Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Die folgenden Informationen FAQs können Ihnen bei der Behebung von Problemen mit Ihren Amazon SageMaker Asynchronous Inference-Endpunkten helfen.
Sie können die folgenden Methoden verwenden, um die Anzahl der Instances hinter Ihrem Endpunkt zu ermitteln:
Sie können die SageMaker DescribeEndpointKI-API verwenden, um die Anzahl der Instances hinter dem Endpunkt zu einem bestimmten Zeitpunkt zu beschreiben.
Sie können die Anzahl der Instances abrufen, indem Sie sich Ihre CloudWatch Amazon-Metriken ansehen. Sehen Sie sich die metrics for your endpoint instances an, z. B.
CPUUtilizationoder,MemoryUtilizationund überprüfen Sie die Statistik zur Anzahl der Stichproben für einen Zeitraum von 1 Minute. Die Anzahl sollte der Anzahl der aktiven Instances entsprechen. Der folgende Screenshot zeigt die in der CloudWatch Konsole grafisch dargestellteCPUUtilizationMetrik, wobei die Statistik auf eingestellt istSample count, der Zeitraum auf1 minuteeingestellt ist und die resultierende Anzahl 5 ist.
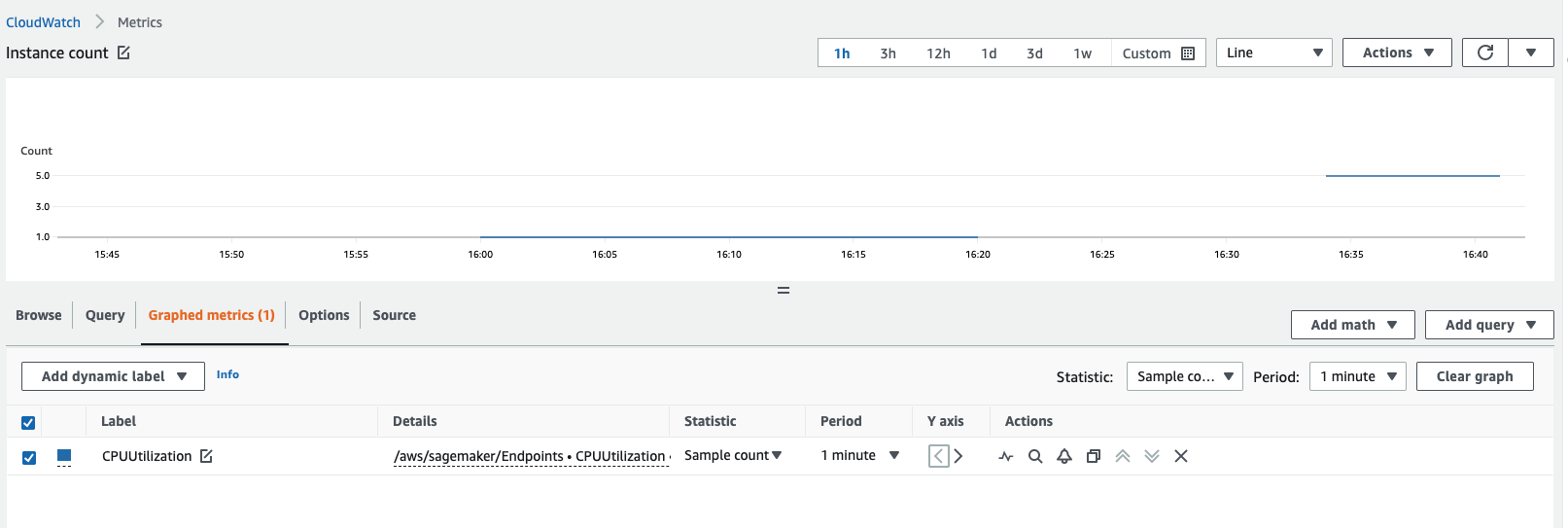
Sie können die folgenden Methoden verwenden, um die Anzahl der Instances hinter Ihrem Endpunkt zu ermitteln:
Sie können die SageMaker DescribeEndpointKI-API verwenden, um die Anzahl der Instances hinter dem Endpunkt zu einem bestimmten Zeitpunkt zu beschreiben.
