Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Arbeiten mit dem Abfrage-Editor v2
Der Abfrage-Editor v2 dient hauptsächlich dazu, Abfragen zu bearbeiten und auszuführen, Ergebnisse zu visualisieren und Ihre Arbeit mit Ihrem Team zu teilen. Mit dem Abfrage-Editor v2 können Sie Datenbanken, Schemata, Tabellen und benutzerdefinierte Funktionen (user-defined functions, UDFs) erstellen. Im Strukturansichtsbereich können Sie für jede Ihrer Datenbanken ihre Schemata anzeigen. Von den einzelnen Schemata können Sie Tabellen, Ansichten, UDFs und gespeicherte Prozeduren anzeigen.
Themen
Öffnen des Abfrage-Editors v2
Den Abfrage-Editor v2 öffnen
Melden Sie sich bei der Amazon Redshift Redshift-Konsole an AWS Management Console und öffnen Sie sie unter https://console.aws.amazon.com/redshiftv2/
. Wählen Sie im Navigator-Menü Editor und dann Query editor v2 (Abfrage-Editor v2) aus. Der Abfrage-Editor v2 wird in einer neuen Registerkarte geöffnet.
Die Abfrage-Editor-Seite enthält ein Navigationsmenü, in dem Sie eine Ansicht wie folgt auswählen können:
- Editor
Sie verwalten und fragen Ihre Daten ab, die als Tabellen organisiert und in einer Datenbank enthalten sind. Die Datenbank kann gespeicherte Daten oder einen Verweis auf Daten enthalten, die an anderer Stelle, z. B. in Amazon S3, gespeichert sind. Sie stellen eine Verbindung zu einer Datenbank her, die entweder in einem Cluster oder einer Serverless-Arbeitsgruppe enthalten ist.
In der Ansicht Editor haben Sie die folgenden Steuerelemente:
Im Feld Cluster oder Workgroup (Arbeitsgruppe) wird der Name des Objekts angezeigt, mit dem Sie gerade verbunden sind. Das Feld Database (Datenbank) zeigt die Datenbanken innerhalb des Clusters oder der Arbeitsgruppe an. Aktionen in der Ansicht Database (Datenbank) wirken sich standardmäßig auf die ausgewählte Datenbank aus.
Eine hierarchische Strukturansicht Ihrer Cluster oder Arbeitsgruppen, Datenbanken und Schemata. Unter den Schemata können Sie mit Ihren Tabellen, Ansichten, Funktionen und gespeicherten Prozeduren arbeiten. Jedes Objekt in der Baumansicht bietet ein Kontextmenü zum Ausführen verknüpfter Aktionen für das Objekt, etwa Refresh (Aktualisieren) oder Drop (Entfernen).
Die Aktion
 Create (Erstellen) zum Erstellen von Datenbanken, Schemata, Tabellen und Funktionen.
Create (Erstellen) zum Erstellen von Datenbanken, Schemata, Tabellen und Funktionen.Die
 -Aktion Daten laden, um Daten aus Amazon S3 oder aus einer lokalen Datei in Ihrer Datenbank zu laden.
-Aktion Daten laden, um Daten aus Amazon S3 oder aus einer lokalen Datei in Ihrer Datenbank zu laden.Das Symbol
 Save (Speichern) zum Speichern Ihrer Abfrage.
Save (Speichern) zum Speichern Ihrer Abfrage. Das Symbol
 Shortcuts zum Anzeigen der Tastenkombinationen für den Editor.
Shortcuts zum Anzeigen der Tastenkombinationen für den Editor. Ein
 Mehr-Symbol, um mehr Aktionen im Editor anzuzeigen. Wie beispielsweise:
Mehr-Symbol, um mehr Aktionen im Editor anzuzeigen. Wie beispielsweise: Für mein Team freigeben zum Freigeben einer Abfrage oder eines Notebooks für Ihr Team. Weitere Informationen finden Sie unter Zusammenarbeiten und Teilen im Team.
Das Symbol Shortcuts zum Anzeigen der Tastenkombinationen für den Editor.
Tab-Verlauf, um den Verlauf einer Registerkarte im Editor anzuzeigen.
Aktualisieren der automatischen Vervollständigung, um die angezeigten Vorschläge beim Verfassen von SQL zu aktualisieren.
Den
 Editor-Bereich, in dem Sie Ihre Abfrage eingeben und ausführen können.
Editor-Bereich, in dem Sie Ihre Abfrage eingeben und ausführen können. Nachdem Sie eine Abfrage ausgeführt haben, erscheint die Registerkarte Result mit den Ergebnissen. Hier können Sie Chart (Diagramm) aktivieren und sich die Ergebnisse visuell darstellen lassen. Sie können mit der Option Export (Exportieren) einen Export Ihrer Ergebnisse durchführen.
Ein
Notebook-Bereich, in dem Sie Abschnitte hinzufügen können, um SQL einzugeben und auszuführen oder Markdown hinzuzufügen. Nachdem Sie eine Abfrage ausgeführt haben, erscheint die Registerkarte Result mit den Ergebnissen. In diesem Bereich können Sie mit Export (Exportieren) einen Export Ihrer Ergebnisse durchführen.
- Abfragen

Eine Abfrage enthält die SQL-Befehle zum Verwalten und Abfragen Ihrer Daten in einer Datenbank. Wenn Sie den Abfrage-Editor v2 verwenden, um Beispieldaten zu laden, werden auch Beispielabfragen für Sie erstellt und gespeichert.
