Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Reduzieren Sie den Umfang der gescannten Daten
Erwägen Sie zunächst, nur die Daten zu laden, die Sie benötigen. Sie können die Leistung verbessern, indem Sie einfach die Datenmenge reduzieren, die für jede Datenquelle in Ihren Spark-Cluster geladen wird. Verwenden Sie die folgenden Kennzahlen, um zu beurteilen, ob dieser Ansatz angemessen ist.
Sie können die von Amazon S3 gelesenen Bytes in CloudWatchMetriken und weiteren Details in der Spark-Benutzeroberfläche überprüfen, wie im Abschnitt Spark-Benutzeroberfläche beschrieben.
CloudWatch Metriken
Sie können die ungefähre Lesegröße von Amazon S3 unter ETLDatenbewegung (Byte) sehen. Diese Metrik zeigt die Anzahl der Byte, die seit dem letzten Bericht von allen Ausführern aus Amazon S3 gelesen wurden. Sie können damit die ETL Datenbewegung aus Amazon S3 überwachen und Lesevorgänge mit Aufnahmeraten aus externen Datenquellen vergleichen.
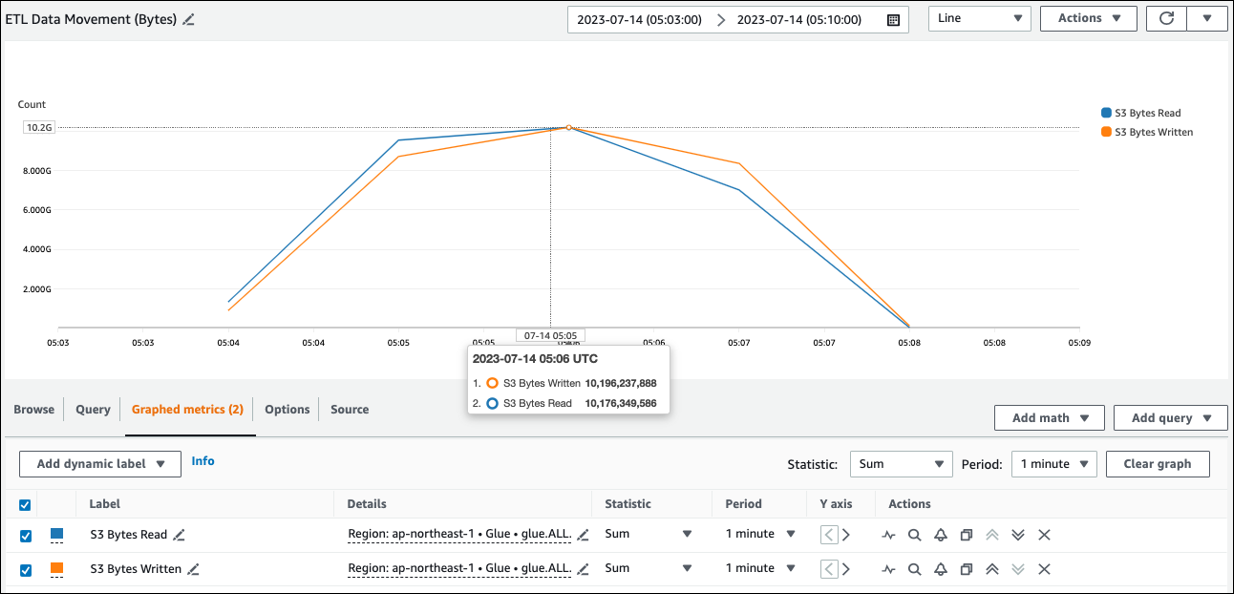
Wenn Sie einen größeren S3-Byte-Lesedatenpunkt als erwartet beobachten, sollten Sie die folgenden Lösungen in Betracht ziehen.
Spark-Benutzeroberfläche
Auf der Registerkarte Stage in der AWS Glue Benutzeroberfläche von Spark können Sie die Eingabe - und Ausgabegröße sehen. Im folgenden Beispiel liest Stufe 2 47,4 GiB Eingang und 47,7 GiB Ausgang, während Stufe 5 61,2 MiB Eingang und 56,6 MiB Ausgang liest.