Sie können die Anzahl der Instances abrufen, indem Sie sich Ihre CloudWatch Amazon-Metriken ansehen. Sehen Sie sich die metrics for your endpoint instances an, z. B.
CPUUtilizationoder,MemoryUtilizationund überprüfen Sie die Statistik zur Anzahl der Stichproben für einen Zeitraum von 1 Minute. Die Anzahl sollte der Anzahl der aktiven Instances entsprechen. Der folgende Screenshot zeigt die in der CloudWatch Konsole grafisch dargestellteCPUUtilizationMetrik, wobei die Statistik auf eingestellt istSample count, der Zeitraum auf1 minuteeingestellt ist und die resultierende Anzahl 5 ist.
In den folgenden Tabellen sind die gängigen einstellbaren Umgebungsvariablen für SageMaker KI-Container nach Framework-Typ aufgeführt.
TensorFlow
| Umgebungsvariable | Beschreibung |
|---|---|
|
|
Bei TensorFlow basierten Modellen ist die |
|
|
Dieser Parameter bestimmt den Anteil des verfügbaren GPU-Speichers für die Initialisierung von Cuda/cuDNN und anderen GPU-Bibliotheken. |
|
Dies ist auf die |
|
Dies ist auf die |
|
Dies bestimmt die Anzahl der Auftragnehmer-Prozesse, die Gunicorn zur Bearbeitung von Anfragen starten soll. Dieser Wert wird in Kombination mit anderen Parametern verwendet, um einen Satz abzuleiten, der den Inferenzdurchsatz maximiert. Darüber hinaus |
|
Dies bestimmt die Anzahl der Auftragnehmer-Prozesse, die Gunicorn zur Bearbeitung von Anfragen starten soll. Dieser Wert wird in Kombination mit anderen Parametern verwendet, um einen Satz abzuleiten, der den Inferenzdurchsatz maximiert. Darüber hinaus |
|
Python verwendet intern OpenMP für die Implementierung von Multithreading innerhalb von Prozessen. In der Regel werden Threads erzeugt, die der Anzahl der CPU-Kerne entsprechen. Wenn ein bestimmter Prozess jedoch zusätzlich zu Simultaneous Multi Threading (SMT) implementiert wird, wie z. B. bei Intel HypeThreading, kann es sein, dass er einen bestimmten Kern überlastet, indem er doppelt so viele Threads erzeugt wie die Anzahl der tatsächlichen CPU-Kerne. In bestimmten Fällen kann eine Python-Binärdatei bis zu viermal so viele Threads wie verfügbare Prozessorkerne erzeugen. Daher ist eine ideale Einstellung für diesen Parameter, wenn Sie die verfügbaren Kerne mit Auftragnehmer-Threads überbelegt haben, |
|
|
In einigen Fällen kann das Ausschalten von MKL die Inferenz beschleunigen, wenn |
PyTorch
| Umgebungsvariable | Beschreibung |
|---|---|
|
|
Dies ist die maximale Batchverzögerungszeit TorchServe , die bis zum Empfang abgewartet wird. |
|
|
Wenn TorchServe es nicht die in |
|
|
Die Mindestanzahl von Arbeitskräften, auf TorchServe die herunterskaliert werden darf. |
|
|
Die maximale Anzahl von Mitarbeitern, auf die TorchServe eine Skalierung erfolgen darf. |
|
|
Die Zeitverzögerung, nach deren Ablauf die Inferenz abläuft, wenn keine Antwort erfolgt. |
|
|
Die maximale Nutzlastgröße für TorchServe. |
|
|
Die maximale Antwortgröße für TorchServe. |
Multi Model Server (MMS)
| Umgebungsvariable | Beschreibung |
|---|---|
|
|
