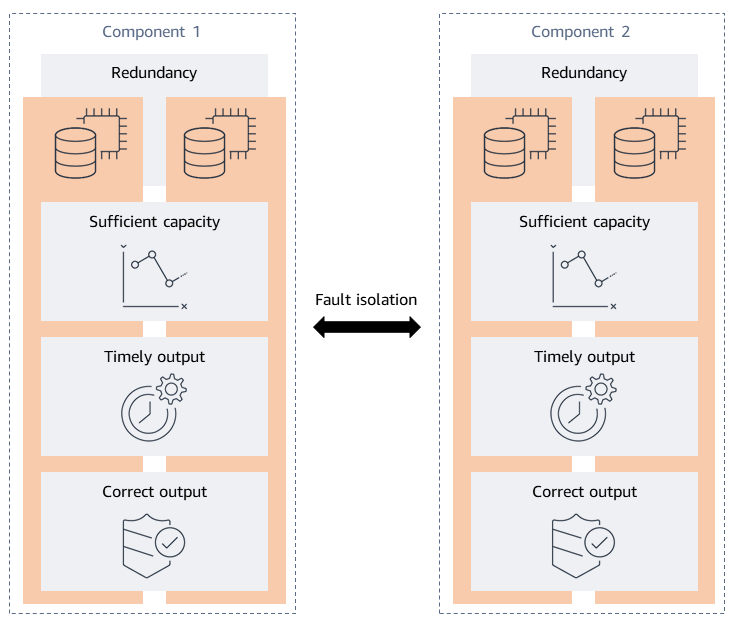
-
Redundanz — Fehlertoleranz wird durch Redundanz erreicht, die Single Points of Failure (SPOFs) eliminiert. Redundanz kann sich von Ersatzkomponenten in Ihrem Workload bis hin zu vollständigen Replikaten Ihres gesamten Anwendungsstapels erstrecken. Wenn Sie Redundanz für Ihre Anwendungen in Betracht ziehen, ist es wichtig, den Grad der Redundanz zu berücksichtigen, den die von Ihnen verwendete Infrastruktur, Datenspeicher und Abhängigkeiten bietet. Amazon DynamoDB und Amazon Simple Storage Service (Amazon S3) bieten beispielsweise Redundanz, indem sie Daten über mehrere Availability Zones in einer Region replizieren und AWS Lambda Ihre Funktionen auf mehreren Worker-Knoten in mehreren Availability Zones ausführen. Berücksichtigen Sie bei jedem Service, den Sie nutzen, was der Service bietet und worauf Sie achten müssen.
-
Ausreichende Kapazität — Ihr Workload benötigt ausreichend Ressourcen, um wie vorgesehen zu funktionieren. Zu den Ressourcen gehören Arbeitsspeicher, CPU-Zyklen, Threads, Speicher, Durchsatz, Servicekontingenten und viele andere.
-
Rechtzeitige Ausgabe — Wenn Kunden Ihren Workload nutzen, erwarten sie, dass er die vorgesehene Funktion innerhalb eines angemessenen Zeitraums erfüllt. Sofern der Service kein Service ein Service Level Agreement (SLA) für die Latenz vorsieht, basieren ihre Erwartungen in der Regel auf empirischen Erkenntnissen, d. h. auf ihren eigenen Erfahrungen. Dieses durchschnittliche Kundenerlebnis wird normalerweise als die durchschnittliche Latenz (P50) in Ihrem System angesehen. Wenn Ihre Arbeitslast länger als erwartet dauert, kann sich diese Latenz auf das Kundenerlebnis auswirken.
-
Richtige Ausgabe — Die korrekte Ausgabe der Software Ihres Workloads ist erforderlich, damit dieser die beabsichtigte Funktionalität bietet. Ein falsches oder unvollständiges Ergebnis kann schlimmer sein als gar keine Antwort.
-
Fehlerisolierung — Durch die Fehlerisolierung wird der Umfang der Auswirkungen auf den vorgesehenen Fehlerbehälter beschränkt, wenn ein Fehler auftritt. Sie stellt sicher, dass bestimmte Komponenten Ihres Workloads gleichzeitig ausfallen, und verhindert gleichzeitig, dass ein Ausfall auf andere unbeabsichtigte Komponenten übergreift. Es trägt auch dazu bei, den Umfang der Auswirkungen Ihres Workloads auf die Kunden zu begrenzen. Die Fehlerisolierung unterscheidet sich etwas von den vorherigen vier Eigenschaften, da sie akzeptiert, dass ein Fehler bereits aufgetreten ist, dieser aber eingedämmt werden sollte. Sie können eine Fehlerisolierung in Ihrer Infrastruktur, Ihren Abhängigkeiten und Softwarefunktionen einrichten.
Wenn eine bestimmte Eigenschaft verletzt wird, kann dies dazu führen, dass ein Workload nicht verfügbar ist oder als nicht verfügbar wahrgenommen wird. Auf der Grundlage dieser gewünschten Resilienzeigenschaften und unserer Erfahrung in der Zusammenarbeit mit vielen AWS Kunden haben wir fünf häufige Fehlerkategorien identifiziert: einzelne Fehlerquellen, übermäßige Last, übermäßige Latenz, Fehlkonfigurationen und Bugs sowie Shared Fate, was wir als SEEMS abkürzen. Diese bieten eine einheitliche Methode zur Kategorisierung potenzieller Ausfallarten und werden in der folgenden Tabelle beschrieben.
Kategorie des Fehlers |
Verstößt |
Definition |
|---|---|---|
Einzelne Fehlerquellen (SPOFs) |
Redundanz |
Ein Ausfall einer einzelnen Komponente unterbricht das System aufgrund mangelnder Redundanz der Komponente. |
Übermäßige Belastung |
Ausreichende Kapazität |
Over-consumption Wenn eine Ressource aufgrund von übermäßigem Bedarf oder übermäßigem Verkehr ausgelastet ist, kann die Ressource ihre erwartete Funktion nicht erfüllen. Dies kann das Erreichen von Grenzwerten und Kontingenten beinhalten, was zu einer Drosselung und Ablehnung von Anfragen führen kann. |
Übermäßige Latenz |
Rechtzeitige Ausgabe |
Die Latenz bei der Systemverarbeitung oder beim Netzwerkverkehr überschreitet die erwartete Zeit, die erwarteten Service Level Objectives (SLOs) oder Service Level Agreements (SLAs). |
Fehlkonfiguration und Bugs |
Richtige Ausgabe |
Softwarefehler oder Fehlkonfigurationen des Systems führen zu einer falschen Ausgabe. |
Gemeinsames Schicksal |
Isolierung von Fehlern |
Ein Fehler, der durch eine der vorherigen Fehlerkategorien verursacht wurde, überschreitet die Grenzen der vorgesehenen Fehlerisolierung und überträgt sich auf andere Teile des Systems oder auf andere Kunden. |