Wenn Sie Spark SQL oder DataFrame Approaches in Ihrem AWS Glue Job verwenden, werden auf der ataFrame Registerkarte SQL/D weitere Statistiken zu diesen Phasen angezeigt. In diesem Fall zeigt Stufe 2 die Anzahl der gelesenen Dateien: 430, die Größe der gelesenen Dateien: 47,4 GiB und die Anzahl der Ausgabezeilen: 160.796.570.
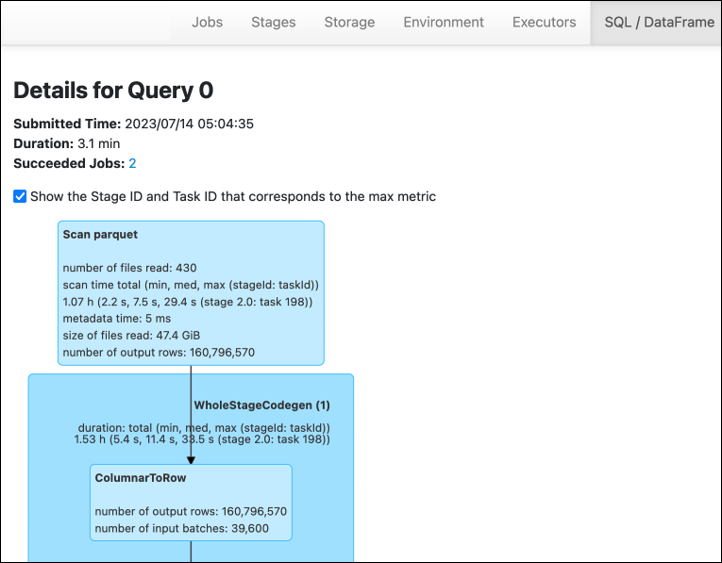
Wenn Sie feststellen, dass zwischen den Daten, die Sie einlesen, und den Daten, die Sie verwenden, ein erheblicher Größenunterschied besteht, probieren Sie die folgenden Lösungen aus.
Amazon S3
Um die Datenmenge zu reduzieren, die beim Lesen aus Amazon S3 in Ihren Job geladen wird, sollten Sie Dateigröße, Komprimierung, Dateiformat und Dateilayout (Partitionen) für Ihren Datensatz berücksichtigen. AWS Glue Für Spark-Jobs werden häufig Rohdaten verwendet, aber für eine effiziente verteilte Verarbeitung müssen Sie die Funktionen Ihres Datenquellenformats überprüfen. ETL
-
Dateigröße — Wir empfehlen, die Dateigröße der Ein- und Ausgaben in einem moderaten Bereich zu halten (z. B. 128 MB). Zu kleine und zu große Dateien können Probleme verursachen.
Eine große Anzahl kleiner Dateien verursacht die folgenden Probleme:
-
Starke Netzwerk-I/O-Last auf Amazon S3 aufgrund des Overheads, der erforderlich ist, um Anfragen (wie
ListGet, oderHead) für viele Objekte zu stellen (im Vergleich zu einigen wenigen Objekten, die dieselbe Datenmenge speichern). -
Starke I/O- und Verarbeitungslast auf dem Spark-Treiber, was viele Partitionen und Aufgaben generiert und zu übermäßiger Parallelität führt.
Wenn Ihr Dateityp jedoch nicht teilbar ist (z. B. Gzip) und die Dateien zu groß sind, muss die Spark-Anwendung warten, bis eine einzelne Aufgabe das Lesen der gesamten Datei abgeschlossen hat.
Um die übermäßige Parallelität zu reduzieren, die entsteht, wenn für jede kleine Datei eine Apache Spark-Aufgabe erstellt wird, verwenden Sie die Dateigruppierung für. DynamicFrames Dieser Ansatz verringert die Wahrscheinlichkeit, dass es beim Spark-Treiber zu einer OOM Ausnahme kommt. Um die Gruppierung von Dateien zu konfigurieren, legen Sie die
groupSizeParametergroupFilesund fest. Im folgenden Codebeispiel wird das AWS Glue DynamicFrame API in einem ETL Skript mit diesen Parametern verwendet.dyf = glueContext.create_dynamic_frame_from_options("s3", {'paths': ["s3://input-s3-path/"], 'recurse':True, 'groupFiles': 'inPartition', 'groupSize': '1048576'}, format="json") -
-
Komprimierung — Wenn Ihre S3-Objekte Hunderte von Megabyte groß sind, sollten Sie erwägen, sie zu komprimieren. Es gibt verschiedene Komprimierungsformate, die grob in zwei Typen eingeteilt werden können:
-
Nicht aufteilbare Komprimierungsformate wie Gzip erfordern, dass die gesamte Datei von einem Worker dekomprimiert wird.