Wenn Sie eine gespeicherte Abfrage auswählen, können Sie diese über das Kontextmenü (Rechtsklickmenü) öffnen, umbenennen und löschen. Sie können Attribute wie den Abfrage-ARN einer gespeicherten Abfrage anzeigen, indem Sie Abfragedetails auswählen. Sie können auch den Versionsverlauf einsehen, an die Abfrage angehängte Tags bearbeiten und die Abfrage mit Ihrem Team teilen.
- Notebooks

Ein SQL-Notebook enthält SQL- und Markdown-Zellen. Sie können mit Notebooks mehrere SQL-Befehle in einem einzigen Dokument organisieren, kommentieren und freigeben.
Wenn Sie ein gespeichertes Notebook auswählen, können Sie dieses über das Kontextmenü (Rechtsklickmenü) öffnen, umbenennen, duplizieren und löschen. Sie können Attribute wie den Notebook-ARN eines gespeicherten Notebooks anzeigen, indem Sie Notebook-Details auswählen. Sie können auch den Versionsverlauf einsehen, an das Notebook angehängte Tags bearbeiten, das Notebook exportieren und mit Ihrem Team teilen. Weitere Informationen finden Sie unter Erstellen und Ausführen von Notebooks.
- Diagramme

Ein Diagramm ist eine visuelle Darstellung Ihrer Daten. Der Abfrage-Editor v2 bietet Werkzeuge, um verschiedene Diagramme zu erstellen und zu speichern.
Wenn Sie ein gespeichertes Diagramm auswählen, können Sie dieses über das Kontextmenü (Rechtsklickmenü) öffnen, umbenennen und löschen. Sie können Attribute wie den Diagramm-ARN eines gespeicherten Diagramms anzeigen, indem Sie Diagrammdetails auswählen. Sie können auch an das Diagramm angehängte Tags bearbeiten und das Diagramm exportieren. Weitere Informationen finden Sie unter Visualisieren von Abfrageergebnissen.
- Verlauf

Der Abfrage-Verlauf ist eine Liste von Abfragen, die Sie mit dem Amazon-Redshift-Abfrage-Editor v2 ausgeführt haben. Diese Abfragen wurden entweder als einzelne Abfragen oder als Teil eines SQL-Notebooks ausgeführt. Weitere Informationen finden Sie unter Abfrage- und Registerkarten-Verlauf anzeigen.
- Geplante Abfragen

Eine geplante Abfrage ist eine Abfrage, deren Ausführung für bestimmte Zeitpunkte geplant ist.
Alle Ansichten des Abfrage-Editors v2 haben die folgenden Symbole:
Ein Symbol
 Visual mode (Visualisierungsmodus) zum Umschalten zwischen Hell- und Dunkelmodus.
Visual mode (Visualisierungsmodus) zum Umschalten zwischen Hell- und Dunkelmodus.Ein Symbol
 Settings (Einstellungen), um ein Menü mit den verschiedenen Einstellungsbildschirmen anzuzeigen.
Settings (Einstellungen), um ein Menü mit den verschiedenen Einstellungsbildschirmen anzuzeigen.Ein Symbol
 Editor preferences (Editor-Einstellungen) zum Bearbeiten Ihrer Einstellungen, wenn Sie den Abfrage-Editor v2 verwenden. Hier können Sie die Workspace-Einstellungen bearbeiten, um die Schriftgröße, die Tabulatorgröße und andere Anzeigeneinstellungen zu ändern. Sie können die automatische Vervollständigung auch aktivieren (oder deaktivieren), um Vorschläge bei der Eingabe Ihrer SQL-Anweisung anzuzeigen.
Editor preferences (Editor-Einstellungen) zum Bearbeiten Ihrer Einstellungen, wenn Sie den Abfrage-Editor v2 verwenden. Hier können Sie die Workspace-Einstellungen bearbeiten, um die Schriftgröße, die Tabulatorgröße und andere Anzeigeneinstellungen zu ändern. Sie können die automatische Vervollständigung auch aktivieren (oder deaktivieren), um Vorschläge bei der Eingabe Ihrer SQL-Anweisung anzuzeigen.Ein Symbol
 Connections (Verbindungen), um die von Ihren Editor-Registerkarten verwendeten Verbindungen anzuzeigen.
Connections (Verbindungen), um die von Ihren Editor-Registerkarten verwendeten Verbindungen anzuzeigen.Eine Verbindung wird zum Abrufen von Daten aus einer Datenbank verwendet. Eine Verbindung wird für eine bestimmte Datenbank erstellt. Bei einer isolierten Verbindung sind die Ergebnisse eines SQL-Befehls, der die Datenbank ändert, z. B. das Erstellen einer temporären Tabelle, auf einer anderen Editor-Registerkarte nicht sichtbar. Wenn Sie eine Editor-Registerkarte im Abfrage-Editor v2 öffnen, ist die Standardeinstellung eine isolierte Verbindung. Wenn Sie eine gemeinsam genutzte Verbindung erstellen, d. h. Sie deaktivieren den Schalter Isolated session (Isolierte Sitzung), dann sind die Ergebnisse in anderen gemeinsam genutzten Verbindungen mit der gleichen Datenbank untereinander sichtbar. Editor-Registerkarten, die eine gemeinsame Verbindung mit einer Datenbank verwenden, werden jedoch nicht parallel ausgeführt. Abfragen, die dieselbe Verbindung verwenden, müssen warten, bis die Verbindung verfügbar ist. Eine Verbindung mit einer Datenbank kann nicht mit einer anderen Datenbank gemeinsam genutzt werden, sodass SQL-Ergebnisse nicht über verschiedene Datenbankverbindungen hinweg sichtbar sind.