Dieser Parameter ist nützlich, wenn Sie ein Szenario haben, in dem der Typ der Nutzlast der Inferenzanforderung groß ist und aufgrund der größeren Nutzlast möglicherweise ein höherer Heap-Speicherverbrauch der JVM, in der diese Warteschlange verwaltet wird, auftreten kann. Im Idealfall sollten Sie die Heap-Speicheranforderungen von JVM niedriger halten und Python-Workern ermöglichen, mehr Speicher für die eigentliche Modellbereitstellung zuzuweisen. JVM dient nur dazu, die HTTP-Anfragen zu empfangen, sie in die Warteschlange zu stellen und sie zur Inferenz an die Python-basierten Worker weiterzuleiten. Wenn Sie den |
|
|
Dieser Parameter ist für die Backend-Modellbereitstellung vorgesehen und kann für die Optimierung nützlich sein, da dies die kritische Komponente der gesamten Modellbereitstellung ist, auf deren Grundlage die Python-Prozesse Threads für jedes Modell erzeugen. Wenn diese Komponente langsamer (oder nicht richtig abgestimmt) ist, ist das Frontend-Tuning möglicherweise nicht effektiv. |
Sie können denselben Container für asynchrone Inferenz verwenden wie für Real-Time Inference oder Batch Transform. Sie sollten sicherstellen, dass die Timeouts und die Payload-Größenbeschränkungen für Ihren Container so eingestellt sind, dass größere Payloads und längere Timeouts verarbeitet werden können.
Beachten Sie die folgenden Grenzwerte für asynchrone Inferenz:
Größenbeschränkung für die Nutzlast: 1 GB
Timeout-Limit: Eine Anfrage kann bis zu 60 Minuten dauern.
Warteschlangennachricht TimeToLive (TTL): 6 Stunden
Anzahl der Nachrichten, die in Amazon SQS gespeichert werden können: Unbegrenzt. Es gibt jedoch ein Kontingent von 120.000 für die Anzahl der laufenden Nachrichten für eine Standardwarteschlange und 20.000 für eine FIFO-Warteschlange.
Im Allgemeinen können Sie mit Asynchronous Inference die Skalierung auf der Grundlage von Aufrufen oder Instances vornehmen. Bei Aufrufmetriken empfiehlt es sich, sich Ihre ApproximateBacklogSize anzusehen. Dabei handelt es sich um eine Metrik, die die Anzahl der Elemente in Ihrer Warteschlange definiert, die noch verarbeitet wurden. Sie können diese Metrik oder Ihre InvocationsPerInstance Metrik verwenden, um zu verstehen, bei welchem TPS Sie möglicherweise gedrosselt werden. Überprüfen Sie auf Instance-Ebene Ihren Instance-Typ und dessen CPU/GPU-Auslastung, um zu definieren, wann eine Skalierung erforderlich ist. Wenn eine einzelne Instance eine Kapazität von über 60-70% aufweist, ist dies oft ein gutes Zeichen dafür, dass Sie Ihre Hardware ausgelastet haben.
Es wird nicht empfohlen, mehrere Skalierungsrichtlinien zu verwenden, da diese zu Konflikten führen und zu Verwirrung auf Hardwareebene führen können, was zu Verzögerungen bei der Skalierung führen kann.
Prüfen Sie, ob Ihr Container in der Lage ist, Ping- und Aufruf-Anfragen gleichzeitig zu verarbeiten. SageMaker KI-Aufrufanforderungen dauern ungefähr 3 Minuten. In dieser Zeit schlagen in der Regel mehrere Ping-Anfragen fehl, da das Timeout dazu führt, dass die SageMaker KI Ihren Container als erkennt. Unhealthy
Ja. MaxConcurrentInvocationsPerInstance ist eine Funktion von asynchronen Endpunkten. Dies hängt nicht von der Implementierung des benutzerdefinierten Containers ab. MaxConcurrentInvocationsPerInstance steuert die Geschwindigkeit, mit der Aufrufanforderungen an den Kundencontainer gesendet werden. Wenn dieser Wert auf 1 festgelegt ist, wird immer nur eine Anfrage an den Container gesendet, unabhängig davon, wie viele Auftragnehmer sich im Kundencontainer befinden.