-
Aufteilbare Komprimierungsformate wie bzip2 oder LZO (indexiert) ermöglichen die teilweise Dekomprimierung einer Datei, die parallelisiert werden kann.
Bei Spark (und anderen gängigen Engines für verteilte Verarbeitung) teilen Sie Ihre Quelldatendatei in Teile auf, die Ihre Engine parallel verarbeiten kann. Diese Einheiten werden oft als Splits bezeichnet. Sobald Ihre Daten in einem teilbaren Format vorliegen, können die optimierten AWS Glue Reader Splits aus einem S3-Objekt abrufen, indem sie ihnen die
RangeOption bieten, nur bestimmteGetObjectAPI Blöcke abzurufen. Sehen Sie sich das folgende Diagramm an, um zu sehen, wie dies in der Praxis funktionieren würde.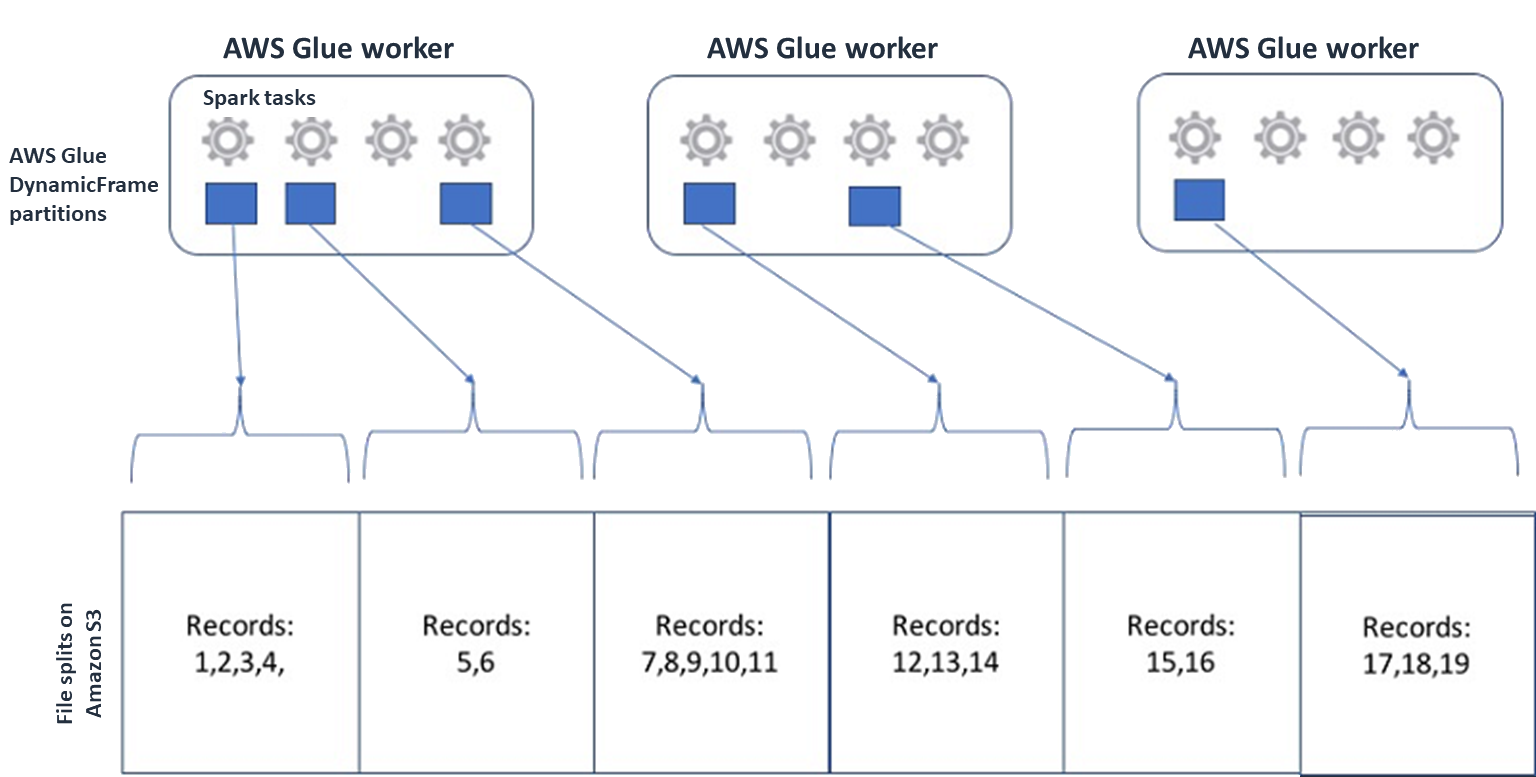
Komprimierte Daten können Ihre Anwendung erheblich beschleunigen, sofern die Dateien entweder eine optimale Größe haben oder die Dateien aufgeteilt werden können. Die kleineren Datengrößen reduzieren die von Amazon S3 gescannten Daten und den Netzwerkverkehr von Amazon S3 zu Ihrem Spark-Cluster. Andererseits CPU ist mehr erforderlich, um Daten zu komprimieren und zu dekomprimieren. Der Umfang der erforderlichen Rechenleistung hängt vom Komprimierungsverhältnis Ihres Komprimierungsalgorithmus ab. Berücksichtigen Sie diesen Kompromiss bei der Auswahl Ihres teilbaren Komprimierungsformats.
Anmerkung
GZIP-Dateien sind zwar im Allgemeinen nicht splittbar, aber Sie können einzelne Parkettblöcke mit gzip komprimieren und diese Blöcke können parallelisiert werden.