Die Anzahl der Verbindungen, die im Konto eines Benutzers aktiv sein können, wird von einem Administrator des Abfrage-Editors v2 gesteuert.
Ein Symbol
 Account settings (Kontoeinstellungen), das von einem Administrator verwendet wird, um bestimmte Einstellungen aller Benutzer im Konto zu ändern. Weitere Informationen finden Sie unter Ändern von Kontoeinstellungen.
Account settings (Kontoeinstellungen), das von einem Administrator verwendet wird, um bestimmte Einstellungen aller Benutzer im Konto zu ändern. Weitere Informationen finden Sie unter Ändern von Kontoeinstellungen.
Herstellen einer Verbindung mit einer Amazon-Redshift-Datenbank
Um eine Verbindung zu einer Datenbank herzustellen, wählen Sie den Namen des Clusters oder der Arbeitsgruppe im Strukturansichtsbereich aus. Geben Sie bei Aufforderung die Verbindungsparameter ein.
Wenn Sie eine Verbindung zu einem Cluster oder einer Arbeitsgruppe und ihren Datenbanken herstellen, geben Sie in der Regel einen Namen für Database (Datenbank) an. Sie stellen außerdem Parameter bereit, die für eine der folgenden Authentifizierungsmethoden erforderlich sind:
- IAM Identity Center
-
Stellen Sie mit dieser Methode mit Ihren Single-Sign-On-Anmeldeinformationen von Ihrem Identitätsanbieter (IDP) eine Verbindung zu Ihrem Amazon Redshift Data Warehouse her. Ihr Cluster oder Ihre Arbeitsgruppe muss in der Amazon-Redshift-Konsole für IAM Identity Center aktiviert sein. Hilfe beim Einrichten von Verbindungen zum IAM Identity Center finden Sie unter. Connect Redshift mit IAM Identity Center, um Benutzern eine Single-Sign-On-Erfahrung zu bieten
- Verbundbenutzer
-
Bei dieser Methode müssen die Prinzipal-Tags Ihrer IAM-Rolle oder Ihres Benutzers die Verbindungsdetails angeben. Sie konfigurieren diese Tags in AWS Identity and Access Management oder bei Ihrem Identity Provider (IdP). Der Abfrage-Editor v2 basiert auf den folgenden Tags.
RedshiftDbUser– Dieses Tag definiert den Datenbankbenutzer, der vom Abfrage-Editor v2 verwendet wird. Dieses Tag ist erforderlich.RedshiftDbGroups– Dieses Tag definiert die Datenbankgruppen, die beim Herstellen einer Verbindung mit dem Abfrage-Editor v2 verbunden werden. Dieses Tag ist optional und sein Wert muss eine durch Doppelpunkte getrennte Liste sein, z. B.group1:group2:group3. Leere Werte werden ignoriert, d. h.group1::::group2wird alsgroup1:group2interpretiert.
Diese Tags werden an die API
redshift:GetClusterCredentialsweitergeleitet, um Anmeldeinformationen für Ihren Cluster abzurufen. Weitere Informationen finden Sie unter Einrichten von Prinzipal-Tags für die Verbindung eines Clusters oder einer Arbeitsgruppe von Query Editor v2 aus. - Temporäre Anmeldeinformationen unter Verwendung eines Datenbankbenutzernamens
-
Diese Option ist nur dann verfügbar, wenn Sie eine Verbindung mit einem Cluster herstellen. Bei dieser Methode, Abfrage-Editor v2, geben Sie einen User name (Benutzername) für die Datenbank an. Query Editor v2 generiert ein temporäres Passwort, um eine Verbindung zu der Datenbank mit Ihrem Datenbankbenutzernamen herzustellen. Ein Benutzer, der diese Methode verwendet, um eine Verbindung herzustellen, muss über die IAM-Berechtigung
redshift:GetClusterCredentialsverfügen. Wenn Sie verhindern möchten, dass Benutzer diese Methode verwenden, ändern Sie ihren IAM-Benutzer oder ihre -Rolle, um diese Berechtigung zu verweigern. - Temporäre Anmeldeinformationen unter Verwendung Ihrer IAM-Identität
-
Diese Option ist nur dann verfügbar, wenn Sie eine Verbindung mit einem Cluster herstellen. Bei dieser Methode ordnet Query Editor v2 Ihrer IAM-Identität einen Benutzernamen zu und generiert ein temporäres Passwort zum Herstellen einer Verbindung zu der Datenbank mit Ihrer IAM-Identität. Ein Benutzer, der diese Methode verwendet, um eine Verbindung herzustellen, muss über die IAM-Berechtigung
redshift:GetClusterCredentialsWithIAMverfügen. Wenn Sie verhindern möchten, dass Benutzer diese Methode verwenden, ändern Sie ihren IAM-Benutzer oder ihre -Rolle, um diese Berechtigung zu verweigern. - Datenbank-Benutzername und -Passwort
-
Geben Sie bei dieser Methode auch einen User name (Benutzername) und ein Password (Passwort) für die Datenbank an, mit der Sie eine Verbindung herstellen. Der Abfrage-Editor v2 erstellt in Ihrem Namen ein Secret, das in AWS Secrets Manager gesichert wird. Dieses Secret enthält Anmeldeinformationen zum Verbinden mit Ihrer Datenbank.
