Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Optimieren Sie benutzerdefinierte Funktionen
Benutzerdefinierte Funktionen (UDFs) und RDD.map in beeinträchtigen die Leistung PySpark häufig erheblich. Dies liegt an dem Aufwand, der erforderlich ist, um Ihren Python-Code in der Scala-Implementierung, die Spark zugrunde liegt, korrekt darzustellen.
Das folgende Diagramm zeigt die Architektur von PySpark Jobs. Wenn Sie verwenden PySpark, verwendet der Spark-Treiber die Py4j-Bibliothek, um Java-Methoden von Python aus aufzurufen. Beim Aufrufen von Spark SQL oder DataFrame integrierten Funktionen gibt es kaum Leistungsunterschiede zwischen Python und Scala, da die Funktionen auf jedem Executor JVM mit einem optimierten Ausführungsplan ausgeführt werden.
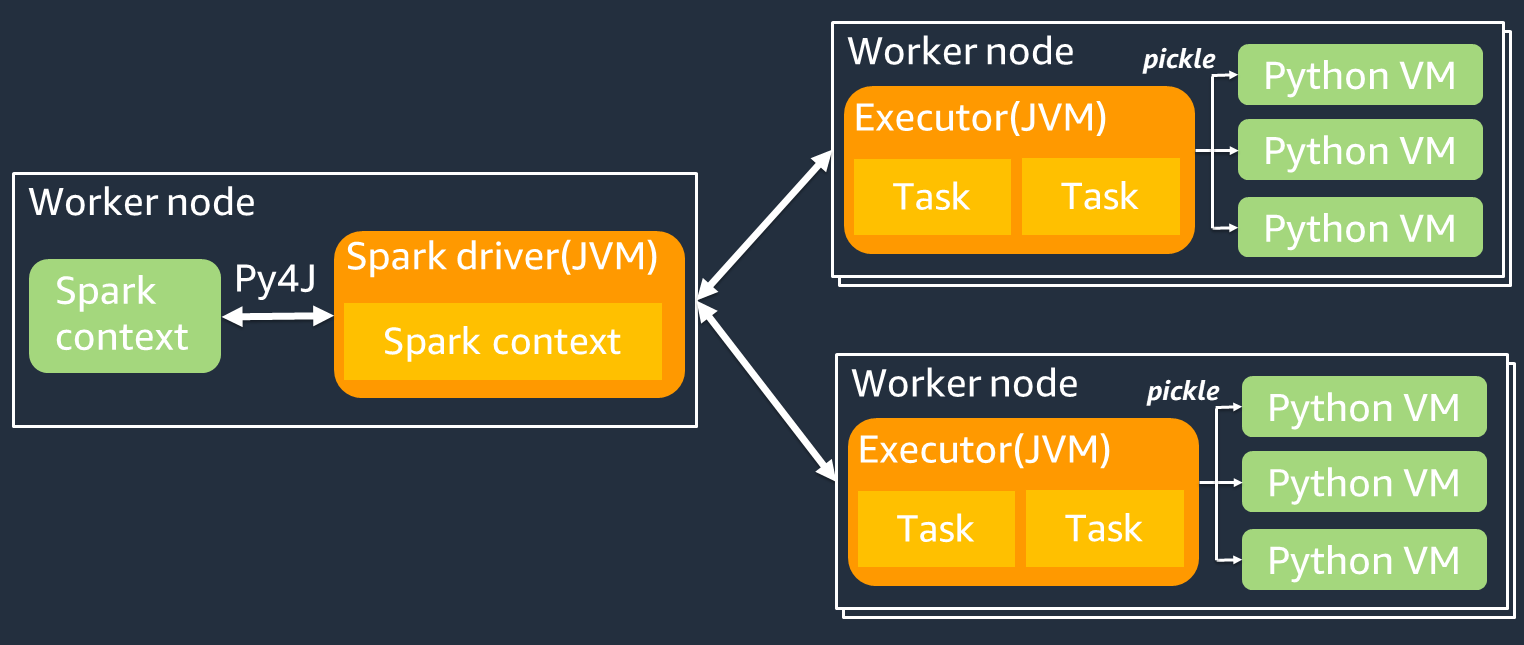
Wenn Sie Ihre eigene Python-Logik verwenden, z. B. usingmap/ mapPartitions/ udf, wird die Aufgabe in einer Python-Laufzeitumgebung ausgeführt. Die Verwaltung von zwei Umgebungen verursacht Gemeinkosten. Darüber hinaus müssen Ihre Daten im Speicher transformiert werden, damit sie von den integrierten Funktionen der JVM Laufzeitumgebung verwendet werden können. Pickle ist ein Serialisierungsformat, das standardmäßig für den Austausch zwischen der JVM und der Python-Laufzeit verwendet wird. Die Kosten für diese Serialisierung und Deserialisierung sind jedoch sehr hoch, sodass in Java oder Scala UDFs geschriebene Versionen schneller sind als in Python. UDFs
Beachten Sie Folgendes, um den Aufwand für Serialisierung und Deserialisierung zu vermeiden: PySpark
-
Verwenden Sie die integrierten SQL Spark-Funktionen — Erwägen Sie, Ihre eigene Funktion UDF oder Map-Funktion durch Spark SQL oder DataFrame integrierte Funktionen zu ersetzen. Bei der Ausführung von Spark SQL oder DataFrame integrierten Funktionen gibt es kaum Leistungsunterschiede zwischen Python und Scala, da die Aufgaben von jedem Executor ausgeführt werden. JVM
-
Implementieren Sie UDFs in Scala oder Java — Erwägen Sie die Verwendung von aUDF, die in Java oder Scala geschrieben ist, da sie auf dem ausgeführt werden. JVM
-
Verwenden Sie Apache Arrow-based UDFs für vektorisierte Workloads — Erwägen Sie die Verwendung von Arrow-based. UDFs Diese Funktion wird auch als Vectorized (Pandas) bezeichnet. UDF UDF Apache Arrow
ist ein sprachunabhängiges In-Memory-Datenformat, mit dem Daten effizient AWS Glue zwischen Python-Prozessen übertragen werden können. JVM Dies ist derzeit für Python-Benutzer, die mit Pandas oder NumPy Daten arbeiten, am vorteilhaftesten. Arrow ist ein spaltenförmiges (vektorisiertes) Format. Die Verwendung erfolgt nicht automatisch und erfordert möglicherweise einige geringfügige Änderungen an der Konfiguration oder am Code, um alle Vorteile zu nutzen und die Kompatibilität sicherzustellen. Weitere Informationen und Einschränkungen finden Sie unter Apache Arrow unter PySpark