-
-
Dateiformat — Verwenden Sie ein Spaltenformat. Apache Parquet
und Apache ORC sind beliebte spaltenförmige Datenformate. ORCSpeichern und speichern Sie Daten effizient, indem Sie spaltenbasierte Komprimierung verwenden, jede Spalte auf der Grundlage ihres Datentyps kodieren und komprimieren. Weitere Informationen zu Parquet-Kodierungen finden Sie unter Parquet-Kodierungsdefinitionen. Parquet-Dateien können auch aufgeteilt werden. Spaltenformate gruppieren Werte nach Spalten und speichern sie zusammen in Blöcken. Wenn Sie Spaltenformate verwenden, können Sie Datenblöcke überspringen, die Spalten entsprechen, die Sie nicht verwenden möchten. Spark-Anwendungen können nur die Spalten abrufen, die Sie benötigen. Im Allgemeinen bedeuten bessere Komprimierungsraten oder das Überspringen von Datenblöcken, dass weniger Byte aus Amazon S3 gelesen werden, was zu einer besseren Leistung führt. Beide Formate unterstützen auch die folgenden Pushdown-Ansätze zur Reduzierung von I/O:
-
Projection Pushdown — Projection Pushdown ist eine Technik, mit der nur die in Ihrer Anwendung angegebenen Spalten abgerufen werden. Sie geben Spalten in Ihrer Spark-Anwendung an, wie in den folgenden Beispielen gezeigt:
-
DataFrame Beispiel:
df.select("star_rating") -
SQLSpark-Beispiel:
spark.sql("select start_rating from <table>")
-
-
Predicate Pushdown — Predicate Pushdown ist eine Technik zur effizienten Verarbeitung von Klauseln.