- AWS Secrets Manager
-
Bei dieser Methode geben Sie anstelle eines Datenbanknamens ein in Secrets Manager gespeichertes Secret an, das Ihre Datenbank und Ihre Anmeldeinformationen enthält. Hinweise zum Erstellen eines Geheimnisses finden Sie unterEin Geheimnis für Datenbankverbindungsdaten erstellen.
Wenn Sie mit dem Abfrage-Editor v2 einen Cluster oder eine Arbeitsgruppe auswählen, können Sie je nach Kontext Verbindungen über das Kontextmenü (Rechtsklick) erstellen, bearbeiten und löschen. Sie können Attribute wie den Verbindungs-ARN der Verbindung anzeigen, indem Sie Verbindungsdetails auswählen. Sie können auch an die Verbindung angehängte Tags bearbeiten.
Durchsuchen einer Amazon-Redshift-Datenbank
In einer Datenbank können Sie Schemata, Tabellen, Ansichten, Funktionen und gespeicherte Prozeduren im Baumansichtsbereich verwalten. Jedem Objekt in der Ansicht sind Aktionen in einem Kontextmenü (rechte Maustaste) zugeordnet.
In der hierarchischen Strukturansicht werden Datenbankobjekte angezeigt. Wenn Sie das Strukturansichtsfenster aktualisieren und Datenbankobjekte anzeigen möchten, die möglicherweise erstellt wurden, nachdem die Strukturansicht zuletzt angezeigt wurde, wählen Sie das
 -Symbol aus. Beim Öffnen des Kontextmenüs (rechte Maustaste) erscheint ein Objekt, das anzeigt, welche Aktionen Sie ausführen können.
-Symbol aus. Beim Öffnen des Kontextmenüs (rechte Maustaste) erscheint ein Objekt, das anzeigt, welche Aktionen Sie ausführen können.
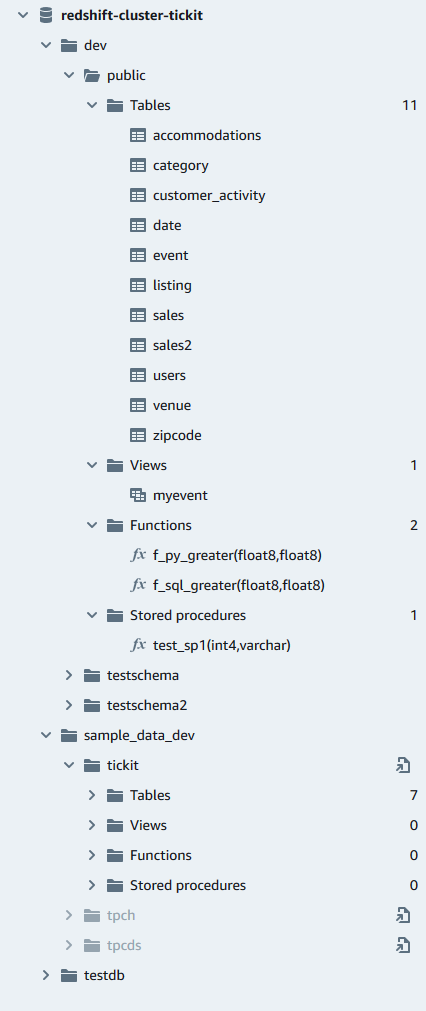
Nachdem Sie eine Tabelle ausgewählt haben, haben Sie folgende Optionen:
Um eine Abfrage im Editor mit einer SELECT-Anweisung zu starten, die alle Spalten in der Tabelle abfragt, verwenden Sie die Option Select table (Tabelle wählen).
Um die Attribute oder eine Tabelle anzuzeigen, verwenden Sie die Option Show table definition (Tabellendefinition anzeigen). Hiermit können Sie Spaltennamen, Spaltentypen, Kodierung, Verteilungsschlüssel, Sortierschlüssel sehen und ob eine Spalte Nullwerte enthalten kann. Weitere Informationen über Tabellenattribute finden Sie unter CREATE TABLE im Datenbankentwicklerhandbuch zu Amazon Redshift.
Um eine Tabelle zu löschen, verwenden Sie Delete (Löschen). Sie können entweder mit Truncate table (Tabelle abschneiden) alle Zeilen aus der Tabelle löschen oder mit Drop table (Tabelle entfernen) die Tabelle aus der Datenbank entfernen. Weitere Informationen finden Sie unter TRUNCATE und DROP TABLE im Datenbankentwicklerhandbuch zu Amazon Redshift.
Wählen Sie bei einem Schema Refresh (Aktualisieren) oder Drop Schema (Schema entfernen) aus.
Wählen Sie bei einer Ansicht Show view definition (Ansichtsdefinition anzeigen) oder Drop view (Ansicht entfernen) aus.
Wählen Sie bei einer Funktion Show function definition (Funktionsdefinition anzeigen) oder Drop function (Funktion entfernen) aus.
Wählen Sie bei einer gespeicherten Prozedur Show procedure definition (Prozedurdefinition anzeigen) oder Drop procedure (Prozedur entfernen) aus.
Erstellen von Datenbankobjekten
Sie können Datenbankobjekte erstellen, etwa Datenbanken, Schemata, Tabellen und benutzerdefinierte Funktionen (UDFs). Sie müssen mit einem Cluster oder einer Arbeitsgruppe und einer Datenbank verbunden sein, um Datenbankobjekte zu erstellen.