Der Fehler bedeutet, dass der Kundencontainer einen Fehler zurückgegeben hat. SageMaker KI kontrolliert das Verhalten von Kundencontainern nicht. SageMaker KI gibt einfach die Antwort von zurück ModelContainer und versucht es nicht erneut. Wenn Sie möchten, können Sie den Aufruf so konfigurieren, dass er es bei einem Fehler erneut versucht. Wir empfehlen Ihnen, die Container-Protokollierung zu aktivieren und Ihre Container-Logs zu überprüfen, um die Ursache für den 500-Fehler in Ihrem Modell zu finden. Überprüfen Sie auch die entsprechenden CPUUtilization und MemoryUtilization Metriken zum Zeitpunkt des Fehlers. Sie können den S3 auch für FailurePath die Modellantwort in Amazon SNS als Teil der asynchronen Fehlerbenachrichtigungen zur Untersuchung von Fehlern konfigurieren.
Sie können die Metrik InvocationsProcesssed, überprüfen, die mit der Anzahl der Aufrufe übereinstimmen sollte, die Sie erwarten, dass sie in einer Minute verarbeitet werden, basierend auf einer einzigen Parallelität.
Die bewährte Methode besteht darin, Amazon SNS zu aktivieren, einen Benachrichtigungsdienst für messaging-orientierte Anwendungen, bei dem mehrere Abonnenten „Push“ -Benachrichtigungen über zeitkritische Nachrichten über verschiedene Transportprotokolle wie HTTP, Amazon SQS und E-Mail anfordern und empfangen. Asynchronous Inference sendet Benachrichtigungen, wenn Sie einen Endpunkt mit CreateEndpointConfig und einen Amazon SNS-Thema angeben.
Um Amazon SNS zur Überprüfung der Prognoseergebnisse von Ihrem asynchronen Endpunkt zu verwenden, müssen Sie zunächst ein Thema erstellen, das Thema abonnieren, Ihr Abonnement für das Thema bestätigen und den Amazon-Ressourcennamen (ARN) dieses Themas notieren. Ausführliche Informationen zum Erstellen, Abonnieren und Auffinden des Amazon-ARN eines Amazon SNS-Themas finden Sie unter Configuring Amazon SNS im Amazon SNS SNS-Entwicklerhandbuch. Weitere Informationen zur Verwendung von Amazon SNS mit asynchroner Inferenz finden Sie unter Überprüfen der Prognoseergebnisse.
Ja. Asynchrone Inferenz bietet einen Mechanismus zum Herunterskalieren auf null Instances, wenn keine Anfragen vorliegen. Wenn Ihr Endpunkt in diesen Zeiträumen auf null Instances herunterskaliert wurde, wird Ihr Endpunkt erst wieder hochskaliert, wenn die Anzahl der Anfragen in der Warteschlange das in Ihrer Skalierungsrichtlinie angegebene Ziel überschreitet. Dies kann zu langen Wartezeiten für Anfragen in der Warteschlange führen. Wenn Sie in solchen Fällen für neue Anfragen, die unter dem angegebenen Warteschlangenziel liegen, von Null auf Instances hochskalieren möchten, können Sie eine zusätzliche Skalierungsrichtlinie namens HasBacklogWithoutCapacity verwenden. Weitere Informationen zur Definition dieser Skalierungsrichtlinie finden Sie unter Autoscale an asynchronous endpoint.
Eine vollständige Liste der von Asynchronous Inference pro Region unterstützten Instances finden Sie unter Preise. SageMaker