WHEREGROUP BYBeide Formate enthalten Datenblöcke, die Spaltenwerte darstellen. Jeder Block enthält Statistiken für den Block, z. B. Maximal- und Minimalwerte. Spark kann anhand dieser Statistiken bestimmen, ob der Block gelesen oder übersprungen werden soll, abhängig vom in der Anwendung verwendeten Filterwert. Um diese Funktion zu verwenden, fügen Sie den Bedingungen weitere Filter hinzu, wie in den folgenden Beispielen wie folgt dargestellt:-
DataFrame Beispiel:
df.select("star_rating").filter("star_rating < 2") -
SQLSpark-Beispiel:
spark.sql("select * from <table> where star_rating < 2")
-
-
-
Dateilayout — Indem Sie Ihre S3-Daten in Objekten in unterschiedlichen Pfaden speichern, je nachdem, wie die Daten verwendet werden, können Sie relevante Daten effizient abrufen. Weitere Informationen finden Sie unter Organisieren von Objekten mithilfe von Präfixen in der Amazon S3 S3-Dokumentation. AWS Glue unterstützt das Speichern von Schlüsseln und Werten in Amazon S3 S3-Präfixen im Format
key=value, wobei Ihre Daten nach dem Amazon S3 S3-Pfad partitioniert werden. Durch die Partitionierung Ihrer Daten können Sie die Menge der Daten einschränken, die von jeder nachgelagerten Analyseanwendung gescannt werden, wodurch die Leistung verbessert und die Kosten gesenkt werden. Weitere Informationen finden Sie unter Verwalten von Partitionen für die ETL Ausgabe in AWS Glue.Durch die Partitionierung wird Ihre Tabelle in verschiedene Teile unterteilt, und die zugehörigen Daten werden in gruppierten Dateien gespeichert, die auf Spaltenwerten wie Jahr, Monat und Tag basieren, wie im folgenden Beispiel gezeigt.
# Partitioning by /YYYY/MM/DD s3://<YourBucket>/year=2023/month=03/day=31/0000.gz s3://<YourBucket>/year=2023/month=03/day=01/0000.gz s3://<YourBucket>/year=2023/month=03/day=02/0000.gz s3://<YourBucket>/year=2023/month=03/day=03/0000.gz ...Sie können Partitionen für Ihren Datensatz definieren, indem Sie ihn mit einer Tabelle in der modellieren. AWS Glue Data Catalog Anschließend können Sie den Umfang der gescannten Daten einschränken, indem Sie Partitionen wie folgt bereinigen:
-
Für AWS Glue DynamicFrame, setzen Sie
push_down_predicate(odercatalogPartitionPredicate).dyf = Glue_context.create_dynamic_frame.from_catalog( database=src_database_name, table_name=src_table_name, push_down_predicate = "year='2023' and month ='03'", ) -
Legen Sie für Spark DataFrame einen festen Pfad zum Bereinigen von Partitionen fest.
df = spark.read.format("json").load("s3://<YourBucket>/year=2023/month=03/*/*.gz") -
Für Spark SQL können Sie die WHERE-Klausel festlegen, um Partitionen aus dem Datenkatalog zu löschen.
df = spark.sql("SELECT * FROM <Table> WHERE year= '2023' and month = '03'") -
Um beim Schreiben Ihrer Daten nach Datum zu partitionieren AWS Glue, geben Sie partitionKeys DynamicFrame oder partitionBy()
DataFrame zusammen mit den Datumsinformationen in Ihren Spalten wie folgt ein. -
DynamicFrame
glue_context.write_dynamic_frame_from_options( frame= dyf, connection_type='s3',format='parquet' connection_options= { 'partitionKeys': ["year", "month", "day"], 'path': 's3://<YourBucket>/<Prefix>/' } ) -
DataFrame
df.write.mode('append')\ .partitionBy('year','month','day')\ .parquet('s3://<YourBucket>/<Prefix>/')
Dies kann die Leistung der Nutzer Ihrer Ausgabedaten verbessern.
Wenn Sie nicht über die Möglichkeit verfügen, die Pipeline zu ändern, mit der Ihr Eingabe-Dataset erstellt wird, ist Partitionierung keine Option. Stattdessen können Sie nicht benötigte S3-Pfade ausschließen, indem Sie Glob-Muster verwenden. Legen Sie beim Einlesen Ausnahmen fest. DynamicFrame Der folgende Code schließt beispielsweise Tage in den Monaten 01 bis 09 im Jahr 2023 aus.