Erstellen von Datenbanken
Sie können den Abfrage-Editor v2 verwenden, um Datenbanken in Ihrem Cluster oder Ihrer Arbeitsgruppe zu erstellen.
Eine Datenbank erstellen
Weitere Informationen über Datenbanken finden Sie unter CREATE DATABASE im Datenbankentwicklerhandbuch zu Amazon Redshift.
Wählen Sie
Create (Erstellen) aus und danach Database (Datenbank).Geben Sie einen Database name (Datenbanknamen) ein.
(Optional) Wählen Sie Users and groups (Benutzer und Gruppen) und dort einen Database user (Datenbankbenutzer) aus.
(Optional) Sie können die Datenbank aus einem Datashare oder AWS Glue Data Catalog erstellen. Weitere Informationen zu AWS Glue finden Sie unter Was ist AWS Glue? im AWS Glue Entwicklerhandbuch.
(Optional) Wählen Sie Mit einem Datashare erstellen aus und klicken Sie auf Einen Datashare auswählen. Die Liste enthält Producer-Datashares, mit denen ein Consumer-Datashare im aktuellen Cluster oder in der aktuellen Arbeitsgruppe erstellt werden kann.
(Optional) Wählen Sie Erstellen mit AWS Glue Data Catalog und wählen Sie eine AWS Glue-Datenbank aus. Geben Sie im Datenkatalogschema den Namen ein, der für das Schema verwendet wird, wenn auf die Daten in einem dreiteiligen Namen (database.schema.table) verwiesen wird.
Wählen Sie Datenbank erstellen aus.
Die neue Datenbank wird in der Baumansicht angezeigt.
Wenn Sie den optionalen Schritt zum Abfragen einer Datenbank auswählen, die aus einem Datashare erstellt wurde, stellen Sie eine Verbindung mit einer Amazon-Redshift-Datenbank im Cluster oder in der Arbeitsgruppe her (z. B. die Standarddatenbank
dev). Verwenden Sie dabei die dreiteilige Notation (database.schema.table), die auf den Datenbanknamen verweist, den Sie beim Auswählen der Option Mit einem Datashare erstellen erstellt haben. Die Datashare-Datenbank ist auf der Editor-Registerkarte des Abfrage-Editors v2 aufgeführt, jedoch nicht für eine direkte Verbindung aktiviert.Wenn Sie den optionalen Schritt zur Abfrage einer Datenbank wählen, die aus einer erstellt wurde AWS Glue Data Catalog, stellen Sie eine Verbindung zu Ihrer Amazon Redshift Redshift-Datenbank im Cluster oder in der Arbeitsgruppe her (z. B. die Standarddatenbank
dev) und verwenden Sie die dreiteilige Notation (database.schema.table), die auf den Datenbanknamen verweist, den Sie erstellt haben, als Sie Create using ausgewählt haben, auf das Schema AWS Glue Data Catalog, das Sie in Data catalog schema benannt haben, und auf die Tabelle in. AWS Glue Data CatalogÄhnlich wie:SELECT * FROMglue-database.glue-schema.glue-tableAnmerkung
Vergewissern Sie sich, dass Sie mithilfe der Verbindungsmethode Temporäre Anmeldeinformationen mit Ihrer IAM-Identität mit der Standarddatenbank verbunden sind und dass Ihren IAM-Anmeldeinformationen Nutzungsrechte für die AWS Glue Datenbank gewährt wurden.
GRANT USAGE ON DATABASEglue-databaseto "IAM:MyIAMUser"Die AWS Glue Datenbank ist auf der Registerkarte des Abfrage-Editors v2 aufgeführt, sie ist jedoch nicht für eine direkte Verbindung aktiviert.
Weitere Informationen zum Abfragen von finden Sie unter Arbeiten mit von Lake Formation verwalteten Datenfreigaben als Verbraucher und Arbeiten mit von Lake Formation verwalteten Datenfreigaben als Produzent im Amazon Redshift Database Developer Guide. AWS Glue Data Catalog
Beispiel für das Erstellen einer Datenbank als Datashare-Consumer
Das folgende Beispiel beschreibt ein bestimmtes Szenario, das verwendet wurde, um mithilfe des Abfrage-Editors v2 eine Datenbank aus einem Datashare zu erstellen. Sehen Sie sich dieses Szenario an, um zu erfahren, wie Sie aus einem Datashare in Ihrer Umgebung eine Datenbank erstellen können. Dieses Szenario verwendet zwei Cluster, cluster-base (der Producer-Cluster) und cluster-view (der Consumer-Cluster).
Verwenden Sie die Amazon-Redshift-Konsole, um einen Datashare für die Tabelle
category2im Clustercluster-basezu erstellen. Der Producer-Datashare heißtdatashare_base.Weitere Informationen zum Erstellen von Datashares finden Sie unter Freigeben von Daten über Cluster in Amazon Redshift im Datenbankentwicklerhandbuch zu Amazon Redshift.