. Im folgenden Beispiel wird eine einfache inkrementelle Version UDF in Standard-Python, als Vectorized UDF und in Spark verglichen. SQL
Standardpython UDF
Die Beispielzeit beträgt 3,20 (Sekunden).
Beispiel-Code
# DataSet df = spark.range(10000000).selectExpr("id AS a","id AS b") # UDF Example def plus(a,b): return a+b spark.udf.register("plus",plus) df.selectExpr("count(plus(a,b))").collect()
Ausführungsplan
== Physical Plan == AdaptiveSparkPlan isFinalPlan=false +- HashAggregate(keys=[], functions=[count(pythonUDF0#124)]) +- Exchange SinglePartition, ENSURE_REQUIREMENTS, [id=#580] +- HashAggregate(keys=[], functions=[partial_count(pythonUDF0#124)]) +- Project [pythonUDF0#124] +- BatchEvalPython [plus(a#116L, b#117L)], [pythonUDF0#124] +- Project [id#114L AS a#116L, id#114L AS b#117L] +- Range (0, 10000000, step=1, splits=16)
Vektorisiert UDF
Die Beispielzeit beträgt 0,59 (Sekunden).
Vectorized UDF ist fünfmal schneller als das vorherige Beispiel. UDF Wenn Sie Physical Plan das überprüfen, können Sie sehenArrowEvalPython, was zeigt, dass diese Anwendung von Apache Arrow vektorisiert wurde. Um Vectorized zu aktivierenUDF, müssen Sie in Ihrem Code Folgendes angebenspark.sql.execution.arrow.pyspark.enabled = true.
Beispiel-Code
# Vectorized UDF from pyspark.sql.types import LongType from pyspark.sql.functions import count, pandas_udf # Enable Apache Arrow Support spark.conf.set("spark.sql.execution.arrow.pyspark.enabled", "true") # DataSet df = spark.range(10000000).selectExpr("id AS a","id AS b") # Annotate pandas_udf to use Vectorized UDF @pandas_udf(LongType()) def pandas_plus(a,b): return a+b spark.udf.register("pandas_plus",pandas_plus) df.selectExpr("count(pandas_plus(a,b))").collect()
Ausführungsplan
== Physical Plan == AdaptiveSparkPlan isFinalPlan=false +- HashAggregate(keys=[], functions=[count(pythonUDF0#1082L)], output=[count(pandas_plus(a, b))#1080L]) +- Exchange SinglePartition, ENSURE_REQUIREMENTS, [id=#5985] +- HashAggregate(keys=[], functions=[partial_count(pythonUDF0#1082L)], output=[count#1084L]) +- Project [pythonUDF0#1082L] +- ArrowEvalPython [pandas_plus(a#1074L, b#1075L)], [pythonUDF0#1082L], 200 +- Project [id#1072L AS a#1074L, id#1072L AS b#1075L] +- Range (0, 10000000, step=1, splits=16)
Funke SQL
Die Beispielzeit beträgt 0,087 (Sekunden).
Spark SQL ist viel schneller als VectorizedUDF, da die Aufgaben auf jedem Executor JVM ohne Python-Laufzeit ausgeführt werden. Wenn Sie Ihre UDF durch eine integrierte Funktion ersetzen können, empfehlen wir, dies zu tun.
Beispiel-Code
df.createOrReplaceTempView("test") spark.sql("select count(a+b) from test").collect()
Pandas für Big Data verwenden
Wenn Sie bereits mit Pandas