dyf = glueContext.create_dynamic_frame.from_catalog( database=db, table_name=table, additional_options = { "exclusions":"[\"**year=2023/month=0[1-9]/**\"]" }, transformation_ctx='dyf' )Sie können Ausnahmen auch in den Tabelleneigenschaften im Datenkatalog festlegen:
-
Schlüssel:
exclusions -
Wert:
["**year=2023/month=0[1-9]/**"]
-
-
-
Zu viele Amazon S3 S3-Partitionen — Vermeiden Sie es, Ihre Amazon S3 S3-Daten in Spalten zu partitionieren, die einen großen Wertebereich enthalten, wie z. B. eine ID-Spalte mit Tausenden von Werten. Dies kann die Anzahl der Partitionen in Ihrem Bucket erheblich erhöhen, da die Anzahl der möglichen Partitionen das Produkt aller Felder ist, nach denen Sie partitioniert haben. Zu viele Partitionen können zu folgenden Problemen führen:
-
Erhöhte Latenz beim Abrufen von Partitionsmetadaten aus dem Datenkatalog
-
Höhere Anzahl kleiner Dateien, was mehr Amazon S3 API S3-Anfragen erfordert (
ListGet, undHead)
Wenn Sie beispielsweise einen Datumstyp in
partitionByoder festlegenpartitionKeys, eignet sich eine Partitionierung auf Datumsebene für viele Anwendungsfälle.yyyy/mm/ddEsyyyy/mm/dd/<ID>könnten jedoch so viele Partitionen generiert werden, dass sich dies negativ auf die Gesamtleistung auswirken würde.Andererseits erfordern einige Anwendungsfälle, wie z. B. Echtzeitverarbeitungsanwendungen, viele Partitionen wie
yyyy/mm/dd/hh. Wenn Ihr Anwendungsfall umfangreiche Partitionen erfordert, sollten Sie die Verwendung von AWS Glue Partitionsindizes in Betracht ziehen, um die Latenz beim Abrufen von Partitionsmetadaten aus dem Datenkatalog zu reduzieren. -
Datenbanken und JDBC
Um den Datenscan beim Abrufen von Informationen aus einer Datenbank zu reduzieren, können Sie in einer Abfrage ein where Prädikat (oder eine SQL Klausel) angeben. Datenbanken, die keine SQL Schnittstelle bereitstellen, bieten ihren eigenen Mechanismus zum Abfragen oder Filtern.
Wenn Sie Verbindungen mit Java Database Connectivity (JDBC) verwenden, stellen Sie eine Auswahlabfrage mit der where Klausel für die folgenden Parameter bereit:
-
Verwenden DynamicFrame Sie für die sampleQueryOption. Wenn Sie das
additional_optionsArgument verwendencreate_dynamic_frame.from_catalog, konfigurieren Sie es wie folgt.query = "SELECT * FROM <TableName> where id = 'XX' AND" datasource0 = glueContext.create_dynamic_frame.from_catalog( database = db, table_name = table, additional_options={ "sampleQuery": query, "hashexpression": key, "hashpartitions": 10, "enablePartitioningForSampleQuery": True }, transformation_ctx = "datasource0" )Wenn
using create_dynamic_frame.from_options, konfigurieren Sie dasconnection_optionsArgument wie folgt.query = "SELECT * FROM <TableName> where id = 'XX' AND" datasource0 = glueContext.create_dynamic_frame.from_options( connection_type = connection, connection_options={ "url": url, "user": user, "password": password, "dbtable": table, "sampleQuery": query, "hashexpression": key, "hashpartitions": 10, "enablePartitioningForSampleQuery": True } ) -
Verwenden Sie für DataFrame die Abfrageoption
. query = "SELECT * FROM <TableName> where id = 'XX'" jdbcDF = spark.read \ .format('jdbc') \ .option('url', url) \ .option('user', user) \ .option('password', pwd) \ .option('query', query) \ .load() -
Verwenden Sie für Amazon Redshift AWS Glue 4.0 oder höher, um die Pushdown-Unterstützung im Amazon Redshift Spark-Connector zu nutzen.
dyf = glueContext.create_dynamic_frame.from_catalog( database = "redshift-dc-database-name", table_name = "redshift-table-name", redshift_tmp_dir = args["temp-s3-dir"], additional_options = {"aws_iam_role": "arn:aws:iam::role-account-id:role/rs-role-name"} ) -
Informationen zu anderen Datenbanken finden Sie in der Dokumentation zu dieser Datenbank.
AWS Glue Optionen
-
Um einen vollständigen Scan für alle fortlaufenden Auftragsausführungen zu vermeiden und nur Daten zu verarbeiten, die während der letzten Auftragsausführung nicht vorhanden waren, aktivieren Sie Job-Lesezeichen.
-
Um die Menge der zu verarbeitenden Eingabedaten zu begrenzen, aktivieren Sie die begrenzte Ausführung mit Job-Lesezeichen. Dies trägt dazu bei, die Menge der gescannten Daten bei jeder Auftragsausführung zu reduzieren.