Verwenden Sie die Amazon-Redshift-Konsole, um einen Datashare
datashare_baseals Consumer für die Tabellecategory2im Clustercluster-viewzu erstellen.Sehen Sie sich das Strukturansichtsfenster im Abfrage-Editor v2 an, das die Hierarchie von
cluster-baseanzeigt als:Cluster:
cluster-baseDatenbank:
devSchema:
publicTabellen:
category2
Wählen Sie
Create (Erstellen) aus und danach Database (Datenbank).Geben Sie
see_datashare_baseals Datenbankname ein.Wählen Sie Mit einem Datashare erstellen aus und klicken Sie auf Einen Datashare auswählen. Wählen Sie
datashare_baseals Quelle der Datenbank aus, die Sie erstellen.Das Strukturansichtsfenster im Abfrage-Editor v2 zeigt die Hierarchie von
cluster-viewan als:Cluster:
cluster-viewDatenbank:
see_datashare_baseSchema:
publicTabellen:
category2
Wenn Sie die Daten abfragen, stellen Sie eine Verbindung mit der Standarddatenbank des Clusters
cluster-view(in der Regeldev) her, aber verweisen Sie auf die Datashare-Datenbanksee_datashare_basein Ihrem SQL-Code.Anmerkung
In der Editoransicht des Abfrage-Editors v2 ist der ausgewählte Cluster
cluster-view. Die ausgewählte Datenbank istdev. Diesee_datashare_base-Datenbank ist aufgeführt, jedoch nicht für eine direkte Verbindung aktiviert. Sie wählen diedev-Datenbank aus und verweisen aufsee_datashare_basein dem SQL-Code, den Sie ausführen.SELECT * FROM "see_datashare_base"."public"."category2";Die Abfrage ruft Daten aus dem Datashare
datashare_baseim Clustercluster_baseab.
Beispiel für das Erstellen einer Datenbank aus einem AWS Glue Data Catalog
Das folgende Beispiel beschreibt ein bestimmtes Szenario, das verwendet wurde, um eine Datenbank AWS Glue Data Catalog mithilfe eines Abfrage-Editors v2 zu erstellen. Sehen Sie sich dieses Szenario an, um zu erfahren, wie Sie eine Datenbank aus einer AWS Glue Data Catalog in Ihrer Umgebung erstellen können. Dieses Szenario verwendet einen Cluster cluster-view, der die von Ihnen erstellte Datenbank enthalten soll.
Wählen Sie
Create (Erstellen) aus und danach Database (Datenbank).Geben Sie
data_catalog_databaseals Datenbankname ein.Wählen Sie Create using a AWS Glue Data Catalog und wählen Sie Choose an AWS Glue database aus. Wählen Sie
glue_dbals Quelle der Datenbank aus, die Sie erstellen.Wählen Sie Datenkatalogschema aus und geben Sie
myschemaals Schemaname ein, der in dreiteiliger Notation verwendet werden soll.Das Strukturansichtsfenster im Abfrage-Editor v2 zeigt die Hierarchie von
cluster-viewan als:Cluster:
cluster-viewDatenbank:
data_catalog_databaseSchema:
myschemaTabellen:
category3
Wenn Sie die Daten abfragen, stellen Sie eine Verbindung mit der Standarddatenbank des Clusters
cluster-view(in der Regeldev) her, aber verweisen Sie auf die Datenbankdata_catalog_databasein Ihrem SQL-Code.Anmerkung
In der Editoransicht des Abfrage-Editors v2 ist der ausgewählte Cluster
cluster-view. Die ausgewählte Datenbank istdev. Diedata_catalog_database-Datenbank ist aufgeführt, jedoch nicht für eine direkte Verbindung aktiviert. Sie wählen diedev-Datenbank aus und verweisen aufdata_catalog_databasein dem SQL-Code, den Sie ausführen.SELECT * FROM "data_catalog_database"."myschema"."category3";Die Abfrage ruft Daten ab, die von AWS Glue Data Catalog katalogisiert sind.
Erstellen von Schemata
Sie können den Abfrage-Editor v2 verwenden, um Schemata in Ihrem Cluster oder Ihrer Arbeitsgruppe zu erstellen.
Ein Schema erstellen
Weitere Informationen über Schemata finden Sie unter Schemata im Datenbankentwicklerhandbuch zu Amazon Redshift.
Wählen Sie
Create (Erstellen) aus und danach Schema.Geben Sie einen Schema name (Schemennamen) ein.
Wählen Sie entweder Local (Lokal) oder External (Extern) für Schema type (Schematyp) aus.
Weitere Informationen über lokale Schemata finden Sie unter CREATE SCHEMA im Datenbankentwicklerhandbuch zu Amazon Redshift. Weitere Informationen über externe Schemata finden Sie unter CREATE EXTERNAL SCHEMA im Datenbankentwicklerhandbuch zu Amazon Redshift.
Wenn Sie External (Extern) auswählen, stehen Ihnen folgende Optionen für ein externes Schema zur Verfügung.
Glue Data Catalog (Glue-Datenkatalog) – zum Erstellen eines externen Schemas in Amazon Redshift, das auf Tabellen in AWS Glue verweist. Wählen Sie neben der AWS Glue Datenbank auch die dem Cluster zugeordnete IAM-Rolle und die dem Datenkatalog zugeordnete IAM-Rolle aus.
PostgreSQL – zum Erstellen eines externen Schemas in Amazon Redshift, das auf eine Datenbank verweist, die mit Amazon RDS für PostgreSQL oder mit einer Edition von Amazon Aurora PostgreSQL kompatibel ist. Geben Sie die Verbindungsinformationen für die Datenbank an. Weitere Informationen über Verbundabfragen finden Sie unter Abfragen von Daten mit Verbundabfragen im Datenbankentwicklerhandbuch zu Amazon Redshift.
MySQL – zum Erstellen eines externen Schemas in Amazon Redshift, das auf eine Datenbank verweist, die mit Amazon RDS für MySQL oder mit einer Edition von Amazon Aurora MySQL kompatibel ist. Geben Sie die Verbindungsinformationen für die Datenbank an. Weitere Informationen über Verbundabfragen finden Sie unter Abfragen von Daten mit Verbundabfragen im Datenbankentwicklerhandbuch zu Amazon Redshift.
Wählen Sie Create schema (Schema erstellen) aus.
Das neue Schema wird in der Baumansicht angezeigt.
Erstellen von Tabellen
Sie können den Abfrage-Editor v2 verwenden, um Tabellen in Ihrem Cluster oder Ihrer Arbeitsgruppe zu erstellen.
Eine Tabelle erstellen
Sie können eine Tabelle basierend auf einer CSV-Datei erstellen, in der Sie jede Spalte der Tabelle angeben bzw. definieren. Weitere Informationen über Tabellen finden Sie unter Gestalten von Tabellen und CREATE TABLE im Datenbankentwicklerhandbuch zu Amazon Redshift.
Wählen Sie Open query in editor (Abfrage im Editor öffnen) aus, um die Anweisung CREATE TABLE anzuzeigen und zu bearbeiten, bevor Sie die Abfrage zum Erstellen der Tabelle ausführen.
Klicken Sie auf
Create (Erstellen) und wählen Sie Table (Tabelle) aus.Wählen Sie ein Schema aus.
Geben Sie einen Tabellennamen ein.
Wählen Sie
Add field (Feld hinzufügen), um eine Spalte hinzuzufügen. Verwenden Sie eine CSV-Datei als Vorlage für die Tabellendefinition:
Wählen Sie Load from CSV (Laden aus CSV) aus.
Gehen Sie zum Speicherort der Datei.
Wenn Sie eine CSV-Datei verwenden, muss die erste Zeile der Datei die Spaltenüberschriften enthalten.
Wählen Sie die Datei und dann Open (Öffnen). Bestätigen Sie, dass die Spaltennamen und Datentypen korrekt sind.
Wählen Sie die einzelnen Spalten und die gewünschten Optionen aus:
Wählen Sie einen Wert für Encoding (Codierung) aus.
Wählen Sie einen Default value (Standardwert) aus.
Aktivieren Sie Automatically increment (Automatisch inkrementieren), wenn die Spaltenwerte inkrementiert werden sollen. Geben Sie dann einen Wert für Auto increment seed (Seed automatisch inkrementieren) und Auto increment step (Schritt automatisch inkrementieren) ein.
Aktivieren Sie Not NULL (Nicht NULL), wenn die Spalte immer einen Wert enthalten soll.
Geben Sie einen Wert für Size (Größe) für die Spalte ein.
Aktivieren Sie Primary key (Primärschlüssel), wenn Sie möchten, dass die Spalte ein Primärschlüssel sein soll.
Aktivieren Sie Unique key (Einmaliger Schlüssel), wenn Sie möchten, dass die Spalte ein einmaliger Schlüssel sein soll.
(Optional) Wählen Sie Table details (Tabellendetails) und dann eine der folgenden Optionen aus:
Spalte des Verteilungsschlüssels und deren Stil.
Spalte des Sortierschlüssels und deren Stil.
Aktivieren Sie Backup, um die Tabelle in Snapshots aufzunehmen.
Aktivieren Sie Temporary table (Temporäre Tabelle), um die Tabelle als temporäre Tabelle zu erstellen.
Wählen Sie Open query in editor (Abfrage im Editor öffnen) aus, um noch mehr Einstellungen zum Definieren der Tabelle zu treffen, bzw. Create table (Tabelle erstellen), um die Tabelle zu erstellen.
Erstellung von Funktionen
Sie können den Abfrage-Editor v2 verwenden, um Funktionen in Ihrem Cluster oder Ihrer Arbeitsgruppe zu erstellen.
Eine Funktion erstellen
Wählen Sie
Create (Erstellen) aus und dann Function (Funktion).Wählen Sie bei Type entweder SQL oder Python als Typ aus.
Wählen Sie einen Wert für Schema aus.
Geben Sie bei Name einen Namen für die Funktion ein.
Geben Sie bei Volatility den Wert der Volatilität der Funktion ein.
Wählen Sie Parameters nach ihren Datentypen in der Reihenfolge der Eingabeparameter.
Wählen Sie bei Returns (Rückgabewerte) einen Datentyp aus.
Geben Sie den SQL-Programmcode oder den Python-Programmcode für die Funktion ein.
Wählen Sie Create (Erstellen) aus.
Weitere Informationen über benutzerdefinierte Funktionen (UDFs) finden Sie unter Erstellen von benutzerdefinierten Funktionen im Datenbankentwicklerhandbuch zu Amazon Redshift.
Abfrage- und Registerkarten-Verlauf anzeigen
Sie können den Abfrage-Verlauf mit dem Abfrage-Editor v2 anzeigen. Im Abfrageverlauf werden nur Abfragen angezeigt, die Sie mit dem Abfrage-Editor v2 ausgeführt haben. Es werden Abfragen angezeigt, die über eine Editor- oder Notebook-Registerkarte ausgeführt wurden. Sie können die angezeigte Liste nach einem Zeitraum filtern, z. B. This week, in dem eine Woche als Montag–Sonntag definiert ist. Die Liste der Abfragen ruft gleichzeitig 25 Zeilen mit Abfragen ab, die Ihrem Filter entsprechen. Wählen Sie Load more (Mehr laden) aus, um den nächsten Satz anzuzeigen. Wählen Sie eine Abfrage aus dem Menü Actions (Aktionen) aus. Die verfügbaren Aktionen hängen davon ab, ob die ausgewählte Abfrage gespeichert wurde. Sie können die folgenden Operationen auswählen:
View query details (Abfragedetails anzeigen) – zeigt eine Abfragedetailseite mit weiteren Informationen zu der ausgeführten Abfrage an.
Open query in a new tab (Abfrage in einer neuen Registerkarte öffnen) – öffnet eine neue Editor-Registerkarte und bereitet sie mit der ausgewählten Abfrage vor. Wenn die Verbindung noch besteht, werden der Cluster oder die Arbeitsgruppe und die Datenbank automatisch ausgewählt. Stellen Sie zum Durchführen der Abfrage zunächst sicher, dass der richtige Cluster oder die richtige Arbeitsgruppe und die richtige Datenbank ausgewählt wurden.
Open source tab (Open-Source-Registerkarte) – wenn die Registerkarte noch geöffnet ist, wird zu der Editor- oder Notebook-Registerkarte navigiert, die die Abfrage bei ihrer Ausführung enthielt. Der Inhalt des Editors oder Notebooks hat sich möglicherweise geändert, nachdem die Abfrage ausgeführt wurde.
Open saved query (Gespeicherte Abfrage öffnen) – navigiert zur Editor- oder Notebook-Registerkarte und öffnet die Abfrage.
Sie können auch den Verlauf der Abfragen anzeigen, die auf einer Editor-Registerkarte ausgeführt wurden, oder den Verlauf der Abfragen, die auf einer Notebook-Registerkarte ausgeführt wurden. Wenn Sie den Verlauf der Abfragen auf einer Registerkarte anzeigen möchten, wählen Sie Tab history (Registerkartenverlauf) aus. Im Registerkartenverlauf können Sie Folgendes tun:
Copy query (Abfrage kopieren) – kopiert den SQL-Inhalt der Abfrageversion in die Zwischenablage.
Open query in a new tab (Abfrage in einer neuen Registerkarte öffnen) – öffnet eine neue Editor-Registerkarte und bereitet sie mit der ausgewählten Abfrage vor. Wenn Sie die Abfrage ausführen möchten, müssen Sie den Cluster oder die Arbeitsgruppe und die Datenbank auswählen.
View query details (Abfragedetails anzeigen) – zeigt eine Abfragedetailseite mit weiteren Informationen zu der ausgeführten Abfrage an.
Überlegungen zur Arbeit mit dem Abfrage-Editor v2
Beachten Sie Folgendes, wenn Sie mit dem Abfrage-Editor v2 arbeiten.
Das Abfrageergebnis darf höchstens 5 MB bzw. 100 000 Zeilen groß sein.
Sie können Abfragen mit bis zu 300 000 Zeichen ausführen.
Sie können Abfragen mit bis zu 30 000 Zeichen speichern.
Standardmäßig führt der Abfrage-Editor v2 automatisch einen Commit für jeden einzelnen SQL-Befehl aus, der ausgeführt wird. Wenn eine BEGIN-Anweisung bereitgestellt wird, werden Anweisungen innerhalb des BEGIN-COMMIT- oder BEGIN-ROLLBACK-Blocks als einzelne Transaktion ausgeführt. Weitere Informationen zu Transaktionen finden Sie unter BEGIN im Datenbankentwicklerhandbuch zu Amazon Redshift.
Die maximale Anzahl von Warnungen, die der Abfrage-Editor v2 während der Ausführung einer SQL-Anweisung anzeigt, beträgt
10. Wenn beispielsweise eine gespeicherte Prozedur ausgeführt wird, werden maximal 10 RAISE-Anweisungen angezeigt.Der Abfrage-Editor v2 unterstützt kein IAM
RoleSessionName, das Kommas (,) enthält. Möglicherweise wird ein Fehler ähnlich dem folgenden angezeigt:Fehlermeldung: „'aroa123456789example:MyText, yourtext' is not a valid value for TagValue - it contains unzulässige Zeichen“ Dieses Problem tritt auf, wenn Sie ein IAM definieren, das ein Komma enthält, und dann den Abfrage-Editor v2 mit dieser IAM-Rolle verwendenRoleSessionName.
Ändern von Kontoeinstellungen
Ein Benutzer mit den richtigen IAM-Berechtigungen kann Account settings (Kontoeinstellungen) für andere Benutzer im selben AWS-Konto anzeigen und ändern. Dieser Administrator kann Folgendes anzeigen oder festlegen:
Die maximale Anzahl gleichzeitiger Datenbankverbindungen pro Benutzer im Konto. Dazu gehören Verbindungen für Isolated sessions (Isolierte Sitzungen). Wenn Sie diesen Wert ändern, kann es 10 Minuten dauern, bis die Änderung wirksam wird.
Erlauben Sie Benutzern im Konto, einen gesamten Ergebnissatz aus einem SQL-Befehl in eine Datei zu exportieren.
Laden und zeigen Sie Beispieldatenbanken mit einigen zugehörigen gespeicherten Abfragen an.
Geben Sie einen Amazon-S3-Pfad an, der von Kontobenutzern verwendet wird, um Daten aus einer lokalen Datei zu laden.
Zeigen Sie den ARN des KMS-Schlüssels an, der zum Verschlüsseln von Ressourcen des Abfrage-Editors v2 verwendet wird.
